Автор: Денис Аветисян
Новая система позволяет находить математические теоремы, опираясь на смысл их формулировок, а не только на ключевые слова.
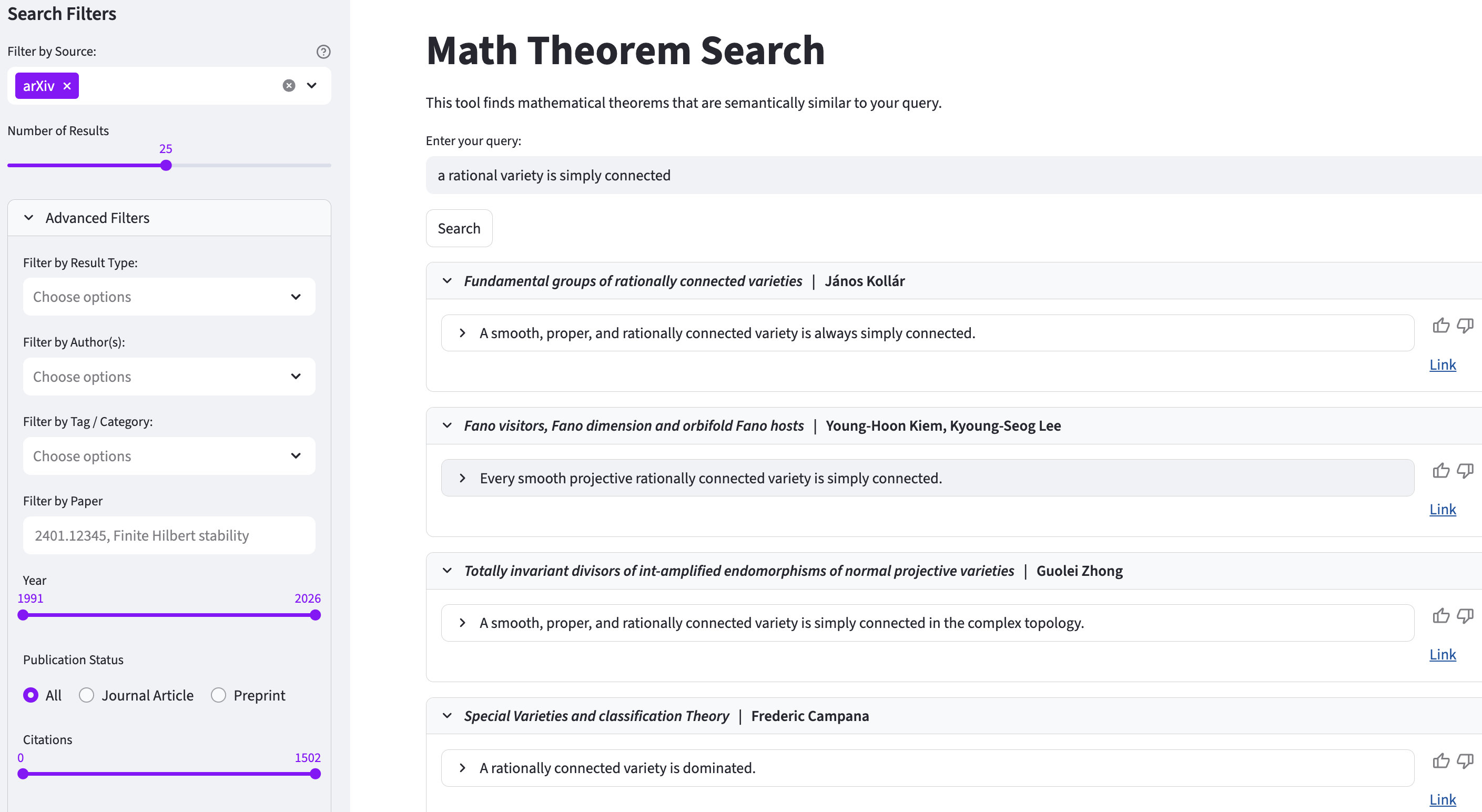
Исследователи разработали корпус из 9 миллионов теорем и систему семантического поиска, использующую большие языковые модели для представления теорем в виде понятных слоганов.
