Автор: Денис Аветисян
Новое исследование систематически сравнивает методы снижения размерности данных, чтобы оптимизировать работу квантовых алгоритмов машинного обучения в задачах анализа данных физики высоких энергий.
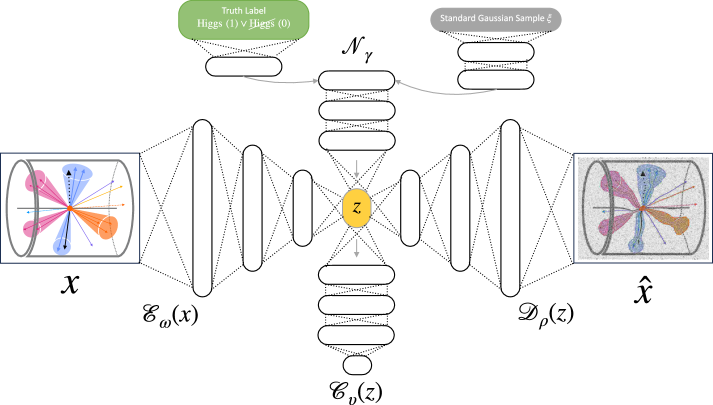
В статье проводится оценка различных методов снижения размерности, включая новый Sinkhorn Autoencoder, для повышения производительности квантовых SVM на высокоразмерных данных.
Вычислительные ограничения квантовых алгоритмов машинного обучения становятся препятствием при работе с данными высокой размерности. В работе ‘Learning Reduced Representations for Quantum Classifiers’ систематически исследуются и сравниваются различные методы понижения размерности, включая разработанный автокодировщик Sinkclass, для повышения эффективности квантовых машин опорных векторов в задачах классификации частиц высоких энергий. Полученные результаты демонстрируют, что грамотное понижение размерности позволяет значительно улучшить производительность квантовых алгоритмов, при этом предложенный автокодировщик превосходит базовые модели на 40%. Какие еще инновационные подходы к понижению размерности могут открыть путь к более широкому применению квантового машинного обучения в различных областях науки и техники?
Высокоразмерные Данные: Вызов для Анализа
Современные наборы данных, особенно данные, получаемые в физике высоких энергий ($HighEnergyPhysicsData$), характеризуются чрезвычайно высокой размерностью, что создает серьезные трудности для традиционных методов анализа. Каждый эксперимент в этой области генерирует огромное количество параметров, описывающих траектории частиц, энергии и другие характеристики, что приводит к пространствам данных с тысячами и даже миллионами измерений. Традиционные алгоритмы, разработанные для работы с данными меньшей размерности, часто оказываются неэффективными или требуют неприемлемо больших вычислительных ресурсов для обработки таких сложных наборов. Это затрудняет выявление скрытых закономерностей, аномалий и новых физических явлений, требуя разработки инновационных подходов к обработке и анализу данных, способных эффективно справляться с проблемой высокой размерности.
Высокая размерность современных наборов данных, таких как данные высокоэнергетической физики, представляет значительные трудности для извлечения значимых признаков и распознавания закономерностей. Традиционные методы анализа часто оказываются неэффективными при работе с огромным количеством параметров, что требует разработки новых подходов к представлению данных. Успешное решение этой задачи предполагает не просто уменьшение размерности, но и сохранение ключевой информации, заключенной в данных, для обеспечения точности и надежности результатов. Исследователи активно изучают методы, позволяющие эффективно кодировать данные в более компактном виде, минимизируя потери информации и повышая производительность алгоритмов анализа, что открывает возможности для обнаружения скрытых взаимосвязей и углубленного понимания сложных систем.
Существующие методы снижения размерности данных, применяемые к сложным наборам, таким как данные высокоэнергетической физики, часто сталкиваются с проблемой сохранения информационной целостности. Процесс уменьшения количества признаков неизбежно приводит к потере части информации, что может существенно исказить результаты анализа и привести к смещенным или неточным выводам. Например, при использовании методов, основанных на главных компонентах ($PCA$), незначительные, но важные сигналы могут быть подавлены при выделении лишь наиболее значимых компонент. Это особенно критично в областях, где даже небольшие отклонения могут указывать на новые физические явления или закономерности. В результате, анализ данных, основанный на сниженной размерности, может упустить важные детали или создать ложные корреляции, что требует разработки более совершенных алгоритмов, способных минимизировать потерю информации и обеспечивать надежные результаты.
