Автор: Денис Аветисян
Новое исследование демонстрирует возможности машинного обучения в автоматизации создания квантовых схем для достижения целевых квантовых состояний.
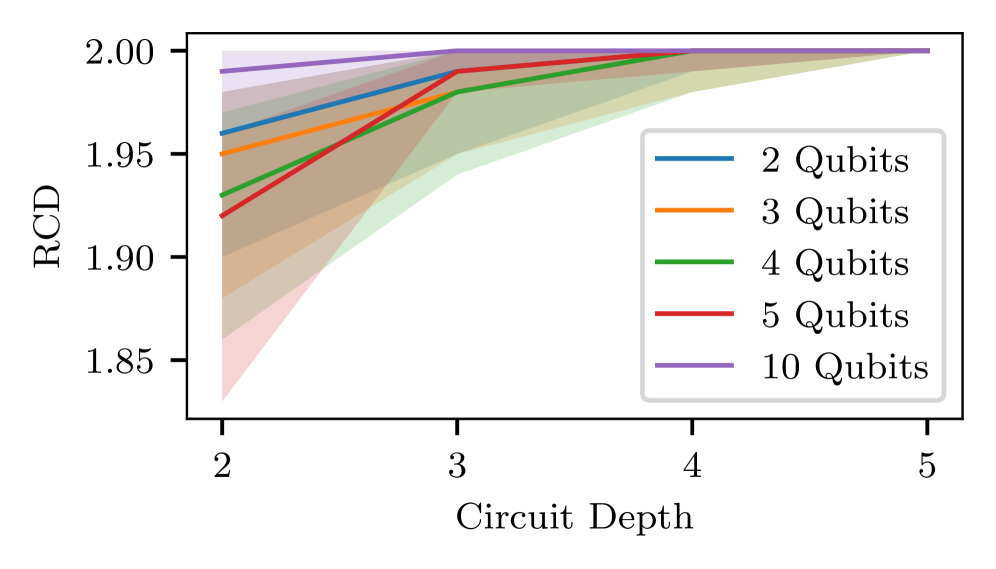
Сравнительный анализ алгоритмов обучения с подкреплением для синтеза параметрических квантовых цепей, выявляющий ограничения масштабируемости и требующие улучшения методов оптимизации.
Несмотря на значительный прогресс в области квантовых вычислений, эффективный синтез параметризованных квантовых состояний остается сложной задачей. В работе «Reinforcement Learning for Parameterized Quantum State Preparation: A Comparative Study» предложен подход, расширяющий метод направленного синтеза квантовых схем (DQCS) с использованием обучения с подкреплением для непрерывной оптимизации однокубитных вращений R_x, R_y и R_z. Исследование сравнивает одно- и двухэтапные стратегии обучения, демонстрируя, что одноэтапный алгоритм PPO обеспечивает надежную реконструкцию базовых и колоколообразных состояний, однако масштабируемость ограничена сложностью и запутанностью систем. Какие новые методы обучения и оптимизации позволят преодолеть эти ограничения и реализовать потенциал квантовых вычислений в задачах подготовки сложных квантовых состояний?
Элегантность в Сложности: Задача Квантового Проектирования
Разработка эффективных квантовых схем является ключевым фактором для реализации потенциала квантовых вычислений, однако представляет собой сложную задачу. Суть проблемы заключается в экспоненциальном росте сложности при увеличении числа кубитов, что делает поиск оптимальных решений чрезвычайно трудоемким. Традиционные методы проектирования схем, успешно применяемые в классической электронике, оказываются неэффективными в квантовой области из-за принципиальных отличий в природе квантовых систем и необходимости учета таких явлений, как суперпозиция и запутанность. Поиск оптимальной квантовой схемы требует не только минимизации количества необходимых квантовых операций, но и учета особенностей конкретной квантовой платформы, чтобы обеспечить ее физическую реализуемость и устойчивость к ошибкам. В связи с этим, разработка новых алгоритмов и методологий проектирования квантовых схем является одной из центральных задач современной квантовой информатики, определяющей перспективы создания практически полезных квантовых компьютеров.
Традиционные методы разработки квантовых схем сталкиваются с экспоненциальным ростом сложности при увеличении числа кубитов, что делает поиск оптимальных решений крайне затруднительным. Пространство возможных схем быстро становится непомерно большим, требуя огромных вычислительных ресурсов для их анализа и оптимизации. Более того, существующие алгоритмы часто не учитывают специфические ограничения и особенности конкретного квантового оборудования, что приводит к созданию схем, которые теоретически эффективны, но трудно реализуемы на практике. Необходимость создания схем, адаптированных к конкретным аппаратным платформам и минимизирующим потребление ресурсов, представляет собой серьезную проблему, требующую разработки новых подходов и инструментов для автоматизированного проектирования квантовых схем.
