Автор: Денис Аветисян
Новый подход, сочетающий квантовое обучение с подкреплением и вариационные квантовые схемы, позволяет оптимизировать инвестиционные портфели с высокой эффективностью.
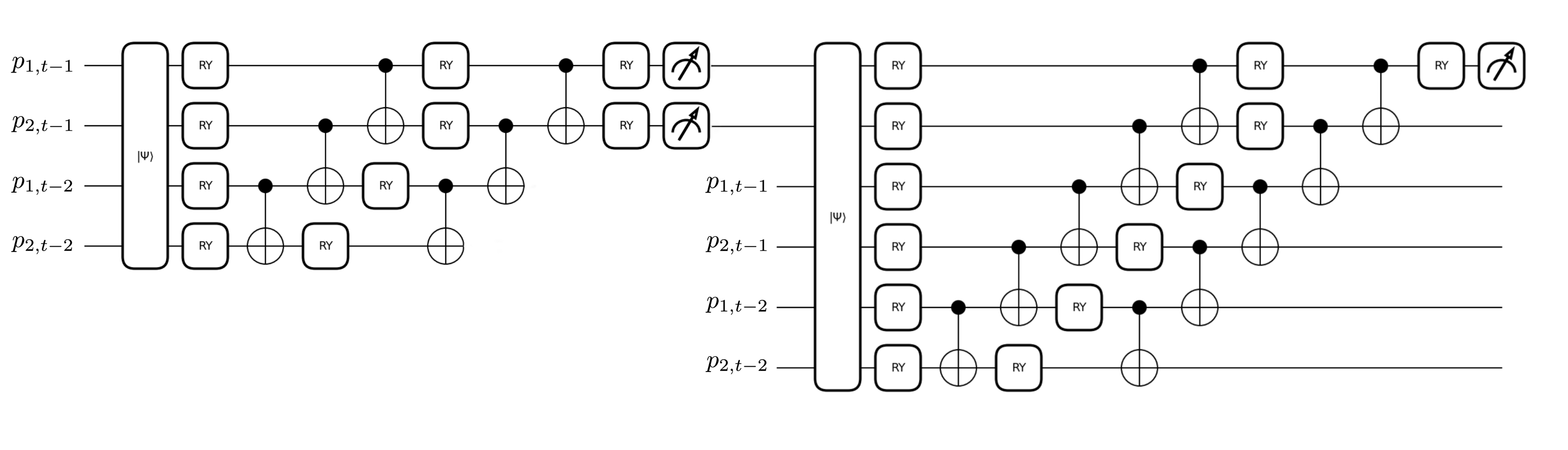
В статье представлен и протестирован новый фреймворк квантового обучения с подкреплением для динамической оптимизации портфеля, демонстрирующий конкурентоспособную производительность при меньшем количестве параметров по сравнению с классическими подходами глубокого обучения с подкреплением.
Эффективное управление инвестиционным портфелем в условиях высокой волатильности финансовых рынков остается сложной задачей. В данной работе, посвященной ‘Variational Quantum Circuit-Based Reinforcement Learning for Dynamic Portfolio Optimization’, предлагается новый подход к динамической оптимизации портфеля на основе квантового обучения с подкреплением, использующего вариационные квантовые схемы. Полученные результаты демонстрируют, что квантовые агенты достигают сопоставимой, а в некоторых случаях и превосходящей, риск-скорректированную доходность по сравнению с классическими моделями глубокого обучения с подкреплением, при значительно меньшем количестве параметров. Сможет ли квантовое обучение с подкреплением стать ключевой технологией для принятия решений в сложных и нестационарных финансовых средах?
Пределы Классического Построения Портфеля
Традиционные стратегии построения портфеля, такие как Равновесный портфель и Оптимизация по среднему и отклонению, опираются на точное представление состояния рынка и часто сталкиваются с трудностями в условиях сложной рыночной динамики. Эти методы требуют детальной информации о корреляциях между активами и предполагают, что исторические данные отражают будущие тенденции, что не всегда справедливо. В реальности, рынки характеризуются нелинейностью, неожиданными событиями и постоянными изменениями в поведении участников, что приводит к несоответствию между теоретическими моделями и фактическими результатами. Предположение о нормальном распределении доходностей, лежащее в основе многих классических подходов, также часто не соответствует действительности, особенно в периоды высокой волатильности или кризисов. В результате, стратегии, основанные на этих предположениях, могут оказаться неэффективными в управлении рисками и достижении оптимальной доходности в условиях реальной рыночной конъюнктуры.
