Автор: Денис Аветисян
Новое исследование показывает, что ключевое отличие опытных специалистов в области анализа данных — не последовательность действий, а гибкость и эффективность их выполнения.
Анализ рабочих процессов в Jupyter Notebooks позволяет выявить закономерности развития экспертности и оптимизировать обучение Data Science в эпоху генеративного искусственного интеллекта.
Развитие подлинной экспертности в науке о данных требует не только знания инструментов, но и овладения гибкими, процессными навыками, которые трудно передать напрямую. В исследовании ‘What makes an Expert? Comparing Problem-solving Practices in Data Science Notebooks’ проведен анализ 440 Jupyter-блокнотов для выявления различий в подходах к решению задач у опытных специалистов и новичков. Полученные данные свидетельствуют о том, что эксперты не отличаются от начинающих последовательностью этапов анализа данных, однако демонстрируют более структурированный рабочий процесс и эффективные, контекстно-зависимые действия на уровне отдельных ячеек кода. Не является ли развитие итеративного мышления ключевым фактором успешного обучения науке о данных в эпоху автоматизации и генеративных моделей искусственного интеллекта?
Взлом Системы: За рамками Техники — Адаптивное Решение Задач
Традиционное образование в области анализа данных зачастую делает акцент на освоении технических инструментов и алгоритмов, упуская из виду развитие навыков адаптивного решения проблем. Это приводит к формированию ощутимого разрыва между имеющимися знаниями и реальными потребностями рынка труда. Вместо того, чтобы обучать студентов гибкому мышлению и способности разбивать сложные задачи на более простые, учебные программы нередко ограничиваются изучением синтаксиса языков программирования и принципов работы отдельных моделей. В результате, специалисты, обладающие глубокими техническими знаниями, могут испытывать затруднения при столкновении с нестандартными ситуациями или при необходимости применения аналитических навыков в новых областях, что снижает их эффективность и конкурентоспособность.
Эффективные специалисты в области анализа данных не ограничиваются лишь знанием программных инструментов и алгоритмов. Ключевым навыком является умение разбивать сложные, многогранные задачи на более мелкие, управляемые компоненты. Этот процесс декомпозиции позволяет последовательно анализировать каждую часть, выявлять ключевые зависимости и находить оптимальные решения. Успешные специалисты способны не только применять известные методы к отдельным фрагментам проблемы, но и синтезировать полученные результаты, формируя целостную картину и адаптируя подход по мере необходимости. Именно способность к такому структурированному мышлению и позволяет эффективно справляться с реальными задачами, которые редко укладываются в рамки стандартных учебных примеров.
Современные задачи, с которыми сталкиваются специалисты по данным, характеризуются всё возрастающей сложностью и многогранностью, что требует отказа от линейных подходов в пользу гибкого мышления и итеративных стратегий. Традиционные методы решения проблем часто оказываются неэффективными при работе с неструктурированными данными, неопределенностью и постоянно меняющимися условиями. Успешные специалисты теперь должны уметь разбивать сложные вопросы на более мелкие, управляемые части, быстро адаптироваться к новым данным и результатам, а также постоянно пересматривать и совершенствовать свои решения на основе обратной связи. Этот переход предполагает развитие навыков критического мышления, креативности и способности к обучению на протяжении всей жизни, что позволяет эффективно справляться с непредсказуемыми вызовами и извлекать ценную информацию из сложных систем.