Обучение с Подкреплением: Автоматизация Квантового Синтеза
Обучение с подкреплением (RL) представляет собой перспективный подход к автоматизации проектирования квантовых схем. В отличие от традиционных методов, требующих ручного определения последовательности операций, RL позволяет агенту самостоятельно изучать оптимальные стратегии построения схем путем взаимодействия со средой. Этот процесс включает в себя определение пространства состояний, представляющего текущую конфигурацию квантовой системы, пространства действий, включающего допустимые квантовые операции, и функции вознаграждения, оценивающей близость текущей конфигурации к целевому состоянию. Агент, используя алгоритмы RL, такие как Q-learning или Policy Gradient, стремится максимизировать суммарное вознаграждение, тем самым оптимизируя структуру квантовой схемы для достижения заданных целей. Такой подход особенно полезен для задач, где аналитическое решение затруднено или невозможно, а также для поиска нетривиальных и эффективных схем.
В контексте синтеза квантовых схем, применение обучения с подкреплением (RL) предполагает моделирование процесса построения схемы как последовательного процесса принятия решений. Агент RL, взаимодействуя со средой (симулятором квантовой схемы), последовательно выбирает операции (например, применение квантовых гейтов) для изменения состояния квантовой системы. Каждое действие агента приводит к изменению состояния и получению вознаграждения, зависящего от близости текущего состояния к целевому. Агент обучается максимизировать суммарное вознаграждение, что приводит к построению квантовой схемы, которая с высокой вероятностью достигает желаемого целевого состояния, определяемого задачей.
Для построения и моделирования сред обучения с подкреплением (RL) в контексте синтеза квантовых схем используются инструменты из пакетов Gymnasium и PennyLane. Gymnasium предоставляет гибкую платформу для создания пользовательских сред RL, позволяя определять пространство состояний, действия и функции вознаграждения, специфичные для задачи синтеза квантовых схем. PennyLane, в свою очередь, является библиотекой для дифференцируемого программирования квантовых вычислений и обеспечивает эффективное моделирование квантовых схем, необходимых для оценки производительности агента RL и расчета вознаграждений. Комбинация этих двух библиотек позволяет исследователям и разработчикам создавать комплексные среды RL, в которых агенты могут обучаться оптимальным стратегиям для синтеза квантовых схем, удовлетворяющих заданным критериям.
Архитектуры Агентов: Одношаговый и Двухшаговый Подходы
Исследовались две различные архитектуры агентов для синтеза квантовых схем. Одноступенчатый агент непосредственно выбирает гейты и параметры схемы, осуществляя синтез за один шаг. В отличие от него, двухступенчатый агент функционирует в два этапа: сначала он предлагает топологию схемы (структуру связей между гейтами), а затем уточняет параметры этой топологии для достижения оптимальной производительности. Такой подход позволяет разделить задачу синтеза на этапы проектирования структуры и оптимизации параметров, что потенциально повышает эффективность поиска оптимальных схем.
Двухэтапный агент использует оптимизатор Adam для точной настройки параметров квантовых схем после определения их топологии. Процесс оптимизации направляется правилом сдвига параметров (Parameter-Shift Rule), которое позволяет эффективно вычислять градиенты целевой функции относительно параметров схемы. Данный метод, основанный на оценке производных функции потерь путем небольших изменений параметров, обеспечивает градиентный спуск в пространстве параметров, минимизируя функцию потерь и максимизируя производительность схемы. Применение Adam в сочетании с правилом сдвига параметров позволяет агенту быстро и эффективно находить оптимальные значения параметров для предложенной топологии схемы.
Для обучения обеих архитектур агентов — одностадийной и двухстадийной — использовался алгоритм Proximal Policy Optimization (PPO), обеспечивающий эффективное исследование и использование пространства поиска. Экспериментальные результаты показали, что одностадийный агент, обученный с использованием PPO, успешно осваивает синтез квантовых схем для подготовки состояний. В частности, агент надежно воспроизводит базисные и колоколообразные состояния до 5 кубитов при ограничении на глубину схемы λ ≤ 3-4. Это демонстрирует способность агента к эффективной оптимизации параметров схем и генерации квантовых цепей заданной сложности.
