Автор: Денис Аветисян
Новое исследование показывает, что принудительный порядок генерации текста в диффузионных языковых моделях, вопреки интуиции, повышает их способность к логическому мышлению.
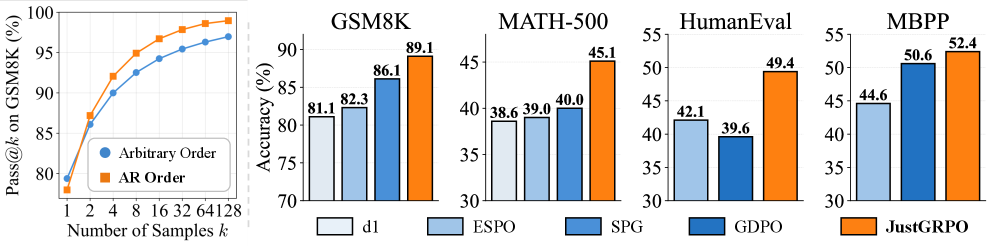
Ограничение произвольности порядка декодирования во время обучения с подкреплением предотвращает преждевременное сужение пространства решений и улучшает рассудочные возможности моделей.
Неочевидно, что расширение возможностей генерации токенов в диффузионных языковых моделях (dLLM) всегда приводит к улучшению их рассуждений. В работе ‘The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models’ авторы исследуют парадокс, заключающийся в том, что произвольный порядок генерации, хотя и кажется интуитивно полезным, на деле может сужать пространство поиска решений. Они показали, что dLLM склонны избегать токенов с высокой неопределенностью, что приводит к преждевременному коллапсу процесса рассуждений. Может ли намеренное ограничение порядка генерации и применение стандартных алгоритмов обучения с подкреплением, таких как GRPO, открыть путь к более эффективному использованию потенциала dLLM для решения сложных задач?
За пределами Авторегрессии: Новая Парадигма Генерации Последовательностей
Традиционные языковые модели, такие как рекуррентные нейронные сети и трансформеры, функционируют на основе авторегрессивного подхода, последовательно предсказывая следующий элемент в последовательности. Этот метод, хотя и доказал свою эффективность, имеет фундаментальные ограничения. Каждая новая предсказания зависит от предыдущих, что исключает возможность параллельной обработки и существенно ограничивает глубину рассуждений модели. В результате, сложные задачи, требующие одновременного анализа множества потенциальных решений или долгосрочного планирования, оказываются особенно сложными для таких моделей. Ограниченная параллелизация также снижает скорость генерации последовательностей, что является критичным для приложений реального времени и обработки больших объемов данных.
Несмотря на свою эффективность, традиционные языковые модели часто испытывают трудности при решении сложных задач, требующих исследования множества возможных путей решения. Ограничение связано с последовательным характером генерации: каждая новая единица текста формируется на основе предыдущей, что препятствует одновременному рассмотрению альтернативных вариантов. В ситуациях, где требуется творческий подход или анализ нескольких перспектив, модель может застревать в локальных оптимумах или упускать из виду более оптимальные решения, поскольку не обладает возможностью «отступить» и исследовать другие ветви генерации. Эта проблема особенно заметна при решении задач, требующих логического вывода, планирования или креативного письма, где успех зависит от способности оценивать и комбинировать различные варианты развития событий.
В отличие от традиционных языковых моделей, использующих авторегрессионный подход, диффузионные большие языковые модели (Diffusion LLM) предлагают принципиально иную парадигму генерации последовательностей. Вместо последовательного предсказания следующего токена, они рассматривают процесс создания текста как дискретное шумоподавление. Это означает, что модель начинает с полностью случайной последовательности, постепенно «очищая» её от шума, пока не сформируется связный и осмысленный текст. Такой подход позволяет модели исследовать множество возможных путей генерации параллельно, избегая ограничений последовательной обработки, присущих авторегрессионным моделям, и потенциально открывая новые возможности для решения сложных задач, требующих креативности и глубокого рассуждения.
Раскрытие Параллелизма: Произвольный Порядок Генерации и Его Влияние
Диффузионные модели, в сочетании с методами генерации в произвольном порядке (Arbitrary Order Generation), позволяют осуществлять параллельную декодировку, значительно ускоряя процесс генерации. Традиционные авторегрессионные модели генерируют токены последовательно, что является узким местом в производительности. В отличие от них, методы параллельной декодировки позволяют одновременно обрабатывать множество возможных токенов на каждом шаге, что приводит к экспоненциальному увеличению скорости генерации, особенно при использовании аппаратного ускорения, такого как графические процессоры. Эта возможность особенно важна для задач, требующих обработки больших объемов данных или генерации длинных последовательностей, где последовательная генерация становится непрактичной.
