Автор: Денис Аветисян
Исследование предлагает инновационную систему обучения с подкреплением, вдохновленную квантовыми вычислениями, для оптимизации работы цепей поставок в эпоху Интернета вещей.
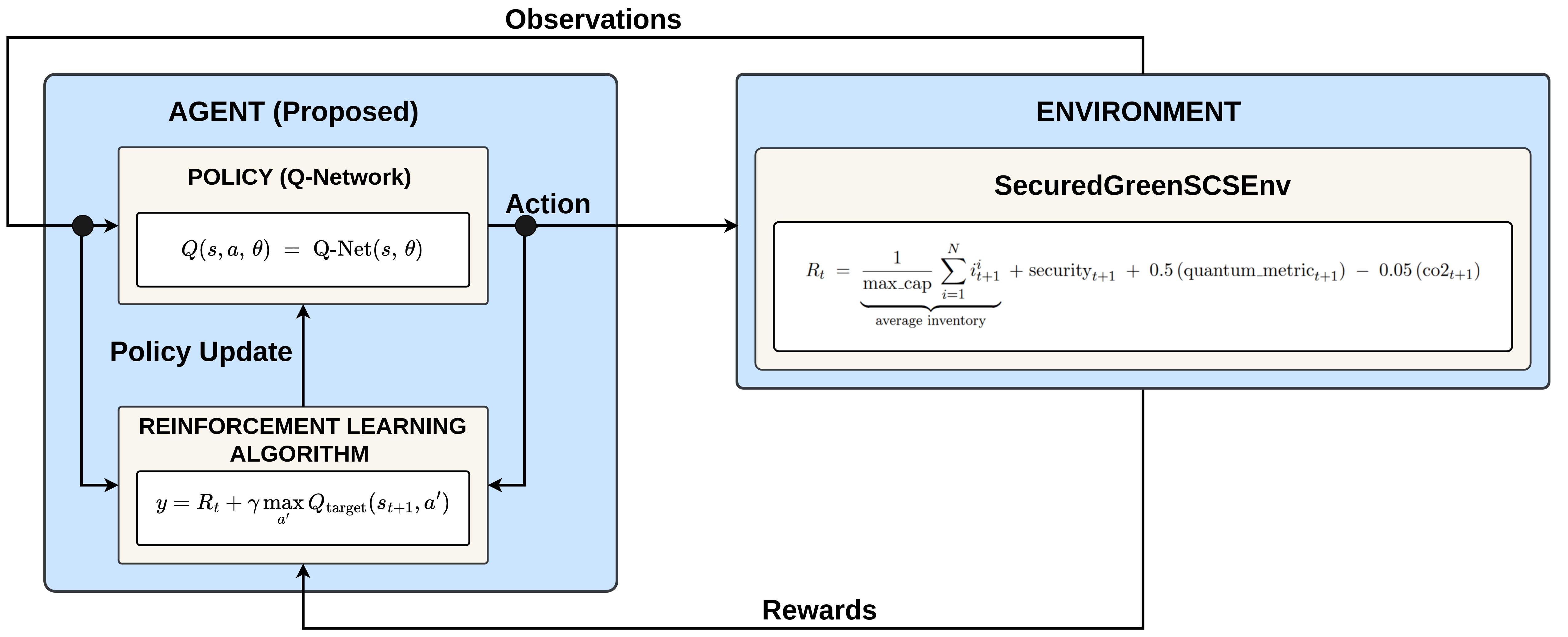
Предлагается фреймворк, объединяющий квантовое моделирование и данные AIoT для многоцелевой оптимизации, повышения безопасности и устойчивости систем управления цепями поставок.
Современные логистические цепочки сталкиваются с противоречием между необходимостью высокой скорости и требованиями экологической устойчивости и безопасности. В данной работе, посвященной теме ‘Quantum-Inspired Reinforcement Learning for Secure and Sustainable AIoT-Driven Supply Chain Systems’, предложен инновационный подход, объединяющий обучение с подкреплением, вдохновленное квантовыми вычислениями, и данные от Интернета вещей (AIoT). Разработанная система оптимизирует управление запасами, снижает выбросы углекислого газа и обеспечивает криптографическую безопасность, используя аналог спиновой цепи и многоцелевую функцию вознаграждения. Способны ли такие квантово-вдохновленные AIoT-системы сформировать основу для действительно устойчивых и безопасных глобальных цепочек поставок будущего?
