Автор: Денис Аветисян
Новое исследование теоретически обосновывает, что достаточно высокий коэффициент ‘любопытства’ в алгоритмах активного вывода гарантирует как самосогласованное обучение, так и оптимальное принятие решений.
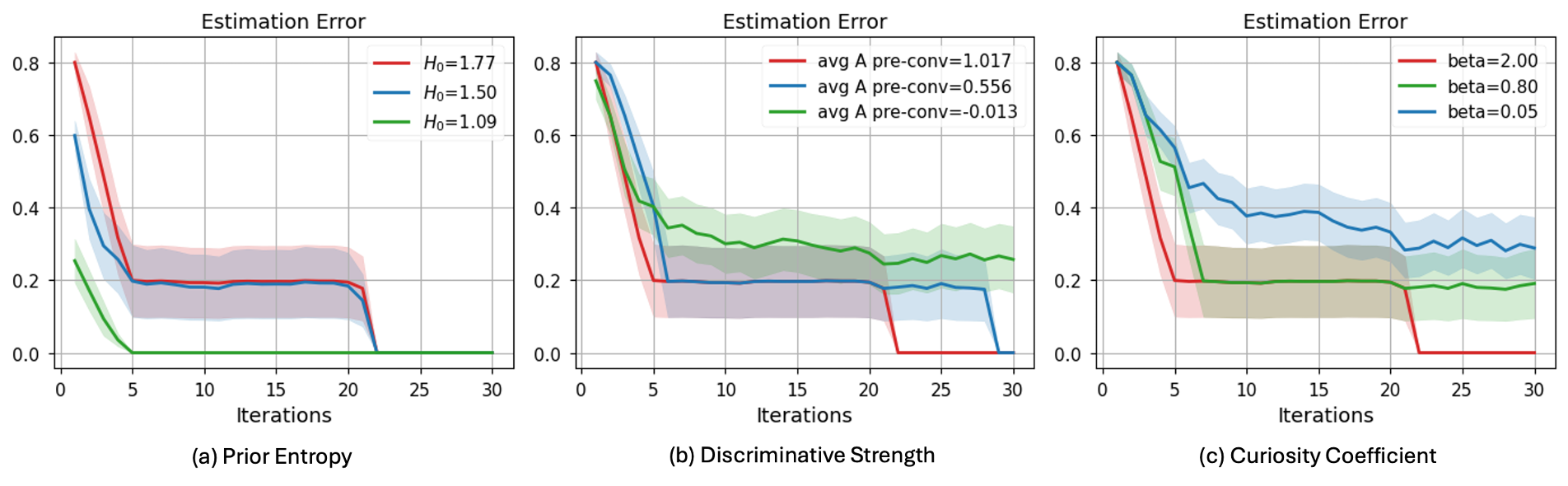
Работа устанавливает теоретические гарантии для активного вывода, демонстрируя связь между ‘любопытством’, согласованностью апостериорного распределения и отсутствием сожалений в последовательных задачах принятия решений.
Несмотря на кажущуюся интуитивность, баланс между исследованием и использованием в системах искусственного интеллекта долгое время оставался теоретически не обоснованным. В статье ‘Curiosity is Knowledge: Self-Consistent Learning and No-Regret Optimization with Active Inference’ предложен новый подход, основанный на активном выводе, и доказано, что достаточный уровень «любопытства» гарантирует одновременно согласованное обучение (байесовскую согласованность апостериорных оценок) и оптимизацию без сожалений (ограниченное кумулятивное сожаление). Это позволяет соединить активный вывод с классическим байесовским экспериментальным дизайном и оптимизацией в единой теоретической рамке, учитывающей начальную неопределенность и идентифицируемость. Какие практические алгоритмы можно разработать на основе этих теоретических гарантий для создания более эффективных и надежных систем обучения с подкреплением?