Возможность параллельного декодирования, обеспечиваемая диффузионными моделями и методами вроде Arbitrary Order Generation, критически важна для решения сложных задач, требующих рассмотрения множества альтернативных путей. В задачах, связанных с логическим выводом, планированием или поиском оптимальных решений, необходимо оценить большое количество гипотез и вариантов развития событий. Параллельная генерация токенов позволяет одновременно исследовать эти возможности, значительно сокращая время, необходимое для достижения результата по сравнению с последовательным подходом. Это особенно актуально в задачах, где пространство поиска решений экспоненциально велико, и перебор всех вариантов невозможен из-за вычислительных ограничений.
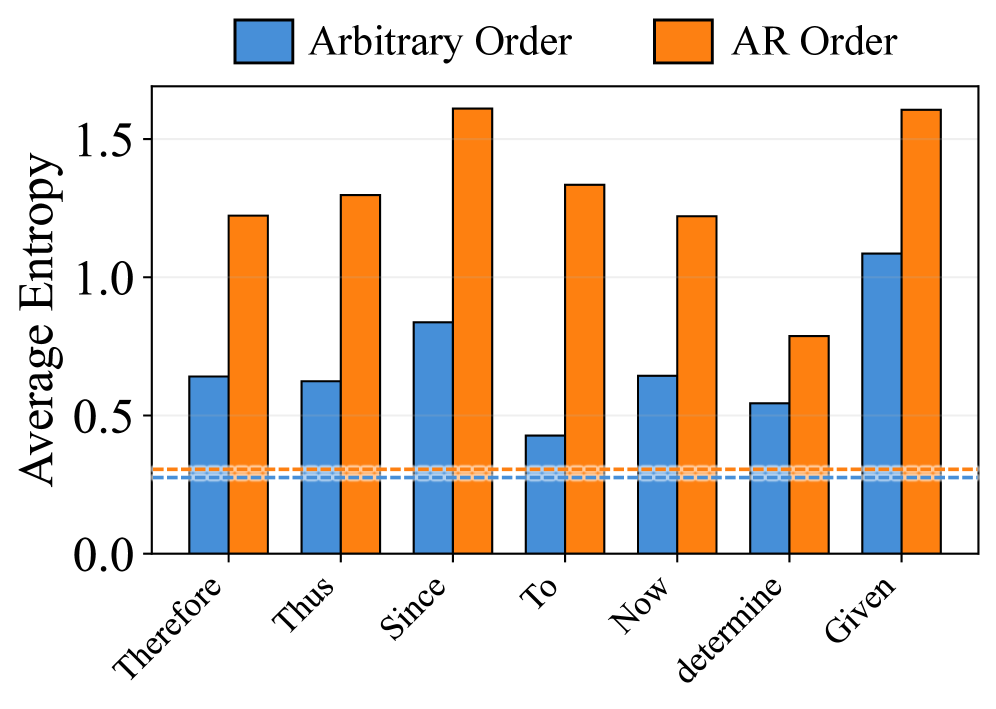
Свобода генерации токенов, обеспечиваемая методами вроде Arbitrary Order Generation в диффузионных моделях, может приводить к снижению энтропии в критических точках принятия решений. Это проявляется в сужении спектра рассматриваемых вариантов, что ограничивает способность модели исследовать пространство возможных решений. В результате, несмотря на ускорение генерации, качество итогового результата может ухудшиться, особенно в задачах, требующих глубокого рассуждения и учета множества факторов. Снижение энтропии выражается в предсказуемости выбора токенов, что уменьшает вероятность обнаружения оптимального или креативного решения.
Навигация в Пространстве Решений: Охват и Логические Разветвления
Эффективное рассуждение напрямую зависит от максимального охвата пространства решений — способности исследовать разнообразные пути к решению. Ограничение этого охвата, вызванное преждевременной фокусировкой на узком подмножестве возможностей, снижает вероятность достижения оптимального результата. Поиск, ориентированный на максимальное исследование различных вариантов, позволяет избежать локальных оптимумов и повысить вероятность обнаружения наиболее эффективного решения задачи, особенно в сложных и неоднозначных ситуациях. Важно, чтобы процесс рассуждений предусматривал систематическое рассмотрение альтернативных подходов и избегал преждевременного исключения потенциально полезных стратегий.
