Автор: Денис Аветисян
Новое исследование оценивает, насколько хорошо современные мультимодальные модели справляются с распознаванием лиц в условиях различных спектральных искажений.
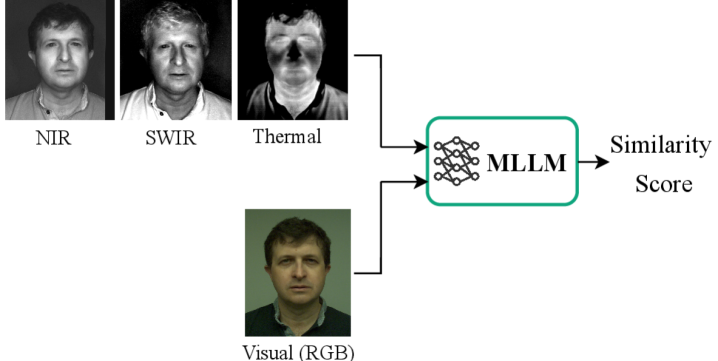
Оценка производительности больших мультимодальных моделей в задачах гетерогенного распознавания лиц, включая сценарии с переходом между различными спектральными диапазонами.
Несмотря на впечатляющие успехи в области обработки мультимодальных данных, большие языковые модели (MLLM) показывают ограниченную эффективность в задачах гетерогенного распознавания лиц. В работе ‘Evaluating Multimodal Large Language Models for Heterogeneous Face Recognition’ проведена систематическая оценка современных MLLM в сценариях распознавания лиц по изображениям, полученным с использованием различных спектральных диапазонов — видимого, ближнего инфракрасного, коротковолнового инфракрасного и тепловизионного. Полученные результаты демонстрируют значительный разрыв в производительности между MLLM и специализированными системами распознавания лиц, особенно в сложных кросс-спектральных условиях. Какие архитектурные и тренировочные стратегии позволят MLLM эффективно решать задачи гетерогенной биометрической идентификации?
Разрыв между реальностью и идеальной теорией распознавания лиц
Традиционные системы распознавания лиц сталкиваются с существенными трудностями при обработке изображений, полученных в различных условиях освещения, с разных углов обзора и с использованием различных сенсорных технологий. Неоднородность входных данных — будь то изменения интенсивности света, повороты головы или разница между видимым и инфракрасным спектром — приводит к снижению точности и надежности идентификации. Эта проблема возникает из-за того, что алгоритмы, обученные на одном типе изображений, часто испытывают трудности с обобщением на данные, отличающиеся по своим характеристикам. В результате, системы могут ошибочно идентифицировать людей или не распознавать их вовсе, что особенно критично в приложениях, связанных с безопасностью и контролем доступа. Современные исследования направлены на разработку более устойчивых алгоритмов, способных эффективно справляться с этими вариациями и обеспечивать высокую точность распознавания в различных условиях.
Существенное препятствие для надежной идентификации лиц заключается в так называемом “разрыве между модальностями” — различиях в способах получения изображений. Например, изображение, полученное в видимом свете, существенно отличается от изображения, полученного в инфракрасном диапазоне, даже если на нем запечатлено одно и то же лицо. Эти различия касаются не только цветовой гаммы, но и деталей, видимых в разных спектрах. Традиционные алгоритмы распознавания лиц, обученные на изображениях одного типа, часто демонстрируют значительное снижение точности при анализе изображений, полученных с использованием другой модальности. Преодоление этого разрыва требует разработки новых методов, способных эффективно объединять информацию из различных источников, учитывая специфические особенности каждого из них и обеспечивая устойчивость к изменениям в условиях съемки.
Методы сближения разнородных данных: от проекций до синтеза
Методы проецирования в общее пространство и извлечения инвариантных признаков направлены на уменьшение разрыва между различными модальностями изображений путем преобразования гетерогенных данных в унифицированное представление. Данные методы используют математические преобразования, такие как преобразование главных компонент (PCA) или линейный дискриминантный анализ (LDA), для создания общего векторного пространства, в котором изображения из разных модальностей (например, ближнего инфракрасного и видимого спектра) могут быть сопоставлены и сравнены. Инвариантные признаки, в свою очередь, выделяются таким образом, чтобы быть устойчивыми к изменениям в модальности, освещении или позе объекта, что позволяет проводить более надежное сопоставление и распознавание. Эффективность этих методов напрямую зависит от выбора подходящих преобразований и признаков, а также от качества исходных данных.