Традиционные методы построения портфелей, такие как оптимизация по Марковицу, часто сталкиваются с серьезными вычислительными трудностями при работе с большим объемом данных и динамично меняющимися рыночными условиями. С увеличением числа активов и факторов, влияющих на их стоимость, потребность в вычислительных ресурсах экспоненциально возрастает, делая процесс оптимизации чрезвычайно медленным и непрактичным. Более того, эти методы, как правило, плохо адаптируются к новым данным, что приводит к неоптимальному соотношению риска и доходности. В результате, портфели, построенные на основе этих алгоритмов, могут уступать по эффективности более гибким и адаптивным стратегиям, особенно в периоды высокой волатильности и неопределенности на финансовых рынках. Таким образом, ограничения в вычислительной мощности и способности к адаптации становятся ключевыми факторами, препятствующими достижению максимальной прибыли при заданном уровне риска.
Исследования показывают, что пренебрежение транзакционными издержками существенно снижает потенциальную прибыльность портфеля, выявляя важное ограничение традиционных стратегий управления активами. Даже незначительные комиссии брокерам и биржи, накапливаясь при частых операциях, могут значительно уменьшить итоговую доходность, особенно в периоды высокой волатильности рынка. P = R - TC, где P — чистая прибыль, R — валовая доходность, а TC — совокупные транзакционные издержки, — эта простая формула демонстрирует, что оптимизация портфеля должна учитывать не только потенциальную прибыль, но и все сопутствующие расходы. В практической реализации стратегий, игнорирование транзакционных издержек приводит к переоценке потенциальной доходности и, как следствие, к неоптимальным инвестиционным решениям.
Обучение с Подкреплением: Новый Подход к Управлению Портфелем
Глубокое обучение с подкреплением (Deep Reinforcement Learning, DRL) представляет собой перспективный подход к оптимизации портфеля, позволяющий агенту изучать оптимальные торговые стратегии посредством взаимодействия с моделями финансовых рынков. В отличие от традиционных методов, требующих явного задания правил или статистических предположений, DRL использует алгоритмы обучения, основанные на максимизации кумулятивной награды. Агент, взаимодействуя с рыночной средой, получает обратную связь в виде прибыли или убытка и корректирует свою политику действий для достижения наилучших результатов. Этот подход позволяет адаптироваться к меняющимся рыночным условиям и учитывать сложные взаимосвязи между активами, что делает его эффективным инструментом для автоматизированного управления инвестиционным портфелем.
Алгоритмы DeepQNetwork (DQN) и PolicyGradient позволяют агентам обучаться принятию оптимальных решений в сложных пространствах состояний, характерных для финансовых рынков. DQN использует Q-функцию для оценки ценности действий в каждом состоянии, обучаясь посредством итеративного улучшения этой оценки на основе опыта, полученного в процессе взаимодействия со средой. PolicyGradient, в свою очередь, напрямую оптимизирует политику агента, определяющую вероятность выбора того или иного действия в заданном состоянии. Оба подхода нацелены на максимизацию кумулятивной награды, определяющей прибыльность стратегии, и требуют значительных вычислительных ресурсов для обучения, особенно при работе с многомерными пространствами состояний и действий.
