Автор: Денис Аветисян
Новое исследование предлагает глубокий анализ и эффективные методы квантования для ускорения вычислений в больших языковых моделях.
Теоретическое обоснование и практическая реализация схем квантования матричных умножений с использованием алгоритмов Waterfilling и Successive Cancellation для достижения близких к теоретическому пределу результатов.
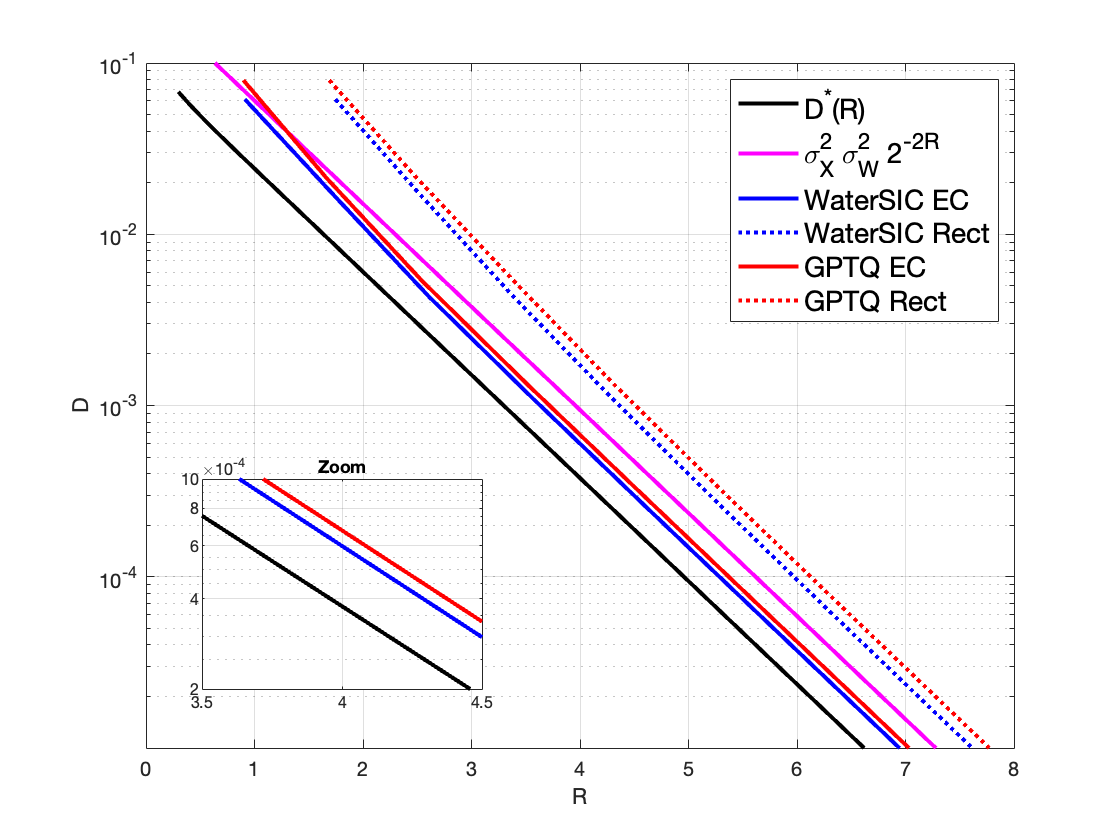
Квантование матричных умножений, критически важное для эффективного развертывания больших языковых моделей, часто сталкивается с компромиссом между скоростью вычислений и точностью представления данных. В работе ‘High-Rate Quantized Matrix Multiplication: Theory and Practice’ проведен теоретический и практический анализ различных схем квантования, рассматривающих как общее квантование матриц, так и случай квантования только весов, основанный на ковариационной матрице \Sigma_X. Показано, что предложенная схема WaterSIC, использующая скалярные INT-квантозаторы и принцип распределения битов по подобию waterfilling, позволяет приблизиться к теоретическим пределам точности с погрешностью всего в 0.25 бит на элемент, будучи нечувствительной к выбору базиса. Не откроет ли это путь к созданию еще более эффективных и точных алгоритмов квантования для LLM и других ресурсоемких задач машинного обучения?
