Автор: Денис Аветисян
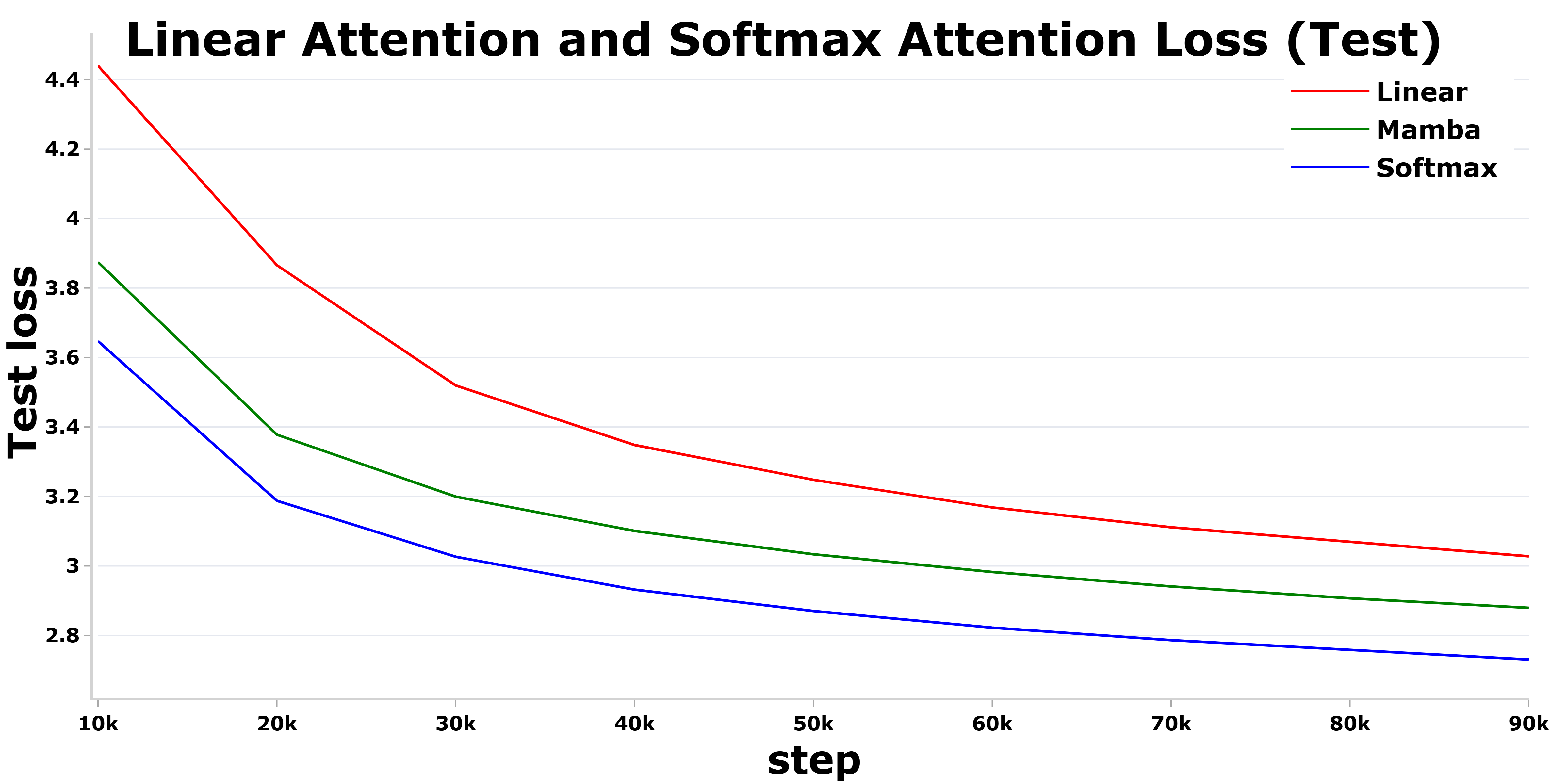
Исследователи представили архитектуру 2Mamba, демонстрирующую конкурентоспособную точность при значительно меньшей вычислительной сложности.