В каждой точке логического разветвления — момента, когда возникает несколько возможных путей решения — происходит снижение энтропии, которое может привести к преждевременному сужению области поиска. Это означает, что система, сталкиваясь с альтернативами, склонна выбирать наиболее очевидный или часто встречающийся вариант, игнорируя потенциально более оптимальные, но менее вероятные решения. В результате, алгоритм может зафиксироваться на субоптимальном пути, не исследуя полный спектр возможностей и снижая вероятность достижения наилучшего результата. Эффект усиливается при увеличении сложности задачи и количества логических разветвлений, что требует применения стратегий для поддержания высокой энтропии и обеспечения всестороннего анализа.
Эксперименты, проведенные с использованием стандартных бенчмарков, таких как GSM8K, MATH и HumanEval, показали улучшение производительности диффузионных моделей при их сочетании с целевым обучением с подкреплением. В частности, достигнута точность в 89.1% на наборе данных GSM8K и 68.1% на MATH, что демонстрирует эффективность данного подхода для задач, требующих сложных рассуждений и решения математических задач. Эти результаты подтверждают возможность повышения качества генерируемых решений за счет использования методов обучения с подкреплением для оптимизации процесса диффузии.

Обучение с Подкреплением для Улучшения Рассуждений
В процессе обучения с подкреплением, алгоритмы, такие как Group Relative Policy Optimization, позволяют эффективно бороться с проблемой снижения энтропии, присущей задачам, требующим рассуждений. Данные алгоритмы стимулируют исследование областей с высокой неопределенностью, вознаграждая модель за выбор менее вероятных, но потенциально более ценных решений. Такой подход позволяет избежать преждевременной сходимости к субоптимальным путям и способствует более полному изучению пространства решений, что особенно важно для сложных задач, требующих креативного подхода и анализа различных сценариев. Вознаграждение за исследование неопределенных областей способствует поддержанию разнообразия генерируемых решений и улучшает общую производительность модели.
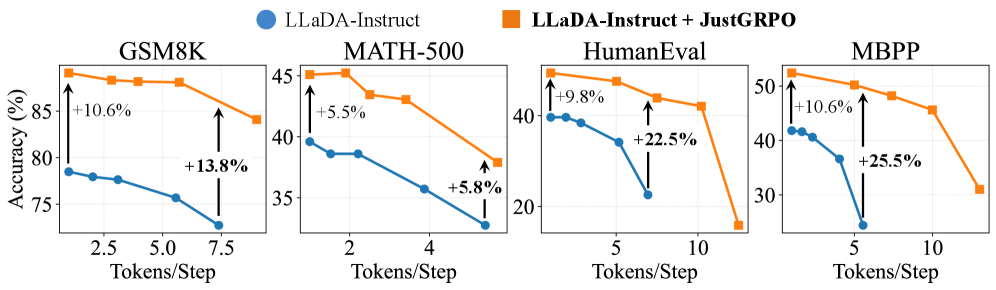
Обучение модели с акцентом на разнообразие решений демонстрирует значительное повышение производительности на сложных эталонах, таких как MBPP. Применяя методы, стимулирующие исследование различных путей решения, удалось достичь отрыва в 25.5% от базового уровня точности при использовании всего 5 токенов на шаг. Этот подход позволяет модели не просто находить работоспособное решение, но и активно исследовать пространство возможных ответов, что особенно важно для задач, требующих креативности и адаптивности. В результате, модель способна генерировать более надежные и устойчивые решения, даже в условиях неполной или неоднозначной информации.
Метрика Pass@kk представляет собой надежный инструмент оценки охвата пространства решений, что позволяет подтвердить эффективность предложенного подхода к обучению с подкреплением. В отличие от традиционных метрик, оценивающих лишь единичный наилучший результат, Pass@kk учитывает вероятность нахождения хотя бы одного верного решения среди k сгенерированных вариантов. Это особенно важно для задач, где существует множество допустимых ответов, и позволяет более точно оценить способность модели к исследованию различных стратегий и нахождению оптимального решения, даже если оно не является самым очевидным. Использование Pass@kk демонстрирует, что предложенные алгоритмы не просто улучшают точность, но и обеспечивают более полное и надежное покрытие пространства возможных решений, что критически важно для решения сложных задач, требующих креативного подхода и учета различных альтернатив.
