Автор: Денис Аветисян
Новый подход к организации баз данных использует гибридные квантово-классические алгоритмы для ускорения обработки запросов и повышения масштабируемости.
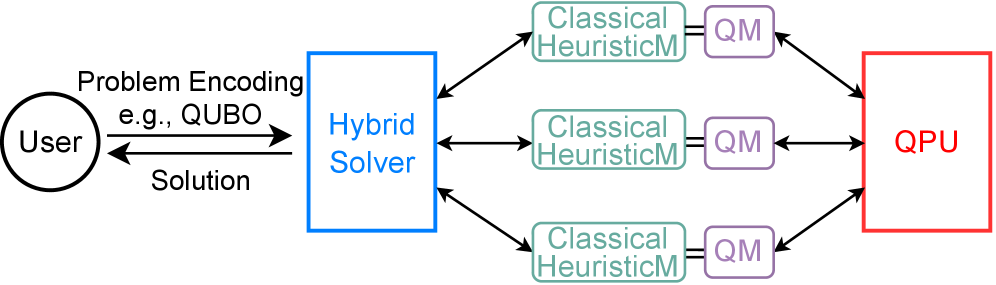
Исследование предлагает архитектуру, объединяющую квантовый отжиг и классические методы оптимизации для решения задач оптимизации баз данных в режиме реального времени с использованием релаксации корреляций и декомпозиции задач.
Несмотря на перспективность квантовых вычислений в решении сложных задач оптимизации баз данных, существующие подходы зачастую лишены гибкости и масштабируемости, необходимых для работы в реальном времени. В данной работе, озаглавленной ‘Towards a Hybrid Quantum-Classical Computing Framework for Database Optimization Problems in Real Time Setup’, предложен новый квантово-дополненный подход к оптимизации запросов, сочетающий классические и квантовые методы, включая релаксацию корреляций и декомпозицию задач. Разработанная гибридная схема позволяет достичь до 14-кратного улучшения производительности по сравнению с классическими оптимизаторами, обеспечивая при этом лучшую эффективность и качество решений, чем у «черных ящиков» квантовых решателей. Станут ли подобные системы основой для следующего поколения интеллектуальных баз данных, способных адаптироваться к динамически меняющимся условиям?
Пределы Классической Оптимизации Баз Данных
Традиционные методы оптимизации баз данных широко используют эвристические алгоритмы для поиска оптимальных планов выполнения запросов в огромном пространстве возможностей. Однако, полагаясь на приближенные решения, эти методы часто не способны найти наилучший план, что приводит к снижению производительности и увеличению времени отклика. Эвристики, будучи быстрыми в реализации, не гарантируют нахождение глобального оптимума, а лишь стремятся к достаточно хорошему решению за разумное время. В результате, даже небольшие изменения в структуре данных или сложности запроса могут потребовать полной переоценки плана, что особенно критично в динамичных средах с постоянно меняющимися данными и требованиями к производительности. Данный подход, хотя и распространен, оставляет значительный потенциал для улучшения эффективности обработки данных, что стимулирует поиск более совершенных методов оптимизации.
По мере увеличения объемов данных, сложность оптимизации запросов к базам данных значительно возрастает, особенно в связи с проблемой оптимального порядка соединения таблиц (join ordering) и планированием транзакций. Каждое возможное соединение таблиц в запросе представляет собой потенциальный путь выполнения, и количество таких путей экспоненциально растет с добавлением каждой новой таблицы. Подобная комбинаторная сложность делает поиск оптимального плана запроса чрезвычайно ресурсоемким, а неэффективное планирование транзакций может приводить к блокировкам и снижению пропускной способности системы. В результате, традиционные методы оптимизации, полагающиеся на эвристики, часто оказываются неспособными эффективно справляться с этими задачами, что требует разработки новых подходов к управлению данными в условиях растущих объемов информации.
Несмотря на активное внедрение методов машинного обучения, задача оптимизации баз данных продолжает сталкиваться с фундаментальными трудностями, обусловленными комбинаторной сложностью. Даже самые передовые алгоритмы, способные анализировать огромные объемы данных и выявлять закономерности, оказываются неспособны эффективно исследовать все возможные варианты выполнения запросов, особенно при большом количестве соединений и сложных условиях фильтрации. Количество потенциальных планов выполнения запроса растет экспоненциально с увеличением числа таблиц и условий, что делает полный перебор невозможным, а эвристические подходы, используемые в машинном обучении, часто приводят к субоптимальным решениям. Таким образом, несмотря на значительные успехи, комбинаторная сложность остается серьезным препятствием на пути к идеальной оптимизации баз данных, требуя разработки принципиально новых подходов.
