Автор: Денис Аветисян
Представлена DeepSeekMath-V2 — языковая модель, способная самостоятельно проверять и улучшать математические рассуждения, демонстрируя впечатляющие результаты в решении сложных задач.
DeepSeekMath-V2 использует обучение с подкреплением и верификацию доказательств для достижения передовых результатов в математических соревнованиях.
Несмотря на значительный прогресс в математическом рассуждении, достигнутый большими языковыми моделями, простое повышение точности конечного ответа не гарантирует корректность самого процесса вывода. В работе ‘DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning’ предложена новая архитектура, основанная на самоверификации доказательств и итеративном улучшении, позволяющая модели не только решать сложные задачи, но и подтверждать правильность каждого шага решения. Разработанная модель DeepSeekMath-V2 демонстрирует передовые результаты в доказательстве теорем, включая золотые медали на IMO 2025 и CMO 2024, а также практически идеальный результат на Putnam 2024. Не откроет ли это путь к созданию искусственного интеллекта, способного к глубокому и надежному математическому мышлению, сравнимому с человеческим?
Математическая Истина: Вызов Автоматизированному Доказательству
Автоматизированное доказательство теорем играет ключевую роль в верификации современных сложных систем, начиная от программного обеспечения и заканчивая аппаратными средствами. Однако, несмотря на значительный прогресс в области искусственного интеллекта, эта задача остается серьезным вызовом. Суть проблемы заключается в экспоненциальном росте вычислительной сложности по мере увеличения размера и усложнения проверяемой системы. Традиционные методы, основанные на логическом выводе и поиске доказательств, часто оказываются неэффективными или неспособными справиться с задачами, требующими глубокого понимания контекста и неявных знаний. Необходимость в надежной и автоматизированной верификации обусловлена растущей зависимостью общества от критически важных систем, в которых даже небольшая ошибка может привести к катастрофическим последствиям. Поэтому поиск новых подходов к автоматическому доказательству теорем остается приоритетной задачей для исследователей в области ИИ.
Традиционные методы автоматического доказательства теорем, несмотря на свою эффективность в простых случаях, сталкиваются с существенными трудностями при работе с нетривиальными задачами. Ограниченность этих подходов обусловлена необходимостью явного представления всех шагов логического вывода, что становится непосильным бременем при возрастающей сложности доказуемых утверждений. Неспособность улавливать тонкие нюансы, контекст и интуитивные подходы, присущие человеческому мышлению, приводит к экспоненциальному росту вычислительных затрат и невозможности решения многих задач. В связи с этим, современное направление исследований фокусируется на разработке новых методов, использующих, например, вероятностные модели и машинное обучение, для более гибкого и эффективного подхода к логическому выводу и преодоления ограничений, свойственных классическим системам доказательства теорем. Подобные инновации направлены на создание систем, способных не просто формально подтверждать истинность утверждений, но и “понимать” их смысл и адаптироваться к различным контекстам.
DeepSeekMath-V2: Основа Самопроверяемого Рассуждения
DeepSeekMath-V2 использует архитектуру большой языковой модели, построенную на базе DeepSeek-V3.2-Exp-Base, и специализируется на доказательстве теорем на естественном языке. В качестве основы была выбрана модель DeepSeek-V3.2-Exp-Base, обладающая улучшенными возможностями генерации текста и понимания сложных логических конструкций. Оптимизация для задач формального доказательства включала в себя предобучение на обширном корпусе математических текстов и доказательств, а также тонкую настройку на специализированных задачах, требующих логического вывода и проверки корректности $latex формул$. Данная архитектура позволяет модели эффективно обрабатывать математические выражения, выводить логические следствия и генерировать пошаговые доказательства теорем.
Модель DeepSeekMath-V2 демонстрирует высокую эффективность как в генерации доказательств, так и в верификации доказательств. Этот процесс реализован в виде замкнутого цикла, где сгенерированное доказательство автоматически подвергается проверке самой моделью. В частности, модель способна генерировать последовательность логических шагов, необходимых для решения математической задачи, а затем анализировать эту последовательность на предмет корректности и полноты, используя внутренние критерии оценки. Такая архитектура позволяет модели самостоятельно выявлять и корректировать ошибки, повышая надежность и точность результатов, и снижая потребность во внешней проверке.