Хрупкость Современных Цепей Поставок
Современные цепочки поставок, основанные на интеграции искусственного интеллекта и интернета вещей (AIoT), несмотря на свою взаимосвязанность, демонстрируют повышенную уязвимость к сбоям. Непредсказуемые события, такие как природные катаклизмы, геополитические конфликты или даже внезапные изменения в потребительском спросе, могут быстро нарушить логистические потоки. Более того, точность данных, поступающих от многочисленных сенсоров и систем мониторинга, зачастую оставляет желать лучшего, приводя к ошибочным прогнозам и неэффективным решениям. Это сочетание факторов создает эффект домино, когда небольшая неточность или локальный сбой может быстро распространиться по всей цепочке, приводя к серьезным финансовым потерям и репутационным рискам для предприятий.
Традиционные методы оптимизации, такие как прогнозирующее управление моделью (MPC), демонстрируют ограниченную эффективность в современных, чрезвычайно сложных цепочках поставок. Основанные на предположении о стабильности и предсказуемости систем, они испытывают трудности при столкновении с внезапными изменениями спроса, перебоями в поставках или неточностями данных. В результате, оптимизация, основанная на устаревших или неполных данных, приводит к неэффективному распределению ресурсов, увеличению издержек и, в конечном итоге, к сбоям в работе всей цепочки. Неспособность MPC быстро адаптироваться к новым условиям делает его уязвимым инструментом в эпоху глобальной нестабильности и растущей волатильности рынка, что подчеркивает необходимость разработки более гибких и адаптивных стратегий управления.
Уязвимость современных цепочек поставок значительно возрастает из-за присущего потокам данных шума и неопределенности. Поступающая информация, будь то данные о запасах, логистике или спросе, часто содержит неточности, искажения и пропуски, вызванные техническими сбоями, человеческим фактором или внешними помехами. Это приводит к формированию неполной или вводящей в заблуждение картины происходящего, что затрудняет принятие обоснованных решений и повышает риск сбоев. Традиционные методы оптимизации, такие как модельно-прогнозное управление, оказываются недостаточно устойчивыми к подобным помехам, поскольку предполагают высокую точность входных данных. В связи с этим, возникает потребность в разработке более надежных и адаптивных подходов, способных эффективно обрабатывать шумные и неполные данные, и обеспечивать стабильную работу цепочки поставок даже в условиях высокой неопределенности.
Квантовое Вдохновение для Устойчивости Цепей Поставок
Квантово-вдохновленная модель предлагает новый подход к управлению цепочками поставок, используя принципы квантовой механики для отражения сложных взаимосвязей между элементами системы. В отличие от традиционных методов, которые часто упрощают эти взаимодействия, данная модель позволяет учитывать корреляции и зависимости между различными компонентами цепочки поставок, такими как поставщики, производственные мощности, логистические узлы и конечные потребители. Это достигается за счет применения квантовых концепций для представления и анализа потоков данных, что позволяет более точно моделировать динамику системы и повысить ее устойчивость к различным внешним воздействиям и неопределенностям. Особенностью подхода является возможность моделирования нелинейных взаимодействий и эффектов, которые сложно или невозможно учесть с помощью классических методов.
Модель использует квантовую спиновую цепь для представления потока данных от устройств интернета вещей (AIoT). В данной модели каждый спин в цепи соответствует конкретному элементу данных или узлу в цепи поставок. Взаимодействие между спинами отражает корреляции и зависимости между этими элементами, позволяя моделировать сложные взаимосвязи, которые традиционные методы часто упускают из виду. Это позволяет учитывать каскадные эффекты и зависимость различных частей цепи поставок друг от друга, что критически важно для точного прогнозирования и эффективного управления рисками. Использование спиновой цепи позволяет моделировать нелинейные зависимости и коррелированные события, возникающие в реальных цепях поставок.
Модель, использующая квантово-подобное кодирование информации, демонстрирует повышенную устойчивость к различным видам шума, включая ошибки смены бита (Bit-Flip Noise), фазовые ошибки (Phase-Flip Noise) и деполяризующий шум (Depolarizing Noise). В отличие от классических методов, квантово-подобное представление данных позволяет модели сохранять более высокую среднюю награду при работе в зашумленных условиях. Это достигается за счет распределения информации таким образом, что отдельные ошибки оказывают меньшее влияние на общую производительность системы, обеспечивая надежность и стабильность функционирования даже при наличии помех в потоке данных.
