Автор: Денис Аветисян
В статье представлен детальный обзор и оценка четырех популярных фреймворков для организации и автоматизации жизненного цикла машинного обучения.
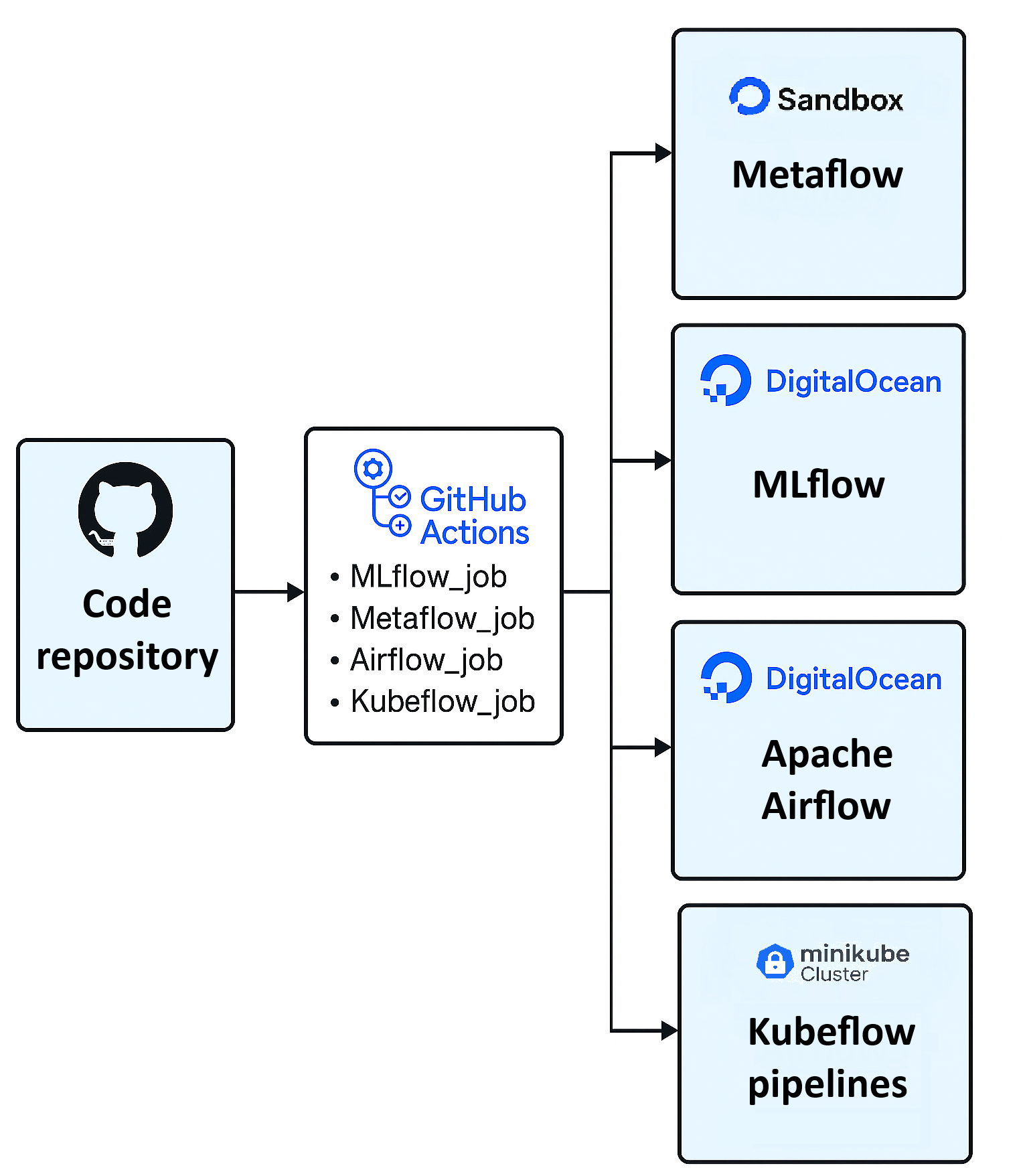
Исследование сравнивает возможности MLflow, Metaflow, Apache Airflow и Kubeflow Pipelines для построения, развертывания и управления ML-пайплайнами.
