Автор: Денис Аветисян
В статье представлен метод Gaussian Quant (GQ), позволяющий преобразовывать Гауссовские Автокодировщики в VQ-VAE без дополнительного обучения.
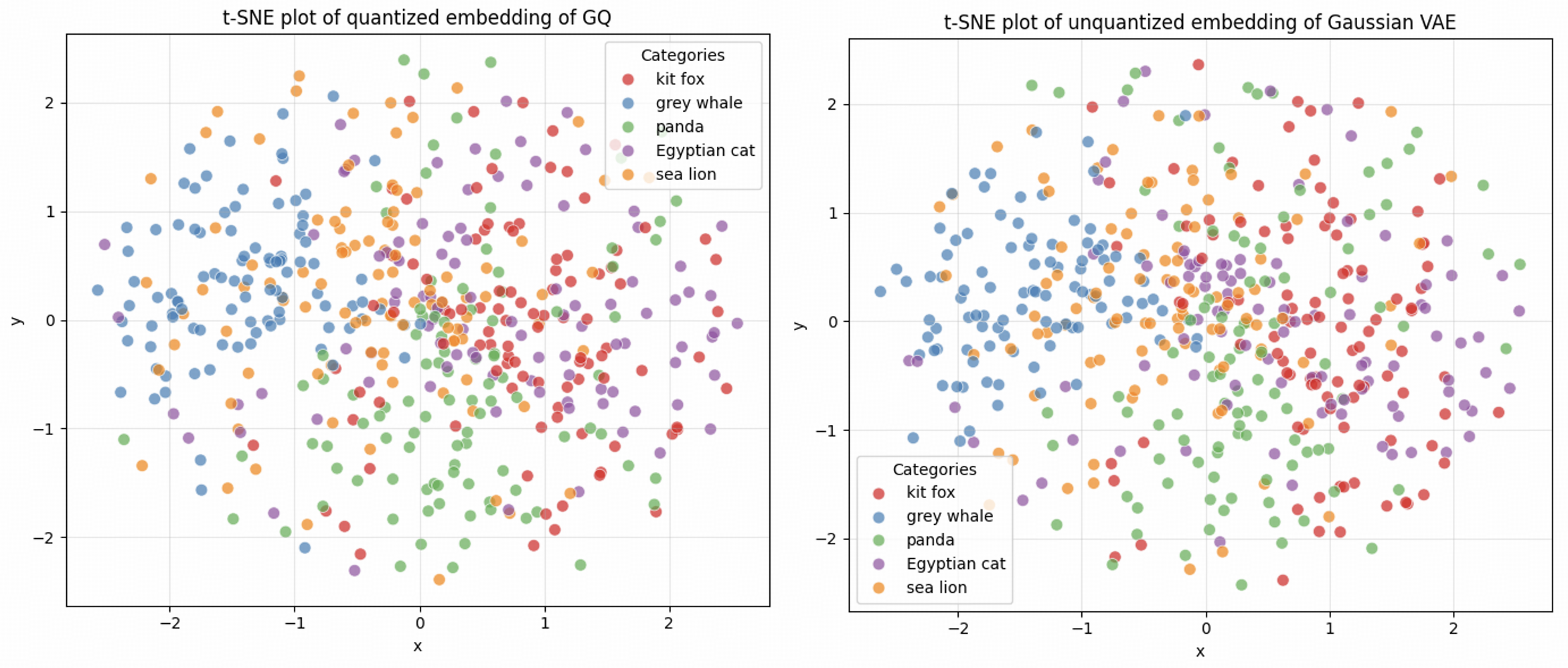
Разработанный подход обеспечивает высокую производительность и теоретически обоснованное ограничение расхождения (Target Divergence Constraint) при квантовании.
Дискретизация непрерывных представлений в автоэнкодерах часто сопряжена со сложностями обучения и потерей информации. В данной работе, посвященной ‘Vector Quantization using Gaussian Variational Autoencoder’, предложен новый подход Gaussian Quant (GQ), позволяющий преобразовать Гауссовский вариационный автоэнкодер в векторно-квантованный (VQ-VAE) без дополнительного обучения. GQ генерирует кодбук на основе случайного Гауссовского шума и квантует среднее апостериорное распределение, гарантируя малую ошибку квантования при определенных условиях и используя практический метод обучения с ограничением целевого расхождения (TDC). Превосходя существующие VQ-VAE, такие как VQGAN и TokenBridge, предложенный подход открывает новые перспективы для эффективного сжатия и представления данных — какие еще архитектуры и задачи могут выиграть от такого простого и эффективного преобразования?