Ключевой особенностью DeepSeekMath-V2 является наличие механизмов самопроверки, позволяющих модели выявлять потенциальные ошибки в генерируемых доказательствах до внешней оценки. Этот процесс включает в себя анализ шагов доказательства и оценку их соответствия логическим правилам и аксиомам. В частности, модель способна идентифицировать противоречия в рассуждениях, некорректные применения правил вывода и другие логические несоответствия, что значительно повышает надежность и достоверность получаемых результатов. Самопроверка осуществляется посредством независимой оценки, отличной от процесса генерации доказательства, что минимизирует риск подтверждения собственной ошибки.

Обучение с Подкреплением для Надежности и Точности
В DeepSeekMath-V2, как генерация, так и верификация математических доказательств оптимизируются с использованием методов обучения с подкреплением. Этот подход позволяет модели самостоятельно улучшать стратегии построения и проверки доказательств, максимизируя вероятность успешного решения математических задач. Обучение с подкреплением применяется для определения оптимальной последовательности шагов, необходимых для достижения цели — формирования корректного и полного доказательства для заданного математического утверждения или, наоборот, для эффективной оценки корректности представленного доказательства. В процессе обучения модель получает вознаграждение за правильные шаги и штрафы за ошибки, что способствует развитию навыков генерации и верификации доказательств с высокой точностью и надежностью.
В DeepSeekMath-V2 для оптимизации стратегий генерации и верификации математических доказательств используется алгоритм GRPO (Generalized Rollout Policy Optimization). GRPO обеспечивает эффективную оптимизацию политики в сложном пространстве возможных доказательств, позволяя модели находить оптимальные последовательности шагов для решения математических задач. Алгоритм основан на оценке ценности действий в процессе построения доказательства и использует обобщенный подход к оценке политики, что позволяет улучшить качество генерируемых решений и повысить точность верификации. Особенностью GRPO является возможность эффективной работы с дискретными пространствами действий, характерными для задач, связанных с математическими доказательствами, где каждый шаг представляет собой выбор определенной операции или утверждения.
Для оценки качества верификатора, используемого в DeepSeekMath-V2, применяется процесс вторичной проверки, получивший название “Мета-верификация”. Данный процесс предполагает независимую оценку корректности работы верификатора на специально подобранном наборе задач, отличных от тех, что используются для обучения и основной проверки. Целью мета-верификации является выявление потенциальных ошибок или слабых мест в логике верификатора, а также обеспечение дополнительного уровня гарантии достоверности результатов, получаемых системой в целом. Оценка производится на основе статистических показателей, таких как точность и полнота, позволяющих количественно оценить эффективность верификатора в различных сценариях.
Производительность и Значение для Рассуждений ИИ
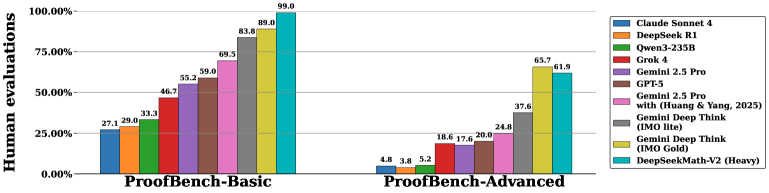
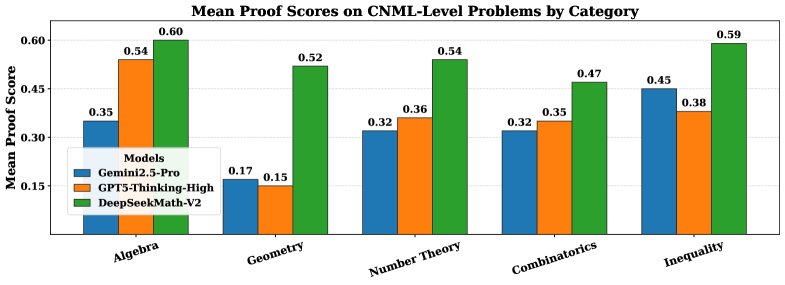
Модель DeepSeekMath-V2 продемонстрировала выдающиеся результаты на ряде авторитетных бенчмарков, предназначенных для оценки способностей к математическому рассуждению. Успешно решая задачи из `IMO-ProofBench` и `ISL`, а также демонстрируя превосходство в различных математических соревнованиях, включая `IMO`, `CMO` и `Putnam Competition`, система подтверждает свою высокую эффективность. Особенно примечательно, что модель не только успешно справляется со сложными математическими проблемами, но и демонстрирует стабильность и надежность в решении задач различного уровня сложности, что указывает на потенциал для создания более интеллектуальных и эффективных систем искусственного интеллекта в области математики и за ее пределами.