В условиях растущей сложности жизненного цикла моделей машинного обучения, выбор подходящего инструмента для организации рабочих процессов MLOps становится критически важной задачей. Данная работа, ‘An Empirical Evaluation of Modern MLOps Frameworks’, представляет собой эмпирическое исследование наиболее популярных MLOps-фреймворков — MLflow, Metaflow, Apache Airflow и Kubeflow Pipelines — с точки зрения простоты установки, гибкости конфигурации и совместимости. Результаты оценки, полученные при реализации классификаторов изображений (MNIST) и анализа тональности текстов (IMDB, BERT), позволяют определить оптимальные инструменты для различных сценариев развертывания ML-моделей. Какие факторы станут определяющими при выборе MLOps-платформы в будущем и как изменится ландшафт инструментов в связи с развитием новых технологий?
Поиск ясности в машинном обучении: проблема воспроизводимости
Традиционные методы обучения моделей машинного обучения зачастую не предусматривают надёжной регистрации параметров и артефактов, что существенно затрудняет воспроизводимость результатов. Отсутствие детальной информации о версиях используемых библиотек, гиперпараметрах, случайных зернах и даже исходных данных приводит к тому, что повторное выполнение эксперимента может дать отличающиеся результаты, даже при использовании идентичного кода. Это не только усложняет верификацию научных исследований, но и представляет серьёзную проблему при внедрении моделей в критически важные системы, где надёжность и предсказуемость имеют первостепенное значение. Фактически, без систематического отслеживания всех компонентов обучения, ценные инсайты теряются, а модели становятся сложными в поддержке и дальнейшем совершенствовании, что замедляет прогресс в области машинного обучения.
Отсутствие возможности воспроизвести результаты машинного обучения создает серьезные препятствия для совместной научной работы, поскольку затрудняет проверку и подтверждение выводов другими исследователями. Это особенно критично в сферах, требующих строгого аудита, например, в финансовом секторе или здравоохранении, где необходимо обеспечить прозрачность и надежность принимаемых решений. В регулируемых отраслях, где соблюдение нормативных требований является приоритетом, невозможность отследить и верифицировать каждый этап обучения модели может привести к юридическим последствиям и потере доверия. Таким образом, воспроизводимость становится не просто технической задачей, а ключевым фактором для обеспечения ответственности, надежности и широкого внедрения систем машинного обучения.
Эффективное отслеживание экспериментов является краеугольным камнем для создания надежных и масштабируемых систем машинного обучения. В процессе разработки моделей возникает огромное количество итераций, каждая из которых зависит от множества факторов — параметров обучения, используемых данных, версий программного обеспечения и т.д. Без систематизированного учета этих факторов, воссоздать результаты обучения, выявить причины ошибок или адаптировать модель к новым данным становится практически невозможным. Тщательное документирование каждого этапа эксперимента, включая гиперпараметры, метрики, артефакты и окружение, позволяет не только обеспечить воспроизводимость результатов, но и значительно упростить процесс отладки, оптимизации и последующего обслуживания модели, что критически важно для ее успешного внедрения и долгосрочной эксплуатации.
Отсутствие надлежащего отслеживания экспериментов в машинном обучении приводит к необратимой потере ценных знаний, полученных в процессе разработки моделей. Без систематизированной регистрации параметров, данных и артефактов, исследователям и инженерам становится крайне сложно воспроизвести результаты, понять причины успеха или неудачи конкретной конфигурации, и, как следствие, эффективно оптимизировать модели. Это затрудняет не только научные исследования и сотрудничество, но и усложняет процесс сопровождения и улучшения развернутых систем, увеличивая риски, связанные с устареванием моделей и снижением их производительности. В конечном итоге, пренебрежение отслеживанием экспериментов подрывает долгосрочную устойчивость и масштабируемость систем машинного обучения.