Классические Методы Снижения Размерности: Основы и Ограничения
Методы снижения размерности, такие как $PCA$ (Principal Component Analysis), $ICA$ (Independent Component Analysis) и $NMF$ (Non-Negative Matrix Factorization), являются хорошо зарекомендовавшими себя подходами к уменьшению вычислительной сложности и визуализации многомерных данных. $PCA$ использует ортогональные преобразования для выявления направлений максимальной дисперсии, $ICA$ стремится разделить данные на статистически независимые компоненты, а $NMF$ разлагает матрицу данных на неотрицательные матрицы, что обеспечивает интерпретируемость результатов. Все три метода широко применяются в различных областях, включая обработку изображений, анализ сигналов и машинное обучение, благодаря своей эффективности и относительной простоте реализации.
Методы снижения размерности, такие как анализ главных компонент (PCA), анализ независимых компонент (ICA) и неотрицательная матричная факторизация (NMF), эффективно выявляют основные дисперсии в данных и формируют представления меньшей размерности на основе статистических свойств. PCA, например, максимизирует дисперсию данных вдоль последовательных главных компонент, позволяя отбросить компоненты с минимальной дисперсией. ICA стремится выделить статистически независимые компоненты, что полезно для разделения смешанных сигналов. NMF, в свою очередь, использует неотрицательные ограничения, обеспечивая интерпретируемость полученных факторов. В каждом случае, снижение размерности достигается путем представления данных в новом пространстве, где ключевые статистические характеристики исходных данных сохраняются, а шум и избыточность уменьшаются.
Классические методы понижения размерности, такие как анализ главных компонент (PCA), анализ независимых компонент (ICA) и не-отрицательная матричная факторизация (NMF), часто базируются на линейных предположениях о данных. Это означает, что они эффективно работают только в случаях, когда взаимосвязи между признаками можно апроксимировать линейными функциями. В ситуациях, когда данные обладают сложной, нелинейной структурой, эти методы могут значительно терять информацию. Кроме того, они склонны не сохранять локальную структуру данных — то есть, близкие точки в исходном пространстве могут оказываться далеко друг от друга в пониженном пространстве, что негативно влияет на задачи классификации и кластеризации. Это особенно актуально для данных высокой размерности, где нелинейные эффекты становятся более выраженными.
Методы, такие как Локально-Линейное Вложение (Locally Linear Embedding, LLE) и Спектральное Вложение (Spectral Embedding), направлены на преодоление ограничений классических методов понижения размерности, связанных с сохранением локальной структуры данных. LLE предполагает, что каждая точка данных может быть реконструирована как линейная комбинация своих ближайших соседей, и стремится сохранить эти локальные отношения в пространстве пониженной размерности. Спектральное вложение, в свою очередь, использует собственные векторы матрицы сходства для определения координат точек в новом пространстве, что позволяет эффективно сохранять как локальные, так и глобальные свойства данных, особенно в случаях, когда данные лежат на нелинейном многообразии. Оба подхода стремятся минимизировать искажения при отображении данных в пространство меньшей размерности, акцентируя внимание на поддержании связей между близлежащими точками данных.
Автоэнкодеры: Обучение Эффективным Представлениям Данных
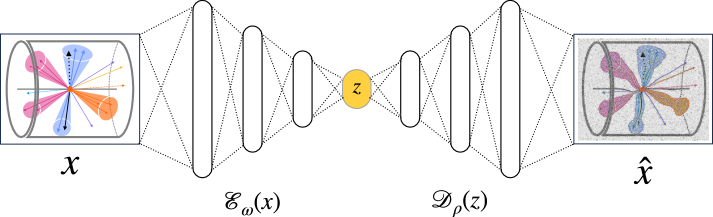
Автоэнкодеры (Autoencoder) представляют собой нейронные сети, предназначенные для обучения сжатым представлениям данных. Базовая архитектура, известная как “vanilla” автоэнкодер, состоит из двух основных компонентов: энкодера и декодера. Энкодер принимает входные данные и преобразует их в представление меньшей размерности — латентное пространство (latent space). Декодер, в свою очередь, реконструирует исходные данные из этого сжатого представления. Обучение происходит путем минимизации ошибки реконструкции, то есть разницы между исходными данными и их реконструкцией. Такой подход позволяет выделить наиболее значимые признаки данных и создать эффективное представление для дальнейшего анализа или использования в других моделях машинного обучения.
