Автор: Денис Аветисян
Уменьшение размеров и повышение эффективности языковых моделей, в сочетании с доступностью вычислительных ресурсов, создают растущие риски, поскольку даже недорогое оборудование позволяет развертывать потенциально вредоносные кампании на основе ИИ.

Исследование посвящено анализу угроз безопасности, связанных с развитием и распространением маломасштабных моделей искусственного интеллекта.
Несмотря на растущее внимание к рискам, связанным с мощными искусственными интеллектами, всё больше опасений вызывает потенциал маломощных моделей. В своей работе ‘Small models, big threats: Characterizing safety challenges from low-compute AI models’ авторы исследуют, как уменьшение вычислительных требований и повышение эффективности языковых моделей создаёт новые угрозы. Исследование показывает, что даже на потребительском оборудовании можно развернуть кампании дезинформации, мошенничества и других злоупотреблений, используя открытые маломощные модели. Не приведет ли это к ситуации, когда защита от высокопроизводительных систем окажется неэффективной против растущего числа доступных и опасных маломощных ИИ?
Растущая доступность ИИ: Новая парадигма
Исторически, создание мощных больших языковых моделей (LLM) требовало колоссальных вычислительных ресурсов, что существенно ограничивало доступ к этой технологии. Для обучения и развертывания таких моделей, как GPT-3, требовались дорогостоящие серверные фермы и значительные затраты электроэнергии. Это создавало барьер для исследователей, стартапов и даже крупных компаний, не имеющих достаточного финансирования или инфраструктуры. В результате, возможности искусственного интеллекта, основанные на LLM, оставались недоступными для широкого круга пользователей и ограничивались узким кругом организаций, способных позволить себе необходимые ресурсы. Данная ситуация препятствовала развитию инноваций и широкому внедрению передовых технологий обработки естественного языка.
В последнее время наблюдается значительный прогресс в области искусственного интеллекта, проявляющийся в тенденции к разработке “AI с низкими вычислительными требованиями”. Исследования показывают, что для достижения определенного уровня производительности, измеряемого стандартными бенчмарками, необходимый размер моделей машинного обучения уменьшился в десять раз за последний год. Этот прорыв позволяет развертывать сложные алгоритмы искусственного интеллекта не на мощных серверных установках, а непосредственно на потребительском оборудовании — персональных компьютерах, смартфонах и других устройствах. Такое снижение вычислительной нагрузки открывает новые возможности для широкого применения ИИ, делая его более доступным и демократичным для разработчиков и пользователей по всему миру.