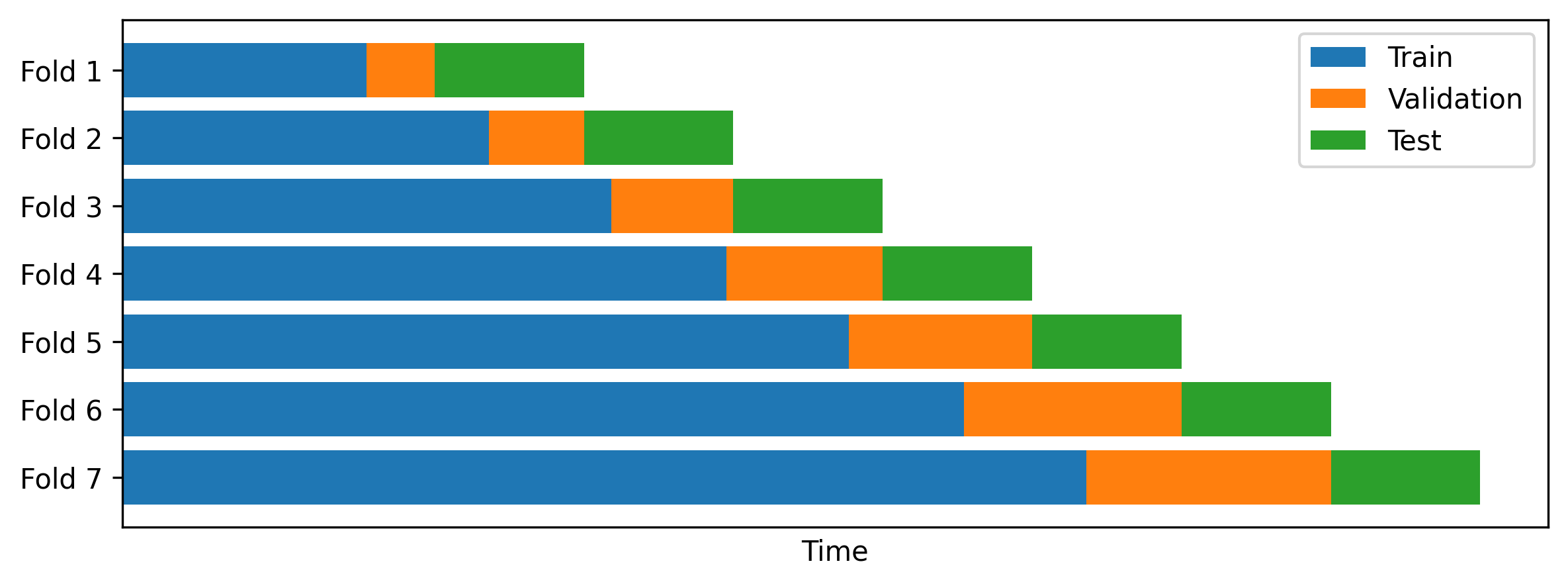
Эффективность алгоритмов обучения с подкреплением в управлении портфелем напрямую зависит от корректно определенной функции вознаграждения (RewardFunction), которая направляет агента к желаемым результатам, таким как максимизация прибыли или минимизация риска. Эта функция должна точно отражать цели инвестора и учитывать все значимые факторы, влияющие на доходность портфеля. Для обеспечения надежности и обобщающей способности полученных стратегий, необходима строгая валидация алгоритма с использованием перекрестной проверки (CrossValidation), включающей разделение данных на обучающую, валидационную и тестовую выборки, а также оценку производительности на этих данных для предотвращения переобучения и обеспечения устойчивости к новым рыночным условиям.
Квантовое Обучение с Подкреплением: Раскрытие Потенциала Квантовых Вычислений
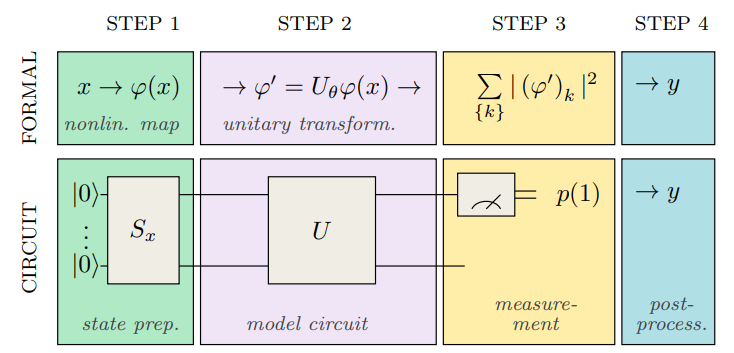
Квантовое обучение с подкреплением (QRL) использует квантовые схемы для представления политик агента и ускорения процесса обучения. В отличие от классических методов, QRL позволяет кодировать политики в виде квантовых состояний, что потенциально обеспечивает экспоненциальное увеличение выразительности при том же количестве параметров. Это достигается за счет использования квантовой суперпозиции и запутанности для эффективного исследования пространства политик. Использование квантовых схем позволяет моделировать сложные зависимости и взаимосвязи между состояниями и действиями, что может привести к более быстрой сходимости и улучшенным результатам в задачах обучения с подкреплением по сравнению с классическими подходами.