Методы, основанные на синтезе, стремятся преобразовать изображения из одной модальности (например, ближнего инфракрасного спектра — NIR) в другую (например, видимого спектра — VIS), что позволяет проводить сопоставление данных, полученных из разных источников. Данный подход предполагает построение моделей, способных генерировать изображения в целевой модальности на основе входных данных из исходной модальности. Эффективность таких методов напрямую зависит от сложности используемой архитектуры и объема обучающих данных, необходимых для достижения реалистичных и точных преобразований изображений. В результате, становится возможным применение алгоритмов обработки изображений, разработанных для одной модальности, к данным, представленным в другой.
Реализация надежных систем распознавания лиц, использующих мультимодальные данные, требует применения сложных архитектур нейронных сетей. Эффективная обработка и интеграция разнородных потоков данных, таких как изображения в видимом и инфракрасном диапазонах, предъявляет высокие требования к вычислительным ресурсам и алгоритмической сложности. Современные подходы включают в себя многослойные сверточные сети (CNN), сети с вниманием (attention networks) и графовые нейронные сети (GNN) для моделирования взаимосвязей между различными модальностями и извлечения наиболее релевантных признаков. Для достижения высокой точности и устойчивости к изменениям условий освещения и позы необходимо учитывать специфику каждой модальности и разрабатывать специализированные модули для их обработки и объединения.
Мультимодальные LLM: новый рубеж в идентификации лиц
Многомодальные большие языковые модели (LLM) обладают способностью обрабатывать как визуальные, так и текстовые входные данные, предоставляя мощную основу для интеграции различных модальностей изображений лиц. Это достигается за счет объединения возможностей обработки естественного языка с возможностями компьютерного зрения, что позволяет моделям не только распознавать лица на изображениях, но и понимать контекст, связанный с этими изображениями, и извлекать информацию из текстовых описаний. Такая интеграция позволяет использовать различные типы входных данных, такие как фотографии, видео и текстовые метки, для повышения точности и надежности систем распознавания лиц, а также для решения более сложных задач, таких как идентификация личности по описанию или анализ эмоций на основе визуальных и текстовых данных.
Модели, такие как Gemma 3, Mistral, LLaVA, InternVL3, Qwen3-VL и Aya-Vision, представляют собой расширение возможностей существующих больших языковых моделей (LLM) за счет интеграции функций обработки визуальной информации. Эти модели позволяют не только понимать текст, но и анализировать изображения, что обеспечивает более комплексное и точное восприятие данных. Они достигают этого, используя архитектуру Transformer для обработки как текстовых, так и визуальных признаков, что позволяет им устанавливать связи между ними и выполнять задачи, требующие понимания обоих типов информации. В частности, они способны к выполнению задач, связанных с распознаванием объектов, описанием изображений и ответами на вопросы, основанные на визуальном контенте.
Архитектура Transformer является ключевым компонентом многомодальных больших языковых моделей, обеспечивая возможность захвата сложных взаимосвязей между визуальными признаками и семантической информацией. Основываясь на механизмах внимания (attention), Transformer позволяет модели взвешивать различные части входного изображения и текста, определяя наиболее релевантные признаки для конкретной задачи распознавания лиц. Этот подход позволяет эффективно обрабатывать как локальные детали (например, форма глаз или носа), так и глобальный контекст изображения, что критически важно для точного анализа и интерпретации данных. Использование многоголовочного внимания (multi-head attention) дополнительно повышает способность модели к улавливанию различных типов зависимостей между признаками, улучшая общую производительность в задачах распознавания лиц и понимания визуальной информации.
Оценка производительности и перспективы развития мультимодального распознавания лиц
Для оценки эффективности мультимодальных больших языковых моделей (MLLM) в задачах распознавания лиц используются ключевые метрики, позволяющие количественно оценить их производительность. Истинную долю принятия (True Accept Rate) измеряют как процент правильно идентифицированных лиц, в то время как ложную долю принятия (False Accept Rate) и ложную долю отказа (False Reject Rate) отражают ошибки системы. Объединенная метрика — равная ошибка (Equal Error Rate) — показывает точку, в которой эти две ошибки выравниваются, давая общее представление о точности. Наконец, доля приобретения (Acquire Rate) указывает на способность модели успешно распознавать лица в различных условиях и при различных входных данных. Комбинация этих метрик позволяет всесторонне оценить надежность и эффективность MLLM в сложных сценариях распознавания лиц.