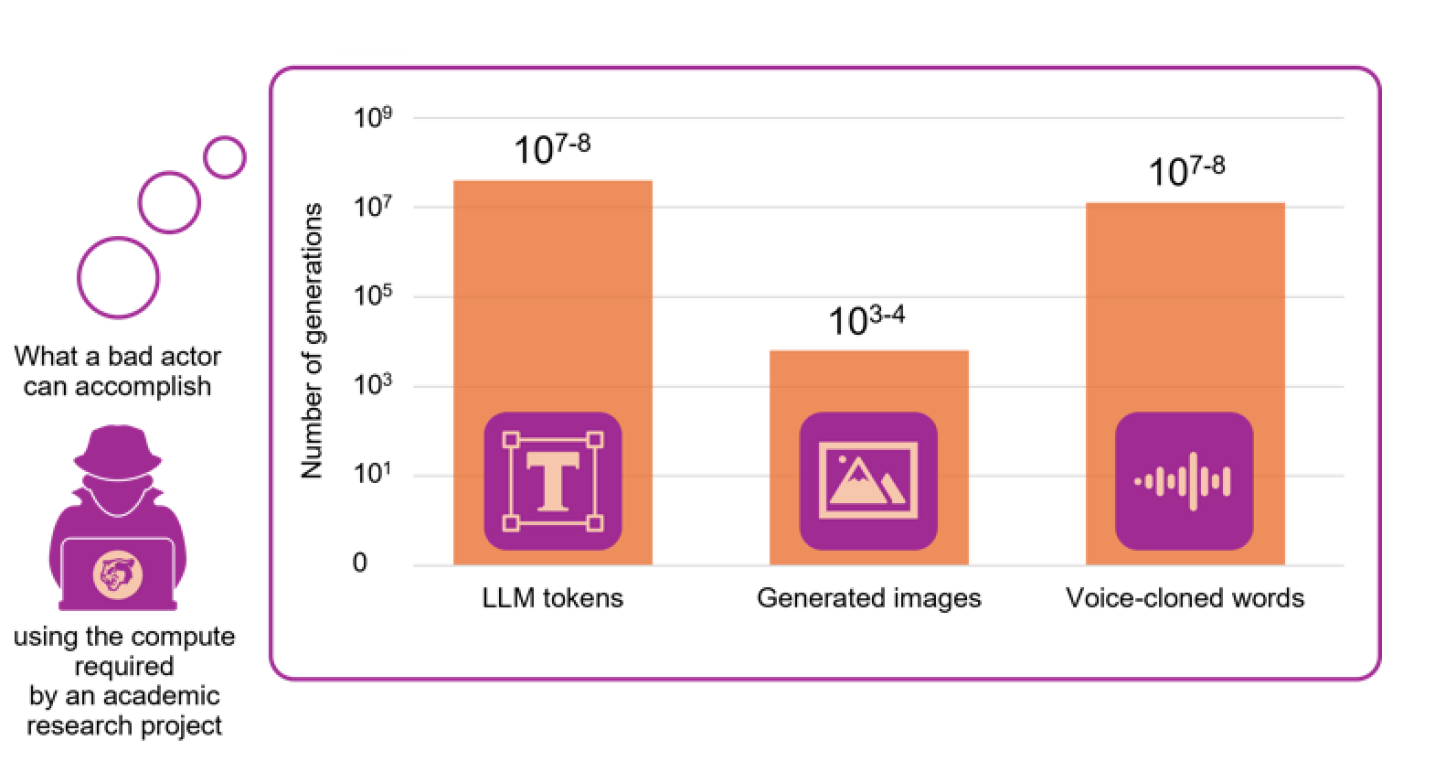
Демократизация вреда: Расширяющийся ландшафт угроз
Распространение моделей искусственного интеллекта с низкими вычислительными требованиями значительно упрощает доступ к технологиям для злоумышленников. Ранее требовавшие значительных ресурсов и специализированного оборудования, такие инструменты теперь могут быть развернуты и использованы на потребительском оборудовании, таком как стандартные компьютеры и мобильные устройства. Это снижает финансовый и технический порог входа для проведения вредоносных кампаний, позволяя большему числу акторов, включая отдельных лиц и небольшие группы, участвовать в киберпреступности и дезинформации. Уменьшение требований к вычислительным мощностям также способствует распространению готовых решений и инструментов, облегчая автоматизацию вредоносных действий и расширяя их масштаб.
Распространение доступных моделей искусственного интеллекта значительно расширяет возможности для проведения кампаний, направленных на нанесение социального вреда. Это включает в себя увеличение масштабов дезинформационных кампаний, фишинговых атак, а также появление всё более реалистичных подделок голоса. Увеличение вычислительной мощности, доступной для широкого круга пользователей, позволяет злоумышленникам автоматизировать и масштабировать эти атаки, что делает их более эффективными и сложными для обнаружения. В частности, отмечается рост числа случаев использования подобных технологий в схемах шантажа и распространения ложной информации, что представляет серьезную угрозу для информационной безопасности и общественного доверия.
Рейтинг LLM от Hugging Face демонстрирует стремительную миниатюризацию языковых моделей, что ускоряет распространение вредоносных возможностей. Симуляции показывают, что многие кампании, направленные на нанесение социального вреда, теперь могут быть реализованы на потребительском оборудовании. Например, кампания по дезинформации, аналогичная той, что наблюдалась во время Brexit, может генерировать до 65 000 твитов. Модели, используемые в схемах сексторшана, насчитывают более 100 000 загрузок, что указывает на широкую доступность инструментов для злоумышленников.