2Mamba использует линейное внимание и квадратичную скрытую функцию состояния с A-маской, предлагая потенциально масштабируемую альтернативу традиционным трансформерам.
Несмотря на растущую популярность трансформеров с линейным вниманием благодаря их вычислительной эффективности, они часто уступают по точности традиционным моделям с softmax-вниманием. В данной работе, озаглавленной ‘2Mamba2Furious: Linear in Complexity, Competitive in Accuracy’, авторы предлагают новый подход, основанный на модификации архитектуры Mamba-2, для преодоления этого разрыва. Предложенный метод, 2Mamba, достигает точности, сопоставимой с softmax-вниманием, при значительно меньших затратах памяти для обработки длинных последовательностей, благодаря возведению скрытого состояния в квадрат и оптимизации A-маски. Способен ли 2Mamba стать масштабируемой альтернативой стандартным трансформерам и открыть новые возможности для анализа данных?
Преодоление Квадратичной Сложности Внимания
Стандартный механизм внимания, основанный на функции softmax, несмотря на свою эффективность, сталкивается с проблемой квадратичной сложности. Это означает, что вычислительные затраты и потребление памяти растут пропорционально квадрату длины обрабатываемой последовательности O(n^2). В результате, применение этого механизма становится затруднительным при работе с длинными текстами, такими как большие корпуса данных или сложные научные статьи. По мере увеличения длины последовательности, потребность в вычислительных ресурсах и памяти растет экспоненциально, что ограничивает возможность масштабирования моделей и эффективной обработки обширных информационных потоков. Данное ограничение является ключевым препятствием на пути к созданию более мощных и универсальных систем искусственного интеллекта, способных эффективно анализировать и понимать большие объемы данных.
Квадратичная сложность механизма внимания представляет собой серьезное препятствие при обработке обширных наборов данных, таких как The Pile, и масштабировании моделей для решения всё более сложных задач. В частности, при увеличении длины последовательности входных данных, вычислительные затраты и потребление памяти растут пропорционально квадрату этой длины. Это означает, что обработка длинных текстов, например, при анализе больших объемов научной литературы или при создании сложных языковых моделей, становится крайне ресурсоемкой и зачастую невозможной на стандартном оборудовании. Подобное ограничение существенно замедляет процесс обучения и ограничивает потенциал моделей в понимании и генерации длинных, связных текстов, что является ключевым фактором для достижения высокого уровня производительности в различных областях, включая машинный перевод, анализ тональности и ответы на вопросы.
Несмотря на значительные улучшения, предлагаемые оптимизациями вроде Flash Attention, фундаментальные ограничения механизма softmax остаются определяющим фактором в масштабируемости моделей обработки последовательностей. Flash Attention, оптимизируя использование памяти и скорость вычислений, позволяет обрабатывать более длинные последовательности, но не устраняет присущую softmax квадратичную сложность O(n^2), где n — длина последовательности. Это означает, что с ростом длины входных данных вычислительные затраты растут экспоненциально, что создает узкое место при работе с обширными наборами данных, такими как The Pile, и ограничивает возможности модели в решении более сложных задач. Поэтому, несмотря на повышение эффективности, эти оптимизации лишь смягчают проблему, а не решают её, подчеркивая необходимость поиска принципиально новых подходов к механизмам внимания, способных обойти квадратичную сложность и обеспечить истинное масштабирование.
Модели Пространства Состояний и Архитектура Mamba
Модель пространства состояний (SSM) представляет собой математический фреймворк для моделирования последовательных данных, предлагающий потенциальную линейную сложность в отношении длины последовательности. В отличие от рекуррентных нейронных сетей (RNN) и трансформеров, которые часто имеют квадратичную сложность из-за последовательной обработки или механизма внимания, SSM использует систему линейных дифференциальных уравнений для описания эволюции скрытого состояния. Это позволяет эффективно обрабатывать длинные последовательности, поскольку вычисление скрытого состояния в каждый момент времени может быть выполнено за линейное время, используя такие методы, как свёрточные операции или рекурсивные алгоритмы. Математически, SSM обычно описывается уравнениями h'(t) = Ah(t) + Bx(t) и y(t) = Ch(t) + Dx(t), где x(t) — входной сигнал, h(t) — скрытое состояние, а y(t) — выходной сигнал. Матрицы A, B, C, D определяют динамику системы и преобразование входа в выход.