Реверс-Инжиниринг Данных: Многоуровневый Взгляд на Рабочий Процесс
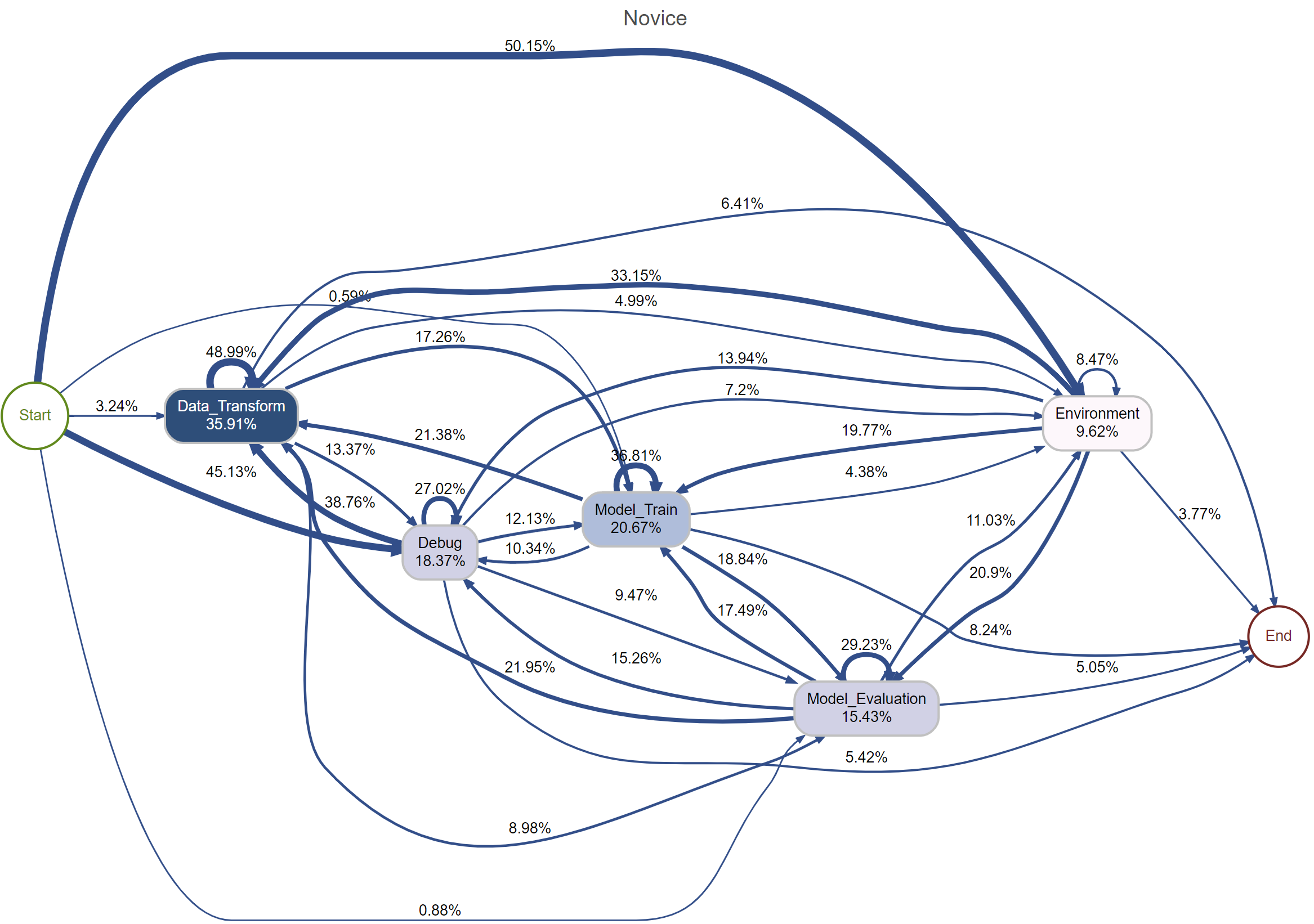
Предлагаемый многоуровневый фреймворк предоставляет детализированный взгляд на процесс Data Science, рассматривая его на трех уровнях: общий процесс, переходы между фазами и отдельные действия. Первый уровень охватывает весь цикл Data Science от постановки задачи до внедрения решения. Второй уровень фокусируется на критических точках перехода между фазами, таких как сбор данных, предобработка, моделирование и оценка, определяя ключевые критерии для перехода от одной фазы к другой. Третий уровень детализирует отдельные действия внутри каждой фазы, описывая конкретные задачи, инструменты и методы, используемые на каждом этапе. Такая гранулярность позволяет проводить более точный анализ и оптимизацию каждого аспекта процесса Data Science.
Данная структура объединяет ключевые элементы, такие как практики сбора данных, тщательное ведение записей и осмысленную интерпретацию, в единый рабочий процесс. Сбор данных включает в себя определение источников, методов получения и обеспечение репрезентативности выборки. Тщательное ведение записей подразумевает документирование всех этапов обработки данных, включая трансформации, очистку и обоснование принятых решений. Интерпретация данных, в свою очередь, фокусируется на извлечении значимых выводов, выявлении закономерностей и оценке статистической значимости полученных результатов, что необходимо для обоснованного принятия решений и построения надежных моделей.
