Автор: Денис Аветисян
Новый обзор всесторонне анализирует типичные ошибки в рассуждениях больших языковых моделей, выявляя их слабые места и предлагая пути решения.
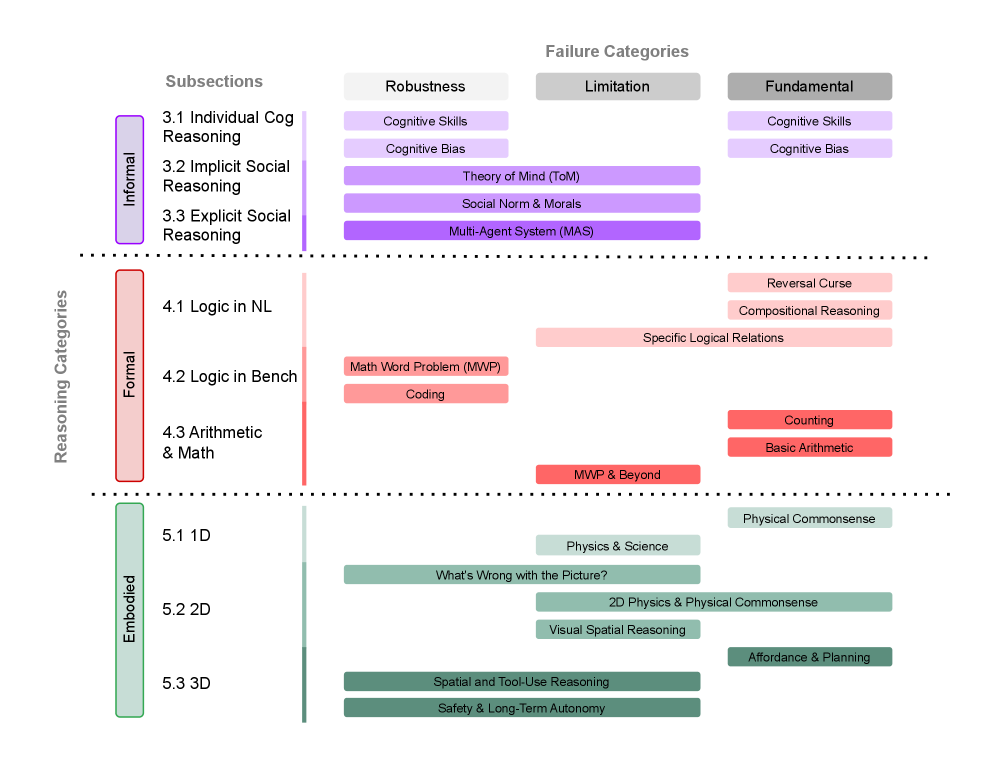
В статье представлена подробная таксономия ошибок, классифицированных по типам рассуждений: формальным, неформальным и воплощенным.
Несмотря на впечатляющие успехи в решении широкого спектра задач, большие языковые модели (LLM) демонстрируют существенные провалы в рассуждениях, даже в кажущихся простыми сценариях. В работе ‘Large Language Model Reasoning Failures’ представлен первый всесторонний обзор, посвященный систематизации этих недостатков. Авторы предлагают новую классификацию, выделяющую типы рассуждений — воплощенное и невоплощенное (с подразделением на интуитивное и логическое), а также типы ошибок — фундаментальные, специфичные для конкретной области и связанные с недостаточной устойчивостью. Каковы перспективы создания более надежных и эффективных LLM, способных к последовательным и обоснованным выводам?
Пределы Языка: Разоблачение Ошибок Рассуждений
Современные большие языковые модели демонстрируют удивительную способность генерировать связные и грамматически верные тексты, зачастую неотличимые от созданных человеком. Однако, несмотря на кажущуюся беглость речи, эти модели систематически терпят неудачу при решении задач, требующих сложного логического мышления. Проблемы возникают не из-за недостатка информации, а из-за особенностей принципа работы — модели, по сути, оперируют статистическими закономерностями в тексте, а не глубоким пониманием смысла. Это приводит к тому, что даже при идеальном владении языком, модели могут давать неверные ответы на вопросы, требующие анализа, обобщения или применения знаний в новых ситуациях, подчеркивая разницу между лингвистической компетенцией и истинным интеллектом.
Ошибки, демонстрируемые большими языковыми моделями, не сводятся к банальному отсутствию знаний в их базе данных. Исследования показывают, что корень проблемы кроется в принципиальных ограничениях самого процесса обработки информации. Модели, обученные на распознавании паттернов и статистических закономерностях в тексте, испытывают трудности, когда требуется не просто воспроизвести увиденное, а осуществить логический вывод, построить причинно-следственную связь или применить знания в новой, незнакомой ситуации. По сути, эти системы превосходно умеют имитировать рассуждения, но не способны к истинному логическому мышлению, что и приводит к неожиданным и порой абсурдным результатам при решении задач, требующих более глубокого анализа.