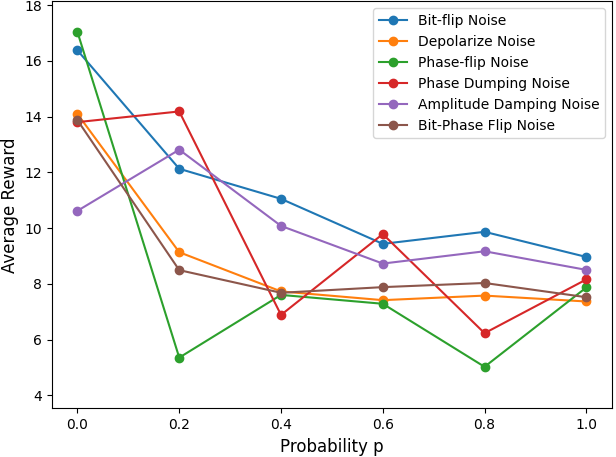
Интеллектуальные Агенты для Надежного Принятия Решений
Обучение с подкреплением (Reinforcement Learning) предоставляет структуру для тренировки агентов, способных оптимизировать операции в цепях поставок в условиях неопределенности. В рамках этого подхода, агент взаимодействует с симулированной средой цепи поставок, принимая решения относительно заказов, транспортировки и управления запасами. Каждое действие агента оценивается посредством функции вознаграждения, отражающей ключевые показатели эффективности, такие как стоимость, уровень обслуживания и время выполнения заказов. Алгоритмы обучения с подкреплением, такие как Q-learning или Policy Gradient, позволяют агенту итеративно улучшать свою стратегию принятия решений, максимизируя суммарное вознаграждение и адаптируясь к изменяющимся условиям и случайным событиям, таким как задержки поставок или колебания спроса. Это обеспечивает автоматизированную оптимизацию сложных логистических процессов, учитывая различные ограничения и цели.
Комбинирование обучения с подкреплением с многоцелевой стратегией позволяет осуществлять целостную оптимизацию логистических операций. Данный подход предполагает одновременное рассмотрение нескольких, часто противоречивых, целей: управления запасами, минимизации выбросов углерода и обеспечения безопасности поставок. Обучение с подкреплением обеспечивает механизм для поиска оптимальной политики, балансирующей между этими целями, в то время как многоцелевая стратегия формализует требования к каждой из них. Например, штрафы за выбросы углерода могут быть включены в функцию вознаграждения, побуждая агента выбирать более экологичные маршруты и методы транспортировки, даже если это связано с незначительным увеличением затрат или времени доставки. Аналогично, обеспечение безопасности может быть представлено как ограничение, которое агент должен соблюдать при принятии решений, даже если это снижает эффективность использования ресурсов.
Применение робастных марковских процессов принятия решений (Robust Markov Decision Processes, RMDP) и дистрибутивно-робастных расширений (Distributionally Robust Extensions, DRE) обеспечивает формальный подход к учету наихудших сценариев и реальных возмущений в задачах оптимизации. RMDP моделируют неопределенность в динамике среды, минимизируя максимальные потери в рамках заданного множества возможных сценариев. DRE расширяют этот подход, учитывая не только точечные оценки неопределенности, но и её распределение, что позволяет более точно оценивать риски и строить стратегии, устойчивые к широкому спектру отклонений от ожидаемых значений. В контексте управления цепями поставок, это позволяет разрабатывать решения, гарантирующие приемлемый уровень производительности даже при значительных колебаниях спроса, сбоях в поставках или других неблагоприятных факторах. Формализация неопределенности через RMDP и DRE позволяет применять математические методы для гарантии надежности и устойчивости решений, в отличие от эвристических подходов.
Оптимизация Производительности и Адаптивности Агентов
Применение таких методов, как Deep Q-Network и Proximal Policy Optimization, значительно расширяет возможности обучения агентов, позволяя им эффективно адаптироваться к меняющимся условиям. Deep Q-Network, используя глубокие нейронные сети для аппроксимации Q-функции, позволяет агентам находить оптимальные стратегии в сложных пространствах состояний. Proximal Policy Optimization, в свою очередь, обеспечивает более стабильное обучение за счет ограничения изменений в политике агента, предотвращая резкие ухудшения производительности. Сочетание этих методов позволяет создавать интеллектуальных агентов, способных не только быстро осваивать новые задачи, но и поддерживать высокую эффективность в динамично меняющейся среде, что особенно важно для приложений, требующих гибкости и устойчивости к непредсказуемым факторам.
Ансамблевое обучение с подкреплением значительно повышает устойчивость систем искусственного интеллекта, объединяя несколько агентов, каждый из которых обладает собственной уникальной точкой зрения и стратегией обучения. Такой подход позволяет компенсировать недостатки отдельных агентов, поскольку ошибки одного агента могут быть скорректированы другими, что приводит к более надежным и стабильным результатам. Разнообразие стратегий обучения в ансамбле позволяет адаптироваться к более широкому спектру ситуаций и неопределенностей, что особенно важно в динамичных и сложных средах, где требуется гибкость и способность к быстрому обучению. Использование ансамблевого подхода позволяет не просто улучшить среднюю производительность, но и снизить риск принятия неоптимальных решений в критических ситуациях, повышая общую надежность системы.