Модель Mamba использует концепцию моделей пространства состояний (SSM) для создания селективной модели пространства состояний, представляющей собой более эффективную альтернативу традиционным механизмам внимания. В отличие от механизмов внимания, сложность которых растет квадратично с длиной последовательности O(n^2), Mamba стремится к линейной сложности O(n), что позволяет обрабатывать более длинные последовательности данных с меньшими вычислительными затратами. Это достигается за счет использования рекуррентных связей внутри SSM и оптимизации процесса обработки информации для фокусировки на наиболее релевантных частях входной последовательности, что обеспечивает повышенную эффективность и масштабируемость.
Ключевым компонентом архитектуры Mamba является механизм AA-Mask (Adaptive Alignment Mask), предназначенный для управления потоком информации и повышения эффективности селективной памяти. AA-Mask динамически регулирует, какая часть скрытого состояния передается на каждом шаге, основываясь на текущем входе и предыдущем состоянии. Это достигается путем вычисления весов, определяющих вклад каждого элемента скрытого состояния, что позволяет модели фокусироваться на наиболее релевантной информации и отфильтровывать шум. В отличие от традиционных механизмов внимания, AA-Mask позволяет избежать квадратичной сложности по длине последовательности, что существенно ускоряет обработку длинных последовательностей данных и повышает общую производительность модели. Эффективность AA-Mask заключается в его способности адаптироваться к входным данным, обеспечивая более точное и эффективное представление последовательности.
Масштабирование Mamba с 2Mamba и 2Mamba-E
Модель Mamba-2 является развитием архитектуры Mamba и внедряет алгоритм ассоциативного сканирования (associative scan). Этот алгоритм позволяет значительно повысить эффективность обработки последовательностей за счет динамического определения релевантных частей входных данных. В отличие от традиционных методов, требующих фиксации размера контекста, ассоциативное сканирование адаптируется к структуре данных, снижая вычислительные затраты и повышая точность модели, особенно при работе с длинными последовательностями. В результате, Mamba-2 демонстрирует улучшенные показатели производительности и точности по сравнению с базовой архитектурой Mamba.
Архитектура 2Mamba внедряет скрытое состояние второго порядка, что позволяет модели улавливать более сложные зависимости в данных. Для стабилизации процесса обучения и предотвращения проблем, связанных с градиентами, используется метод Online Softmax. Этот подход динамически нормализует веса, что способствует более быстрому схождению и улучшает общую производительность модели. Внедрение второго порядка скрытого состояния в сочетании с Online Softmax позволяет 2Mamba достигать значительных улучшений в производительности по сравнению с предшествующими версиями и другими моделями, сохраняя при этом вычислительную эффективность.
Итерация 2Mamba-E повышает точность за счет экспоненцирования скрытого состояния и использования «квадратного» скрытого состояния (Squared Hidden State) для улучшения представления данных. Данный подход позволяет достичь уровня точности, сопоставимого с механизмами softmax-внимания. Экспоненцирование скрытого состояния способствует усилению значимых признаков, а применение «квадратного» скрытого состояния, по сути, h_i^2, позволяет модели более эффективно захватывать нелинейные зависимости в данных и улучшать качество представления информации, приближая производительность к моделям, использующим традиционное внимание.

