Автор: Денис Аветисян
В статье представлен обзор новейших достижений в применении алгоритмов машинного обучения для реконструкции и идентификации частиц в эксперименте CMS.
Обзор применения методов машинного обучения для улучшения идентификации адронов, тау-лептонов и анализа данных, полученных в эксперименте CMS, включая перспективы для будущих данных высокой светимости.
По мере увеличения сложности экспериментов в физике высоких энергий, традиционные методы реконструкции и идентификации частиц сталкиваются со значительными ограничениями. В настоящей работе, посвященной ‘Machine learning in online and offline reconstruction and identification with CMS’, представлен обзор существенного прогресса в применении алгоритмов машинного обучения для повышения эффективности анализа данных, полученных на детекторе CMS. Показано, что использование методов машинного обучения позволяет улучшить идентификацию физических объектов, оптимизировать реконструкцию энергии и повысить устойчивость к экстремальным условиям на Большом адронном коллайдере. Какие новые возможности откроет машинное обучение для анализа данных, получаемых в будущем на высоколюминесцентном LHC и в экспериментах следующего поколения?
Преодолевая Пределы: Сложности Идентификации Частиц на HL-LHC
Высоколюминесцентный адронный коллайдер (HL-LHC) столкнётся с беспрецедентным уровнем наложения событий, известного как “pileup”, что значительно усложнит идентификацию элементарных частиц. Увеличение интенсивности пучков, необходимое для повышения статистической точности экспериментов, приводит к тому, что в каждом акте столкновений возникает множество дополнительных взаимодействий, происходящих практически одновременно. Это приводит к образованию сложной “картины” событий, где следы различных частиц перекрываются, затрудняя их разделение и точное определение их характеристик. В результате, традиционные методы идентификации частиц, разработанные для менее интенсивных условий, оказываются неэффективными, требуя разработки новых, более устойчивых к наложению событий алгоритмов и детекторных технологий.
В условиях экстремальной загруженности Высоколюминесцентного коллайдера (HL-LHC) традиционные методы идентификации частиц сталкиваются со значительными трудностями. Увеличение числа одновременных столкновений, известное как наложение событий, приводит к снижению четкости сигналов и затрудняет разделение первичных частиц от вторичных продуктов распада и фонового шума. Существующие алгоритмы, разработанные для менее плотных условий, теряют эффективность в определении траекторий частиц и измерении их энергии и импульса, что напрямую влияет на точность реконструкции событий и, следовательно, на возможность обнаружения новых физических явлений. Сложность различения близких по характеристикам частиц, таких как электроны и фотоны, или мюоны и пионы, возрастает многократно, требуя разработки инновационных подходов к обработке данных и повышению устойчивости алгоритмов к высоким уровням наложения.
Точная идентификация электронов, фотонов и мюонов является основополагающей для широкого спектра физических анализов, проводимых на Большом адронном коллайдере. Эти частицы служат ключевыми индикаторами новых явлений, таких как распад частиц за пределы Стандартной модели или открытие дополнительных измерений. Например, анализ распадов бозона Хиггса требует четкого различения электронов и фотонов для измерения их свойств и проверки предсказаний теории. Идентификация мюонов критически важна в поисках редких распадов и нарушений CP-инвариантности. В связи с этим, разработка инновационных методов идентификации, способных эффективно справляться с растущим уровнем фонового шума и сложностью данных, является приоритетной задачей для будущих экспериментов на коллайдере.
Глубокое Обучение на Службе Реконструкции Частиц
Глубокие нейронные сети, на примере DeepSuperCluster, демонстрируют улучшение кластеризации энергии электронов и фотонов по сравнению с традиционными алгоритмами. DeepSuperCluster использует архитектуру, основанную на сверточных нейронных сетях, для обработки данных калориметров и более точно разделять энергии отдельных частиц. В отличие от классических методов, таких как алгоритмы на основе фиксированных параметров или скользящих окон, DeepSuperCluster обучается непосредственно на данных, что позволяет ему адаптироваться к сложным профилям энергии и улучшить разрешение энергии, особенно в областях с высокой плотностью частиц. Это позволяет более эффективно идентифицировать и реконструировать электроны и фотоны в экспериментах с высокой энергией.