Оркестровка рабочих процессов: жизненный цикл машинного обучения
Платформы, такие как Apache Airflow и Metaflow, предоставляют возможность программного определения и планирования сложных конвейеров обработки данных, используемых в машинном обучении. Вместо ручного запуска отдельных скриптов и задач, эти инструменты позволяют описать весь процесс — от извлечения и предобработки данных до обучения модели и оценки её производительности — в виде направленного ациклического графа (DAG). Это обеспечивает автоматизацию, версионность и возможность повторного выполнения конвейеров, а также позволяет легко отслеживать зависимости между задачами и управлять ресурсами, необходимыми для их выполнения. Определение конвейера происходит с использованием Python, что дает гибкость и позволяет интегрировать различные библиотеки и инструменты анализа данных.
Автоматизация этапов предварительной обработки данных, обучения моделей и их оценки позволяет значительно повысить эффективность и снизить вероятность ошибок в процессе машинного обучения. В частности, автоматизация устраняет рутинные задачи, связанные с подготовкой данных к обучению, такие как очистка, преобразование и обогащение. Автоматическое обучение позволяет быстро тестировать различные алгоритмы и гиперпараметры, оптимизируя производительность модели. Автоматическая оценка, включающая использование метрик качества и валидационных выборок, обеспечивает объективную оценку модели и выявление потенциальных проблем на ранних стадиях. В результате, время разработки и внедрения моделей сокращается, а их надежность и точность повышаются.
Интеграция рабочих процессов машинного обучения с облачной инфраструктурой, такой как DigitalOcean, позволяет эффективно масштабировать вычислительные ресурсы для обработки больших объемов данных и обучения сложных моделей. DigitalOcean предоставляет виртуальные машины, хранилища данных и сетевые сервисы, необходимые для выполнения ресурсоемких задач, связанных с предобработкой данных, обучением моделей и проведением оценок. Использование облачных ресурсов позволяет динамически выделять и освобождать ресурсы в зависимости от текущей нагрузки, оптимизируя затраты и обеспечивая высокую производительность даже при работе с петабайтами данных и моделями, требующими значительных вычислительных мощностей. Такая интеграция позволяет командам Data Science сосредоточиться на разработке и улучшении моделей, не беспокоясь об управлении инфраструктурой.
GitHub Actions предоставляет возможности непрерывной интеграции и непрерывной доставки (CI/CD) для автоматизации тестирования и развертывания моделей машинного обучения. Это достигается за счет определения рабочих процессов (workflows) в виде YAML-файлов, которые определяют последовательность шагов, выполняемых при определенных событиях, таких как отправка кода в репозиторий. Автоматизированное тестирование включает в себя запуск модульных тестов, интеграционных тестов и тестов производительности, что позволяет быстро выявлять и устранять ошибки. Автоматическое развертывание позволяет обновлять модели в производственной среде без ручного вмешательства, обеспечивая более быстрый цикл разработки и поставки.
MLflow: централизованный контроль над экспериментом и версиями
MLflow предоставляет централизованную платформу для регистрации параметров, метрик и артефактов в процессе обучения моделей машинного обучения. Регистрация параметров включает в себя все входные данные, влияющие на обучение, такие как скорость обучения, размер пакета и архитектура модели. Метрики, например, точность и потери, записываются во время обучения для оценки производительности модели. Артефакты, включающие обученные модели, скрипты, наборы данных и любые другие файлы, необходимые для воспроизведения результатов, также хранятся централизованно. Это позволяет исследователям и инженерам отслеживать прогресс экспериментов, сравнивать различные конфигурации и обеспечивать воспроизводимость результатов обучения.
Централизованная регистрация параметров, метрик и артефактов в MLflow позволяет проводить сравнительный анализ различных экспериментов, выявляя наиболее эффективные конфигурации и модели. Детальная фиксация всех аспектов обучения, включая версии библиотек и используемые данные, обеспечивает воспроизводимость результатов, что критически важно для валидации, отладки и последующего повторного использования моделей. Возможность точного воссоздания условий эксперимента гарантирует, что полученные результаты не зависят от случайных факторов и могут быть подтверждены другими исследователями или использованы в производственной среде.