В основе квантового обучения с подкреплением (QRL) лежат вариационные квантовые схемы (VQC). Эти схемы, состоящие из параметризованных квантовых вентилей, позволяют эффективно представлять и оптимизировать стратегии агента. VQC позволяют исследовать сложные пространства стратегий, преобразуя параметры схемы для определения действий агента в конкретных состояниях среды. Пространство параметров схемы θ определяет политику, и оптимизация этих параметров посредством алгоритмов, таких как градиентный спуск, позволяет агенту учиться и улучшать свою производительность. Использование квантовых схем позволяет потенциально моделировать более сложные политики с меньшим числом параметров по сравнению с классическими подходами, что способствует более эффективному обучению и обобщению.
Правило смещения параметров (ParameterShiftRule) является ключевым компонентом при вычислении градиентов в квантовых схемах, используемых в обучении с подкреплением. В отличие от классических методов, где градиенты вычисляются напрямую, в квантовых схемах требуется учитывать вероятностную природу квантовых вычислений. ParameterShiftRule позволяет эффективно оценить градиент функции потерь путем выполнения квантовой схемы дважды — с небольшим смещением фазы для каждого параметра — и последующего вычитания результатов. Это позволяет избежать необходимости вычисления производной квантовой схемы напрямую, что значительно упрощает процесс оптимизации и позволяет эффективно обучать квантовые агенты с подкреплением. \frac{\partial F(\theta)}{\partial \theta} = \frac{1}{2} [F(\theta + \frac{\pi}{2}) - F(\theta - \frac{\pi}{2})] , где F(θ) — функция потерь, а θ — параметры схемы.
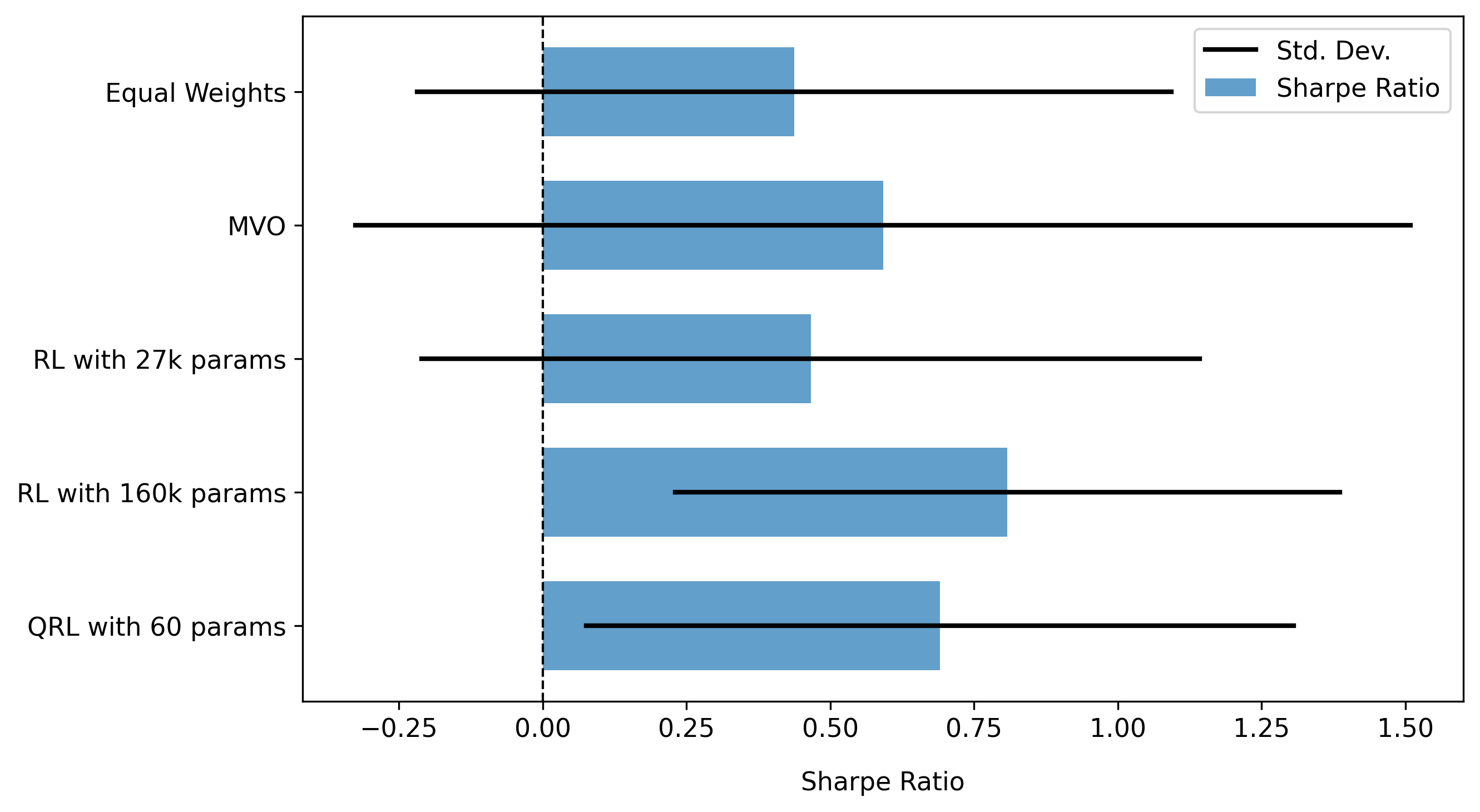
Агенты, использующие квантовое обучение с подкреплением (QRL), продемонстрировали превосходство над классическими аналогами при значительно меньшем количестве параметров. В ходе экспериментов было установлено, что QRL-агенты достигают сопоставимых значений коэффициента Шарпа (Sharpe Ratio) с передовыми моделями глубокого обучения с подкреплением (Deep Reinforcement Learning), при этом требуя существенно меньше вычислительных ресурсов и параметров модели для достижения аналогичной производительности. Это указывает на потенциальную эффективность QRL в задачах, где ограничены ресурсы или требуется компактное представление политики.
