Автор: Денис Аветисян
Новый подход объединяет возможности квантовых вычислений и глубокого обучения с подкреплением для решения сложных задач оптимизации.
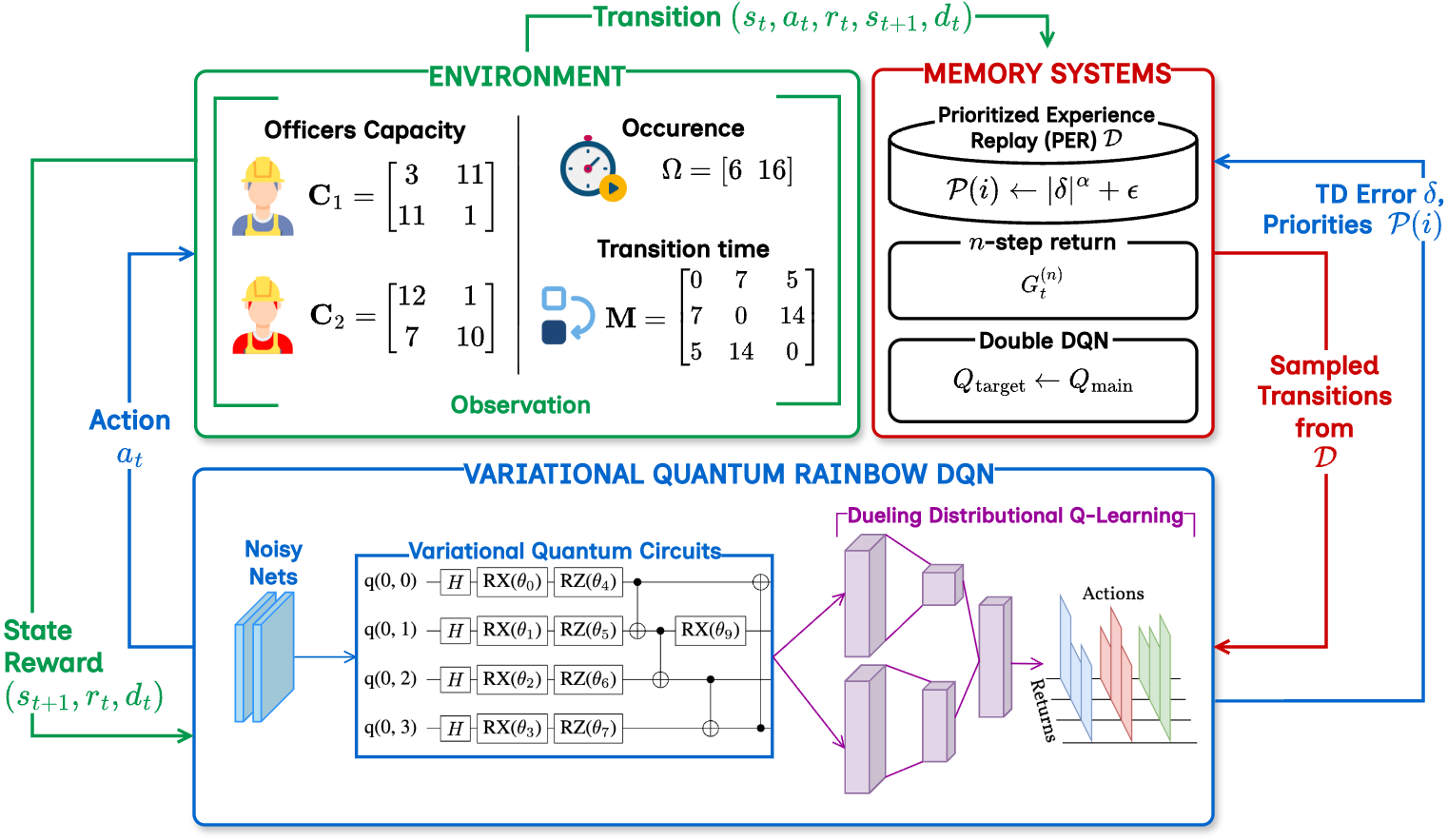
В статье представлена VQR-DQN — новая квантовая платформа обучения с подкреплением, использующая вариационные квантовые схемы для улучшения распределения ресурсов, продемонстрированная на примере управления человеческими ресурсами.
Несмотря на значительные успехи в области машинного обучения с подкреплением, задачи оптимизации, связанные с комбинаторной сложностью, остаются вычислительно затратными. В данной работе, посвященной ‘Variational Quantum Rainbow Deep Q-Network for Optimizing Resource Allocation Problem’ представлена новая структура VQR-DQN, объединяющая вариационные квантовые схемы с передовыми методами глубокого обучения с подкреплением. Показано, что предложенный подход позволяет снизить время выполнения на 26.8% в задачах распределения ресурсов, превосходя классические алгоритмы DQN и Rainbow DQN на 4.9-13.4%. Может ли интеграция квантовых вычислений открыть новые горизонты для решения масштабных задач оптимизации в различных областях?