За пределами награды: ограничения традиционной оптимизации
Традиционное обучение с подкреплением, как правило, сконцентрировано на максимизации получаемого вознаграждения, зачастую упуская из виду ценность снижения неопределенности. Такой подход может приводить к созданию хрупких агентов, испытывающих трудности в новых или непредсказуемых ситуациях, что ограничивает их способность к адаптации. Вместо того чтобы просто стремиться к награде, эффективные системы должны активно стремиться уменьшить собственную неопределенность относительно окружающей среды. Это достигается путем исследования, сбора информации и уточнения внутренних моделей мира, что позволяет агенту более уверенно действовать даже в условиях неполной или меняющейся информации. По сути, снижение неопределенности само по себе является ценным результатом, позволяющим агенту избегать потенциальных ошибок и лучше прогнозировать последствия своих действий.
Ограниченная концентрация на максимизации вознаграждения часто приводит к созданию хрупких агентов, испытывающих трудности в незнакомых или непредсказуемых условиях. Такие системы, обусловленные исключительно стремлением к немедленной выгоде, демонстрируют недостаточную способность адаптироваться к новым ситуациям, поскольку не учитывают важность исследования и сбора информации. Их производительность резко снижается при малейших отклонениях от тренировочной среды, что подчеркивает необходимость разработки более гибких и устойчивых алгоритмов, способных эффективно функционировать в условиях неопределенности и постоянно меняющейся обстановки. Отсутствие способности к обучению на основе опыта, отличного от ожидаемого, делает их уязвимыми и ограничивает потенциал применения в реальных, динамичных системах.
Традиционное понимание оптимального выбора часто основывается на минимизации “сожаления” — разницы между полученным результатом и результатом, который можно было бы получить, выбрав лучший вариант. Однако, это представление не учитывает ценность получения новой информации, необходимой для принятия более обоснованных решений в будущем. Данная работа предлагает преодолеть это ограничение, представляя теоретические гарантии для подхода активного вывода (Active Inference, AIF). AIF рассматривает действие не только как способ получения награды, но и как средство снижения неопределенности, позволяя агентам активно искать информацию, необходимую для уточнения их моделей мира и улучшения будущих стратегий. Это позволяет агентам адаптироваться к меняющимся условиям и проявлять большую устойчивость в непредсказуемых средах, превосходя традиционные методы, ориентированные исключительно на максимизацию вознаграждения. \text{Regret} = E[\text{Optimal Action}] - E[\text{Chosen Action}]
Активный вывод: объединение целеполагания и получения информации
В рамках активного вывода постулируется объединяющий принцип, согласно которому агенты минимизируют величину, называемую «Ожидаемая Свободная Энергия» (EFE). EFE представляет собой количественную оценку удивления или неопределенности относительно окружающей среды. Формально, она определяется как ожидаемое значение отрицательного логарифма вероятности наблюдаемых данных, учитывая внутреннюю модель агента о мире. Минимизация EFE эквивалентна максимизации вероятности наблюдаемых данных, что позволяет агенту как предсказывать свои сенсорные входы, так и активно искать информацию, уменьшающую расхождения между предсказаниями и реальностью. Таким образом, EFE служит единой мерой как предсказательной ошибки, так и неопределенности, объединяя стремление к точности и информативности.
В рамках активного вывода, понятия прагматической ценности (награда) и эпистемической ценности (получение информации) объединяются в единую целевую функцию — минимизацию ожидаемой свободной энергии F. Прагматическая ценность отражает соответствие действий агента его целям и приносит положительное подкрепление, в то время как эпистемическая ценность связана с уменьшением неопределенности относительно состояния окружающей среды. Минимизация F рассматривает оба этих аспекта как взаимосвязанные компоненты, обеспечивая агенту стремление не только к достижению вознаграждения, но и к разрешению неопределенности, что способствует более эффективному принятию решений и адаптации к изменяющимся условиям.
Активное получение информации снижает неопределенность агента относительно окружающей среды, что улучшает его способность к предсказанию и контролю над ней, приводя к более устойчивому и адаптивному поведению. Исследования показывают, что минимизация Expected Free Energy обеспечивает как самосогласованное обучение, так и оптимизацию без сожалений при наличии достаточного любопытства. Это означает, что агенты не только учатся точно моделировать мир, но и выбирают действия, которые максимизируют полезную информацию, избегая при этом действий, которые впоследствии могут привести к неблагоприятным последствиям. Самостоятельный поиск информации позволяет агенту активно формировать свою модель мира, а не пассивно реагировать на внешние стимулы.