Встроенная система версионирования моделей в MLflow обеспечивает возможность отката к предыдущим версиям, что критически важно для восстановления работоспособности в случае обнаружения проблем в текущей версии. Каждая сохраненная версия модели включает в себя все необходимые метаданные, такие как параметры обучения, метрики и артефакты, что гарантирует воспроизводимость результатов и позволяет точно определить причину ухудшения производительности. Это позволяет командам разработчиков эффективно управлять жизненным циклом моделей, обеспечивая стабильную и предсказуемую работу в производственной среде и минимизируя риски, связанные с развертыванием новых версий.
По результатам недавних оценок, MLflow демонстрирует минимальные усилия по установке и настройке в сравнении с такими инструментами как Airflow, Metaflow и Kubeflow Pipelines. Данное преимущество обусловлено упрощенной архитектурой и меньшим количеством зависимостей, что позволяет быстро развернуть платформу даже в условиях ограниченных ресурсов и опыта. В частности, MLflow не требует развертывания сложной инфраструктуры оркестрации, в отличие от упомянутых инструментов, что существенно снижает порог входа для пользователей и команд разработчиков.
Интеграция MLflow с облачными платформами, такими как DigitalOcean, и инструментами CI/CD, например GitHub Actions, существенно упрощает процессы развертывания и мониторинга моделей машинного обучения. Автоматизация сборки, тестирования и развертывания моделей в CI/CD позволяет быстро внедрять изменения и обеспечивать непрерывную интеграцию и доставку (CI/CD). Развертывание моделей непосредственно на DigitalOcean позволяет использовать масштабируемую инфраструктуру без необходимости ручной настройки. Мониторинг производительности развернутых моделей, осуществляемый через MLflow, предоставляет данные о метриках, необходимых для отслеживания и поддержания качества работы модели в производственной среде.
От рукописных цифр к анализу тональности: разнообразие применений
Описанный фреймворк демонстрирует универсальность, успешно применяясь в различных задачах, включая классификацию изображений на примере знаменитого набора данных MNIST. Этот набор, состоящий из рукописных цифр, служит эталоном для оценки алгоритмов машинного зрения. Возможность эффективной реализации подобных задач подчеркивает гибкость системы и её пригодность для решения широкого спектра проблем, от автоматического распознавания символов до более сложных задач анализа изображений. Успешная работа с MNIST является показателем способности фреймворка к масштабированию и адаптации к различным типам данных и задачам, открывая перспективы для разработки инновационных приложений в области компьютерного зрения и искусственного интеллекта.
Анализ тональности, осуществляемый с помощью таких наборов данных, как IMDB, становится возможным благодаря данной платформе, открывая возможности для глубокого понимания мнения клиентов. Платформа позволяет обрабатывать большие объемы текстовой информации — отзывы, комментарии, публикации в социальных сетях — и автоматически определять эмоциональную окраску текста: положительную, отрицательную или нейтральную. Это позволяет компаниям оперативно выявлять проблемные зоны, оценивать эффективность маркетинговых кампаний и персонализировать взаимодействие с аудиторией, значительно повышая уровень удовлетворенности клиентов и укрепляя репутацию бренда.
Сочетание надёжных рабочих процессов, отслеживания экспериментов и масштабируемой инфраструктуры развертывания открывает новые горизонты для инноваций, основанных на данных. Эта синергия позволяет исследователям и разработчикам не только эффективно организовывать и документировать процесс машинного обучения — от подготовки данных до финальной модели — но и быстро итерировать, сравнивать результаты различных подходов и, что особенно важно, легко переносить разработанные решения в производственную среду. Такой комплексный подход значительно ускоряет цикл разработки, снижает риски, связанные с внедрением моделей, и позволяет организациям оперативно реагировать на меняющиеся потребности рынка, используя данные для принятия обоснованных решений и получения конкурентных преимуществ.