Квантовые Вычисления: Новый Горизонт Производительности Баз Данных
Квантовые вычисления демонстрируют потенциал экспоненциального ускорения при решении задач оптимизации, что обусловлено использованием принципов суперпозиции и запутанности. В отличие от классических алгоритмов, которые исследуют варианты последовательно, квантовые алгоритмы, такие как алгоритм Гровера и квантовый отжиг, могут одновременно оценивать множество решений. Это приводит к теоретическому ускорению, которое в некоторых случаях может достигать экспоненциального порядка сложности, например, снижение сложности поиска в несортированном списке с O(n) до O(\sqrt{n}). Достижение «квантового превосходства» или «квантового преимущества» подразумевает решение конкретной задачи на квантовом компьютере быстрее, чем на любом известном классическом компьютере, и данный потенциал является ключевым драйвером исследований в области квантовых вычислений и их применения к задачам оптимизации в различных областях, включая логистику, финансы и машинное обучение.
Гибридные квантово-классические вычисления представляют собой практичный подход к решению сложных задач, объединяя сильные стороны обеих вычислительных парадигм. Классические компьютеры эффективно справляются с обработкой данных, управлением потоком операций и реализацией логических операций, в то время как квантовые компьютеры способны экспоненциально ускорять определенные типы вычислений, особенно в задачах оптимизации и моделирования. В гибридной архитектуре классический компьютер выполняет большую часть вычислительной нагрузки, включая предварительную и постобработку данных, а квантовый процессор используется для решения критически важных подзадач, требующих высокой вычислительной мощности. Такой подход позволяет обойти ограничения текущего аппаратного обеспечения квантовых компьютеров и использовать их возможности для повышения общей производительности системы, что делает его наиболее перспективным направлением развития квантовых вычислений на ближайшее будущее.
Платформы, такие как IBM Quantum и D-Wave, предоставляют аппаратную основу для реализации квантовых алгоритмов, отличаясь подходами к построению квантовых вычислительных систем. IBM Quantum использует сверхпроводящие кубиты, обеспечивая универсальность и возможность выполнения широкого спектра квантовых алгоритмов, в то время как D-Wave специализируется на квантовом отжиге, предназначенном для решения задач оптимизации. Обе платформы предоставляют доступ к квантовому оборудованию через облачные сервисы, позволяя разработчикам экспериментировать с квантовыми вычислениями и разрабатывать специализированные алгоритмы. D-Wave Systems предлагает компьютеры, основанные на архитектуре квантового отжига, в то время как IBM Quantum предоставляет доступ к сверхпроводящим кубитам различной конфигурации, включая системы с увеличенным количеством кубитов и улучшенной когерентностью.