Оценка Производительности и Перспективы Развития
Для оценки качества генерируемых квантовых состояний применяются метрики, такие как ошибка самосогласованности (Self-Fidelity Error), предоставляющие количественную меру эффективности работы квантовых схем. Данный показатель позволяет определить, насколько точно полученное состояние соответствует желаемому, и служит ключевым инструментом для оптимизации параметров схемы и выявления источников ошибок. Высокое значение ошибки самосогласованности указывает на значительное отклонение от целевого состояния, требующее дальнейшей калибровки и совершенствования алгоритмов управления квантовыми битами. В контексте исследования, использование данной метрики позволило объективно сравнить производительность различных подходов к оптимизации схем и продемонстрировать превосходство разработанного агента на основе алгоритма PPO над классическими вариационными методами.
В основе конструирования квантовых схем лежат элементарные логические операции, известные как квантовые гейты. В данном исследовании ключевую роль играют гейты Rx, Ry, Rz, отвечающие за вращение состояния кубита вокруг соответствующих осей, и CNOT, выполняющий управляемое отрицание, необходимую операцию для создания запутанности. Комбинация этих базовых гейтов определяет пространство состояний, которое может быть достигнуто схемой. Именно выбор и последовательность применения Rx, Ry, Rz и CNOT предопределяют сложность и функциональность квантовой цепи, а также её способность реализовывать конкретные квантовые алгоритмы или моделировать физические системы. Таким образом, понимание влияния этих фундаментальных блоков на результирующее квантовое состояние является критически важным для разработки эффективных и точных квантовых вычислений.
Эксперименты показали, что агент на основе алгоритма PPO, работающий в одношаговом режиме, демонстрирует впечатляющие показатели успешности — от 83 до 99% при генерации двухкубитных базисных состояний и от 61 до 77% для состояний Белла, при значениях параметра λ в диапазоне от 1 до 5. В ходе сравнения с классическим вариационным методом, одношаговый агент PPO превзошел его, достигнув более высокой точности — выше 0.31 — на десяти случайных двухкубитных целевых состояниях при глубине цепи L=4. При этом, переход к двухшаговой стратегии потребовал примерно в три раза больше вычислительного времени, однако не привел к существенному улучшению производительности, что указывает на эффективность одношагового подхода для оптимизации квантовых схем.
Исследование, представленное в статье, демонстрирует, что обучение с подкреплением способно эффективно решать задачу синтеза параметрических квантовых схем. Однако, сложность и запутанность квантовых состояний быстро становятся ограничивающим фактором для масштабируемости. В этой связи, слова Линуса Торвальдса особенно актуальны: «Если у вас есть проблема, которую можно решить с помощью кода, то это не проблема, а особенность». Подобно тому, как разработчик сталкивается с ограничениями вычислительных ресурсов, авторы статьи сталкиваются с экспоненциальным ростом сложности квантовых систем. Необходимость улучшения методов исследования и оптимизации становится очевидной, чтобы преодолеть эти «особенности» и приблизиться к созданию масштабируемых квантовых алгоритмов.
Что Дальше?
Представленная работа, демонстрируя возможность обучения синтезу параметризованных квантовых схем с использованием обучения с подкреплением, лишь подчеркивает фундаментальную сложность задачи. Достигнутый успех, хоть и значим, оказывается ограниченным масштабируемостью, что неудивительно. Ведь любое приближение, основанное на эвристиках, неизбежно сталкивается с границами, диктуемыми экспоненциальным ростом сложности с увеличением числа кубитов и степени запутанности. Напоминает попытку построить Вавилонскую башню — каждая добавленная ступень лишь усугубляет нестабильность конструкции.
Будущие исследования должны быть сосредоточены не на смягчении симптомов, а на поиске более элегантных и доказуемо сходящихся алгоритмов. Необходимы методы, позволяющие эффективно исследовать пространство параметров, избегая застревания в локальных оптимумах. Использование градиентных методов, возможно, в сочетании с обучением с подкреплением, представляется перспективным направлением, однако и здесь требуется строгое математическое обоснование, а не эмпирическая проверка на ограниченном наборе тестовых примеров.
В конечном счете, истинный прогресс в данной области будет достигнут лишь тогда, когда удастся отойти от компромиссов и найти алгоритмы, гарантирующие оптимальное решение, а не просто «достаточно хорошее» для практического применения. Иначе, квантовые вычисления рискуют остаться впечатляющей, но в конечном итоге несостоятельной математической игрой.
Оригинал статьи: https://arxiv.org/pdf/2602.16523.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Искусственный интеллект и квантовая физика: кто кого?
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Саморедактирование научных статей: новый взгляд на качество и влияние
- Искусственный интеллект осваивает встраиваемые системы: новый подход к обучению
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Ядро молекулы под наблюдением: новый взгляд на спектроскопию
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
2026-02-19 17:33