Трудный путь к эффективности: Баланс точности и производительности
Современные модели глубокого обучения, особенно крупные языковые модели, предъявляют колоссальные требования к вычислительным ресурсам. Обучение и применение таких моделей требует значительных объемов памяти, высокой пропускной способности и мощных процессоров. Это связано с огромным количеством параметров, которые необходимо хранить и обрабатывать, а также с необходимостью выполнения большого количества математических операций. Растущий размер моделей, обусловленный стремлением к повышению точности и охвата, создает серьезные проблемы для их развертывания на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы. В результате, разработка методов снижения вычислительной нагрузки, не жертвуя при этом точностью, становится критически важной задачей в области искусственного интеллекта.
Уменьшение размера моделей глубокого обучения посредством квантования является критически важной задачей для их развертывания на устройствах с ограниченными ресурсами. Однако, простая, наивная реализация квантования, заключающаяся в грубом снижении разрядности весов и активаций, часто приводит к неприемлемому снижению точности. Это происходит из-за значительных искажений сигнала, возникающих при уменьшении количества бит, используемых для представления данных. В результате, несмотря на снижение вычислительных затрат и требований к памяти, производительность модели может существенно ухудшиться, что делает ее непригодной для практического применения. Поэтому, для успешного квантования необходимо разрабатывать и применять более сложные методы, минимизирующие потери точности и сохраняющие полезную информацию, закодированную в исходной модели.
Высокоточная квантизация, необходимая для эффективной работы современных нейронных сетей, сталкивается с фундаментальными ограничениями, обусловленными искажением сигнала. Теоретические исследования показывают, что существует нижняя граница точности, определяемая формулой 2\pi e \sigma W^2 2^{-2R}, где σ — стандартное отклонение сигнала, W — максимальный вес, а R — количество бит, используемых для квантизации. Преодоление этой границы требует разработки инновационных методов, позволяющих минимизировать потери информации при переходе от чисел с плавающей точкой к целочисленным представлениям. Игнорирование этих теоретических ограничений приводит к существенной деградации производительности модели, даже при использовании наивных подходов к квантизации, и делает поиск оптимальных стратегий квантизации сложной, но необходимой задачей.
Водяное заполнение и последовательная отмена помех: Надёжный фундамент
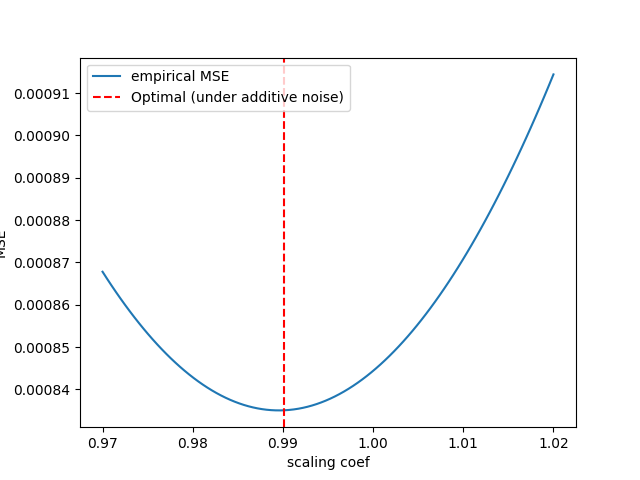
Решение методом заполнения водяной поверхностью (Waterfilling) представляет собой оптимальную стратегию распределения скорости передачи данных, направленную на минимизацию искажений при квантовании. Этот подход основан на распределении мощности передачи между различными каналами таким образом, чтобы максимизировать пропускную способность при заданном уровне шума. В основе алгоритма лежит принцип, согласно которому каналам с высоким отношением сигнал/шум (SNR) выделяется большая мощность, а каналам с низким SNR — меньшая, что позволяет эффективно использовать доступные ресурсы и минимизировать среднеквадратичную ошибку квантования. Математически, оптимальное распределение мощности определяется решением уравнения, учитывающего ограничения по общей мощности и целевую функцию минимизации искажений. Данный метод широко применяется в системах с многоканальным доступом, таких как OFDM, для повышения эффективности передачи данных и улучшения качества сигнала.