Проблема Распределения Ресурсов: Предел Масштабируемости
Проблема распределения ресурсов представляет собой фундаментальную задачу, относящуюся к классу NP-трудных, что означает отсутствие известных алгоритмов, способных найти оптимальное решение за полиномиальное время. Её значимость проявляется в широком спектре областей — от логистики и управления цепочками поставок до распределения вычислительных мощностей и планирования производства. Однако, традиционные методы, такие как линейное программирование и генетические алгоритмы, зачастую оказываются неэффективными при работе со сложными, многомерными сценариями. С ростом числа переменных и ограничений вычислительная сложность экспоненциально возрастает, делая поиск оптимальных решений практически невозможным в реальном времени. Это ограничивает их применимость в динамично меняющихся условиях и требует поиска новых, масштабируемых подходов к решению данной задачи.
Традиционные методы решения задач распределения ресурсов, такие как линейное программирование и генетические алгоритмы, сталкиваются с существенными трудностями при увеличении масштаба решаемой проблемы. По мере роста числа переменных и ограничений, вычислительная сложность этих подходов экспоненциально возрастает, что приводит к неприемлемому увеличению времени вычислений. В результате, даже относительно небольшие изменения в объеме данных могут сделать эти методы практически неприменимыми для задач, требующих оперативных решений. Например, в логистических сетях или системах управления энергоснабжением, где ресурсы необходимо распределять в реальном времени, подобная вычислительная неэффективность может привести к серьезным сбоям и потерям. Таким образом, необходимость в разработке более масштабируемых алгоритмов становится критически важной для эффективного управления сложными системами.
Ограничения масштабируемости, возникающие при решении задач распределения ресурсов, подталкивают к изучению возможностей, которые открывают интеллектуальные агенты и обучение с подкреплением. Традиционные методы оптимизации, сталкиваясь с ростом сложности и многомерностью задач, часто становятся непрактичными из-за экспоненциального увеличения вычислительных затрат. В отличие от них, агенты, способные к самообучению в процессе взаимодействия со сложной средой распределения ресурсов, демонстрируют перспективность в преодолении этих ограничений. Обучение с подкреплением позволяет им адаптироваться к меняющимся условиям, находить оптимальные стратегии распределения, даже в ситуациях, когда точное математическое моделирование затруднено или невозможно. Подобный подход, имитирующий способность к адаптации и принятию решений в реальном времени, открывает новые горизонты для эффективного управления ресурсами в различных областях — от логистики и финансов до управления энергосистемами и роботизированными комплексами.
Обучение с Подкреплением: Новый Параллель в Оптимизации
Обучение с подкреплением (RL) представляет собой парадигму, в которой агент взаимодействует со средой, получая вознаграждение или штраф за каждое действие. Этот процесс позволяет агенту методом проб и ошибок выработать оптимальную политику поведения, максимизирующую суммарное вознаграждение. В контексте динамического распределения ресурсов, RL обеспечивает механизм адаптации к изменяющимся условиям и оптимизации использования ресурсов без необходимости явного программирования правил. Агент самостоятельно изучает наиболее эффективные стратегии распределения, основываясь на получаемой обратной связи от среды, что делает RL особенно подходящим для задач, где заранее неизвестны оптимальные решения или условия постоянно меняются.
Глубокое обучение с подкреплением (Deep Reinforcement Learning, DRL) расширяет возможности традиционного обучения с подкреплением за счет использования глубоких нейронных сетей для обработки пространств состояний высокой размерности. В отличие от классических методов, требующих ручного выделения признаков или использования табличных методов, DRL позволяет агенту автоматически извлекать релевантные признаки непосредственно из необработанных данных, таких как изображения или сенсорные потоки. Это существенно расширяет применимость обучения с подкреплением к задачам, где количество возможных состояний слишком велико для хранения в таблице $Q$-значений, и позволяет находить решения для ранее неразрешимых проблем в областях, таких как робототехника, компьютерные игры и управление ресурсами.
Алгоритмы Q-обучения и глубоких Q-сетей (Deep Q-Networks, DQN) служат базовыми методами для разработки эффективных стратегий распределения ресурсов, однако их практическое применение требует дальнейших усовершенствований. Q-обучение, основанное на итеративном обновлении $Q$-функции, подвержено проблемам сходимости и требует тщательного подбора параметров, таких как скорость обучения и фактор дисконтирования. DQN, использующий глубокие нейронные сети для аппроксимации $Q$-функции, сталкивается с нестабильностью обучения, вызванной корреляцией данных и нелинейностью сети. Для повышения производительности и стабильности применяются такие техники, как Experience Replay и Target Networks, но остаются актуальными задачи оптимизации архитектуры сети, методов исследования и алгоритмов обновления параметров.
