Автор: Денис Аветисян
Новое исследование оценивает способность современных языковых моделей понимать принципы квантовых вычислений и выявляет слабые места в их знаниях.

Представлен комплексный бенчмарк Quantum-Audit для оценки понимания языковыми моделями концепций квантовых вычислений, демонстрирующий успехи в базовых знаниях и недостатки в продвинутых темах, таких как квантовая безопасность и многоязычная производительность.
Несмотря на растущую роль больших языковых моделей (LLM) в квантовых вычислениях, систематической оценки их понимания фундаментальных концепций и способности к логическому мышлению в этой области не проводилось. В настоящей работе, представленной под названием ‘Quantum-Audit: Evaluating the Reasoning Limits of LLMs on Quantum Computing’, разработан комплексный бенчмарк, включающий 2700 вопросов, для оценки возможностей 26 LLM в области квантовых вычислений. Полученные результаты свидетельствуют о том, что модели демонстрируют успехи в освоении базовых понятий, но испытывают трудности с более сложными темами, такими как квантовая безопасность, и часто не способны распознавать и исправлять ложные предпосылки. Какие новые подходы к обучению и оценке LLM необходимы для достижения надежного и компетентного применения в квантовых технологиях?
Квантовая неопределённость: Исследование границ понимания LLM
Современные большие языковые модели (LLM) демонстрируют впечатляющий прогресс в обработке информации, однако степень их реального понимания сложных научных дисциплин, таких как квантовые вычисления, остается предметом дискуссий. Несмотря на способность генерировать связные тексты и отвечать на вопросы, часто неясно, основаны ли эти ответы на глубоком осмыслении принципов квантовой механики или же являются результатом статистического сопоставления паттернов в огромных массивах данных. Эта неопределенность особенно важна, учитывая растущую роль LLM в научных исследованиях и потенциальную возможность их использования для автоматизации процессов открытия и анализа в таких областях, как материаловедение и разработка алгоритмов. Понимание границ их компетентности в квантовой области необходимо для критической оценки результатов, полученных с их участием, и предотвращения распространения неверной или вводящей в заблуждение информации.
Существующие системы оценки больших языковых моделей (LLM) зачастую не способны выявить подлинное понимание научных концепций, ограничиваясь лишь констатацией способности к сопоставлению шаблонов. Это связано с тем, что многие тесты ориентированы на воспроизведение информации, а не на демонстрацию способности к логическим выводам и решению проблем, требующих глубокого осмысления. В результате, модели могут успешно проходить тесты, не обладая при этом реальным пониманием принципов, лежащих в основе изучаемых явлений. Таким образом, возникает острая необходимость в разработке более строгих и комплексных методов оценки, способных достоверно определить, действительно ли модель «понимает» изучаемый материал или лишь имитирует понимание, основываясь на статистических закономерностях в данных обучения.
Оценка возможностей больших языковых моделей (LLM) в понимании квантовых концепций становится все более важной, поскольку их потенциальная роль в научных открытиях неуклонно растет. В связи с этим было разработано комплексное тестирование, получившее название Quantum-Audit, включающее в себя 2700 вопросов, охватывающих широкий спектр тем квантовых вычислений. Данный набор вопросов призван выявить не просто способность LLM к поверхностному сопоставлению шаблонов, а истинное понимание принципов квантовой механики и их применения. Quantum-Audit предоставляет исследователям инструмент для объективной оценки и сравнения различных LLM, что, в свою очередь, способствует развитию более надежных и компетентных систем искусственного интеллекта, способных к поддержке и ускорению научных исследований в области квантовых технологий.

Quantum-Audit: Строгий инструмент оценки
Набор данных Quantum-Audit представляет собой комплексную и сложную платформу для оценки производительности больших языковых моделей (LLM) в области квантовых вычислений. Он включает в себя широкий спектр вопросов, охватывающих фундаментальные концепции, алгоритмы и применения квантовой механики. Набор данных разработан для выявления как способности LLM к воспроизведению фактов, так и их способности к логическому выводу и решению проблем, специфичных для квантовой области. Комплексность набора данных заключается в его разнообразии, охватывающем как теоретические основы, так и практические аспекты квантовых вычислений, что позволяет проводить всестороннюю оценку возможностей LLM в данной области.