Комбинация алгоритма Waterfilling с последовательной интерференционной отменой (SIC) позволяет достичь итеративного улучшения характеристик системы и существенного прироста производительности. В процессе SIC, после первоначального распределения мощности, полученного с помощью Waterfilling, слабые сигналы последовательно вычитаются из принятого сигнала, что позволяет более точно декодировать оставшиеся, сильные сигналы. Этот процесс повторяется для каждого уровня мощности, приближая общую производительность к теоретическому нижнему пределу, определяемому выражением 2\pi e \sigma^2 W^{22-2R}, где σ — стандартное отклонение шума, W — пропускная способность канала, а R — целевая скорость передачи данных. Использование SIC в сочетании с Waterfilling эффективно снижает влияние интерференции и позволяет приблизиться к теоретически достижимой границе скорости передачи данных при заданном уровне шума.
Эффективная реализация алгоритма WaterSIC требует использования эффективных методов матричной декомпозиции, таких как разложение Холецкого. Для характеризации данных используется матрица ковариации, что позволяет оптимизировать процесс распределения мощности. При правильной реализации, достигается искажение, не превышающее теоретическую нижнюю границу в пределах фактора приблизительно 1.4233, что подтверждается аналитическими вычислениями и практическими экспериментами. Использование разложения Холецкого существенно снижает вычислительную сложность, позволяя масштабировать алгоритм для обработки больших объемов данных и обеспечивая высокую производительность в системах связи.
Оптимизация для современных архитектур: Квантование FPMM и INTMM
Квантование матричных умножений с плавающей точкой (FPMM) и целочисленных матричных умножений (INTMM) является критически важным для ускорения процесса инференса в задачах глубокого обучения. Традиционно, операции умножения матриц требуют значительных вычислительных ресурсов и потребляют много энергии. Квантование, то есть представление чисел с меньшей разрядностью, позволяет существенно снизить эти требования. Переход от операций с плавающей точкой (например, FP32) к целочисленным операциям (INT8 или даже INT4) приводит к уменьшению объема памяти, необходимой для хранения весов и активаций, а также к увеличению пропускной способности вычислений благодаря использованию специализированных аппаратных средств, поддерживающих целочисленные операции. В результате, квантование FPMM и INTMM является ключевым фактором повышения производительности и энергоэффективности при развертывании моделей глубокого обучения, особенно на устройствах с ограниченными ресурсами.
Для повышения эффективности выполнения операций с плавающей точкой (FPMM) применяются различные методы квантования, включая Absmax, Dithered Quantization и преобразования Адамара. В частности, вращение Адамара (Hadamard Rotation) демонстрирует значительное снижение ошибки квантования при использовании 8-битного целочисленного представления (INT8). Этот подход позволяет уменьшить потерю точности, возникающую при переходе от операций с плавающей точкой к целочисленным, что критически важно для ускорения инференса моделей глубокого обучения, особенно в задачах, требующих высокой производительности и ограниченных вычислительных ресурсов. \text{Ошибка квантования} \approx \frac{q}{2^n} , где q — шаг квантования, а n — количество бит.
Схемы квантования, включая Absmax, Dithered Quantization и преобразования Адамара, успешно применяются для оптимизации производительности больших языковых моделей, таких как Llama-3-8B. Практические результаты показывают, что применение этих методов позволяет значительно снизить вычислительные затраты и ускорить процесс инференса без существенной потери точности. В частности, преобразование Адамара демонстрирует эффективность в снижении ошибки квантования при использовании 8-битной целочисленной квантизации (INT8), что делает его перспективным решением для развертывания моделей на ресурсоограниченных устройствах и в условиях высокой нагрузки.
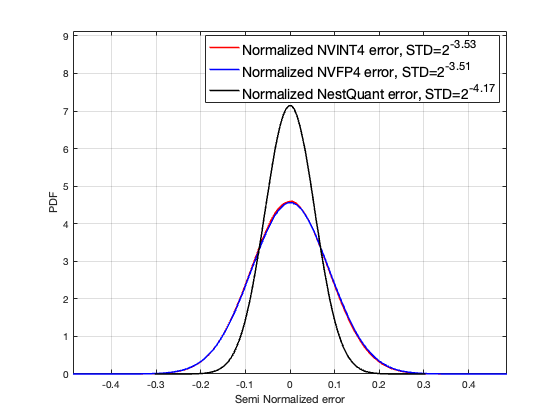
Разрушая границы: NestQuant и за её пределами
Метод NestQuant представляет собой инновационный подход к квантованию, который позволяет оптимизировать компромисс между объемом и вторым моментом, что существенно повышает эффективность обработки данных. Традиционные методы квантования часто фокусируются исключительно на минимизации ошибки между исходным сигналом и его квантованной версией, игнорируя влияние формы распределения данных на итоговую производительность. NestQuant, напротив, учитывает как объем, так и второй момент распределения, позволяя более точно адаптировать процесс квантования к конкретным характеристикам данных. \text{Эффект заключается в более эффективном использовании доступного битового бюджета и снижении потерь информации, что приводит к улучшению качества реконструкции сигнала и повышению производительности в различных приложениях, таких как сжатие изображений и аудио, машинное обучение и обработка сигналов.} Данный подход особенно важен при работе с высокоразмерными данными, где традиционные методы могут приводить к значительным потерям информации и снижению точности.