В рамках предложенной многоуровневой структуры, практики рефлексии являются неотъемлемой частью итеративного процесса разработки решений на основе данных. Рефлексия подразумевает систематическую оценку каждого этапа, от сбора данных до интерпретации результатов, с целью выявления потенциальных улучшений и ошибок. Это включает в себя критический анализ принятых решений, используемых методов и полученных результатов, а также документирование полученного опыта для последующего использования и совершенствования подхода. Постоянная самооценка и коррекция действий на основе рефлексии позволяют оптимизировать процесс, повысить точность и надежность решений, а также адаптироваться к изменяющимся требованиям и данным.
Анализ Последовательностей: Раскрывая Скрытые Паттерны Экспертизы
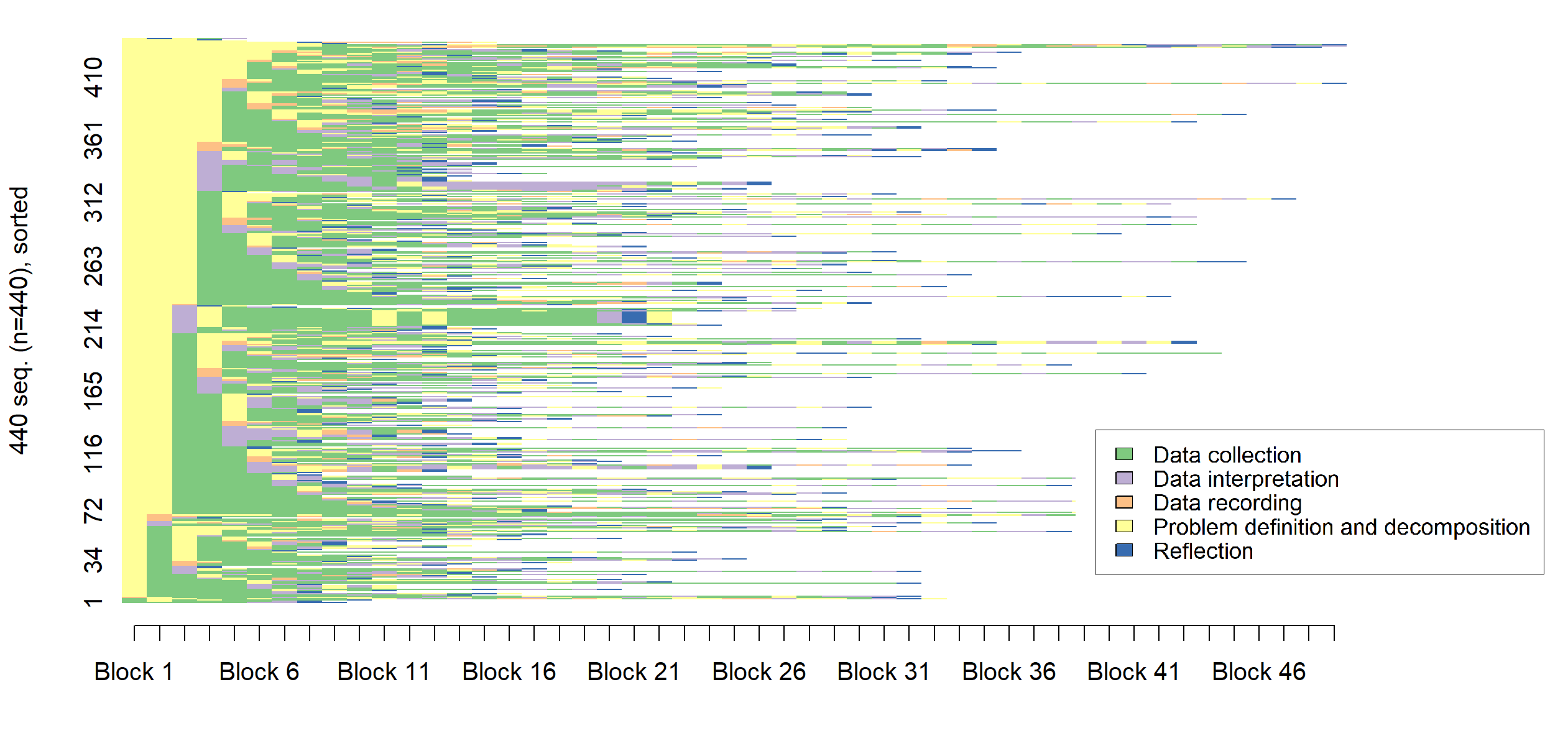
Анализ последовательностей, применяемый к Jupyter Notebooks, представляет собой эффективный метод выявления скрытых закономерностей в рабочих процессах специалистов по Data Science. Этот подход позволяет представить структуру каждого ноутбука как последовательность действий (например, загрузка данных, предобработка, обучение модели, визуализация результатов), что дает возможность количественно сравнивать и анализировать различные стратегии решения задач. Используя алгоритмы анализа последовательностей, можно выявлять общие паттерны, типичные ошибки и отличия в подходах между специалистами разного уровня квалификации. Полученные данные могут быть использованы для разработки инструментов автоматической оценки качества кода, персонализированного обучения и оптимизации рабочих процессов в области анализа данных.