Усиление Обучения с Подкреплением: Продвинутые Алгоритмы
Алгоритмы Double DQN и Dueling DQN направлены на снижение систематической переоценки $Q$-значений, являющейся проблемой в стандартном алгоритме Deep Q-Network (DQN). Double DQN использует два независимых $Q$-сетей для оценки оптимального действия и его значения, что позволяет отделить выбор действия от его оценки и уменьшить переоценку. Dueling DQN разделяет $Q$-сеть на две ветви: одну для оценки значения состояния ($V(s)$), а другую — для оценки преимущества каждого действия в данном состоянии ($A(s,a)$). Итоговая оценка $Q(s,a)$ вычисляется как $Q(s,a) = V(s) + A(s,a)$. Такое разделение позволяет более эффективно обобщать знания и улучшает точность оценки ценности состояний, что приводит к более стабильному и эффективному обучению агента.
Методы приоритезированного воспроизведения (Prioritized Replay) и шумных сетей (Noisy Networks) значительно повышают эффективность обучения с подкреплением. Приоритезированное воспроизведение фокусируется на повторном использовании наиболее информативных переходов опыта, что позволяет агенту быстрее обучаться, уделяя больше внимания редким, но важным событиям. Шумные сети, напротив, вводят коррелированный шум в веса нейронной сети, стимулируя более эффективное исследование пространства состояний без необходимости в сложных стратегиях $\epsilon$-жадности или других методах исследования. Комбинированное применение этих методов позволяет агентам быстрее сходиться к оптимальной политике и лучше обобщать полученный опыт на новые, ранее не встречавшиеся ситуации.
Алгоритм Rainbow DQN представляет собой современное объединение нескольких усовершенствований в обучении с подкреплением, включая Double DQN, Dueling DQN, Prioritized Replay и Noisy Networks. Он служит эталонным алгоритмом для сравнительного анализа, поскольку наша разработка VQR-DQN демонстрирует превосходящие результаты в ряде тестов. Rainbow DQN обеспечивает стабильное и эффективное обучение, но VQR-DQN превосходит его по показателям скорости сходимости и итоговой производительности агента в различных средах, что подтверждается количественными данными, представленными в следующих разделах.
Квантовое Обучение с Подкреплением: Новый Рубеж Возможностей
Квантовое обучение с подкреплением (QRL) представляет собой перспективное направление, использующее принципы квантовой механики для повышения эффективности исследования пространства решений. В отличие от классических алгоритмов обучения с подкреплением, которые могут сталкиваться с трудностями при обработке сложных и высокоразмерных задач, QRL потенциально позволяет значительно ускорить процесс обучения и находить оптимальные стратегии. Это достигается за счет использования таких квантовых явлений, как суперпозиция и запутанность, которые позволяют агенту одновременно исследовать множество возможных вариантов действий, что существенно расширяет возможности поиска наилучшего решения. Использование квантовых вычислений в контексте обучения с подкреплением открывает новые горизонты для решения задач, ранее недоступных для классических алгоритмов, особенно в областях, требующих обработки больших объемов данных и принятия решений в условиях неопределенности.
В рамках разработанной структуры VQR-DQN, вариационные квантовые схемы (VQCs) интегрированы с алгоритмом Rainbow DQN для улучшения представления сложных состояний. Этот подход позволяет извлекать квантовые признаки, которые расширяют возможности агента в процессе обучения оптимальным стратегиям распределения ресурсов. Использование VQCs способствует более эффективному исследованию пространства решений, позволяя агенту идентифицировать и применять стратегии, которые могли бы остаться незамеченными при использовании классических алгоритмов. В результате, VQR-DQN демонстрирует повышенную способность к обобщению и адаптации к новым, сложным задачам, что существенно улучшает его производительность в задачах, требующих оптимального распределения, таких как решение проблем распределения человеческих ресурсов.
Исследование продемонстрировало превосходство разработанной архитектуры VQR-DQN над алгоритмами Double DQN и Rainbow DQN при решении задачи оптимального распределения человеческих ресурсов (HRAP). Наблюдаемое улучшение производительности выражается в значительном сокращении времени выполнения задачи и более эффективном использовании доступных ресурсов. Ключевым элементом, обеспечивающим эту эффективность, является нормализация функции вознаграждения с использованием фактора $\Psi$, определяемого как ($max(C) E T$) + ($max(M) E T$). Данный фактор учитывает максимальные значения критериев компетенции (C) и мотивации (M) сотрудников, умноженные на затраты энергии (E) и время (T), необходимые для выполнения задачи, что позволяет алгоритму более точно оценивать качество принимаемых решений и стремиться к оптимальному распределению ресурсов.