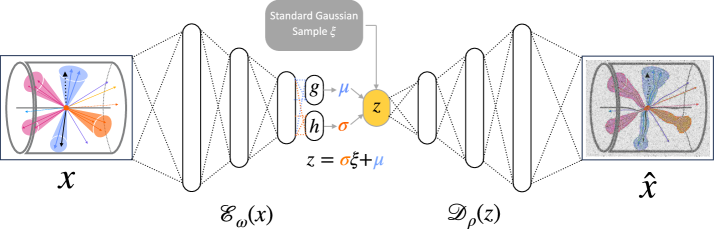
Вариационные автокодировщики (VAE) отличаются от традиционных автокодировщиков тем, что обучают вероятностное латентное пространство. Вместо того, чтобы кодировать входные данные в фиксированный вектор, VAE кодируют их в распределение вероятностей, обычно нормальное распределение, определяемое средним значением и дисперсией. Это позволяет генерировать новые данные, отбирая значения из этого распределения, что делает VAE полезными для задач генеративного моделирования. Кроме того, вероятностный подход действует как форма регуляризации, предотвращая переобучение и улучшая обобщающую способность модели, за счет введения априорного распределения на латентное пространство, которое ограничивает возможные представления данных.
Помимо базовых автоэнкодеров, существуют специализированные архитектуры, такие как классификационные автоэнкодеры, оптимизированные для задач классификации. Особое внимание в исследовании уделено автоэнкодерам Sinkhorn (SAE), использующим $WassersteinDistance$ для регуляризации латентного пространства и повышения стабильности обучения. Результаты показали, что SAE демонстрирует наилучшую производительность при подготовке данных для классификатора на основе квантовой машины опорных векторов (QSVM), достигая значения Area Under the Curve (AUC) равного 0.6, что превосходит показатели других рассмотренных архитектур автоэнкодеров.
Целью использования автокодировщиков является формирование осмысленного $LatentSpace$, который содержит ключевую информацию об исходных данных, обеспечивая эффективный анализ и реконструкцию. В ходе исследований было установлено, что применение Sinkhorn Autoencoder (SAE) позволило достичь показателя Area Under the Curve (AUC) в 0.6, что превосходит результаты, полученные с использованием других архитектур автокодировщиков. Это указывает на более эффективное представление данных в $LatentSpace$ и, как следствие, улучшенные возможности для последующей обработки и классификации.
Квантовое Машинное Обучение: Новые Горизонты Снижения Размерности
Квантовое машинное обучение представляет собой перспективное направление, способное радикально изменить подходы к снижению размерности данных. В отличие от классических алгоритмов, использующих биты для представления информации, квантовые алгоритмы оперируют с кубитами, которые благодаря явлениям суперпозиции и запутанности позволяют обрабатывать экспоненциально больший объем информации. Это открывает возможности для создания алгоритмов, способных эффективно работать с высокоразмерными данными, в которых классические методы сталкиваются с вычислительными ограничениями и проблемами масштабируемости. Использование квантовых свойств для построения более эффективных алгоритмов снижения размерности может привести к значительному улучшению производительности в задачах анализа данных, классификации и прогнозирования, особенно в областях, где данные характеризуются высокой сложностью и многомерностью.
