Автор: Денис Аветисян
Новое исследование показывает, что даже экстремальное снижение точности весов в нейронных сетях может быть эффективным при грамотной оптимизации и использовании нелинейных методов квантования.
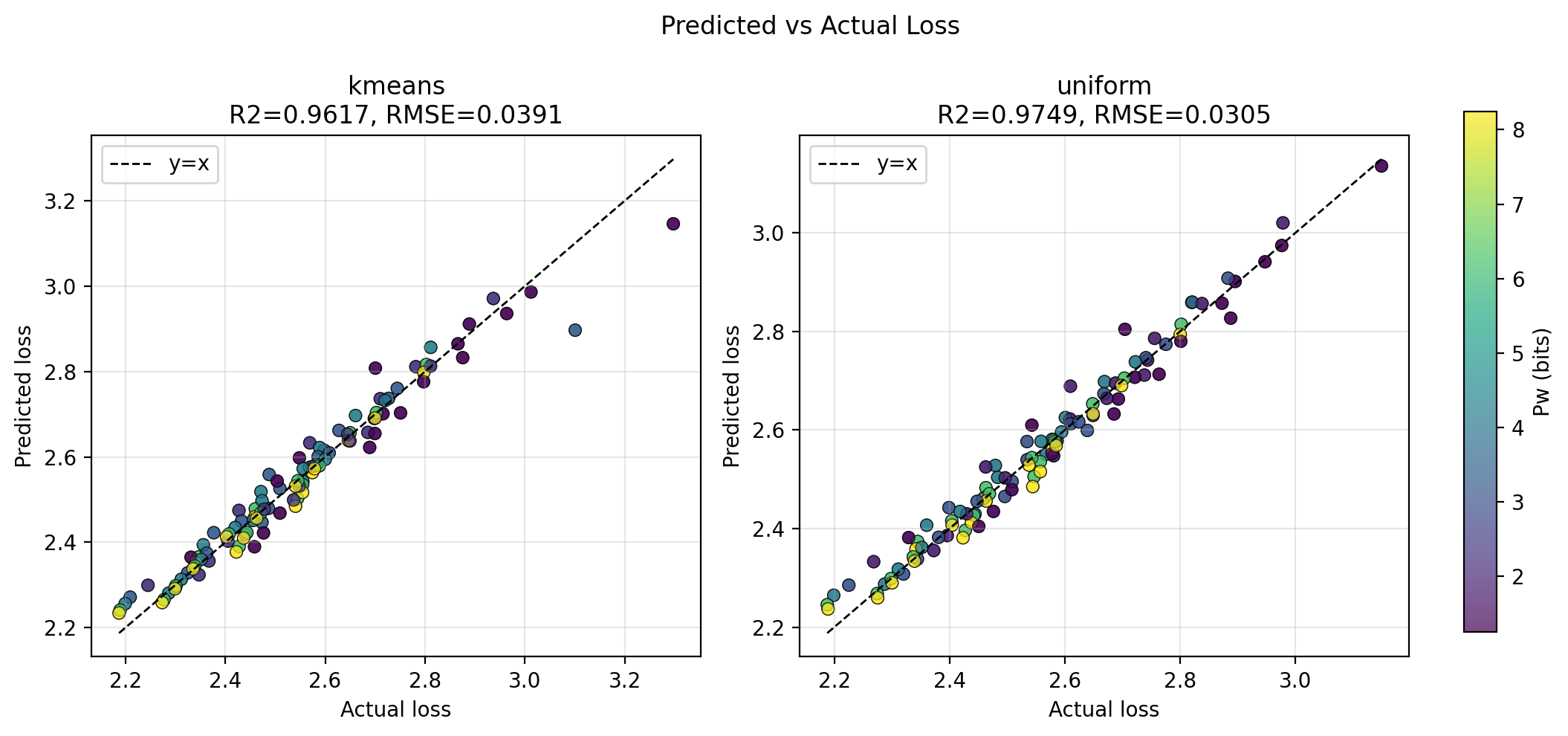
Применение K-Means квантования позволяет добиться сравнимой производительности больших языковых моделей при значительном снижении разрядности весов до 1 бита, оптимизируя использование памяти и пропускной способности.