Сопоставление Оптимизации Баз Данных с Квантовыми Схемами
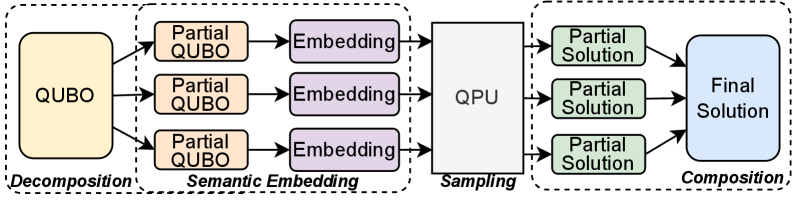
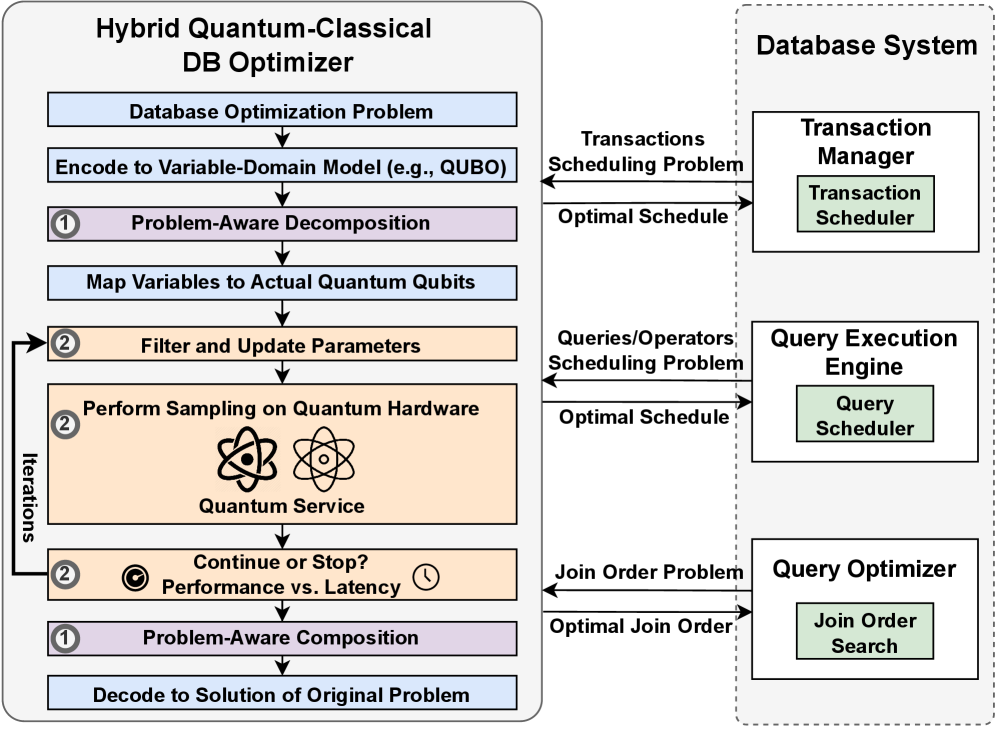
В основе подхода лежит преобразование задач оптимизации баз данных в задачу квадратичной безусловной двоичной оптимизации (QUBO). QUBO — это математическая модель, представляющая собой функцию, минимизируемую по набору бинарных переменных. Такая формулировка позволяет использовать квантовые отжигатели (quantum annealers) для поиска оптимальных решений, поскольку эти устройства изначально предназначены для решения задач QUBO. Каждая операция в плане запроса базы данных, такая как выбор порядка соединения таблиц или выбор оптимального индекса, кодируется как бинарная переменная, а целевая функция QUBO отражает общую стоимость выполнения запроса, включая время доступа к данным и использование ресурсов. Решение задачи QUBO соответствует оптимальному плану выполнения запроса.
Для эффективного решения задач оптимизации баз данных, сформулированных как задачи квадратичной безусловной двоичной оптимизации (QUBO), критически важны методы итерационной корреляционной релаксации и проблемно-ориентированного разложения. Итерационная корреляционная релаксация позволяет упростить сложную функцию QUBO путем последовательного снижения корреляций между переменными, что уменьшает вычислительную сложность. Проблемно-ориентированное разложение, в свою очередь, разбивает исходную задачу на более мелкие подзадачи, сохраняя при этом семантику базы данных и позволяя распараллеливать вычисления. Эти техники необходимы для преодоления ограничений современных квантовых отжигов, которые имеют ограничения по количеству кубитов и связей между ними, и для обеспечения масштабируемости решения для реальных задач оптимизации запросов.