Технические контрмеры: Создание многоуровневой защиты
Методы сжатия моделей, такие как квантизация, прунинг и дистилляция знаний, играют ключевую роль в развертывании алгоритмов машинного обучения в средах с ограниченными вычислительными ресурсами. Квантизация снижает точность представления весов и активаций, уменьшая размер модели и требования к памяти. Прунинг удаляет наименее значимые связи в нейронной сети, снижая сложность вычислений. Дистилляция знаний позволяет передать знания от большой, сложной модели (учителя) к меньшей, более эффективной модели (ученику). Применение этих стратегий позволяет поддерживать приемлемую производительность и точность при значительном снижении потребления ресурсов, что особенно важно для мобильных устройств, встраиваемых систем и облачных вычислений с ограниченным бюджетом.
Технические решения, такие как цифровая водяная марка (digital watermarking) и контент-фильтрация, используются для идентификации и смягчения последствий от вредоносного контента. Цифровая водяная марка позволяет встраивать невидимые данные в цифровой контент, облегчая отслеживание источника распространения и подтверждение подлинности. Контент-фильтрация, в свою очередь, включает в себя анализ контента на наличие признаков вредоносной активности, таких как известные сигнатуры вирусов, нежелательные ключевые слова или паттерны, указывающие на попытки эксплуатации уязвимостей. Эти методы могут применяться как на стороне сервера, для блокировки доступа к вредоносному контенту, так и на стороне клиента, для предотвращения загрузки или выполнения опасных файлов.
Разрабатываются проактивные системы защитного искусственного интеллекта (AI), предназначенные для обнаружения и нейтрализации угроз до того, как они смогут нанести ущерб. Эти системы используют алгоритмы машинного обучения для анализа входящих данных, выявления аномалий и предсказания потенциальных атак. В отличие от реактивных систем безопасности, которые срабатывают после обнаружения угрозы, защитный AI стремится предотвратить её реализацию. Текущие разработки включают системы обнаружения вредоносного ПО на основе поведения, а также AI, способные выявлять и блокировать попытки взлома или несанкционированного доступа к данным. Эффективность этих систем зависит от качества обучающих данных и способности алгоритмов адаптироваться к новым, ранее неизвестным угрозам.
Традиционные метрики, такие как количество операций с плавающей точкой (FLOPs), часто оказываются недостаточными для оценки реального риска, связанного с возможностями модели искусственного интеллекта. Оценка, основанная на возможностях (Capability-Based Risk Evaluation), предполагает анализ фактического потенциала модели к нанесению вреда, учитывая не только вычислительную мощность, но и способность к выполнению определенных действий, таких как генерация дезинформации, обход систем безопасности или манипулирование данными. Этот подход позволяет более точно определить и приоритизировать риски, связанные с развитием и развертыванием систем ИИ, и разрабатывать более эффективные стратегии смягчения последствий, ориентированные на конкретные угрозы, а не просто на абстрактные показатели производительности.
За пределами технологий: Управление и системная устойчивость
Несмотря на значительный прогресс в области безопасности искусственного интеллекта, экспортный контроль над графическими процессорами (GPU) продолжает оставаться критически важным элементом снижения рисков. Современные разработки в области оптимизации алгоритмов и аппаратного обеспечения позволяют достигать сопоставимой производительности при значительно меньших вычислительных затратах. Это означает, что ограничения, основанные исключительно на объеме вычислительных ресурсов, могут оказаться недостаточными для эффективного контроля распространения передовых AI-технологий. Поэтому, сохранение и адаптация экспортных мер, направленных на ограничение доступа к мощным GPU, представляется необходимым дополнением к техническим решениям в области безопасности, обеспечивая более комплексный подход к управлению потенциальными рисками, связанными с развитием искусственного интеллекта.
Европейский закон об искусственном интеллекте (AI Act) устанавливает порог системного риска, основанный на вычислительной мощности, измеряемой в операциях с плавающей запятой в секунду (FLOPs). Однако, эта метрика становится все менее эффективной в условиях стремительного развития технологий. Современные алгоритмы машинного обучения демонстрируют значительное повышение эффективности, позволяя достигать сопоставимых результатов при снижении требуемых вычислительных ресурсов в 10 и более раз. Это означает, что системы, ранее не попадавшие под определение «системного риска» из-за недостаточной вычислительной мощности, теперь могут представлять опасность, оставаясь незамеченными существующими регуляторными рамками. Таким образом, исключительно опора на FLOPs в качестве критерия системного риска может привести к недооценке потенциальных угроз и требует пересмотра в сторону более комплексных и адаптивных подходов к оценке.