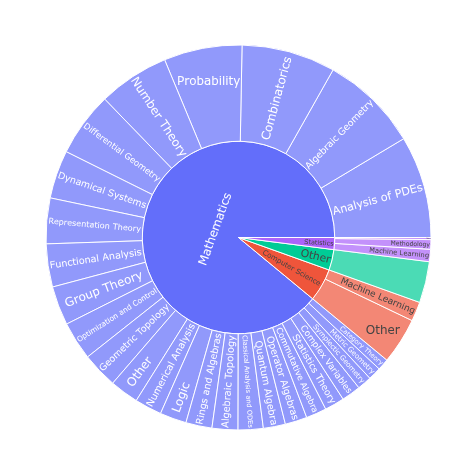
Поиск математических результатов традиционно затруднен из-за необходимости просматривать полные научные статьи вместо конкретных теорем, лемм или предложений. В работе ‘Semantic Search over 9 Million Mathematical Theorems’ представлен масштабный корпус, включающий 9.2 миллиона математических утверждений, извлеченных из различных источников, и разработан метод семантического поиска, использующий большие языковые модели для представления теорем в виде кратких описаний на естественном языке. Показано, что предложенный подход существенно повышает точность поиска как отдельных теорем, так и соответствующих публикаций, демонстрируя эффективность семантического поиска в масштабах интернета. Какие перспективы открывает создание подобных корпусов и систем для автоматизации математических исследований и проверки гипотез?
Преодоление Тупиков: Поиск Смысла в Математических Текстах
Традиционные методы поиска в математической литературе, основанные на сопоставлении ключевых слов, часто оказываются неэффективными при выявлении глубоких смысловых связей между теоремами. Данный подход, хотя и прост в реализации, упускает из виду случаи, когда различные математические утверждения выражают одну и ту же идею, используя отличную терминологию или формулировки. Например, теоремы, доказывающие эквивалентность различных математических объектов, могут не обнаруживаться, если ключевые слова в их названиях и абстрактах не совпадают. Это приводит к дублированию усилий, замедляет процесс математических открытий и препятствует формированию целостного представления о математической теории. Поиск по ключевым словам не учитывает контекст, аналогию или логическую эквивалентность утверждений, что ограничивает его способность находить действительно релевантные результаты и способствует фрагментации математических знаний.
Несмотря на несомненную пользу платформы arXiv, предоставляющей доступ к огромному количеству математических работ, этот же объем информации создает серьезные трудности для исследователей. Ежедневно на arXiv публикуются тысячи препринтов, что делает поиск релевантных результатов чрезвычайно сложной задачей. Традиционные методы поиска, основанные на сопоставлении ключевых слов, часто оказываются неэффективными в условиях такого информационного потока, поскольку не способны учитывать контекст и семантические связи между теоремами. В результате, ученым приходится тратить значительное время и усилия на просеивание огромного количества публикаций, чтобы найти действительно важные и полезные материалы для своей работы. Эта проблема подчеркивает необходимость разработки новых, более интеллектуальных методов поиска, способных эффективно обрабатывать и анализировать огромные объемы математической литературы.
Существующие методы поиска математических теорем часто оказываются неспособны уловить тонкие смысловые оттенки математических утверждений, что серьезно затрудняет эффективный поиск. Проблема заключается в том, что математический язык, несмотря на свою формальную строгость, допускает множество интерпретаций и неявно подразумеваемых связей. Алгоритмы, основанные на простом сопоставлении ключевых слов или синтаксическом анализе, не способны распознать эти скрытые взаимосвязи, особенно когда теоремы сформулированы в различных, но эквивалентных, терминах. Например, утверждение о свойствах групп может быть сформулировано в терминах гомоморфизмов, подгрупп или даже через более абстрактные алгебраические структуры, что делает невозможным его обнаружение при поиске только по явным ключевым словам. Это приводит к тому, что исследователи тратят значительное время на изучение нерелевантной литературы, упуская из виду важные результаты, которые могли бы ускорить прогресс в их области. Более того, неспособность понять семантику математических выражений, таких как \sum_{i=1}^{n} x_i , ограничивает возможности автоматического доказательства теорем и построения математических моделей.
Семантический Поиск: Новый Взгляд на Поиск Теорем
Семантический поиск использует текстовые вложения (Text Embeddings) для представления как запросов, так и теорем в виде векторов в многомерном пространстве. Эти вложения, полученные посредством моделей машинного обучения, кодируют семантическое значение текста в числовые представления фиксированной длины. Каждый вектор отражает смысловое содержание соответствующего текстового фрагмента, позволяя алгоритмам вычислять расстояние или косинусное сходство между векторами запроса и теорем. Более короткое расстояние или более высокое косинусное сходство указывает на более тесную семантическую связь между запросом и теоремой, даже при отсутствии лексического совпадения. Размерность пространства векторов может достигать сотен или тысяч, обеспечивая детальное представление семантической информации. Использование векторного представления позволяет эффективно индексировать и искать теоремы, основываясь на их значении, а не только на ключевых словах.