Квантовое обучение с подкреплением (QRL) продемонстрировало возможность достижения сопоставимых показателей Шарпа (Sharpe Ratio) с классическими моделями обучения с подкреплением, при этом требуя значительно меньшего количества параметров модели. В ходе экспериментов QRL-агент достиг сопоставимых результатов с классической моделью глубокого обучения с подкреплением, состоящей из 13,500 параметров, используя при этом существенно более компактное представление политики. Это снижение количества параметров указывает на потенциальную эффективность QRL в задачах, где вычислительные ресурсы ограничены или требуется компактное представление модели, сохраняя при этом высокую производительность.
В ходе сравнительного анализа квантовое обучение с подкреплением (QRL) продемонстрировало значительное превосходство над классической моделью глубокого обучения с подкреплением, содержащей 13 500 параметров. Эксперименты показали, что QRL превосходит классическую модель по ключевым показателям эффективности, что указывает на потенциальную возможность достижения более высоких результатов с использованием значительно меньшего количества вычислительных ресурсов и упрощенной архитектурой модели. Данный результат подтверждает перспективность применения квантовых вычислений для задач обучения с подкреплением и оптимизации.
Перспективы и Обещания Интеллектуальных Портфелей
Дальнейшие исследования должны быть направлены на создание более устойчивых и масштабируемых алгоритмов обучения с подкреплением (QRL), способных эффективно функционировать в условиях реальной рыночной сложности. Текущие алгоритмы часто демонстрируют ограниченную эффективность при столкновении с нелинейными зависимостями, высокой волатильностью и непредсказуемыми событиями, характерными для финансовых рынков. Разработка алгоритмов, способных адаптироваться к меняющимся рыночным условиям, учитывать множество факторов и обрабатывать большие объемы данных, является ключевой задачей. Особое внимание уделяется разработке методов, позволяющих снизить чувствительность алгоритмов к шуму и обеспечить стабильную работу в долгосрочной перспективе. Успешное решение этой задачи позволит создать интеллектуальные портфели, способные динамически реагировать на изменения рынка и максимизировать доходность при минимизации рисков.