Перспективы: Масштабирование и Обобщение
Модель LLaDA демонстрирует значительный потенциал диффузионных моделей в задаче генерации последовательностей, однако для решения более сложных задач требуется дальнейшее масштабирование. Исследователи отмечают, что текущие архитектуры сталкиваются с ограничениями при работе с длинными последовательностями и сложными зависимостями, что требует разработки новых методов обучения и оптимизации. Увеличение размера модели и объема обучающих данных, наряду с разработкой более эффективных алгоритмов параллелизации, представляется ключевым направлением для расширения возможностей LLaDA и подобных моделей. Перспективным представляется также исследование гибридных подходов, сочетающих диффузионные модели с другими техниками генерации, такими как авторегрессионные модели, для достижения оптимального баланса между качеством и вычислительной эффективностью.
Исследования показывают, что усовершенствование стратегий декодирования и функций потерь может значительно повысить эффективность моделей генерации последовательностей. В частности, перспективным направлением представляется использование Negative Evidence Lower Bound (NELB) — метода, направленного на более точную оценку вероятности генерируемой последовательности и снижение риска генерации нерелевантного или некачественного контента. Эксперименты демонстрируют, что NELB позволяет модели лучше различать правдоподобные и неправдоподобные варианты, что приводит к более когерентным и логичным результатам. Дальнейшая оптимизация этих стратегий, в сочетании с поиском новых подходов к обучению, способна открыть путь к созданию моделей, генерирующих текст, неотличимый от созданного человеком.
В дальнейшем исследования будут сосредоточены на повышении способности модели к обобщению и адаптации к более широкому спектру задач, требующих логического мышления. Особое внимание уделяется разработке методов, позволяющих модели эффективно применять полученные знания в новых, ранее не встречавшихся ситуациях, а также решать сложные задачи, требующие многоступенчатого анализа и вывода. Предполагается, что улучшение обобщающей способности позволит использовать данную технологию не только для генерации последовательностей, но и для решения широкого круга интеллектуальных задач, требующих гибкости и адаптивности, что открывает перспективы для создания более универсальных и интеллектуальных систем искусственного интеллекта.
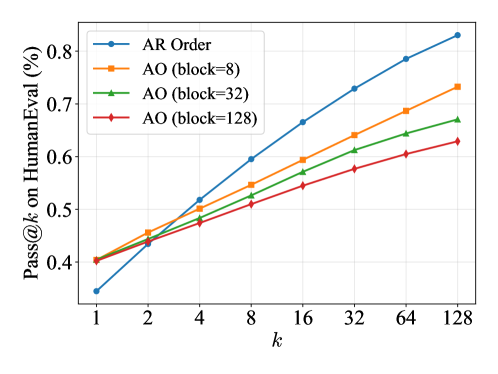
Исследование демонстрирует, что навязанный порядок декодирования в процессе обучения с подкреплением, вопреки интуиции, способствует развитию логических способностей диффузионных языковых моделей. Авторы показывают, что чрезмерная гибкость в определении порядка обработки информации приводит к преждевременному сужению пространства возможных решений, что ограничивает потенциал модели. Как метко заметил Кен Томпсон: «Все системы стареют — вопрос лишь в том, делают ли они достойно». Эта фраза отражает суть работы: система, лишенная четкого порядка, быстро деградирует, теряя способность к эффективному решению задач. Навязанный порядок, в данном контексте, позволяет системе «стареть достойно», сохраняя гибкость и потенциал для развития логического мышления, даже в условиях ограниченного пространства поиска.
Куда Ведет Гибкость?
Представленная работа, демонстрируя парадоксальное преимущество упорядоченности в, казалось бы, гибких системах, лишь подчеркивает фундаментальную истину: любое улучшение стареет быстрее, чем ожидалось. Ограничение энтропии на этапе обучения, вопреки интуиции, может способствовать более устойчивому развитию когнитивных способностей модели. Однако, вопрос о том, как оптимально сбалансировать эту упорядоченность и необходимую креативность, остается открытым. Следующим шагом представляется не просто поиск новых алгоритмов, а глубокое понимание механизмов деградации энтропии в процессе обучения — путешествие назад по стрелке времени, если угодно.
Особое внимание следует уделить исследованию влияния различных типов ограничений на порядок генерации. Действительно ли любое ограничение, независимо от его природы, приводит к аналогичному эффекту? Или существуют способы «тонкой настройки» упорядоченности, позволяющие максимизировать как текущую производительность, так и долгосрочную устойчивость модели к «энтропийному голоду»?
В конечном счете, данная работа служит напоминанием о том, что погоня за абсолютной гибкостью может оказаться иллюзорной. Более продуктивным представляется поиск компромиссов, позволяющих создавать системы, которые стареют достойно, сохраняя свою функциональность и адаптивность на протяжении длительного времени.
Оригинал статьи: https://arxiv.org/pdf/2601.15165.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-24 08:31