Система семантического поиска определяет концептуальную связь между запросом и теоремами путем измерения сходства между их векторными представлениями. Этот процесс, основанный на косинусном расстоянии или других метриках, позволяет выявлять теоремы, релевантные запросу, даже если они не содержат общих ключевых слов. Векторные представления, полученные с помощью моделей встраивания текста, кодируют семантическое значение, что позволяет системе улавливать скрытые связи и находить теоремы, основанные на общих концепциях, а не только на лексическом совпадении. Это особенно важно в математике, где различные обозначения и формулировки могут выражать одно и то же математическое утверждение.
Математический поиск информации (Mathematical Information Retrieval) использует принципы семантического поиска, но адаптирует их для специфики математической литературы. В отличие от традиционного поиска по ключевым словам, он учитывает уникальные особенности математических текстов, такие как высокая плотность формул, использование символов и обозначений, а также абстрактный характер понятий. Это достигается за счет применения специализированных моделей векторных представлений (embeddings), обученных на корпусах математических текстов, что позволяет более точно сопоставлять запросы и теоремы, даже если они не содержат общих терминов, но связаны логически или концептуально. Например, поиск по понятию ∇ (набла) может вернуть теоремы, использующие эквивалентные обозначения или связанные с векторным анализом, даже если само слово «набла» в них не встречается.
Плотный Поиск и Продвинутые Модели Встраивания
Метод плотного поиска (Dense Retrieval) использует текстовые вложения (Text Embeddings), генерируемые моделями, такими как Sentence-BERT и Qwen3-Embedding, для представления запросов и документов в виде векторов в многомерном векторном пространстве. Этот процесс позволяет выполнять семантический поиск, где близость векторов определяет релевантность документа запросу. Вместо сопоставления ключевых слов, система оценивает смысловое сходство между запросом и документом, основываясь на векторном представлении их содержания. Модели Sentence-BERT и Qwen3-Embedding обучены генерировать векторные представления, отражающие семантическое значение текста, что позволяет эффективно находить релевантные документы даже при отсутствии точного совпадения ключевых слов.
Модель ColBERT улучшает процесс плотного поиска за счет использования “позднего взаимодействия” (late interaction), в отличие от традиционных подходов, где векторы запроса и документа сравниваются целиком. ColBERT генерирует векторные представления для каждого токена запроса и каждого токена документа. Сравнение происходит на уровне отдельных токенов, а агрегация результатов осуществляется на заключительном этапе. Это позволяет более точно учитывать семантические связи между конкретными словами в запросе и документе, что приводит к повышению релевантности результатов поиска по сравнению с моделями, выполняющими сравнение на уровне всего запроса и документа.
Для эффективного поиска ближайших соседей в векторном пространстве, используемом в системах Dense Retrieval, широко применяется индекс HNSW (Hierarchical Navigable Small World). Этот алгоритм обеспечивает масштабируемость и высокую скорость поиска за счет построения многоуровневого графа, где каждый узел представляет собой вектор, а ребра соединяют ближайших соседей. Дальнейшая оптимизация достигается применением бинарной квантизации (Binary Quantization), снижающей требования к памяти и ускоряющей вычисления, а также интеграцией с PGVector — расширением PostgreSQL, позволяющим хранить и индексировать векторные представления непосредственно в базе данных, что упрощает развертывание и управление системами поиска.

Извлечение Знаний и Генерация: Усиление Рассуждений
Метод Retrieval-Augmented Generation (RAG) объединяет в себе мощь плотного поиска и большие языковые модели, что позволяет значительно повысить точность и обоснованность извлечения математических теорем. Вместо того, чтобы полагаться исключительно на собственные знания языковой модели, RAG сначала осуществляет поиск релевантных теорем из внешней базы данных, используя методы плотного поиска для эффективного сопоставления запросов и существующих знаний. Затем, найденные теоремы предоставляются языковой модели в качестве контекста, что позволяет ей генерировать более точные и обоснованные ответы, а также избегать галлюцинаций и ошибок. Такой подход обеспечивает доступ к обширному объему математических знаний и позволяет решать задачи, требующие глубокого понимания и применения сложных теорем, что особенно важно в области формальной математики и автоматизированного доказательства теорем.