Для проведения анализа структуры рабочих процессов в области Data Science использовался датасет Code4ML, представляющий собой коллекцию размеченных Jupyter Notebook, полученных с платформы Kaggle. Датасет содержит информацию о последовательности действий, выполненных пользователями при решении задач машинного обучения, и включает в себя метки, указывающие на уровень опыта пользователя — новичок или эксперт. Объем датасета позволяет проводить статистически значимые исследования, выявляющие закономерности в рабочих процессах различных групп пользователей. В частности, каждый блокнот в датасете содержит последовательность ячеек кода и текста, что позволяет проводить анализ последовательностей действий, определяющих структуру рабочего процесса.
Анализ структуры рабочих процессов в Jupyter Notebooks выявил статистически значимые различия между начинающими и опытными специалистами по Data Science. Опытные пользователи демонстрируют более короткие и итеративные процессы по сравнению с новичками. Показатель Silhouette Width, равный 0.28, указывает на наличие различимых, хотя и слабых, кластеров в структуре этих рабочих процессов, что подтверждает возможность их дифференциации на основе анализа последовательности действий. Данные различия позволяют предположить, что структура рабочего процесса может служить индикатором уровня экспертизы в области Data Science.
Статистическая значимость связи между структурой рабочих процессов и уровнем квалификации была подтверждена с использованием критерия хи-квадрат (χ² = 11.85, p = 0.0027). Полученное значение p меньше общепринятого порога статистической значимости (0.05), что указывает на то, что наблюдаемые различия в структуре рабочих процессов между начинающими и опытными специалистами не случайны. Таким образом, можно сделать вывод о наличии статистически подтвержденной связи между способом организации работы в Jupyter Notebook и уровнем владения навыками анализа данных.
Адаптивный Специалист по Данным: Принятие Итеративного Процесса
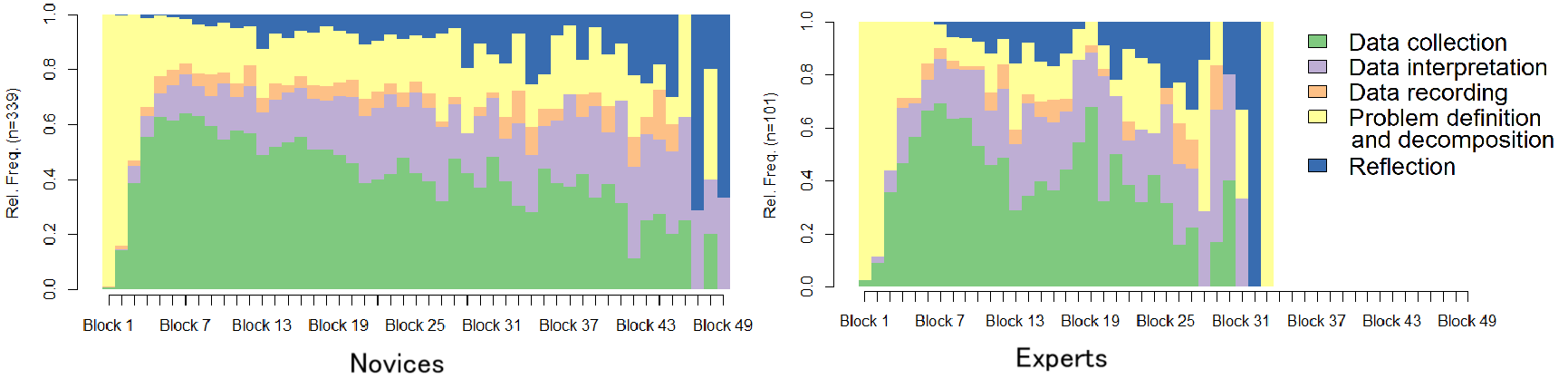
Исследования подтверждают, что итеративный процесс является ключевой характеристикой высококвалифицированных специалистов по анализу данных. Вместо того чтобы полагаться исключительно на знание отдельных инструментов и методов, эксперты демонстрируют способность гибко переходить от этапа к этапу — от формулирования гипотез и экспериментирования, к анализу результатов и их последующей корректировке. Этот подход позволяет им эффективно решать сложные задачи, адаптируясь к изменяющимся данным и требованиям, и, в конечном итоге, достигать более точных и значимых выводов. Итеративность выступает не просто методологией, а неотъемлемой частью профессиональной идентичности опытного специалиста в области анализа данных.