Оценка производительности мультимодальных систем распознавания лиц проводится с использованием изображений, полученных в различных спектральных диапазонах, включая видимый свет, ближний инфракрасный, коротковолновый инфракрасный и тепловой. Такой подход позволяет всесторонне проверить устойчивость системы к изменениям условий освещения, погодным условиям и даже маскировке. Анализ точности распознавания по каждому спектральному каналу выявляет сильные и слабые стороны алгоритмов, а также позволяет определить, насколько эффективно система объединяет информацию из разных источников для повышения общей надежности. Комплексная оценка в различных модальностях является ключевым фактором в разработке систем распознавания лиц, способных функционировать в реальных условиях и обеспечивать высокую степень безопасности и точности.
Недавние оценки демонстрируют, что современные мультимодальные языковые модели (MLLM) пока уступают специализированным моделям распознавания лиц в сложных условиях, особенно при переходе между различными спектральными диапазонами. Показатель Acquire Rate (AR), характеризующий успешность распознавания, значительно варьируется между различными MLLM: Aya-Vision-8B достигает 93.7%, Aya-Vision-32B — 95.8%, а Mistral-3.1-24B показывает наилучший результат в 96.9%. Данные различия подчеркивают необходимость дальнейшей оптимизации MLLM для обеспечения сопоставимой или превосходящей производительности в задачах распознавания лиц, требующих устойчивости к изменениям условий освещения и спектрального состава изображения.
Разработка многомодальных систем распознавания лиц открывает перспективы для создания более точных, надежных и гибких систем идентификации. Данный подход позволяет значительно расширить области применения технологии: от повышения эффективности систем безопасности и видеонаблюдения, где важна безошибочная идентификация в различных условиях освещения и съемки, до совершенствования систем контроля доступа, обеспечивающих защиту объектов и персональных данных. Кроме того, появляется возможность реализации персонализированных сервисов и пользовательских интерфейсов, адаптирующихся к индивидуальным особенностям и предпочтениям, что создает новые возможности для взаимодействия человека и машины и улучшает качество предоставляемых услуг.
Исследование производительности больших мультимодальных моделей (MLLM) в гетерогенном распознавании лиц закономерно выявило их слабость в кросс-спектральных сценариях. Как будто кто-то решил, что достаточно обучить модель на красивых фотографиях, чтобы она работала в условиях плохой освещенности или с изображениями, полученными в разных диапазонах спектра. Впрочем, это не новость. Как однажды заметил Ян Лекун: «Машинное обучение — это искусство перевода желаний в инструкции». Здесь же желания оказались слишком амбициозными для текущего уровня автоматизации, и элегантная теория столкнулась с суровой реальностью продакшена. Иначе говоря, MLLM пока что хороши в демонстрациях, но до надежности специализированных моделей им еще далеко.
Что дальше?
Очередная демонстрация мощи больших языковых моделей, конечно. Но, как обычно, дьявол кроется в деталях — и в спектральных искажениях, как показало исследование. Модели, безусловно, впечатляют своей способностью к обобщению, но когда дело доходит до реальных, грязных данных — данных, которые не прошли тщательную предобработку и не были аккуратно выровнены — они начинают спотыкаться. Неудивительно, впрочем. Все новое — это просто старое с худшей документацией, а задача распознавания лиц, как известно, богата на краевые случаи и нюансы.
Похоже, что энтузиазм вокруг vision-language моделей несколько опережает здравый смысл. Они умеют «понимать» картинки, но распознавание лиц — это не просто понимание, это точное сопоставление мельчайших деталей в условиях постоянных помех. И пока эти модели пытаются «понять», специализированные алгоритмы просто делают свою работу. Впрочем, можно предположить, что следующая волна исследований будет направлена на преодоление этих ограничений — возможно, путем интеграции специализированных модулей или разработки более устойчивых к шуму архитектур.
В конечном итоге, задача остается прежней: создать систему, которая надежно работает в реальных условиях. И пусть модных фреймворков становится все больше, а buzzwords звучат все громче, стоит помнить, что фундаментальные проблемы остаются нерешенными. И пока энтузиасты изобретают новые библиотеки, инженеры будут бороться с теми же старыми багами, просто упакованными в новую обертку. Всё как обычно.
Оригинал статьи: https://arxiv.org/pdf/2601.15406.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-24 18:30