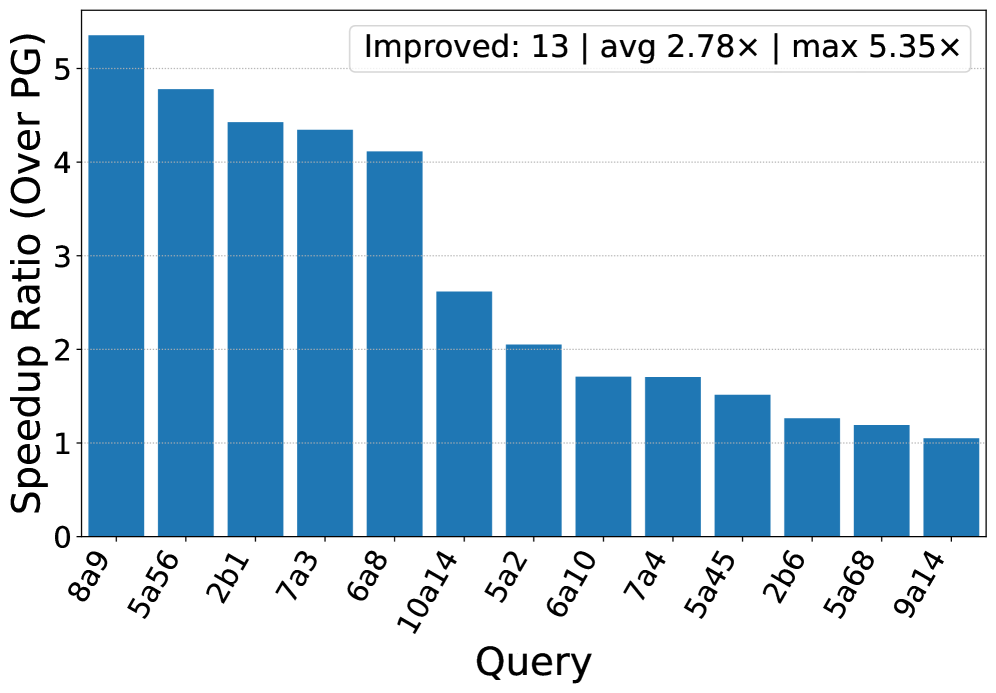
В ходе тестирования разработанная система продемонстрировала ускорение до 14.02x по сравнению с классическим оптимизатором запросов PostgreSQL. Среднее ускорение на наборе из 113 запросов рабочей нагрузки JOB составило 2.70x, а для 40 запросов рабочей нагрузки CEB — 2.78x. Полученные результаты свидетельствуют о значительном повышении производительности, особенно при обработке запросов, характерных для рабочей нагрузки JOB.
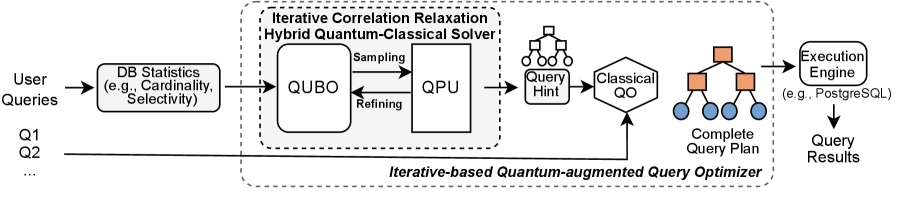
Предложенные методы оптимизации баз данных могут быть эффективно реализованы в системе управления базами данных PostgreSQL посредством расширения pg_hint_plan. Данное расширение предоставляет возможность тонкой настройки плана выполнения запроса, позволяя разработчику непосредственно влиять на выбор стратегии оптимизации. Интеграция с pg_hint_plan позволяет применять квантовые алгоритмы, сформулированные как задачи квадратичной безусловной двоичной оптимизации (QUBO), в рамках существующей инфраструктуры PostgreSQL, не требуя внесения изменений в ядро СУБД. Это достигается путем использования директив pg_hint_plan для указания оптимизатору PostgreSQL использовать разработанные QUBO-основанные стратегии оптимизации для конкретных запросов или схем данных.
Сближение Теории и Практики: Перспективы и Направления Развития
Существенная проблема в практическом применении квантовых вычислений заключается в значительных накладных расходах, связанных с передачей данных и инструкций в квантовые сервисы, доступные через облачные платформы. Этот «коммуникационный барьер» может существенно снижать общую производительность, особенно при работе с большими объемами информации. Задержки, возникающие при передаче данных между классическим и квантовым оборудованием, часто превышают время, необходимое для самих квантовых вычислений. Для эффективного использования квантовых ресурсов необходимо минимизировать объем передаваемых данных и оптимизировать протоколы связи, что требует разработки новых алгоритмов и аппаратных решений для снижения задержек и увеличения пропускной способности каналов связи с квантовыми процессорами.