Преодолевая Границы: Проблема Масштабируемого Представления Изображений
Традиционные сверточные и трансформаторные архитектуры испытывают значительные трудности при эффективной обработке изображений высокого разрешения. Это связано с экспоненциальным ростом вычислительных затрат и требований к памяти при увеличении количества пикселей. По мере роста разрешения изображения, количество параметров в этих моделях также увеличивается, что приводит к замедлению обработки и снижению масштабируемости. Например, для обработки изображения размером $1024 \times 1024$ требуется значительно больше вычислительных ресурсов, чем для изображения $256 \times 256$, что делает применение таких моделей в задачах, требующих обработки изображений высокого разрешения, проблематичным и неэффективным. Данные ограничения подталкивают исследователей к поиску альтернативных подходов к представлению изображений, которые позволят сохранить высокую точность при меньших вычислительных затратах.
Основная сложность в обработке изображений высокого разрешения заключается в ограниченности вычислительных ресурсов, необходимых для представления сложной визуальной информации. Традиционные методы, требующие огромного количества параметров и операций, становятся непрактичными при увеличении разрешения. В связи с этим, исследователи все больше внимания уделяют переходу к компактным и дискретным представлениям изображений. Вместо непрерывных значений пикселей, предлагается использовать дискретные символы или коды, что позволяет значительно снизить объем необходимых данных и вычислительную нагрузку. Такой подход открывает возможности для создания более эффективных и масштабируемых моделей, способных обрабатывать изображения с высоким разрешением на устройствах с ограниченными ресурсами, например, мобильных телефонах или встроенных системах. Разработка подобных методов является ключевой задачей для развития компьютерного зрения и обработки изображений в целом.
Векторная Квантизация: Дискретное Латентное Пространство
Автокодировщики с векторной квантизацией (VQ-VAE) представляют собой эффективный подход к обучению дискретных латентных представлений изображений. В основе этого метода лежит использование кодовой книги — набора векторов, к которым отображаются непрерывные признаки, полученные из входного изображения. Этот процесс квантизации позволяет заменить непрерывный латентный вектор ближайшим вектором из кодовой книги, представляя изображение в виде последовательности дискретных токенов. Такое дискретное представление позволяет упростить моделирование данных и снизить вычислительную нагрузку, а также способствует улучшению генеративных возможностей модели за счет использования дискретных признаков.
Ключевыми элементами, обеспечивающими эффективную квантизацию и стабильное обучение в VQ-VAE, являются функция потерь Commitment Loss и метод Gumbel-Softmax. Commitment Loss, определяемая как $||sg(z) — e||^2$, где $z$ — вектор признаков, $e$ — ближайший вектор из кодовой книги, а $sg$ — оператор остановки градиента, способствует “привязке” вектора признаков к конкретному элементу кодовой книги. Gumbel-Softmax, используемый для дифференцируемого сэмплирования дискретных токенов из кодовой книги, позволяет избежать проблем с недифференцируемостью, возникающих при обычном сэмплировании категориальных распределений, и обеспечивает стабильный поток градиентов в процессе обучения.
Дискретное представление данных, получаемое в VQ-VAE, обеспечивает более эффективное моделирование изображений за счет снижения вычислительной нагрузки и возможности генерации новых данных. Вместо работы с непрерывными векторами латентного пространства, VQ-VAE использует дискретный кодбук, что позволяет значительно уменьшить объем необходимых вычислений при кодировании и декодировании. Это особенно важно при работе с изображениями высокого разрешения или большими наборами данных. Дискретизация латентного пространства также упрощает вероятностное моделирование, позволяя использовать дискретные распределения, такие как категориальное, что в свою очередь, способствует улучшению генеративных возможностей модели и снижению требований к объему памяти. Таким образом, дискретное латентное пространство обеспечивает как вычислительную эффективность, так и повышение качества генерируемых изображений.