Разработанный подход к обучению с подкреплением, вдохновленный принципами квантовых вычислений, продемонстрировал выдающиеся результаты в моделировании цепочек поставок. В ходе экспериментов зафиксирован пиковый уровень вознаграждения в 20.51, что значительно превосходит показатели, достигнутые традиционными методами обучения с подкреплением и модельно-ориентированными алгоритмами. Оптимальная конфигурация системы обеспечила средний уровень вознаграждения в 19.49, подтверждая её превосходство над всеми протестированными альтернативами и демонстрируя потенциал для повышения эффективности и адаптивности в сложных динамических средах.
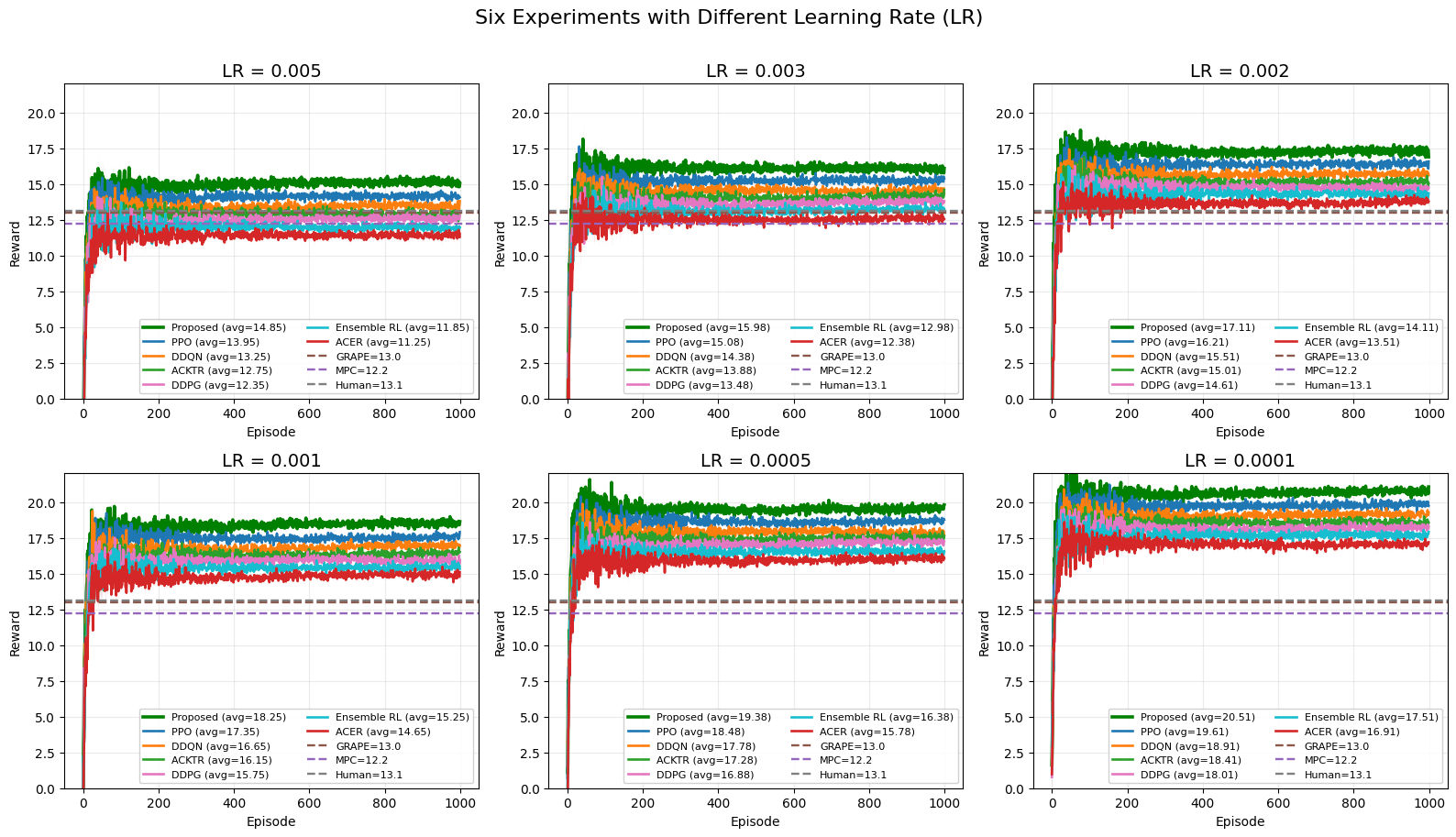
К Будущему Устойчивых Цепей Поставок
Предложенный подход, основанный на принципах квантового вдохновения и обучении с подкреплением, открывает новые возможности для создания цепей поставок, способных не только эффективно функционировать, но и успешно противостоять различным сбоям и быстро адаптироваться к меняющимся условиям. В отличие от традиционных систем, которые часто оказываются хрупкими перед лицом неожиданных событий, данная методика позволяет формировать динамичные и гибкие цепи, способные автоматически перестраиваться и минимизировать негативные последствия от нарушений. Обучение с подкреплением позволяет системе самостоятельно находить оптимальные стратегии управления запасами, маршрутизацией и распределением ресурсов, учитывая множество факторов и прогнозируя возможные риски. Такой проактивный подход обеспечивает не только повышение устойчивости к внешним воздействиям, но и значительное улучшение общей эффективности и конкурентоспособности цепи поставок.