Набор данных Quantum-Audit использует различные форматы вопросов для всесторонней оценки возможностей больших языковых моделей (LLM) в области квантовых вычислений. Помимо вопросов с множественным выбором, проверяющих фактические знания, в наборе представлены вопросы открытого типа, требующие генерации развернутых ответов, и вопросы с ложной посылкой, предназначенные для оценки способности к логическому мышлению и выявлению противоречий в предоставленной информации. Такое разнообразие форматов позволяет оценить не только способность LLM запоминать факты, но и их способность к рассуждениям и решению проблем в контексте квантовых концепций.
Набор данных Quantum-Audit содержит вопросы, тщательно разработанные и проверенные экспертами в области квантовых вычислений, что обеспечивает эталонный уровень для оценки производительности больших языковых моделей (LLM). В процессе валидации было установлено, что точность ответов LLM на вопросы, сгенерированные другими LLM, на 10-15% ниже, чем на вопросы, непосредственно сформулированные экспертами. Данное различие подчеркивает важность качественной авторской работы при создании бенчмарков для оценки понимания сложных научных концепций, таких как квантовые вычисления.

Проверка основ и продвинутых концепций квантовой механики
Quantum-Audit представляет собой инструмент оценки базовых знаний в области квантовой механики, в частности, понимания принципов суперпозиции и запутанности. Оценка проводится посредством серии тестов, направленных на верификацию способности к правильному применению этих фундаментальных концепций. Суть проверки заключается в определении, способен ли тестируемый корректно интерпретировать и использовать принципы |\psi\rangle = \alpha|0\rangle + \beta|1\rangle (суперпозиция) и взаимосвязанные состояния, описываемые запутанностью, для решения базовых задач и предсказания результатов квантовых измерений. Данный этап необходим для подтверждения минимального уровня компетенции перед переходом к изучению более сложных тем в квантовых вычислениях.
Оценка Quantum-Audit включает в себя проверку понимания более сложных областей квантовых вычислений, таких как квантовые логические элементы и схемы, а также квантовое машинное обучение. Данные разделы требуют от тестируемых не просто знания базовых принципов, но и способности применять их к более сложным задачам и алгоритмам. В частности, оценивается понимание принципов построения и функционирования квантовых схем, а также применение квантовых алгоритмов в задачах машинного обучения, что подразумевает глубокое понимание как квантовых, так и классических методов. Успешное прохождение данных тестов демонстрирует способность к решению сложных задач в области квантовых вычислений и машинного обучения.
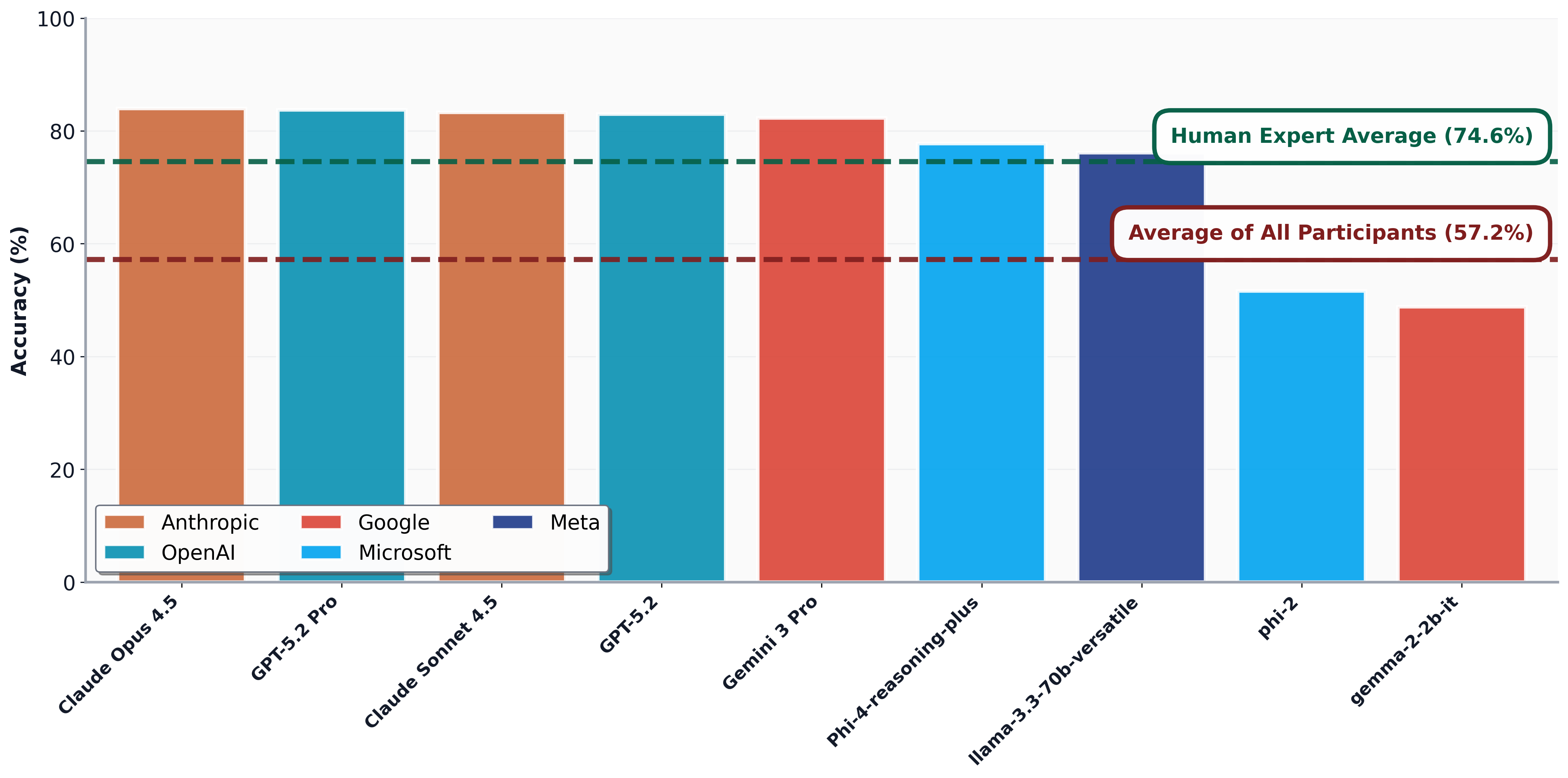