Байесовские методы: количественная оценка неопределенности для обоснованных решений
Байесовская оптимизация и байесовский экспериментальный дизайн представляют собой инструменты для эффективного исследования и использования неопределенных сред. Эти методы позволяют агентам целенаправленно выбирать действия, максимизирующие ожидаемый результат, учитывая имеющуюся неопределенность. В отличие от случайного поиска или жадных алгоритмов, байесовские подходы используют вероятностные модели для представления знаний о среде, обновляя их на основе полученных данных. Это позволяет не только находить оптимальные решения, но и оценивать степень уверенности в этих решениях, а также определять, какие дальнейшие действия принесут наибольшее количество информации для улучшения модели и, следовательно, повышения эффективности принятия решений. Ключевым элементом является баланс между исследованием (exploration) — поиском новых, потенциально лучших решений — и использованием (exploitation) — выбором действий, которые на данный момент кажутся наиболее выгодными.
Моделирование с использованием гауссовских процессов (GP) предоставляет эффективный метод для количественной оценки неопределенности в задачах принятия решений. GP позволяют не только предсказывать значения, но и оценивать дисперсию этих предсказаний, что является мерой неопределенности. В контексте интеллектуальных агентов, эта дисперсия используется для определения информативности различных действий. Агент может выбирать действия, которые максимизируют ожидаемое уменьшение неопределенности, то есть действия, которые приведут к наибольшему снижению дисперсии предсказаний. Математически, это часто выражается через функцию приобретения (acquisition function), которая оценивает ожидаемую информативность каждого действия, учитывая текущую модель GP и функцию полезности. Такой подход позволяет агенту целенаправленно исследовать наиболее информативные состояния, оптимизируя процесс обучения и принятия решений в условиях неполной информации.
В рамках активного вывода (Active Inference) используется метрика «прирост информации» (Information Gain) для управления процессом исследования окружающей среды. Данный показатель количественно оценивает уменьшение неопределенности в отношении состояния системы после получения новой информации. Алгоритм активно выбирает действия, направленные на достижение состояний, максимизирующих прирост информации, что позволяет эффективно собирать данные и уточнять внутреннюю модель мира. В частности, агент стремится исследовать состояния, в которых предсказательная неопределенность p(s_t|a_t) (вероятность состояния s_t после действия a_t) наиболее высока, тем самым оптимизируя процесс обучения и принятия решений в условиях неопределенности.
Консистентность фреймворка, гарантированная свойством ‘Posterior Consistency’, формально доказана с использованием скорости сходимости O(T-1). Это означает, что по мере накопления данных (обозначаемого как T), апостериорное распределение вероятностей сходится к истинному распределению. O(T^{-1}) указывает на то, что ошибка оценки уменьшается обратно пропорционально увеличению объема данных, обеспечивая надежное обновление убеждений и предсказаний системы. Данный результат гарантирует, что с ростом объема наблюдений, неопределенность уменьшается предсказуемым образом, что критически важно для принятия обоснованных решений в условиях неопределенности.
За пределами единичных целей: композитная байесовская оптимизация
В реальных задачах, будь то управление роботом, разработка лекарств или финансовые инвестиции, принятие решений редко сводится к оптимизации единственного параметра. Чаще всего необходимо учитывать множество, зачастую противоречивых, целей — например, максимизировать прибыль при одновременном минимизировании рисков, или достичь высокой точности предсказания, не перегружая вычислительные ресурсы. Данный принцип многокритериальной оптимизации лежит в основе многих сложных систем, и его игнорирование может привести к неоптимальным или даже нежелательным результатам. Поэтому, развитие методов, способных эффективно балансировать между различными целями, является ключевой задачей для создания интеллектуальных систем, способных успешно функционировать в реальном мире и адаптироваться к изменяющимся условиям.