Модель DeepSeekMath-V2 продемонстрировала исключительные результаты в решении сложных математических задач, достигнув золотого уровня на международных олимпиадах `IMO 2025` и `CMO 2024`. Особенно впечатляющим стало выступление на конкурсе `Putnam 2024`, где модель набрала $118$ баллов из $120$ возможных, превзойдя лучший человеческий результат в $90$ баллов. Этот показатель не только подтверждает способность модели к глубокому математическому мышлению, но и указывает на потенциальную возможность создания искусственного интеллекта, способного решать задачи, которые ранее считались прерогативой человеческого интеллекта. Данные достижения открывают новые перспективы для применения ИИ в различных областях науки и техники, требующих сложных вычислений и логического анализа.
В ходе тестирования на наборе данных $IMO-ProofBench$, модель DeepSeekMath-V2 продемонстрировала превосходство над системой DeepThink, успешно решая более сложные математические задачи. Особенно примечательно, что DeepSeekMath-V2 сохраняет высокую конкурентоспособность даже на продвинутом подмножестве $IMO-ProofBench$, требующем более глубокого понимания и нестандартных подходов к решению. Данный результат указывает на значительный прогресс в способности искусственного интеллекта к формальному логическому мышлению и математическому доказательству, подтверждая потенциал модели в решении сложных задач, ранее доступных лишь квалифицированным математикам.
Достижения DeepSeekMath-V2 указывают на перспективность интеграции больших языковых моделей с методами обучения с подкреплением и самопроверкой как пути к созданию более надёжных и заслуживающих доверия систем искусственного интеллекта. Сочетание способности языковых моделей к логическому выводу с механизмом обучения, основанным на вознаграждении за корректные решения, позволяет модели не только генерировать ответы, но и оценивать их достоверность. Самопроверка, как неотъемлемая часть этого процесса, способствует повышению точности и снижению вероятности ошибок в сложных задачах, требующих строгого математического доказательства. Данный подход открывает возможности для разработки ИИ, способного не просто выдавать результаты, но и аргументированно обосновывать их, что является ключевым шагом на пути к созданию действительно интеллектуальных систем.
Данная работа демонстрирует стремление к математической строгости в области искусственного интеллекта. Модель DeepSeekMath-V2, используя подход, сочетающий обучение с подкреплением и самопроверку доказательств, воплощает идею о том, что алгоритм должен быть доказуем, а не просто эмпирически подтвержден. Этот акцент на верификации перекликается с мыслями Г.Х. Харди: “Математика — это наука о том, что можно доказать, а не о том, что можно вычислить.” Подход к самопроверке, предложенный в статье, является воплощением принципа математической чистоты, стремясь к абсолютной корректности решения, а не к простому достижению результата на тестовых примерах. Использование мета-верификации усиливает эту направленность на абсолютную точность, что является ключевым аспектом представленного исследования.
Куда же дальше?
Представленная работа, безусловно, демонстрирует значительный прогресс в области автоматизированного доказательства теорем. Однако, необходимо признать, что способность модели к “самопроверке” не является заменой строгой математической дедукции. Скорее, это изящный способ повысить вероятность получения корректного решения, а не гарантия его истинности. Проблема в том, что даже самая сложная система обучения с подкреплением не может исключить возможность ошибок, особенно в сложных и нетривиальных задачах. Истинная элегантность заключается не в количестве решенных задач, а в гарантии их корректности.
Будущие исследования, вероятно, будут направлены на интеграцию формальных методов верификации с архитектурами больших языковых моделей. Простая комбинация мощности генерации и строгости формальных систем представляется весьма перспективной. Необходимо разработать методы, позволяющие модели не только генерировать доказательства, но и формально их проверять, а также выявлять и исправлять ошибки в процессе рассуждений. Попытки создать “самообучающийся верификатор” представляются более плодотворными, чем бесконечная гонка за увеличением количества решаемых задач.
В конечном счете, задача не в том, чтобы научить машину “думать как математик”, а в том, чтобы создать инструмент, способный помогать математику в его работе. Истинное решение всегда требует человеческого понимания и контроля, даже если большая часть рутинной работы автоматизирована. Машина может предложить гипотезу, но подтвердить или опровергнуть её должен человек.
Оригинал статьи: https://arxiv.org/pdf/2511.22570.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовый скачок: от лаборатории к рынку
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2025-12-02 02:51