Оптимизация передачи данных и минимизация количества запросов к квантовому оборудованию являются ключевыми факторами для достижения реальных преимуществ в производительности. Несмотря на потенциальную скорость квантовых вычислений, значительная часть времени может уходить на передачу информации между классическим и квантовым мирами. Поэтому, снижение объема передаваемых данных и сокращение числа вызовов квантовых функций напрямую влияет на общую эффективность решения задачи. Исследования показывают, что даже небольшое улучшение в этих аспектах может привести к существенному ускорению, позволяя в полной мере использовать возможности квантовых алгоритмов и решать сложные задачи, которые ранее были недоступны.
Среднее время, затрачиваемое на основное квантовое вычисление на квантовом процессоре (QPU), составило 42.116 миллисекунд. В ходе экспериментов удалось добиться значительного снижения задержки всей системы — от 1.78 до 2.65 раз. Данный результат демонстрирует ощутимый прогресс в оптимизации процессов взаимодействия с квантовым оборудованием и подтверждает потенциал для ускорения сложных вычислений за счет использования квантовых технологий. Сокращение задержки особенно важно для приложений, требующих оперативного получения результатов, и открывает новые возможности для интеграции квантовых вычислений в реальные системы.
Дальнейшие исследования, направленные на разработку более эффективных формулировок задач в форме QUBO (Quadratic Unconstrained Binary Optimization) и стратегий их декомпозиции, представляют собой ключевой фактор для раскрытия полного потенциала квантового ускорения в задачах оптимизации баз данных. Улучшение методов преобразования сложных запросов к задачам, решаемым квантовыми алгоритмами, позволит существенно сократить время вычислений и повысить эффективность поиска. Особое внимание уделяется разработке алгоритмов, способных разбивать большие задачи на более мелкие, решаемые параллельно на квантовом процессоре, что значительно ускорит процесс оптимизации и позволит обрабатывать более сложные и объёмные базы данных. Подобные исследования откроют возможности для создания принципиально новых методов анализа и управления данными, недоступных при использовании классических вычислительных систем.
Исследование демонстрирует, что элегантность алгоритма проявляется не в хитроумных уловках, а в непротиворечивости его границ и предсказуемости. Предложенный гибридный квантово-классический подход к оптимизации баз данных, основанный на декомпозиции задач и релаксации корреляций, стремится к математической чистоте решения. Как отмечал Анри Пуанкаре: «Математика — это искусство логического мышления». Эта фраза отражает суть представленной работы: стремление к доказательству корректности алгоритма, а не просто к его работоспособности на тестовых данных. Решение должно быть не просто эффективным, но и принципиально верным, что особенно важно для систем реального времени, где надежность является первостепенной задачей.
Что Дальше?
Без четкого определения задачи оптимизации, любое предлагаемое решение — лишь случайный шум в информационном пространстве. Данная работа, демонстрируя возможности гибридного квантово-классического подхода к оптимизации баз данных, лишь подчеркивает глубину нерешенных вопросов. Необходимо строгое математическое обоснование применимости квантового отжига к конкретным классам запросов, а не эмпирическое подтверждение на ограниченном наборе тестов. Особенно критичен вопрос масштабируемости: способность предложенных методов сохранять преимущества при росте объема данных и сложности запросов остается под вопросом.
Корреляция релаксации, будучи перспективным направлением, требует более детального анализа ее влияния на точность решения. Предложенное разложение задачи на подзадачи должно быть доказано как оптимальное с точки зрения вычислительной сложности, а не просто являться эвристическим приемом. Иначе, выигрыш от квантовых вычислений может быть нивелирован затратами на предварительную обработку данных.
В конечном счете, истинная элегантность решения заключается не в его способности «работать», а в его математической доказуемости. Необходимо перейти от эмпирических наблюдений к строгим теоретическим гарантиям, прежде чем говорить о реальном прорыве в области оптимизации баз данных с использованием квантовых вычислений.
Оригинал статьи: https://arxiv.org/pdf/2602.14263.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Симуляция, которая видит себя: новый подход к физическому моделированию
- Видеомонтаж без следов: Новый подход к удалению и вставке объектов
- Как заставить языковые модели говорить правду?
- Понимание сложных систем: новый взгляд на агентные модели
- Квантовые Игры и Цифровое Сотрудничество: Взгляд изнутри
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Квантовый горизонт лазеров: ресурсы когерентности
- Голос с Акцентом: Управление произношением без акцентированных данных
- Моделирование кровотока мозга: новый взгляд на скорость и точность
2026-02-17 08:29