Несмотря на эффективность обучения с учетом квантования (QAT) для снижения требований к памяти больших языковых моделей (LLM), оптимальный выбор формата квантования и разрядности остается сложной задачей. В данной работе, ‘1-Bit Wonder: Improving QAT Performance in the Low-Bit Regime through K-Means Quantization’, проведено эмпирическое исследование QAT в условиях низкой разрядности, демонстрирующее, что квантование весов на основе k-средних превосходит традиционные целочисленные форматы и может быть эффективно реализовано на стандартном оборудовании. Полученные результаты показывают, что при фиксированном бюджете памяти наилучшая производительность на генеративных задачах достигается при использовании весов, квантованных до 1 бита. Не является ли приоритет количества параметров над точностью ключом к дальнейшей оптимизации LLM и раскрытию их полного потенциала?
Точность как Предел: Вычислительные Ограничения Современных LLM
Современные большие языковые модели, такие как Llama 3, демонстрируют впечатляющие результаты благодаря авторегрессионному декодированию — процессу последовательного предсказания следующего слова в последовательности. Однако, эта выдающаяся производительность достигается ценой значительных вычислительных затрат, что создает серьезные препятствия для их широкого внедрения. Необходимость обработки огромного количества параметров и выполнения сложных вычислений при каждом шаге декодирования требует мощного оборудования и больших затрат энергии. В результате, развертывание и использование этих моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или периферийные серверы, становится крайне сложной задачей, ограничивая доступ к передовым возможностям обработки естественного языка.
Постоянный рост масштабов и сложности современных языковых моделей, таких как Llama 3, создает значительную нагрузку на пропускную способность памяти и вычислительные ресурсы. Это связано с тем, что обработка все большего объема данных и параметров требует экспоненциального увеличения вычислительной мощности, что ограничивает возможность их широкого применения. В результате, развертывание и использование этих моделей становится затруднительным для организаций и исследователей, не располагающих достаточными ресурсами, что замедляет прогресс в области искусственного интеллекта и ограничивает доступ к передовым технологиям обработки естественного языка. Особенно остро эта проблема проявляется при работе с устройствами с ограниченными ресурсами, такими как мобильные телефоны и встраиваемые системы.
Современные большие языковые модели, несмотря на впечатляющую производительность, часто используют избыточную точность представления данных. Традиционное 16-битное представление с плавающей точкой (Floating Point 16) может быть чрезмерным для многих операций, создавая возможности для оптимизации посредством квантования. Исследования показывают, что переход от 16-битных весов к 4-битным позволяет снизить размер модели примерно в 3.5 раза. Такое уменьшение не только экономит память и вычислительные ресурсы, но и открывает перспективы для развертывания сложных моделей на устройствах с ограниченными возможностями, расширяя область их применения и делая технологии обработки естественного языка более доступными.