Повышение устойчивости к потенциальным рискам, связанным с развитием искусственного интеллекта, требует комплексного подхода, охватывающего не только технические средства защиты, но и продуманные нормативные рамки, а также повышение осведомленности общественности. Успешная реализация этого подхода предполагает разработку и внедрение передовых алгоритмов безопасности, способных смягчать угрозы на различных этапах развития систем ИИ. Однако, одних технических мер недостаточно; необходима четкая законодательная база, регулирующая разработку и применение этих технологий, а также определяющая ответственность за возможные последствия. Не менее важным является повышение осведомленности общества о потенциальных рисках и возможностях, связанных с ИИ, что позволит сформировать ответственное отношение к новым технологиям и способствовать их безопасному внедрению в различные сферы жизни.
Будущее требует от человечества не просто развития технологий, но и формирования стратегии, в которой благополучие общества является приоритетом наравне с инновациями. Недостаточно лишь создавать новые инструменты; необходимо заранее оценивать их потенциальное влияние на различные аспекты жизни, включая экономику, социальную сферу и безопасность. Адаптивность становится ключевым фактором, поскольку темпы технологических изменений требуют постоянного пересмотра существующих подходов и готовности к оперативной корректировке стратегий. Такой проактивный подход предполагает инвестиции не только в научные исследования, но и в образование, развитие критического мышления и формирование культуры ответственного использования технологий, что позволит минимизировать риски и максимизировать пользу для всего человечества.
Исследование показывает, что уменьшение вычислительных затрат и увеличение эффективности больших языковых моделей создаёт новые угрозы. Это напоминает о том, как быстро меняется ландшафт искусственного интеллекта и как сложно предсказать все возможные последствия. Дональд Кнут однажды сказал: «Прежде чем оптимизировать код, убедитесь, что он работает». В данном контексте это означает, что прежде чем стремиться к созданию всё более компактных и эффективных моделей, необходимо тщательно оценить риски, связанные с их потенциальным использованием. Подобно тому, как системы растут и развиваются, а не строятся, так и безопасность ИИ требует постоянного внимания и адаптации, а не однократного решения.
Что же впереди?
Изучение уменьшающихся моделей — это не поиск оптимальных алгоритмов сжатия, а наблюдение за тем, как зерно опасности прорастает на неожиданно плодородной почве. Снижение вычислительных затрат не решает проблем безопасности, а лишь перераспределяет их, делая их более доступными для тех, кто не обладает ресурсами для создания колоссов, но вполне способен развернуть рой мелких, но вредоносных агентов. Каждое усовершенствование в области квантования и дистилляции — это не шаг к безопасности, а пророчество о будущем злоупотреблении.
Предстоит понять, что не размер модели определяет угрозу, а ее способность к адаптации и распространению. Исследования должны сместиться от поиска «безопасных» архитектур к пониманию динамики распространения дезинформации и манипуляций в условиях повсеместного распространения низкоресурсных агентов. Вместо того, чтобы строить стены, нужно научиться выращивать иммунитет.
И, возможно, самое важное — признать, что любая попытка «управления» искусственным интеллектом — это лишь иллюзия порядка в хаотичной системе. Системы не строятся, они вырастают. И в этом росте всегда есть место для неожиданного и нежелательного. Каждый рефакторинг начинается как молитва и заканчивается покаянием.
Оригинал статьи: https://arxiv.org/pdf/2601.21365.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Взлом языковых моделей: эволюция атак, а не подсказок
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Кванты в Финансах: Не Шутка!
- Квантовый оптимизатор: Новый подход к сложным задачам
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Искусственный интеллект: новый взгляд на когнитивные механизмы
- Квантовый скачок: Анализ последних новостей
2026-01-31 15:30