Квантовые машины опорных векторов (QSVM) представляют собой перспективный подход к снижению размерности данных, особенно в задачах, связанных с высокоразмерными пространствами признаков. В отличие от классических SVM, QSVM используют квантовые ядра, которые позволяют эффективно вычислять скалярные произведения между векторами в квантовом пространстве состояний. Это, в свою очередь, позволяет выявлять нелинейные зависимости в данных, которые могут быть упущены классическими методами. Использование квантовых ядер может значительно ускорить процесс обучения и повысить точность классификации, особенно в случаях, когда данные характеризуются высокой сложностью и большим количеством признаков. Исследования показывают, что применение QSVM в сочетании с предварительной обработкой данных, например, через Sinkhorn Autoencoder, позволяет достичь улучшения в производительности по сравнению с традиционными нейронными сетями, а также минимизировать потери при реконструкции данных, что подчеркивает потенциал данного подхода для анализа сложных наборов данных.
Несмотря на то, что область квантового машинного обучения находится лишь в начальной стадии развития, она демонстрирует потенциал для преодоления ограничений, присущих классическим алгоритмам. Традиционные методы обработки данных часто сталкиваются с трудностями при работе с высокоразмерными пространствами и сложными взаимосвязями, что приводит к вычислительным затратам и снижению точности. Квантовые алгоритмы, используя принципы суперпозиции и запутанности, способны эффективно исследовать эти пространства и выявлять закономерности, недоступные для классических подходов. Это открывает перспективы для решения задач, ранее считавшихся невыполнимыми, и позволяет извлекать ценную информацию из больших объемов данных, что особенно важно в таких областях, как физика высоких энергий и анализ сложных систем.
Исследования показывают, что квантовые методы обработки данных обладают потенциалом для извлечения новых знаний из сложных наборов данных, в частности, из данных, получаемых в физике высоких энергий. Применение Sinkhorn Autoencoder в качестве предварительного процессора для квантовой машины опорных векторов (QSVM) продемонстрировало улучшение производительности классификации на 0.02 по сравнению с классическим нейронным сетью. Более того, данный подход позволил достичь минимальной не взвешенной ошибки реконструкции при значении $α = 0.06$, что указывает на эффективность предложенной комбинации квантовых и классических методов для анализа и интерпретации сложных данных.

Исследование демонстрирует, что снижение размерности данных играет ключевую роль в повышении эффективности квантовых алгоритмов машинного обучения, особенно при работе с высокоразмерными данными, характерными для физики высоких энергий. Подобно тому, как организм реагирует на любое изменение, система квантовой классификации требует ясной структуры для устойчивой работы. Вернер Гейзенберг однажды заметил: «Самое важное в науке — это не столько решение задачи, сколько постановка правильного вопроса». Данная работа подтверждает эту мысль, акцентируя внимание на необходимости грамотного выбора методов понижения размерности для достижения оптимальной производительности квантовых SVM и раскрытия потенциала квантовых вычислений в анализе сложных физических данных.
Куда двигаться дальше?
Исследование, представленное в данной работе, демонстрирует, что упрощение структуры данных — не просто технический прием, но и необходимое условие для практической реализации квантовых алгоритмов машинного обучения. Подобно тому, как в городском планировании неразумно строить сложные развязки, если можно оптимизировать основные магистрали, так и в квантовых системах избыточность информации может свести на нет все преимущества квантовых вычислений. Однако, стоит признать, что представленные методы — лишь первый шаг. Вопрос не в том, чтобы просто уменьшить размерность, а в том, чтобы сделать это разумно, сохранив при этом ключевые особенности данных.
Очевидным направлением для дальнейших исследований является разработка более адаптивных алгоритмов понижения размерности, способных учитывать специфику различных типов данных, встречающихся в физике высоких энергий и за ее пределами. Необходимо перейти от универсальных решений к системам, способным к самообучению и оптимизации структуры представления информации. Интересно также исследовать возможность интеграции различных методов понижения размерности в единый, иерархический подход, подобно многоуровневой инфраструктуре современного города.
В конечном счете, успех квантового машинного обучения будет зависеть не только от мощности квантовых процессоров, но и от способности создавать элегантные и эффективные системы представления данных. Как показывает данная работа, простота — не слабость, а залог устойчивости и масштабируемости. Именно в этом направлении, вероятно, и кроется ключ к будущим прорывам.
Оригинал статьи: https://arxiv.org/pdf/2512.01509.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-03 04:08