Квантование с Учетом Обучения: Путь к Эффективности
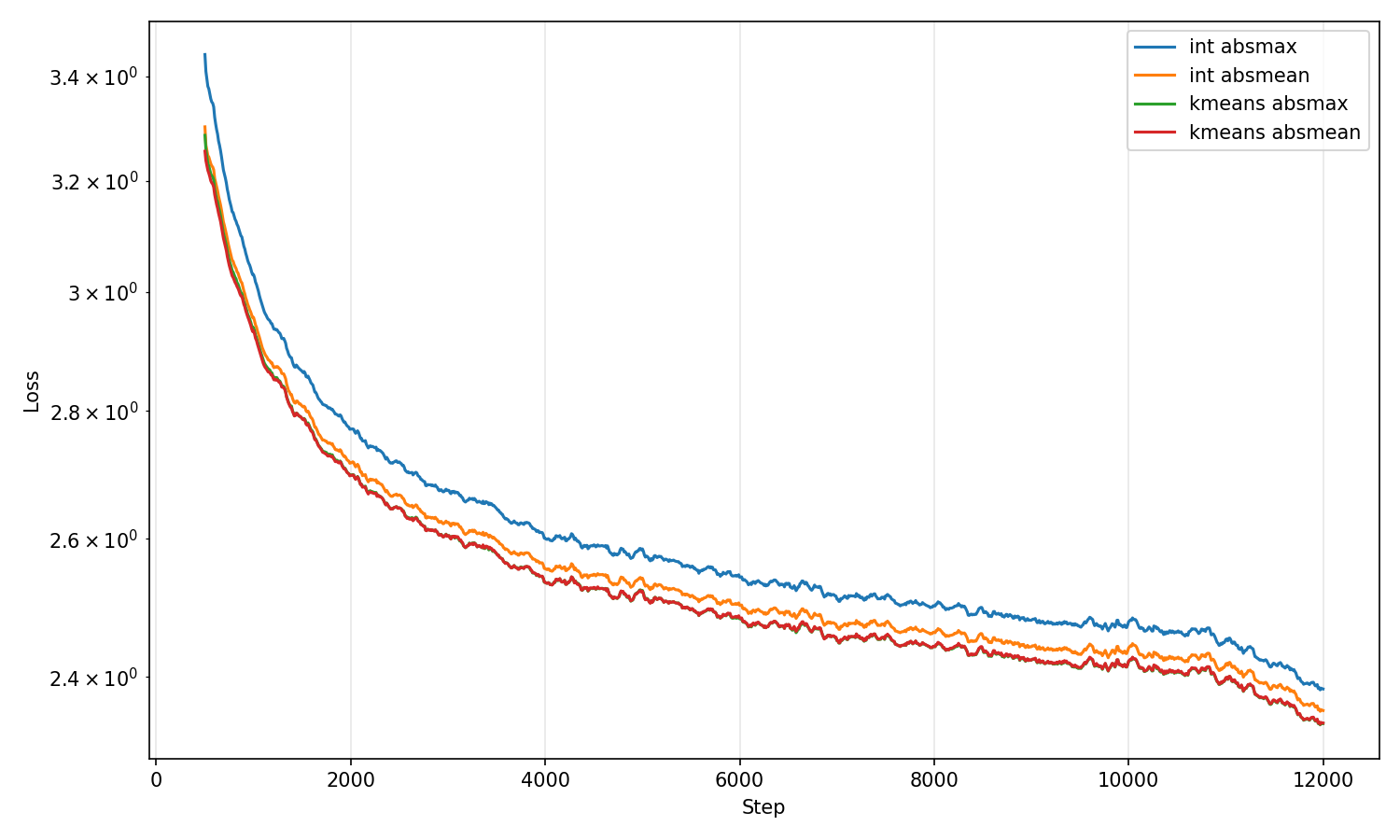
Квантизация, особенно с применением обучения с учетом квантизации (Quantization Aware Training, QAT), представляет собой перспективное решение для повышения эффективности моделей машинного обучения путем снижения разрядности представления весов. Вместо традиционного 32-битного представления с плавающей точкой (float32), веса могут быть представлены, например, 8-битным целым числом (int8). Это приводит к значительному уменьшению размера модели и снижению требований к вычислительным ресурсам и пропускной способности памяти. QAT отличается от пост-квантизации тем, что процесс квантизации учитывается во время обучения модели, что позволяет компенсировать потерю точности, возникающую из-за снижения разрядности. Это достигается путем симуляции эффектов квантизации в прямом и обратном проходах обучения, что позволяет градиентам адаптироваться к ограниченному диапазону значений, доступному в квантованном представлении.
Линейная квантизация, являясь одним из наиболее простых подходов к снижению точности весов модели, заключается в равномерном отображении вещественных чисел на ограниченный диапазон целочисленных значений. Однако, вследствие дискретизации, происходит потеря информации, что может приводить к существенному снижению точности модели. Для минимизации этого эффекта требуется тщательная калибровка, заключающаяся в определении оптимального диапазона квантования и масштабирующего фактора, обеспечивающих наилучшее соответствие между исходными и квантованными весами. Процесс калибровки обычно выполняется на репрезентативном подмножестве данных и направлен на минимизацию ошибки квантования, что критически важно для сохранения производительности модели после квантизации.
Нелинейные методы квантизации, такие как K-Means квантизация, обеспечивают более точное представление весов модели по сравнению с линейной квантизацией за счет адаптации к распределению весов. Вместо равномерного распределения уровней квантизации, K-Means алгоритм кластеризует веса, определяя оптимальные центроиды кластеров, которые и используются в качестве уровней квантизации. Это позволяет минимизировать ошибку квантизации, поскольку каждый вес отображается на ближайший центроид кластера, что приводит к более эффективному использованию доступных битов для представления весов и, как следствие, к снижению потерь точности по сравнению с равномерной квантизацией. Такой подход особенно эффективен для моделей с неравномерным распределением весов.