Исследования показывают, что языковые модели, демонстрирующие впечатляющую беглость речи, зачастую терпят неудачу в задачах, требующих не просто сопоставления шаблонов, а настоящего логического мышления. Особенно заметны эти ограничения при столкновении с принципиально новыми, ранее не встречавшимися ситуациями. Модели, обученные на огромных массивах данных, способны успешно воспроизводить известные закономерности, однако испытывают трудности, когда необходимо экстраполировать знания или применять их в нестандартных обстоятельствах. Это указывает на то, что текущие архитектуры языковых моделей, хоть и эффективны в статистическом анализе текста, не обладают способностью к гибкому и адаптивному мышлению, характерному для человеческого интеллекта, и не могут полноценно решать задачи, требующие креативности и интуиции.
Спектр Рассуждений: Формальное, Неформальное и Воплощенное
Рассуждение не является единым процессом, а включает в себя различные подходы, варьирующиеся от строгой логики формального мышления до интуитивных скачков неформального мышления. Формальное рассуждение опирается на установленные правила вывода и логические принципы, стремясь к дедуктивно обоснованным заключениям. В противоположность этому, неформальное рассуждение использует эвристики, аналогии и вероятностные оценки, часто применяясь в ситуациях, где полные данные отсутствуют или решение требует быстрого анализа. Различие между этими подходами заключается в степени формализации и обоснованности, при этом каждый из них играет важную роль в решении различных типов задач и принятии решений.
Большие языковые модели (LLM) демонстрируют существенные трудности в задачах, требующих формального рассуждения. В частности, LLM подвержены так называемому «проклятию инверсии» (reversal curse), когда изменение порядка логических утверждений в задаче приводит к резкому снижению точности решения. Кроме того, LLM испытывают проблемы с решением комплексных композиционных задач, требующих последовательного применения нескольких логических шагов или объединения информации из различных источников. Эти недостатки связаны с архитектурой LLM, основанной на статистическом анализе текста, а не на символической обработке знаний и дедуктивном выводе, характерных для формальных систем рассуждений.
В отличие от людей, большие языковые модели (LLM) не обладают воплощенным мышлением — способностью обосновывать выводы на основе физического взаимодействия и пространственного понимания. Это означает, что LLM испытывают трудности в решении задач, требующих понимания физических свойств объектов, их взаиморасположения в пространстве и последствий физических действий. Например, модели могут испытывать затруднения при прогнозировании траектории движения объекта, определении устойчивости конструкции или планировании манипуляций с предметами в реальном мире, поскольку их знания ограничены текстовыми данными и не подкреплены опытом непосредственного взаимодействия с окружающей средой.

Устранение Недостатков: Стратегии для Улучшенного Рассуждения
Метод дополнения извлечением (Retrieval Augmentation) представляет собой перспективный подход к повышению точности и снижению фактических ошибок больших языковых моделей (LLM). Суть метода заключается в предоставлении LLM доступа к внешним базам знаний во время генерации ответа. Вместо того, чтобы полагаться исключительно на знания, заложенные в процессе обучения, LLM извлекает релевантную информацию из внешнего источника и интегрирует ее в генерируемый текст. Это позволяет эффективно компенсировать пробелы в знаниях модели и предоставлять более точные и контекстуально обоснованные ответы, особенно в областях, где обучение LLM было ограничено или устарело. Эффективность метода напрямую зависит от качества и релевантности извлекаемой информации, а также от способности LLM правильно интегрировать ее в сгенерированный текст.
Калибровка больших языковых моделей (LLM) является критически важным процессом, обеспечивающим соответствие между уверенностью модели в своих ответах и фактической точностью этих ответов. Простое увеличение объема предоставляемой информации не гарантирует повышение надежности LLM; модель может выдавать неверные ответы с высокой степенью уверенности, что вводит пользователей в заблуждение. Калибровка предполагает настройку выходных вероятностей модели таким образом, чтобы они отражали истинную вероятность правильности ответа. Существуют различные методы калибровки, включая Temperature Scaling и Platt Scaling, которые позволяют скорректировать уверенность модели без изменения ее предсказательной способности. Необходимо регулярно оценивать и корректировать калибровку LLM, особенно при изменении входных данных или задач, чтобы поддерживать высокую надежность и предотвратить распространение недостоверной информации.
Для противодействия злонамеренным манипуляциям, методы водяных знаков (watermarking) становятся критически важными для идентификации текстов, сгенерированных большими языковыми моделями (LLM), и предотвращения распространения дезинформации. Эти методы предусматривают внедрение незаметных изменений в выходной текст, которые позволяют отличить его от контента, созданного человеком. Существуют различные подходы к водяным знакам, включая изменения в распределении вероятностей токенов или использование скрытых сигналов в семантическом пространстве. Эффективность этих методов зависит от их устойчивости к различным видам атак, таким как перефразирование или удаление текста, и требует постоянного совершенствования для противодействия новым угрозам.