Недавние исследования подчеркивают сильные стороны Metaflow в области быстрого прототипирования, обусловленные его декларативной и воспроизводимой моделью программирования. Данный подход позволяет исследователям и разработчикам быстро итеративно создавать, тестировать и развертывать модели машинного обучения, минимизируя затраты времени и ресурсов. Декларативный стиль программирования позволяет сосредоточиться на что нужно сделать, а не на как это сделать, упрощая код и повышая его читаемость. Воспроизводимость, в свою очередь, обеспечивается автоматическим отслеживанием всех параметров эксперимента, версионированием кода и данных, а также возможностью точного воспроизведения результатов. Это особенно важно для обеспечения надежности и валидации моделей, а также для эффективного сотрудничества в командах разработчиков. В результате, Metaflow становится ценным инструментом для ускорения инноваций в области машинного обучения и расширения возможностей для решения сложных задач.
Постоянное совершенствование и расширение использования подобных технологий, как демонстрируют последние исследования, неизбежно ускорит прогресс в области машинного обучения и существенно повлияет на различные отрасли промышленности. Упрощение процессов разработки, отслеживание экспериментов и масштабируемая инфраструктура развертывания позволяют исследователям и разработчикам быстрее воплощать инновационные идеи в жизнь. Это, в свою очередь, открывает новые возможности для автоматизации, анализа данных и принятия обоснованных решений, оказывая влияние на такие сферы, как финансы, здравоохранение, розничная торговля и многие другие. Ожидается, что дальнейшая интеграция этих инструментов позволит создавать более интеллектуальные и эффективные системы, способные решать сложные задачи и приносить пользу обществу.
Исследование, представленное в данной работе, демонстрирует, что современные MLOps-фреймворки, несмотря на свою функциональность, часто страдают от избыточной сложности. Авторы подчеркивают важность четкой организации машинообучающих пайплайнов и эффективного управления версиями моделей. В контексте этого, справедливо замечание Эдсгера Дейкстры: «Простота — это высшая степень совершенства». Данная цитата отражает стремление к лаконичности и ясности, что является ключевым фактором успешной разработки и внедрения MLOps-систем. Излишняя сложность, напротив, может привести к ошибкам и затруднить поддержку, нивелируя все преимущества автоматизации и оркестрации пайплайнов.
Что дальше?
Представленная оценка инструментов MLOps выявляет не столько победителей, сколько границы применимости каждого из них. Упор на технические характеристики, несомненно, важен, однако истинная сложность заключается в адаптации этих систем к изменчивым потребностям конкретных задач машинного обучения. Попытки унифицировать процессы часто приводят к избыточности и усложнению, а не к упрощению.
Будущие исследования должны сосредоточиться не на создании «универсального» инструмента, а на разработке принципов композиции и интеграции. Необходимо учитывать не только техническую совместимость, но и организационные аспекты — скорость адаптации, стоимость обслуживания и, что важнее, способность к эволюции. Поиск оптимального решения — это не столько инженерная задача, сколько вопрос баланса между гибкостью и устойчивостью.
Вероятно, ключевым направлением станет автоматизация не самих пайплайнов, а процессов их рефакторинга и оптимизации. Самообучающиеся системы, способные адаптировать инфраструктуру машинного обучения к меняющимся данным и требованиям, представляются более перспективными, чем бесконечные добавления новых функций к существующим инструментам. Иногда, молчание о новых возможностях информативнее, чем их шумное внедрение.
Оригинал статьи: https://arxiv.org/pdf/2601.20415.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Адаптация моделей к новым данным: квантильная коррекция для нейросетей
- Игры в коалиции: где стабильность распадается на части.
- Разгадывая тайны рождения джетов: машинное обучение на службе физики высоких энергий
- Доказательство устойчивости веб-агента: проактивное свертывание контекста для задач с горизонтом в бесконечность.
- Доказательства просят: Как искусственный интеллект помогает отличать правду от вымысла
- Квантовый прорыв в планировании ресурсов 5G
- Интеллектуальный поиск научных статей: новый подход к исследованию литературы
- Квантовая статистика без границ: новый подход к моделированию
- Голос в переводе: как нейросети учатся понимать речь
2026-01-29 19:53