Эффективность Ресурсов и Влияние Наборов Данных
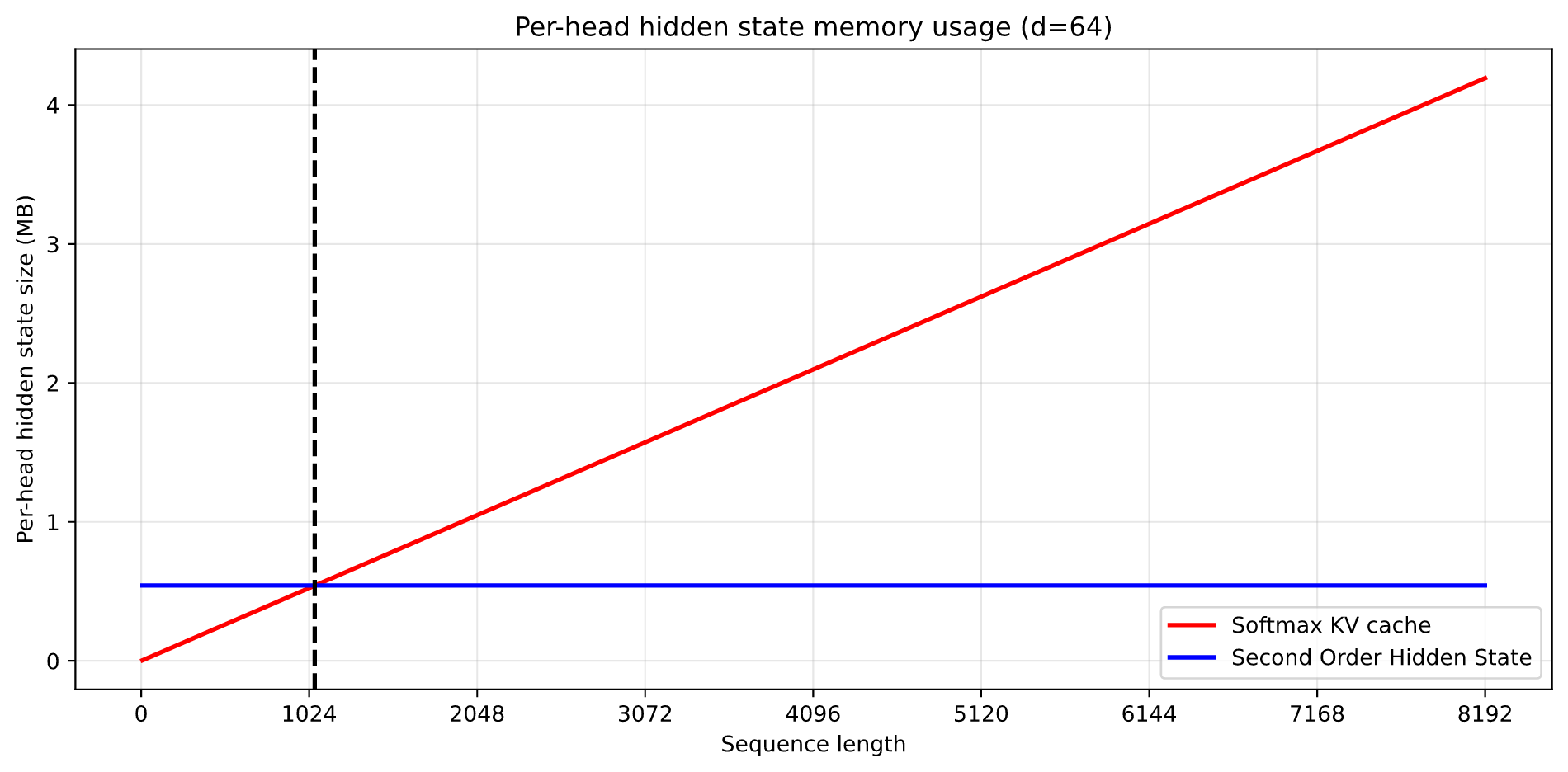
Модели 2Mamba и 2Mamba-E демонстрируют значительное снижение сложности памяти по сравнению с механизмами внимания softmax, что позволяет обучать более крупные модели на существенно больших наборах данных. Исследования показывают, что при обработке последовательностей, превышающих 1058 токенов, использование 2Mamba и 2Mamba-E требует меньше памяти, что открывает возможности для масштабирования языковых моделей. Это снижение вычислительных затрат позволяет исследователям и разработчикам экспериментировать с более сложными архитектурами и расширять объемы обучающих данных, что, в свою очередь, способствует созданию более точных и мощных систем обработки естественного языка. Такая эффективность особенно важна в условиях ограниченных ресурсов и при работе с большими языковыми моделями.