Оценка знаний также включает в себя сложные задачи, такие как операция экспоненциального SWAP и формирование импульсов DRAG, что позволяет оценить понимание практических аспектов реализации квантовых алгоритмов. Несмотря на то, что передовые модели демонстрируют среднюю точность в 92% при оценке базовых концепций квантовой механики, их производительность снижается до 75% при проверке понимания вопросов квантовой безопасности, что указывает на существенные пробелы в освоении данной специализированной области.
Последствия для квантовых вычислений и искусственного интеллекта
Исследования показали, что современные большие языковые модели (LLM) демонстрируют существенные ограничения в точном представлении и логическом осмыслении квантовых явлений. Несмотря на впечатляющие способности в обработке языка, LLM испытывают трудности с контринтуитивной природой квантовой механики, что указывает на недостаток истинного понимания лежащих в её основе принципов. Анализ результатов тестов выявил значительный разрыв в производительности: в то время как эксперты с опытом работы более пяти лет достигают средней точности в 79.4%, а аспиранты и доктора наук — 73.3% и выше, LLM демонстрируют существенно более низкие показатели. Данное несоответствие подчеркивает необходимость разработки новых архитектур искусственного интеллекта и методологий обучения, специально предназначенных для захвата и моделирования сложностей квантовой информации.
Несмотря на впечатляющие возможности в обработке естественного языка, современные большие языковые модели (LLM) испытывают трудности при работе с контринтуитивными принципами квантовой механики. Исследования показывают, что даже при безупречном синтаксисе и грамматике, модели не способны адекватно понимать и оперировать такими понятиями, как суперпозиция, запутанность и квантовая неопределенность. Это свидетельствует о фундаментальном разрыве между способностью модели генерировать правдоподобный текст и истинным пониманием лежащих в его основе физических законов. Данный недостаток проявляется в неспособности решать даже базовые задачи, связанные с квантовыми явлениями, и подчеркивает необходимость разработки принципиально новых архитектур искусственного интеллекта, способных овладеть сложными концепциями квантовой информации.
Полученные результаты указывают на необходимость разработки принципиально новых архитектур искусственного интеллекта и методологий обучения, способных адекватно отражать сложность квантовой информации. В то время как эксперты, обладающие пятилетним и более опытом работы в данной области, демонстрируют точность в 79.4%, а специалисты с ученой степенью — не менее 73.3%, современные языковые модели показывают значительно более низкие результаты. Этот существенный разрыв подчеркивает, что для эффективной работы с квантовыми явлениями необходимы алгоритмы, превосходящие возможности существующих подходов, и требуются инновационные методы, позволяющие ИИ овладеть контринтуитивными принципами квантовой механики.