Оценка влияния квантизации на фактическую вычислительную мощность модели требует анализа эффективной ёмкости, а не только количества параметров. Простое уменьшение разрядности весов может привести к снижению производительности, если не учитывать способность модели к обобщению. Эффективная ёмкость отражает количество действительно используемых параметров, учитывая их вклад в функцию потерь и способность модели адаптироваться к данным. Для точной оценки необходимо измерять производительность модели на валидационных данных после квантизации и сравнивать её с исходной моделью, используя метрики, отражающие способность к обобщению, такие как точность или F1-мера. Учёт эффективной ёмкости позволяет более корректно оценить компромисс между снижением размера модели и сохранением её производительности.
Оптимизация Инференса с Продвинутыми Методами
Оптимизация инференса использует такие методы, как блочное масштабирование (Block Scaling), для дальнейшей тонкой настройки квантованных весов. Данный подход позволяет повысить точность представления весов после квантизации и, как следствие, снизить вычислительные затраты. Блочное масштабирование заключается в применении различных коэффициентов масштабирования к отдельным блокам весов, что позволяет минимизировать потерю информации при переходе к пониженной точности. Это особенно важно при использовании экстремальной квантизации, например, до 4 бит, где стандартные методы квантизации могут приводить к значительной деградации производительности. Применение блочного масштабирования позволяет добиться более высокой точности и эффективности, сохраняя преимущества, связанные со снижением вычислительной сложности и требований к памяти.
Таблицы поиска (Lookup Tables, LUT) являются критически важным компонентом при использовании квантованных весов, обеспечивая быстрое восстановление исходных значений (декодирование). При квантовании весов для уменьшения объема памяти и вычислительной нагрузки, возникает необходимость в обратном преобразовании (декодировании) при выполнении вычислений. LUT представляют собой предварительно вычисленные значения декодированных весов, которые хранятся в памяти и извлекаются значительно быстрее, чем выполнение вычислений декодирования «на лету». Это позволяет минимизировать накладные расходы, связанные со снижением точности, и существенно ускорить процесс инференса, особенно в задачах, требующих высокой пропускной способности.
Параллелизация вычислений с использованием метода Model Parallelism позволяет распределить нагрузку по нескольким графическим процессорам (GPU), существенно ускоряя процесс инференса. Оптимизация выполнения на платформах, таких как CUDA, обеспечивает эффективное использование аппаратных ресурсов NVIDIA. CUDA предоставляет низкоуровневый доступ к GPU, позволяя реализовать специализированные алгоритмы и максимизировать пропускную способность. Комбинация Model Parallelism и CUDA позволяет обрабатывать большие модели и пакеты данных параллельно, что приводит к значительному увеличению скорости инференса и снижению задержки.
Размер пакета (batch size) оказывает существенное влияние на использование пропускной способности памяти и общую пропускную способность вычислений. Исследование показало, что 4-битная модель с 12 миллиардами параметров демонстрирует сопоставимую производительность с 16-битной моделью с 44 миллиардами параметров в условиях, когда производительность ограничена пропускной способностью памяти. При оптимальном размере пакета 4-битная модель достигает почти идеального уровня использования пропускной способности памяти, что позволяет компенсировать разницу в количестве параметров и обеспечить сопоставимую скорость обработки данных.
Законы Масштабирования и Будущее Квантованных LLM
Законы масштабирования предоставляют мощную основу для прогнозирования производительности языковых моделей, основываясь на трёх ключевых факторах: размере модели, объеме обучающих данных и объеме вычислений. Эти законы не просто описывают общую тенденцию улучшения с увеличением ресурсов, но и позволяют предсказывать конкретные показатели, такие как точность и скорость работы. В последнее время, исследования показали, что влияние квантизации — процесса снижения точности представления чисел в модели — также может быть учтено в этих законах, через понятие “эффективной ёмкости”. Квантизация, хотя и снижает вычислительные затраты и требования к памяти, может приводить к потере информации. Поэтому, корректный учёт её влияния в рамках законов масштабирования позволяет разработчикам оптимизировать модели, добиваясь оптимального баланса между точностью и эффективностью, и предсказывать, как снижение точности повлияет на общую производительность.
Понимание влияния квантования на закономерности масштабирования позволяет целенаправленно разрабатывать модели, достигающие оптимальной производительности при пониженной точности представления данных. Исследования показывают, что снижение разрядности, например, до 4 бит, не обязательно ведет к пропорциональному снижению качества работы. Вместо этого, тщательно адаптируя архитектуру и процесс обучения с учетом квантования, можно компенсировать потерю точности и сохранить, а в некоторых случаях даже улучшить, эффективность модели. Этот подход позволяет создавать более компактные и энергоэффективные модели, пригодные для развертывания на устройствах с ограниченными ресурсами, сохраняя при этом высокий уровень производительности, сопоставимый с более крупными и требовательными к ресурсам аналогами.