Перспективы и Широкие Последствия: К Эволюции Систем
Дальнейшие исследования в области квантового обучения с подкреплением (QRL) сосредоточены на разработке более эффективных квантовых алгоритмов, способных значительно ускорить процесс обучения и повысить производительность моделей. Особое внимание уделяется изучению новых гибридных архитектур, объединяющих сильные стороны квантовых и классических вычислений. Такой подход позволит использовать преимущества квантовой обработки для решения наиболее сложных задач обучения, в то время как классические вычисления будут отвечать за менее ресурсоемкие операции. Разработка таких гибридных систем предполагает оптимизацию распределения задач между квантовым и классическим оборудованием, что требует создания новых методов и алгоритмов для эффективного взаимодействия между ними. Ожидается, что подобные инновации приведут к созданию систем QRL, способных решать задачи, непосильные для современных классических алгоритмов, открывая новые горизонты в области искусственного интеллекта и оптимизации.
Расширение сферы применения квантового обучения с подкреплением (QRL) за пределы текущих областей открывает перспективы для значительных оптимизаций и инноваций в различных секторах. В логистике QRL может быть использовано для разработки более эффективных маршрутов доставки и управления цепочками поставок, минимизируя затраты и время транспортировки. В финансовой сфере алгоритмы QRL способны оптимизировать инвестиционные портфели, оценивать риски и выявлять новые возможности для получения прибыли. Особый потенциал наблюдается в здравоохранении, где QRL может применяться для персонализированной медицины, оптимизации режимов лечения и разработки новых лекарственных препаратов, учитывая индивидуальные особенности пациентов. Внедрение QRL в эти и другие области обещает не только повышение эффективности существующих процессов, но и создание принципиально новых решений, основанных на возможностях квантовых вычислений.
В перспективе, слияние квантовых вычислений и обучения с подкреплением сулит революционные изменения в сфере распределения ресурсов. Интеллектуальные системы, способные адаптироваться, обучаться и оптимизировать процессы в режиме реального времени, откроют новые возможности для повышения эффективности, производительности и устойчивости. Данный симбиоз позволит решать сложнейшие задачи оптимизации, недоступные классическим алгоритмам, что найдет применение в широком спектре областей — от логистики и финансов до здравоохранения и управления энергосистемами. Ожидается, что квантовое обучение с подкреплением позволит создавать системы, способные динамически приспосабливаться к меняющимся условиям и находить оптимальные решения даже в условиях неопределенности, значительно превосходя возможности существующих методов.
Предложенная работа демонстрирует стремление к созданию систем, способных адаптироваться и сохранять свою эффективность во времени. Подобно тому, как версионирование является формой памяти для программного обеспечения, VQR-DQN стремится к оптимизации распределения ресурсов, учитывая динамические изменения и сложности задачи. Тим Бернерс-Ли однажды сказал: «Интернет — это для всех, и каждый должен иметь возможность использовать его». Эта идея перекликается с подходом, представленным в статье, поскольку VQR-DQN, используя возможности квантовых вычислений и глубокого обучения с подкреплением, направлен на повышение эффективности распределения ресурсов — будь то человеческие ресурсы, как в данном исследовании, или любые другие, делая системы более гибкими и приспособленными к требованиям времени.
Что впереди?
Представленная работа, стремясь к оптимизации распределения ресурсов посредством симбиоза квантовых вычислений и глубокого обучения с подкреплением, неизбежно сталкивается с тем, что все системы стареют — вопрос лишь в том, делают ли они это достойно. Логирование, в данном контексте, становится хроникой жизни системы, фиксирующей не только успехи, но и неизбежные отклонения от идеала. Очевидно, что масштабируемость вариационных квантовых схем остаётся узким местом, а шум — постоянным спутником, искажающим результаты. Развертывание алгоритма — лишь мгновение на оси времени, за которым следует период адаптации к реальным условиям, где идеализированные предположения могут оказаться несостоятельными.
Будущие исследования, вероятно, сосредоточатся на разработке более устойчивых к шуму квантовых схем и методов снижения требований к квантовым ресурсам. Не менее важной задачей представляется адаптация алгоритма к динамически меняющимся условиям, когда ресурсы и задачи могут изменяться в течение времени. В конечном счете, истинный тест для подобных систем — не в достижении теоретического оптимума, а в способности поддерживать работоспособность и адаптироваться к неизбежным несовершенствам реального мира.
Очевидно, что представленная методология, хотя и перспективна, является лишь одной из многих возможных траекторий развития. Время покажет, станет ли она доминирующей, или же уступит место более элегантным и эффективным решениям. Но даже если этот конкретный алгоритм забудут, сам поиск — это и есть жизнь системы, ее постоянная борьба с энтропией.
Оригинал статьи: https://arxiv.org/pdf/2512.05946.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2025-12-08 13:50