В контексте высокоразрешенных данных, снижение размерности посредством методов скетчирования открывает значительные возможности для повышения эффективности квантования. Данный подход позволяет уменьшить вычислительную сложность и объем памяти, необходимые для обработки информации, без существенной потери качества. Суть заключается в проецировании данных на меньшее число измерений с сохранением наиболее важных характеристик, что позволяет более эффективно распределить уровни квантования и минимизировать искажения. Исследования показывают, что грамотное применение скетчирования в сочетании с оптимизированными алгоритмами квантования позволяет добиться значительного улучшения производительности, особенно при работе с изображениями высокого разрешения и другими многомерными данными, где традиционные методы квантования могут оказаться неэффективными.
Оценка эффективного числа бит является ключевым показателем для анализа информационного содержания квантованных сигналов. Исследование показало, что при использовании оптимизированных методов квантования удается достичь искажений, приближающихся к теоретическому пределу, определяемому теоремой Найквиста-Шеннона. Это означает, что потери информации при преобразовании аналогового сигнала в цифровой формат минимизируются, что критически важно для задач, требующих высокой точности, таких как обработка изображений, звука и данных сенсоров. Использование данной метрики позволяет более эффективно оценивать и сравнивать различные алгоритмы квантования, а также оптимизировать параметры квантования для конкретных приложений, обеспечивая максимальное сохранение информации при минимальном объеме занимаемой памяти. MSE \approx \epsilon, где ε стремится к нулю при оптимальном квантовании.
Исследование, представленное в данной работе, закономерно подводит к мысли о неизбежном компромиссе между теоретической оптимальностью и практической реализацией. Авторы демонстрируют, что даже при использовании низкоточных вычислений, можно приблизиться к теоретическим пределам, определяемым теорией информации, применяя методы, такие как WaterSIC. Это лишь подтверждает известную истину, которую любил повторять Пауль Эрдеш: «Математика — это искусство находить закономерности, которые никто не замечал». В контексте квантования матриц, эта закономерность заключается в умении балансировать между точностью представления данных и вычислительной эффективностью, осознавая, что каждая «революционная» технология завтра станет техдолгом. В конечном счете, производительность всегда найдёт способ сломать элегантную теорию, заставляя инженеров искать новые, более устойчивые решения.
Что дальше?
Представленная работа, тщательно исследуя возможности квантования матричных умножений, неизбежно сталкивается со старым вопросом: насколько близко к теоретическому пределу вообще возможно подойти на практике? Иными словами, каждая новая оптимизация — лишь временное отсрочивание неизбежного столкновения с реальными ограничениями оборудования и, что важнее, с энтропией процесса разработки. Оптимизация квантования, безусловно, важна, но не стоит забывать, что каждое последующее поколение языковых моделей потребует ещё более радикальных подходов, и, вероятно, переизобретения существующих.
Перспективы дальнейших исследований лежат не только в углублении теоретического анализа, но и в осознании того, что «чистый код» в контексте крупномасштабных вычислений — это иллюзия. Неизбежно возникнут новые «костыли», обёрнутые в модные архитектурные паттерны. Возможно, стоит переключить внимание с бесконечного дробления задач на микросервисы на более фундаментальные вопросы — как вообще организовать вычисления так, чтобы они были устойчивы к неизбежному росту сложности.
В конечном итоге, достижение теоретических пределов квантования — это лишь одна из ступеней в бесконечном цикле оптимизации и деградации. Каждая «революционная» технология неизбежно превратится в технический долг, требующий постоянной поддержки и переработки. И, вероятно, нам нужно меньше иллюзий об идеальном коде и больше прагматичного подхода к решению реальных проблем.
Оригинал статьи: https://arxiv.org/pdf/2601.17187.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-28 00:13