Проект LeanSearch демонстрирует практическое применение подхода, объединяющего поиск релевантной информации и генеративные языковые модели, для расширения возможностей формальных математических библиотек. Система не просто предоставляет пользователю теоремы, но активно использует их в процессе логических рассуждений и доказательств. Она позволяет автоматизировать поиск необходимых математических утверждений, необходимых для решения задач или построения новых теорий, существенно ускоряя и упрощая работу с формализованными знаниями. Используя извлеченные теоремы в качестве основы для дальнейших вычислений и логических операций, LeanSearch предоставляет платформу для более эффективного исследования и развития математической науки, открывая новые горизонты для автоматизированного доказательства теорем и проверки математических утверждений.
Исследование продемонстрировало значительное улучшение точности поиска математических теорем. Система, использующая подход Retrieval-Augmented Generation, достигла показателя в 45.0% Hit@20 при поиске непосредственно теорем в специально подобранном наборе данных. Этот результат превосходит аналогичные показатели существующих инструментов, таких как ChatGPT 5.2, Gemini 3 Pro и Google Search. Особенно заметно превосходство над Google Search, который демонстрирует лишь 37.8% Hit@20 при поиске на уровне научных статей. Более того, при поиске статей система достигает 56.8% Hit@20, также опережая Google Search. Данные показатели свидетельствуют о существенном прогрессе в области извлечения математической информации и открывают новые возможности для автоматизированных систем доказательства теорем, образовательных ресурсов и помощи в научных исследованиях.
Полученные результаты демонстрируют значительный прорыв в области поиска математической информации. Достигнув показателя в 45.0% Hit@20 на уровне теорем и 56.8% Hit@20 на уровне статей, система, основанная на методе Retrieval-Augmented Generation, превзошла существующие инструменты, включая ChatGPT 5.2, Gemini 3 Pro и даже Google Search (37.8% Hit@20 на уровне статей). Такое улучшение свидетельствует о повышенной эффективности и точности извлечения релевантных математических теорем и публикаций, что открывает новые возможности для автоматизированных систем доказательства теорем, образовательных ресурсов и помощи в научных исследованиях. Данный прогресс подчеркивает потенциал интеграции методов поиска информации и больших языковых моделей для решения сложных задач в математике и смежных областях.
В этой работе, как и во многих других, авторы пытаются приручить хаос математических теорем, выстраивая из них стройные ряды для поиска. Создание корпуса из девяти миллионов теорем и применение LLM для генерации естественных языковых слоганов — это, конечно, элегантно. Но, как известно, продакшен всегда найдёт способ сломать элегантную теорию. Клод Шеннон как-то сказал: «Информация — это не то, что мы передаём, а то, что принимающая сторона понимает». В данном случае, понимает ли система тонкости математической логики, или просто оперирует похожими фразами — вопрос риторический. Главное, чтобы система работала, хотя бы какое-то время, пока не появится новая, ещё более изощрённая задача.
Что дальше?
Представленный корпус теорем, конечно, впечатляет масштабом. Но стоит помнить: любая база знаний — это просто аккуратная стопка будущих ошибок. Система семантического поиска, использующая большие языковые модели, на данный момент демонстрирует неплохие результаты. Однако, как только кто-нибудь попытается использовать её для решения реальной задачи, а не просто поиска по слоганам, все эти эмбеддинги и «самовосстанавливающиеся» алгоритмы неизбежно дадут сбой. Документация, разумеется, будет утверждать обратное.
Следующим этапом, вероятно, станет попытка автоматической верификации найденных теорем. Но это лишь отодвинет проблему: ошибка в доказательстве — не значит, что теорема неверна, а значит, что система не смогла её правильно интерпретировать. Если баг воспроизводится — это не признак стабильности, а признак того, что мы достаточно долго наблюдали за системой, чтобы его обнаружить.
В конечном счёте, всё это — лишь ещё один уровень абстракции над хаосом. И, как показывает опыт, любой «революционный» подход рано или поздно превращается в техдолг. Задача не в том, чтобы создать идеальную систему поиска, а в том, чтобы смириться с неизбежной неточностью и научиться с ней жить. И, разумеется, вовремя делать бэкапы.
Оригинал статьи: https://arxiv.org/pdf/2602.05216.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Визуальное мышление машин: проверка на прочность
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Ожившие Миры: Новая Эра Видеогенерации
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
2026-02-06 07:47