Будущие направления: К созданию квантово-осведомленного ИИ
В дальнейшем исследования будут сосредоточены на разработке специализированных наборов данных и архитектур, способных более эффективно учитывать уникальные особенности квантовой информации. Существующие модели машинного обучения зачастую испытывают трудности при обработке данных, описывающих квантовые явления, из-за их высокой размерности и нелинейности. Новые подходы предполагают создание данных, имитирующих поведение квантовых систем, а также адаптацию нейронных сетей для эффективного представления и обработки квантовых состояний и операций. Особое внимание уделяется разработке архитектур, способных моделировать квантовую запутанность и суперпозицию, ключевые принципы квантовой механики, что позволит создавать более точные и эффективные алгоритмы для решения задач в области квантовых вычислений и искусственного интеллекта.
Исследования показывают, что интеграция методов символьного рассуждения и техник представления знаний способна значительно расширить возможности больших языковых моделей (LLM) в решении сложных задач квантовой физики. В отличие от традиционных LLM, которые полагаются преимущественно на статистические закономерности в данных, добавление логических правил и формализованных знаний позволяет моделям не только находить решения, но и объяснять их, а также обобщать полученные знания на новые, ранее не встречавшиеся ситуации. Такой подход особенно важен в квантовой области, где интуиция и формальное доказательство играют ключевую роль. Комбинирование статистических методов с символическим выводом позволяет LLM преодолеть ограничения, связанные с неполнотой или неоднозначностью данных, и приблизиться к более глубокому пониманию принципов квантовой механики.
Разработка инструментов с применением искусственного интеллекта для проектирования и верификации квантовых алгоритмов открывает значительные перспективы для реализации полного потенциала квантовых вычислений. Исследования показывают, что использование агентивных и углубленных режимов исследования позволяет добиться среднего улучшения точности в 6.7% при решении сложных задач. Такой подход предполагает активное взаимодействие ИИ с задачей, автоматическое формирование и проверку гипотез, что значительно превосходит традиционные методы. Данный прогресс указывает на возможность создания интеллектуальных систем, способных самостоятельно разрабатывать и оптимизировать квантовые алгоритмы, что существенно ускорит прогресс в данной области и откроет новые горизонты для решения сложных научных и практических задач.
Исследование, представленное в данной работе, подтверждает давно известную истину: системы, подобные большим языковым моделям, демонстрируют удивительную способность усваивать базовые принципы, однако сталкиваются с трудностями при переходе к более сложным концепциям, особенно в области квантовой безопасности. Это напоминает о том, что архитектура — это не структура, а компромисс, застывший во времени. Как однажды заметил Дональд Дэвис: «Простота — это высшая форма сложности». И в данном случае, сложность квантовых вычислений выявляет ограничения в понимании даже самых передовых моделей, подчеркивая необходимость постоянного развития и адаптации систем к новым вызовам.
Что же дальше?
Представленная работа, словно карта звездного неба, выявляет не только освещенные участки понимания больших языковых моделей в области квантовых вычислений, но и обширные, темные зоны. Каждая успешно пройденная проверка — это, скорее, обещание, данное прошлому, чем гарантия будущего. Модели демонстрируют неплохую память о базовых принципах, но хрупкость их рассуждений становится очевидной, когда дело доходит до более сложных тем, таких как квантовая безопасность. Это напоминает о том, что системы не строятся, а взращиваются, и каждый архитектурный выбор — это пророчество о будущем сбое.
Особенно любопытна слабость в кросс-лингвальной производительности. Перевод — это не просто замена слов, а перенос мировоззрения. Модели, словно нетерпеливые ученики, заучивают факты, но не постигают суть. Каждая зависимость от конкретного языка — это долговое обязательство перед культурой, требующее постоянного обслуживания. Контроль над пониманием, как иллюзия, требующая соглашения об уровне обслуживания.
Будущие исследования, вероятно, сосредоточатся на создании не просто «умных» моделей, а систем, способных к самовосстановлению и адаптации. Всё, что построено, когда-нибудь начнет само себя чинить. Истинный прогресс заключается не в увеличении объема знаний, а в развитии способности к критическому мышлению и осознанию границ собственного понимания.
Оригинал статьи: https://arxiv.org/pdf/2602.10092.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Генетическая приоритизация: новый взгляд на отбор генов
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Оптимизация квантовых схем: новый алгоритм для NISQ-устройств
- Границы Разума: Управление Саморазвивающимися ИИ
- Видео-Мыслитель: гармония разума и визуального потока.
- Квантовый усилитель амплитуды: новый подход к поиску основного состояния
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
2026-02-11 15:59