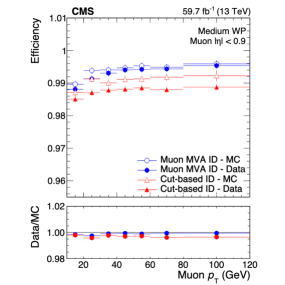
В настоящее время для идентификации мюонов всё шире применяются многовариантные классификаторы, демонстрирующие повышенную эффективность по сравнению с ранее использовавшимися методами, основанными на применении пороговых значений (cut-based methods). Улучшение эффективности подтверждается более точным соответствием между данными, полученными в эксперименте, и результатами моделирования (Data/MC agreement), что наглядно представлено на Рисунке 4. Использование многовариантных классификаторов позволяет учитывать большее количество параметров и сложные корреляции, что повышает точность разделения сигналов и фона.
Современные методы реконструкции частиц, основанные на глубоком обучении, используют подходы, управляемые данными, для выявления сложных зависимостей в экспериментальных данных. Вместо использования заранее определенных критериев или параметров, алгоритмы самостоятельно изучают паттерны, позволяющие эффективно разделять сигнальные события от фоновых. Такой подход позволяет оптимизировать параметры разделения непосредственно на данных, что приводит к повышению эффективности идентификации частиц и снижению влияния систематических погрешностей, связанных с выбором параметров классификации. Обучение моделей происходит на больших объемах данных, позволяя алгоритмам адаптироваться к особенностям конкретного эксперимента и повышать точность реконструкции.
Графовые Нейронные Сети и Трансформеры: Новые Горизонты
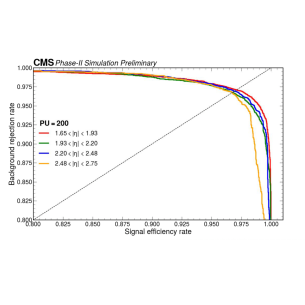
В рамках реконструкции каскадов в HGCAL используются графовые нейронные сети (GNN) для эффективного разделения электромагнитных и адронных ливней. GNN позволяют моделировать пространственное распределение энергии в калориметре, что критически важно для различения сигналов от фотонов и пионов. Эффективность разделения достигается за счет способности GNN учитывать взаимосвязи между отдельными ячейками калориметра и использовать эту информацию для классификации каскадов. Высокая разделяющая способность позволяет существенно снизить количество ложноидентифицированных событий и повысить точность идентификации частиц.
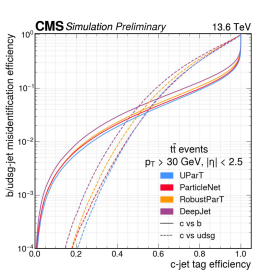
Фреймворк Unified ParticleTransformer (UParT) использует метод состязательного обучения (adversarial training) для повышения устойчивости к ошибкам моделирования в симуляциях, возникающим при классификации струй (jet flavor tagging). В рамках этого подхода, модель обучается отличать реальные данные от смоделированных, что позволяет ей лучше справляться с расхождениями между ними. Результаты показывают, что UParT демонстрирует передовые показатели в идентификации струй, содержащих b-кварки и c-кварки, а также адронных тау-лептонов, превосходя существующие методы по эффективности и точности классификации.
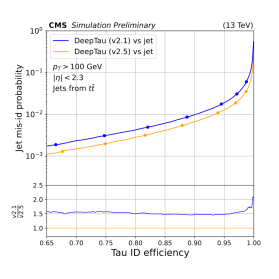
Метод DeepTau использует техники адаптации домена для согласования распределений данных моделирования и экспериментальных данных, что приводит к улучшению идентификации адронных тау-лептонов. Данный подход позволяет добиться существенного прироста эффективности обнаружения и снижения уровня фонового шума. Согласование распределений достигается за счет минимизации расхождений между симулированными и реальными данными, что повышает надежность идентификации адронных тау-лептонов и улучшает общую точность анализа. Результаты, представленные на Рисунке 3, демонстрируют значительное улучшение характеристик идентификации за счет применения данной техники.
Влияние и Перспективы для Физики Частиц
В условиях Высоколюминесцентного Большого адронного коллайдера (HL-LHC) значительно возрастет количество накладывающихся событий, так называемый “pileup”, что существенно усложнит обнаружение редких процессов. Для поддержания чувствительности к этим процессам, критически важным для поиска новой физики, разрабатываются передовые методы анализа данных. Эти методы включают в себя усовершенствованные алгоритмы реконструкции траекторий частиц, более точное определение времени их возникновения и использование машинного обучения для отделения сигналов от фонового шума. Без этих инноваций, редкие события могли бы быть “потеряны” в огромном количестве данных, что существенно ограничило бы возможности HL-LHC для проведения фундаментальных исследований.