Гауссовская Квантизация: Эффективная Обучающая Стратегия
Гауссовская квантизация (GQ) представляет собой метод преобразования Гауссовой Вариационной Автокодирующей Сети (VAE) в VQ-VAE без необходимости переобучения модели. Этот подход позволяет значительно снизить вычислительные затраты, поскольку избегается трудоемкий процесс обучения дискретного кодового пространства. Суть метода заключается в применении квантования к латентному пространству VAE, что позволяет представить непрерывные значения в виде дискретных кодов. В отличие от традиционных методов, требующих обучения квантизатора с нуля, GQ использует уже обученную структуру VAE, что обеспечивает существенную экономию ресурсов и времени. Это делает GQ привлекательным решением для задач, требующих эффективного сжатия и восстановления данных, особенно в условиях ограниченных вычислительных мощностей.
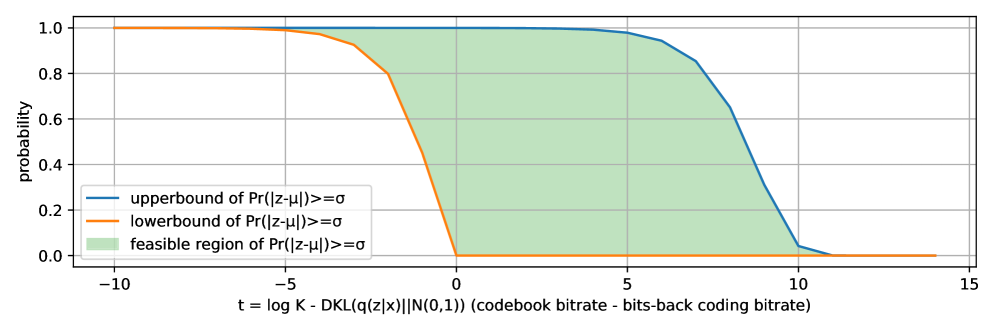
Гауссовская квантизация (GQ) оптимизирует процесс квантизации посредством использования расхождения Кульбака-Лейблера ($KL$ Divergence) и кодирования с возвратом битов (Bits-Back Coding). Данный подход минимизирует потерю информации при дискретизации, обеспечивая низкое значение $DKL$ — всего 0.00033 бит на пиксель. Применение расхождения Кульбака-Лейблера позволяет измерить разницу между непрерывным распределением и дискретным представлением, а кодирование с возвратом битов способствует более точному восстановлению данных после квантизации, что критически важно для сохранения качества изображения.
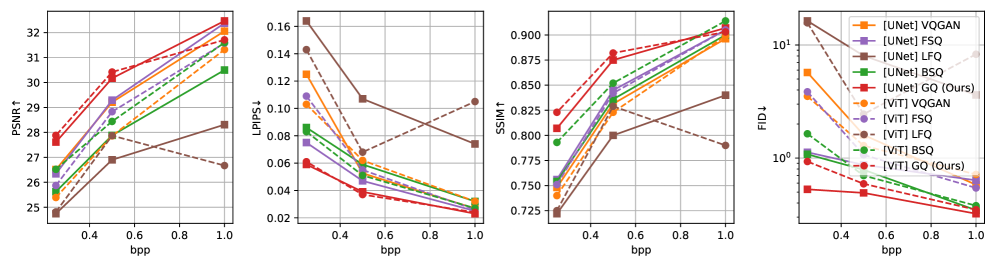
Применение ограничения целевого расхождения (Target Divergence Constraint, TDC) позволяет улучшить производительность квантования Гаусса (GQ) за счет усовершенствования процесса сопоставления распределений. Эксперименты на наборе данных ImageNet показали, что TDC превосходит альтернативные методы, такие как VQGAN, FSQ, LFQ и BSQ, достигая значения PSNR в 31.25 дБ и LPIPS в 0.372. Это свидетельствует о более эффективном сжатии и восстановлении изображений при использовании TDC в сочетании с GQ.

Оценка и Подтверждение: Дискретная Генерация Изображений
Исследования показали, что векторно-квантованные автоэнкодеры (VQ-VAE), дополненные алгоритмом Gumbel-Softmax квантования (GQ), демонстрируют впечатляющие результаты в задачах генерации изображений. Оценка качества с использованием метрик, таких как rFID и gFID, выявила, что полученные показатели сопоставимы с передовыми авторегрессионными моделями генерации, что свидетельствует о высокой эффективности предложенного подхода. Этот результат указывает на потенциал VQ-VAE с GQ как конкурентоспособной альтернативы существующим методам, позволяющей достигать сравнимого качества генерируемых изображений при иной архитектуре и подходе к моделированию.