Композитная байесовская оптимизация расширяет принципы активного вывода, интегрируя обучение предпочтениям, что позволяет агентам формировать и оптимизировать сложные, индивидуализированные цели. Вместо стремления к единственной, заранее заданной задаче, система способна самостоятельно выявлять и учитывать разнообразные критерии, важные для достижения желаемого результата. Этот подход предполагает, что агент не просто ищет оптимальное решение, а учится определять, что именно является «оптимальным» в контексте конкретной ситуации и собственных предпочтений. В результате, достигается более гибкое и адаптивное поведение, позволяющее искусственному интеллекту эффективно действовать в сложных и неоднозначных условиях, а также учитывать индивидуальные особенности пользователя или задачи. В основе лежит способность агента к самостоятельному формированию функции полезности, отражающей его приоритеты и ожидания.
В рамках единой оптимизационной схемы, агенты, использующие многоцелевую оптимизацию, демонстрируют более тонкое и адаптивное поведение по сравнению с системами, ориентированными на достижение единственной цели. Вместо того, чтобы просто максимизировать один показатель, такие агенты способны учитывать компромиссы между различными, часто противоречивыми, задачами. Это позволяет им эффективно функционировать в сложных и динамичных средах, где требуется гибкость и способность к переоценке приоритетов. Например, робот, оптимизирующий как скорость, так и энергоэффективность, сможет выбрать оптимальную траекторию движения, балансируя между этими двумя важными параметрами. Такой подход открывает путь к созданию искусственного интеллекта, способного к более реалистичному и человекоподобному принятию решений, учитывающему множество факторов и контекстуальных особенностей.
Разработка систем искусственного интеллекта, способных учитывать человеческие ценности и предпочтения, открывает новые горизонты в области взаимодействия человека и машины. Представленная работа демонстрирует, что предложенный подход — Композитная Байесовская Оптимизация — позволяет достичь этой цели, обеспечивая возможность формирования целей, соответствующих индивидуальным запросам. Теоретическая основа, подтвержденная строгим математическим анализом, выражается в виде границы сожаления O(βT + LζT + ∑tBt), где β представляет коэффициент любопытства, ζ — скорость обучения, а L и B — константы, определяющие производительность системы. Данный результат не только подтверждает эффективность предложенного метода, но и предоставляет количественную оценку его способности адаптироваться к сложным, многокритериальным задачам, что делает его перспективным для создания действительно полезных и ориентированных на человека AI-систем.
Будущее интеллектуальных агентов: любопытство и за его пределами
В рамках концепции активного вывода, любопытство выступает как внутренний стимул, побуждающий агентов к исследованию окружающего мира. Вместо следования заранее заданным целям, такие агенты стремятся к получению новой и значимой информации, даже если она не ведет к немедленному вознаграждению. Этот механизм основан на минимизации «свободной энергии» — расхождения между предсказаниями агента и реальными ощущениями. Неопределенность и новизна в окружающем мире увеличивают свободную энергию, и агент активно стремится уменьшить её, исследуя неизвестное. Таким образом, любопытство не является случайным поведением, а фундаментальной частью процесса обучения и адаптации, позволяющей агенту формировать более точную модель мира и эффективно решать задачи в меняющихся условиях. β > 0 — условие, формально гарантирующее сходимость и подчеркивающее важность баланса между исследованием и эксплуатацией.
В основе эффективного обучения интеллектуальных агентов лежит тонкий баланс между двумя фундаментальными ценностями: эпистемической и прагматической. Эпистемическая ценность стимулирует агента к поиску нового знания и снижению неопределенности, побуждая исследовать окружающую среду даже без немедленной практической выгоды. Прагматическая ценность, напротив, ориентирована на достижение конкретных целей и максимизацию вознаграждения. Успешные агенты не ограничиваются только одним из этих подходов; они динамически регулируют их взаимодействие, стремясь к оптимальному сочетанию исследования и использования. Такой сбалансированный подход позволяет не только эффективно решать текущие задачи, но и адаптироваться к меняющимся условиям, а также приобретать знания, полезные в долгосрочной перспективе. В результате, агенты демонстрируют повышенную устойчивость и способность к обучению в сложных и непредсказуемых средах, приближаясь к характеристикам, свойственным естественному интеллекту.