Возможность развертывания мощных языковых моделей на устройствах с ограниченными ресурсами открывает новые перспективы для широкого спектра приложений. Ранее сложные вычисления, требующие значительных вычислительных мощностей и памяти, становятся доступными на смартфонах, встроенных системах и других периферийных устройствах. Это позволяет реализовать локальную обработку данных, повышая конфиденциальность и снижая задержки, что критически важно для таких задач, как голосовые помощники, машинный перевод в реальном времени и персонализированные рекомендации. Разработка и оптимизация квантованных моделей, в сочетании с аппаратным ускорением, является ключевым фактором для достижения этой цели, позволяя создавать более эффективные и доступные системы искусственного интеллекта для широкой аудитории.
Продолжающиеся исследования в области продвинутых техник квантования и аппаратного ускорения открывают перспективы для создания более эффективного и доступного искусственного интеллекта. Наблюдается, что модель размером 12 миллиардов параметров, использующая 4-битное квантование, демонстрирует лишь приблизительно 10%-ное снижение скорости работы по сравнению с 16-битной 44-миллиардной моделью. Несмотря на это небольшое замедление, выигрыш в эффективности, связанный со снижением точности вычислений, является значительным и позволяет развертывать мощные языковые модели на устройствах с ограниченными ресурсами. Дальнейшее развитие этих направлений позволит существенно расширить возможности применения искусственного интеллекта и сделать его более доступным для широкого круга пользователей и разработчиков.
Исследование демонстрирует, что агрессивная квантизация, даже до 1-битных весов, не обязательно приводит к существенной потере производительности, если правильно оптимизировать аппаратное обеспечение и использовать нелинейные методы квантизации. Этот подход подчеркивает важность баланса между количеством параметров и точностью представления, что согласуется с принципом математической чистоты кода. Как однажды заметил Дональд Дэвис: «Простота — это высшая сложность». Это высказывание отражает суть представленной работы, где стремление к упрощению, через снижение разрядности весов, требует изысканных алгоритмических решений для поддержания необходимой точности и эффективности, что, в свою очередь, повышает доказуемость и предсказуемость системы.
Куда же дальше?
Представленная работа, демонстрируя жизнеспособность агрессивной квантизации, неизбежно ставит вопрос о границах разумного. Утверждение о приоритете количества параметров над точностью — это не просто инженерный трюк, а, скорее, признание фундаментального ограничения: истинная сложность системы определяется не столько числом бит, сколько архитектурой связей. Однако, упрощение весов до единичного бита, хоть и заманчиво, поднимает вопрос о стабильности обучения и, что более важно, о доказательстве сходимости алгоритма. Достаточно ли эмпирических данных, или требуется строгое математическое обоснование?
Необходимо признать, что оптимизация под конкретное аппаратное обеспечение — это всегда компромисс. Увеличение пропускной способности памяти за счет снижения точности весов — решение прагматичное, но далеко не элегантное. Следующим шагом представляется разработка алгоритмов квантизации, устойчивых к изменениям архитектуры и не требующих тонкой настройки под каждую новую модель. Иначе, мы обречены на бесконечную гонку за оптимизацией, а не на достижение истинного понимания.
В конечном счете, данное исследование подчеркивает, что ключ к эффективному выводу — это не столько снижение точности, сколько выявление и устранение избыточности. Если мы действительно стремимся к созданию интеллектуальных систем, необходимо сосредоточиться на разработке алгоритмов, способных к самообучению и адаптации, а не на искусственном снижении вычислительных затрат. Иначе, мы рискуем создать лишь иллюзию интеллекта, основанную на статистической оптимизации.
Оригинал статьи: https://arxiv.org/pdf/2602.15563.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Искусственный интеллект и квантовая физика: кто кого?
- Взрыв скорости: Оптимизация внимания для современных GPU
- Знаем, чего не знаем: Моделирование вероятностных рассуждений на основе множественных доказательств
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Языковые модели и границы возможного: что делает язык человеческим?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Память на заказ: Как обучить агентов взаимодействовать эффективнее
- Роботы учатся действовать, наблюдая за миром
2026-02-18 14:37