Совершенствование методов идентификации струй и тау-лептонов играет ключевую роль в современной физике высоких энергий. Более точное определение вкуса струй позволяет существенно повысить чувствительность к редким процессам, связанным с распадом бозонов, в частности, бозона Хиггса. Улучшенная идентификация тау-лептонов, являющихся важными сигналами в ряде каналов распада, позволяет снизить фоновый шум и выделить сигналы новой физики, такие как суперсимметрия или дополнительные измерения. Эти достижения открывают новые возможности для детального изучения свойств бозона Хиггса и поиска отклонений от Стандартной модели, что позволит глубже понять фундаментальные законы природы и ответить на вопросы о темной материи и темной энергии.
Дальнейшие исследования в области физики высоких энергий сосредоточены на оптимизации существующих методов анализа данных и разработке принципиально новых архитектур обработки информации. Необходимость в этом обусловлена постоянно растущими объемами данных, получаемых на современных и будущих коллайдерах, таких как Большой адронный коллайдер высокой светимости (HL-LHC). Ученые активно исследуют алгоритмы машинного обучения, включая глубокие нейронные сети, для повышения точности идентификации частиц и реконструкции событий. Особое внимание уделяется разработке устойчивых к шуму и помехам методов, способных эффективно выделять редкие физические процессы на фоне большого количества фоновых событий. Внедрение новых аппаратных решений, таких как специализированные ускорители для машинного обучения и высокопроизводительные вычислительные системы, позволит существенно повысить скорость и эффективность анализа данных, открывая новые возможности для поиска новой физики и углубленного изучения свойств известных частиц.

В исследовании, посвященном применению машинного обучения в эксперименте CMS, отчетливо прослеживается стремление к оптимизации процессов реконструкции и идентификации частиц. Это не просто повышение точности, но и адаптация к возрастающей сложности данных, которые будут генерироваться в будущем при высокой светимости. Как говорил Нильс Бор: «Противоположности не борются, а дополняют друг друга». Эта фраза находит отражение в подходе, демонстрируемом в статье: объединение традиционных методов анализа с передовыми алгоритмами машинного обучения для достижения наилучших результатов. Системы, подобные тем, что используются в CMS, учатся стареть достойно, приспосабливаясь к меняющимся условиям и извлекая максимум информации из доступных данных. Подобно тому, как мудрая система не борется с энтропией, CMS использует машинное обучение, чтобы дышать вместе с возрастающей сложностью данных.
Что впереди?
Представленный обзор демонстрирует, как машинное обучение стало неотъемлемой частью анализа данных в эксперименте CMS. Однако, не стоит забывать, что любая система, даже самая изощренная, подвержена энтропии. Версионирование моделей — это лишь форма памяти, попытка удержать ускользающую точность в условиях меняющегося потока данных. Стрела времени всегда указывает на необходимость рефакторинга, на переосмысление архитектур и алгоритмов.
Особое внимание следует уделить адаптации к данным, получаемым в условиях повышенной светимости. Простое масштабирование существующих моделей может оказаться недостаточным. Необходимы принципиально новые подходы к обработке информации, способные эффективно справляться с колоссальным объемом и сложностью данных. В частности, перспективным направлением представляется разработка алгоритмов, способных к самообучению и адаптации в реальном времени.
В конечном счете, задача состоит не в том, чтобы создать идеальную модель, а в том, чтобы создать систему, способную достойно стареть. Иными словами, алгоритмы должны быть не только точными, но и понятными, интерпретируемыми, и устойчивыми к непредсказуемым изменениям в данных. В противном случае, все усилия окажутся лишь временной отсрочкой неизбежного.
Оригинал статьи: https://arxiv.org/pdf/2602.08010.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Переворот: От Теории к Реальности
- Плоские зоны: от теории к новым материалам
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект на службе редких болезней
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
- Видео-Мыслитель: гармония разума и визуального потока.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Наука, управляемая интеллектом: новая эра открытий
2026-02-11 05:53