Исследование выявило, что опытные специалисты по анализу данных отличаются способностью плавно переходить между этапами экспериментирования, уточнения и оценки. Они не придерживаются жесткого линейного подхода, а демонстрируют гибкость, постоянно адаптируя стратегии на основе полученных результатов. Такой циклический процесс позволяет им эффективно решать сложные задачи, быстро выявлять и корректировать ошибки, а также непрерывно улучшать модели и алгоритмы. Эта способность к итеративному совершенствованию является ключевым отличием экспертов и позволяет им успешно справляться с динамично меняющимися данными и требованиями.
Наблюдения за работой опытных специалистов в области анализа данных выявляют важный сдвиг в приоритетах. Если ранее акцент делался на простом владении инструментами и методами, то теперь ключевым навыком становится умение гибко применять эти инструменты в рамках итеративного подхода. Вместо заучивания алгоритмов и синтаксиса, эксперты демонстрируют способность адаптироваться к меняющимся требованиям задачи, постоянно экспериментировать, оценивать результаты и совершенствовать свои решения. Этот переход подчеркивает, что истинная ценность специалиста заключается не в объеме знаний, а в умении эффективно использовать их для достижения конкретных целей, быстро реагируя на новые данные и вызовы.
Исследование демонстрирует, что экспертность в науке о данных определяется не столько последовательностью шагов, сколько гибкостью и эффективностью их выполнения. Ключевым является умение адаптироваться и итерировать процесс, а не следовать жесткому плану. В этом контексте особенно примечательна фраза Кena Thompson: «Программы должны быть достаточно маленькими, чтобы их можно было понять». Подобно компактному и элегантному коду, эффективный подход к решению задач в науке о данных требует лаконичности и ясности, позволяющих быстро адаптироваться к новым данным и задачам. Понимание принципов работы системы, будь то программа или процесс анализа данных, открывает путь к её оптимизации и контролю.
Куда это всё ведёт?
Исследование, по сути, лишь подтверждает старую истину: важен не сам инструментарий, а умение им пользоваться. Зафиксировать последовательность действий — это всё равно что разобрать часы, чтобы понять время. Понимание же приходит лишь при наблюдении за тем, как эти действия выполняются, с какой гибкостью и эффективностью. Особый интерес представляет вопрос о том, как меняется эта «гибкость» в эпоху генеративных моделей искусственного интеллекта. Не приведёт ли повсеместное использование готовых решений к атрофии навыков самостоятельного решения проблем, к упрощению мышления?
Очевидное ограничение текущего анализа — фокус на вычислительных блокнотах. Мир разработки не ограничивается ими, и методы, эффективные в одной среде, могут оказаться бесполезными в другой. Следующим шагом видится расширение области исследования, включение в анализ других типов рабочих процессов, а также изучение того, как различные инструменты влияют на формирование экспертного мышления. Попытка формализовать «гибкость» и «эффективность» представляется задачей, достойной усилий.
И, конечно, возникает вопрос о том, что вообще значит «экспертность» в эпоху, когда знания устаревают быстрее, чем успеваешь их приобрести. Возможно, настало время пересмотреть сами критерии оценки, сместив акцент с накопления информации на умение быстро адаптироваться, критически мыслить и находить нестандартные решения. Ведь, в конечном счете, знание — это лишь исходный код, а мастерство — умение его взламывать и переписывать.
Оригинал статьи: https://arxiv.org/pdf/2602.15428.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и квантовая физика: кто кого?
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Взрыв скорости: Оптимизация внимания для современных GPU
- Знаем, чего не знаем: Моделирование вероятностных рассуждений на основе множественных доказательств
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Языковые модели и границы возможного: что делает язык человеческим?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Память на заказ: Как обучить агентов взаимодействовать эффективнее
- Понять Мысли Ученика: Как Искусственный Интеллект Расшифровывает Решения по Математике?
2026-02-19 03:54