Интеграция принципов устойчивого развития и приоритезация безопасности открывают возможности для создания экономически эффективных и экологически ответственных цепочек поставок. Внедрение таких механизмов, как штрафы за выбросы углерода, позволяет учитывать экологические издержки и стимулировать использование более экологичных логистических решений. Параллельно, акцент на безопасности обеспечивает стабильность поставок и снижает риски, связанные с различными угрозами. Такой комплексный подход позволяет не только оптимизировать финансовые показатели, но и минимизировать негативное воздействие на окружающую среду, создавая долгосрочную ценность для бизнеса и общества в целом. В результате, формируется система, способная адаптироваться к меняющимся условиям и обеспечивать бесперебойное функционирование даже в условиях нестабильности.
Оптимальная конфигурация коэффициентов вознаграждения, установленная на уровне (1.0, 1.0, 0.5), демонстрирует эффективный баланс между точностью выполнения заказов, обеспечением безопасности и снижением выбросов углекислого газа. Данный набор параметров позволяет создать устойчивую к сбоям и экологически ответственную систему поставок. Продолжающиеся исследования, направленные на применение передовых методов оптимизации, таких как GRAPE, и изучение новых стратегий управления, призваны усовершенствовать данную структуру и полностью раскрыть её потенциал для создания гибких и надёжных цепочек поставок будущего.
Исследование, представленное в статье, стремится к оптимизации сложных систем поставок, используя принципы, вдохновленные квантовой физикой и машинным обучением с подкреплением. В этом стремлении к ясности и эффективности можно увидеть отголоски мудрости Дональда Дэвиса: «Каждая сложность требует алиби». Действительно, предложенная модель, интегрируя данные AIoT и спин-цепочное моделирование, стремится не просто добавить новые элементы, а упростить управление и повысить устойчивость системы. Основная идея, заключающаяся в многоцелевой оптимизации, демонстрирует, что истинное совершенство достигается не за счет увеличения сложности, а благодаря её сокращению и выстраиванию чётких, понятных принципов.
Что дальше?
Представленная работа, несмотря на попытку интеграции квантово-вдохновленного подхода с оптимизацией цепей поставок, оставляет нерешенными вопросы, которые неизбежно возникают при столкновении абстрактной математики с жестокой реальностью. Эффективность предложенных алгоритмов, несомненно, зависит от качества и доступности данных, генерируемых системами AIoT, и пока неясно, насколько устойчива эта система к преднамеренным искажениям или простому шуму. В конечном счете, сложность моделирования, даже с использованием квантово-вдохновленных методов, лишь отражает сложность самой системы, а не упрощает её.
Будущие исследования должны сосредоточиться на разработке методов, позволяющих оценивать и смягчать риски, связанные с неполнотой или недостоверностью данных. Более того, необходимо исследовать возможности применения аналогичных подходов к другим, не менее сложным системам, где взаимодействие множества факторов требует поиска оптимальных решений. Иллюзия совершенства, создаваемая сложными моделями, должна быть отброшена в пользу стремления к ясности и практической применимости.
В конечном счете, задача состоит не в создании все более изощренных алгоритмов, а в понимании фундаментальных ограничений, которые накладывает реальный мир на любые попытки оптимизации. И, возможно, в осознании того, что иногда лучшее решение — это простое и понятное, даже если оно не является оптимальным в строгом математическом смысле.
Оригинал статьи: https://arxiv.org/pdf/2601.22339.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Роботы учатся видеть: новая стратегия управления на основе видео
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Квантовый оптимизатор: Новый подход к сложным задачам
2026-02-02 14:55