За Пределами Синтаксиса: Роль Мировых Моделей и Теории Разума
Для эффективного рассуждения необходима внутренняя “модель мира” — когнитивное представление об окружающей среде, позволяющее прогнозировать развитие событий и планировать действия. В отличие от человека, современные большие языковые модели (LLM) не обладают подобной структурой. Они оперируют лишь статистическими закономерностями в данных, что позволяет им генерировать текст, но не понимать причинно-следственные связи и предвидеть последствия. Отсутствие внутренней модели мира ограничивает их способность к настоящему рассуждению, поскольку они не могут самостоятельно оценить правдоподобность или осмысленность своих выводов, полагаясь исключительно на вероятностные прогнозы. Это приводит к тому, что LLM могут генерировать грамматически правильные, но логически несостоятельные или бессмысленные утверждения, неспособные к адаптации к новым, не предусмотренным в обучающих данных ситуациям.
Существенным ограничением современных больших языковых моделей является недостаток так называемой “теории разума” — способности понимать убеждения, намерения и перспективы других. Этот дефицит препятствует эффективному участию в сложном социальном рассуждении, поскольку модели испытывают трудности с предсказанием действий, мотивированных внутренними состояниями других агентов. Вместо того, чтобы понимать почему кто-то действует определенным образом, языковые модели склонны выявлять лишь статистические закономерности в данных, не улавливая истинных причинно-следственных связей, лежащих в основе социального взаимодействия. Это проявляется в неспособности корректно интерпретировать иронию, сарказм или ложные убеждения, что существенно ограничивает их возможности в задачах, требующих понимания социальных нюансов и эмпатии.
Современные языковые модели демонстрируют впечатляющую способность к синтаксической обработке информации, умело манипулируя структурой языка и генерируя грамматически корректные тексты. Однако, за этой внешней безупречностью скрывается фундаментальное ограничение: модели испытывают трудности с семантическим пониманием и истинным логическим выводом. Они способны имитировать понимание, но не обладают способностью извлекать смысл, улавливать нюансы и проводить обоснованные умозаключения, опираясь на реальное знание о мире. Это означает, что, несмотря на всю свою мощь в обработке языка, модели зачастую оперируют лишь поверхностными закономерностями, не доходя до глубокого осмысления и истинного понимания представленной информации.
Исследование неудач больших языковых моделей в рассуждениях, представленное в работе, неизбежно напоминает о тщетности любых абстракций перед лицом реальности. Авторы тщательно классифицируют ошибки — от формальных до воплощенных, создавая своего рода анатомический атлас интеллектуальных провалов. Это напоминает о том, что даже самые сложные алгоритмы, призванные имитировать человеческое мышление, подвержены закономерным сбоям. Как точно подметил Андрей Колмогоров: «Математика — это искусство того, что очевидно». Однако, в контексте LLM, очевидность часто ускользает, погребаясь под слоями параметров и вероятностей. Ведь всё, что можно задеплоить — однажды упадёт, и эти “упадения” часто оказываются следствием логических ошибок, тщательно задокументированных в данной работе.
Что дальше?
Представленный анализ, столь тщательно классифицирующий ошибки больших языковых моделей, неизбежно наводит на мысль о том, что за каждой «революцией» скрывается лишь новая форма старых проблем. Формальные, неформальные, воплощённые рассуждения — названия меняются, а суть остаётся прежней: машина пытается имитировать интеллект, не имея ни опыта, ни здравого смысла. И, как всегда, продакшен найдёт способ заставить всё это работать… до тех пор, пока не сломается в самый неподходящий момент.
Так называемая «безопасность ИИ» представляется особенно забавной. Словно можно запрограммировать осторожность в систему, построенную на статистической вероятности. Скорее всего, все эти классификации и таксономии лишь создадут иллюзию контроля, пока модели не начнут выдавать совершенно неожиданные и необъяснимые ошибки. Ведь всё новое — это просто старое с худшей документацией.
В конечном итоге, можно предположить, что исследования будут двигаться в направлении всё более сложных и изощрённых способов обхода этих ошибок, а не в направлении их фундаментального устранения. И так будет до тех пор, пока кто-нибудь не вспомнит, что иногда лучшее решение — это просто отказаться от сложной системы и вернуться к чему-то простому и надёжному. Хотя, конечно, это было бы невыгодно.
Оригинал статьи: https://arxiv.org/pdf/2602.06176.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Искусственный интеллект на службе редких болезней
- Наука, управляемая интеллектом: новая эра открытий
- Генетическая приоритизация: новый взгляд на отбор генов
- Квантовый Переворот: От Теории к Реальности
- Видео-Мыслитель: гармония разума и визуального потока.
- Квантовый поиск: новый взгляд на оптимизацию
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
2026-02-10 01:15