Полученные дискретные представления открывают новые возможности для эффективного моделирования и генерации изображений, представляя собой убедительную альтернативу традиционным подходам. В отличие от непрерывных латентных пространств, используемых в классических вариационных автоэнкодерах, дискретизация позволяет существенно упростить процесс обучения и снизить вычислительные затраты. Это достигается за счет того, что модель оперирует с конечным набором дискретных символов, что облегчает моделирование сложных распределений данных. Более того, дискретное представление способствует улучшению качества генерируемых изображений, поскольку модель может более эффективно захватывать и воспроизводить ключевые визуальные характеристики. Таким образом, переход к дискретным представлениям знаменует собой важный шаг в развитии технологий генерации изображений, открывая путь к созданию более быстрых, эффективных и качественных моделей.
Использование архитектуры GQ с реализацией на CUDA позволило значительно ускорить процесс кодирования изображений. Достигнута скорость обработки в 80 кадров в секунду (FPS), что сопоставимо с производительностью оригинальных Гауссовых Вариационных Автоэнкодеров (VAE). Такое увеличение скорости делает дискретное представление изображений, полученное с помощью VQ-VAE и усовершенствованное GQ, практически применимым в задачах, требующих обработки изображений в реальном времени. Это открывает новые возможности для эффективного моделирования и генерации изображений, представляя собой перспективную альтернативу традиционным методам, особенно в контексте вычислительно-интенсивных приложений.

Исследование демонстрирует подход к векторной квантизации, напоминающий вскрытие сложного механизма. Авторы предлагают метод Gaussian Quant (GQ), позволяющий преобразовать Гауссовский Вариационный Автоэнкодер (VAE) в VQ-VAE без дополнительного обучения. Этот процесс, по сути, является реверс-инжинирингом латентного пространства, где ключевым моментом становится генерация кодовых книг и квантование среднего значения апостериорного распределения. Как однажды заметил Карл Фридрих Гаусс: «Я не знаю, как меня воспринимают, но мне кажется, что я обыкновенный человек». В данном исследовании обыкновенные методы, примененные к нестандартной задаче, привели к передовым результатам в области компромисса между скоростью передачи данных и искажениями, подтверждая, что даже в кажущемся хаосе можно найти элегантное решение, если тщательно изучить внутреннюю структуру системы.
Что дальше?
Представленный подход, по сути, демонстрирует, что даже кажущаяся фундаментальная необходимость в обучении может быть обойдена. Если система, основанная на вариационном автоэнкодере, способна к самовоспроизведению, то генерация кодебука, как и само понятие «обучения» в данном контексте, представляется скорее элегантным трюком, чем истинной необходимостью. Однако, возникает вопрос: насколько универсален этот «трюк»? Ограничения, связанные с гауссовским характером латентного пространства, требуют дальнейшего изучения. Что произойдет, если отказаться от этого предположения и рассмотреть более сложные распределения? Попытка расширить данный метод на не-гауссовские модели может потребовать пересмотра теоретических гарантий, но и открыть новые горизонты в области квантования.
Теоретическая гарантия, основанная на ограничении целевого расхождения, безусловно, важна, но она лишь описывает «безопасную зону». Практическая применимость метода в условиях зашумленных или неполных данных, а также его устойчивость к адверсарным атакам, остаются открытыми вопросами. Более того, оптимизация процесса генерации кодебука, особенно для больших и сложных наборов данных, может стать узким местом. Поиск более эффективных алгоритмов, возможно, основанных на принципах самоорганизующихся карт или других методов кластеризации, представляется перспективным направлением.
В конечном счете, представленная работа ставит под сомнение само понятие «обучения» в контексте квантования. Если система способна к самовоспроизведению, то её способность к адаптации и обобщению становится вторичной. Задача исследователя, по сути, заключается в том, чтобы найти «лазейку» в системе, а не в том, чтобы её «обучать». И, как показывает практика, именно такие «лазейки» часто оказываются наиболее интересными и эффективными.
Оригинал статьи: https://arxiv.org/pdf/2512.06609.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-09 14:55