Исследования показали, что модели 2Mamba и 2Mamba-E демонстрируют высокую эффективность при обучении на масштабных наборах данных, таких как The Pile и его оптимизированной версии SlimPajama. Обучение на The Pile, представляющем собой разнообразный корпус текстов, позволило выявить способность моделей к обобщению знаний и адаптации к различным стилям письма. Использование SlimPajama, отличающегося более компактным размером и оптимизированной структурой, подчеркнуло возможности моделей в условиях ограниченных вычислительных ресурсов, не снижая при этом качества результатов. Такое сочетание масштаба данных и эффективности обучения открывает перспективы для создания более надежных и точных языковых моделей, способных к решению сложных задач.
Возможность эффективного масштабирования открывает новые перспективы для создания более надежных и точных языковых моделей, обладающих улучшенными способностями к рассуждению. Исследования показали, что оптимизированная версия 2Mamba, использующая экспоненциальную функцию, демонстрирует незначительное превосходство над традиционным механизмом softmax внимания, что подтверждается более высоким результатом в тесте NIAH (Neural Information Analysis Horizon). Этот прогресс позволяет создавать модели, способные обрабатывать более сложные задачи и генерировать более качественные и осмысленные тексты, что крайне важно для дальнейшего развития искусственного интеллекта и его применения в различных сферах деятельности.

Исследование представляет собой элегантное решение проблемы масштабируемости в архитектурах, основанных на механизмах внимания. Авторы демонстрируют, как, отказавшись от квадратичной сложности традиционных подходов, можно достичь конкурентоспособной точности, сравнимой с softmax-вниманием. Этот подход, использующий линейное внимание и инновационную технику возведения скрытого состояния в квадрат, напоминает о важности ясности и простоты в проектировании систем. Как однажды заметил Джон Маккарти: «Искусственный интеллект — это изучение того, как сделать машины, которые делают вещи, которые требуют интеллекта, когда их делают люди». Эта фраза отражает суть представленной работы — поиск эффективных и интеллектуальных решений для сложных вычислительных задач, что, в свою очередь, открывает новые горизонты для развития искусственного интеллекта.
Куда же дальше?
Представленная работа, безусловно, демонстрирует элегантность линейного внимания, стремящегося к точности softmax, но истинный вопрос заключается не в достижении паритета, а в понимании последствий. Каждая оптимизация, каждая «ускоренная» архитектура создает новые узлы напряжения в системе. Уменьшение вычислительной сложности — это не решение, а перенос проблемы. Где окажется этот новый предел? Каковы будут проявления нестабильности, когда масштабирование продолжится?
Архитектура — это поведение системы во времени, а не схема на бумаге. Использование квадратичной скрытой функции и A-маски — это интересные конструктивные решения, но они лишь симптомы, а не лекарство. Необходимо исследовать фундаментальные ограничения моделей последовательностей. Не является ли сама концепция «внимания» временным решением, вынужденным компромиссом, заменяющим истинное понимание долгосрочных зависимостей?
Будущие исследования, вероятно, сосредоточатся на гибридных подходах, сочетающих линейные и квадратичные механизмы, или же на совершенно новых парадигмах, избегающих принципа внимания вовсе. Главная задача — не построить более быструю модель, а создать систему, способную к подлинному обучению и адаптации, подобно живому организму. Простота и ясность — вот к чему следует стремиться, а не к бесконечному усложнению.
Оригинал статьи: https://arxiv.org/pdf/2602.17363.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Временная запутанность: от хаоса к порядку
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Квантовое программирование: Карта развивающегося мира
- Предел возможностей: где большие языковые модели теряют разум?
- ЭКГ-анализ будущего: От данных к цифровым биомаркерам
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Сердце музыки: открытые модели для создания композиций
- Квантовые кольца: новые горизонты спиновых токов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
2026-02-21 03:00