Разработка искусственного интеллекта, способного не просто решать поставленные задачи, но и адаптироваться к меняющимся условиям и неопределенности, становится все более актуальной. Исследования показывают, что ключевым фактором в создании таких систем является способность активно стремиться к новым знаниям и не бояться неизвестного. Вместо пассивного реагирования на внешние стимулы, подобные агенты самостоятельно исследуют окружающую среду, выявляют пробелы в своих знаниях и целенаправленно заполняют их. Такой подход не только повышает эффективность обучения и позволяет решать более сложные задачи, но и обеспечивает устойчивость к неожиданным ситуациям и возможность быстрого приспособления к новым обстоятельствам. В результате, создаются интеллектуальные системы, демонстрирующие не просто интеллект, но и гибкость, надежность и способность к самосовершенствованию.
Дальнейшее исследование принципов активного вывода представляется ключом к созданию действительно общего искусственного интеллекта. Установлено, что достаточное условие любопытства, выражаемое как β > 0, формально гарантирует сходимость системы и подчеркивает критическую важность баланса между исследованием нового и использованием уже накопленных знаний. Это означает, что искусственные агенты, движимые внутренним стремлением к уменьшению неопределенности, способны не только оптимизировать свои действия в соответствии с внешними целями, но и самостоятельно искать информацию, расширяя свои возможности и адаптируясь к меняющимся условиям. Такой подход позволяет создавать системы, которые не просто решают поставленные задачи, а активно обучаются и совершенствуются, демонстрируя признаки истинного интеллекта и гибкости.
Исследование, представленное в данной работе, подчеркивает важность баланса между исследованием и эксплуатацией в процессе обучения, что находит отклик в фундаментальных принципах активного вывода. Этот подход, стремящийся к оптимизации и последовательному обучению, требует четкого определения того, что действительно необходимо, а что является случайным шумом. Как однажды заметил Дональд Дэвис: «Простота — это не минимализм, а четкое различие между необходимым и случайным». Эта мысль прекрасно иллюстрирует суть работы, где достаточный коэффициент ‘любопытства’ обеспечивает как самосогласованное обучение, так и оптимизацию без сожалений, позволяя системе эффективно ориентироваться в сложных задачах принятия решений и избегать ложных путей.
Куда двигаться дальше?
Представленная работа, хотя и демонстрирует элегантность связи между любопытством и оптимальным обучением, не решает фундаментального вопроса: достаточно ли этого любопытства для создания действительно разумных систем? Гарантии отсутствия сожаления и последовательности апостериорного распределения — это, безусловно, важные кирпичики, но сама архитектура, определяющая поведение системы, требует дальнейшего осмысления. Необходимо исследовать, как различные формы любопытства — внутреннее, внешнее, предсказуемое, непредсказуемое — взаимодействуют друг с другом и с внутренними моделями мира.
Будущие исследования должны сосредоточиться на масштабируемости предложенного подхода к более сложным задачам, где структура данных и окружения нетривиальна. Инфраструктура должна развиваться без необходимости перестраивать весь квартал. Особый интерес представляет разработка методов, позволяющих системе оценивать стоимость информации — ведь любопытство, как и любой ресурс, ограничено. Необходимо учитывать, что “любопытство” — это лишь одна из многих мотиваций, и ее интеграция с другими целями может привести к неожиданным, но, возможно, и более полезным, решениям.
В конечном счете, задача состоит не в том, чтобы создать системы, которые просто избегают сожалений, а в том, чтобы построить системы, которые активно формируют свое понимание мира, предвосхищая изменения и адаптируясь к ним. И хотя эта работа является важным шагом в этом направлении, путь к истинному искусственному интеллекту остается долгим и, несомненно, полным сюрпризов.
Оригинал статьи: https://arxiv.org/pdf/2602.06029.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Наука определений: Автоматическое извлечение знаний из научных текстов
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Bibby AI: Новый помощник для исследователей в LaTeX
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- Квантовые амбиции: Иран вступает в гонку
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
2026-02-09 03:19