Для существенного повышения эффективности агентов, использующих обучение с подкреплением в портфельном управлении, необходимо объединить алгоритмы QRL с передовыми методами представления состояния рынка. Традиционные подходы часто полагаются на упрощенные или неполные описания рыночной ситуации, что ограничивает способность агента к принятию оптимальных решений. Инновационные техники, такие как использование нейронных сетей для обработки больших объемов данных и выявления скрытых закономерностей, позволяют создавать более детализированные и информативные представления состояния. Это, в свою очередь, дает возможность агенту точнее оценивать риски и возможности, адаптироваться к меняющимся условиям и, как следствие, значительно улучшить показатели доходности портфеля. Успешная интеграция этих технологий станет ключевым фактором в разработке интеллектуальных портфелей, способных к динамической оптимизации и эффективному управлению рисками в реальных рыночных условиях.
Конечная цель исследований в области интеллектуальных портфелей — создание самоадаптирующихся инвестиционных стратегий, способных оперативно реагировать на изменяющиеся рыночные условия. Такие портфели призваны не просто следовать за тенденциями, но и прогнозировать их, оптимизируя распределение активов для достижения максимальной доходности при минимизации рисков. Разработка подобных систем требует интеграции передовых алгоритмов машинного обучения, включая обучение с подкреплением, и предполагает постоянную адаптацию к новым данным и рыночным реалиям. В конечном итоге, интеллектуальные портфели должны обеспечить инвесторам стабильный прирост капитала в долгосрочной перспективе, снижая необходимость в ручном управлении и постоянном мониторинге рынка.
Тщательное тестирование и валидация с использованием перекрестной проверки (CrossValidation) являются критически важными этапами при оценке эффективности продвинутых стратегий управления портфелем. Данный подход позволяет не только оценить способность алгоритма к обобщению на новых данных, но и выявить потенциальные переобучения и скрытые недостатки. В процессе перекрестной проверки данные разделяются на несколько подмножеств, на которых последовательно обучается и тестируется модель, обеспечивая более надежную и объективную оценку ее производительности в различных рыночных условиях. Отсутствие адекватной валидации может привести к ошибочным выводам о прибыльности и устойчивости стратегии, а также к значительным финансовым потерям в реальной торговле. Использование CrossValidation позволяет убедиться в надежности алгоритма и его способности адаптироваться к меняющимся рыночным реалиям, что является необходимым условием для успешного применения в управлении инвестициями.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных адаптироваться и сохранять свою эффективность во времени. Авторы предлагают квантово-усиленный алгоритм обучения с подкреплением для оптимизации портфеля, что позволяет добиться конкурентоспособных результатов при меньшем количестве параметров. Этот подход особенно ценен, поскольку он подчеркивает важность устойчивости и долговечности в сложных финансовых моделях. Как однажды заметил Анри Пуанкаре: «Математика не учит нас тому, как добавлять или вычитать, но учит нас тому, как мыслить». Данное исследование, в свою очередь, демонстрирует, как можно мыслить за рамками классических алгоритмов, чтобы создать более надежные и эффективные системы для динамической оптимизации портфеля.
Куда Ведет Дорога?
Представленная работа, как и любая попытка обуздать волатильность рынков, лишь временно отсрочила неизбежное. Верификация квантовых схем в контексте обучения с подкреплением — это, несомненно, шаг вперед, но вопрос не в скорости вычислений, а в сложности самой системы. Параметры, как песчинки в часах, утекают сквозь пальцы, и даже сокращение их числа — лишь иллюзия контроля. Версионирование, в данном случае, — форма памяти, попытка зафиксировать мгновение оптимальности, зная, что оно мимолетно.
Очевидно, что будущее исследований лежит не в гонке за параметрическим превосходством, а в разработке более устойчивых алгоритмов. Необходимо исследовать гибридные подходы, сочетающие в себе сильные стороны как классических, так и квантовых методов, и, что более важно, разрабатывать метрики, способные оценивать не только доходность, но и долговечность портфеля во времени. Стрела времени всегда указывает на необходимость рефакторинга, и игнорировать это — значит обречь систему на преждевременное старение.
В конечном итоге, данная работа — еще один виток в бесконечном цикле оптимизации. Задача не в том, чтобы найти идеальный портфель, а в том, чтобы создать систему, способную адаптироваться к постоянно меняющимся условиям. Все системы стареют — вопрос лишь в том, делают ли они это достойно.
Оригинал статьи: https://arxiv.org/pdf/2601.18811.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-28 06:58