Автор: Денис Аветисян
Исследователи представили StructuralCFN — нейронную сеть, способную выявлять и использовать математические зависимости в табличных данных, обеспечивая высокую точность и понятность результатов.
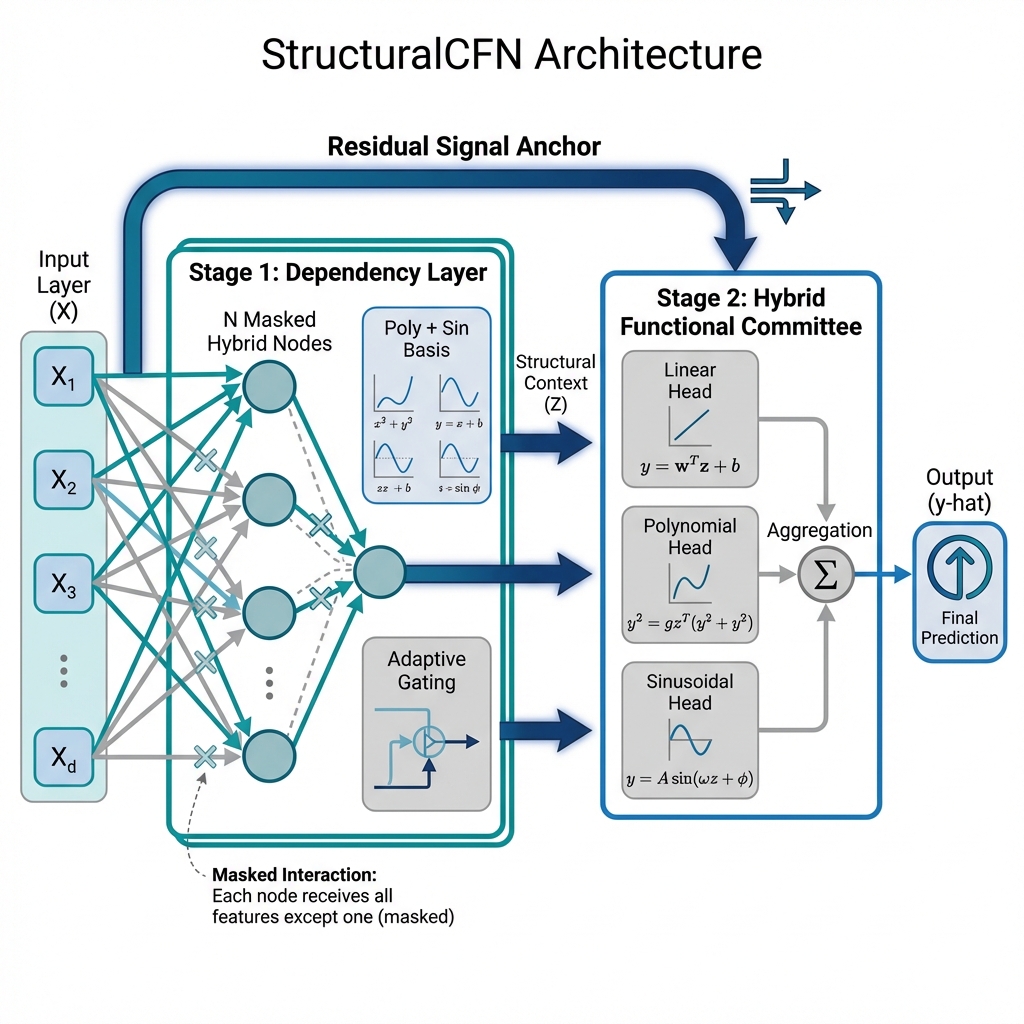
Структурные сети функциональной композиции для табличных данных с использованием априорных знаний и дифференцируемого программирования.
Несмотря на широкое распространение табличных данных в критически важных областях, глубокие нейронные сети часто уступают по производительности градиентному бустингу, сохраняя при этом научную интерпретируемость. В данной работе, посвященной ‘Structural Compositional Function Networks: Interpretable Functional Compositions for Tabular Discovery’, предложена новая архитектура StructuralCFN, которая накладывает отношение-ориентированный индуктивный уклон посредством дифференцируемого структурного априорного знания. StructuralCFN явно моделирует каждую характеристику как математическую композицию ее аналогов, автоматически обнаруживая оптимальную «физику активации» для каждой связи, и позволяет интегрировать специфические для предметной области знания. Возможно ли с помощью подобного подхода создавать компактные и интерпретируемые модели для табличных данных, раскрывающие скрытые закономерности и взаимосвязи?
За пределами «Черных Ящиков»: Необходимость Интерпретируемого Искусственного Интеллекта
Традиционные модели машинного обучения, несмотря на свою вычислительную мощь и способность решать сложные задачи, часто характеризуются недостаточной прозрачностью. Это означает, что процесс принятия решений внутри модели остается непрозрачным, подобно «черному ящику», где невозможно однозначно проследить, какие факторы и каким образом привели к конкретному результату. Отсутствие понимания внутренней логики затрудняет не только отладку и выявление ошибок, но и порождает недоверие со стороны пользователей и экспертов, особенно в критически важных областях, таких как медицина или финансы. Невозможность объяснить, почему модель пришла к определенному выводу, снижает уверенность в ее надежности и препятствует широкому внедрению в практические приложения.
Особую остроту проблема «черного ящика» приобретает при работе со сложными табличными данными, где понимание взаимодействия между признаками является ключевым. В отличие от изображений или текста, где закономерности могут быть визуально очевидны, в табличных данных влияние отдельных признаков и их комбинаций часто скрыто. Например, при оценке кредитоспособности заемщика, не только доход и кредитная история важны, но и их взаимосвязь — например, стабильный, но невысокий доход в сочетании с безупречной кредитной историей может оказаться более благоприятным фактором, чем высокий, но непостоянный доход. Отсутствие возможности понять, какие именно комбинации признаков приводят к определенным результатам, затрудняет выявление предвзятости, обеспечение справедливости и надежности модели, а также лишает возможности использовать знания, полученные моделью, для более глубокого понимания самой предметной области.
Растущий спрос на объяснимый искусственный интеллект (XAI) стимулирует активные поиски новых архитектур, которые не просто демонстрируют высокую производительность, но и позволяют понять логику принятия решений. Исследователи стремятся создать модели, где прозрачность и интерпретируемость являются неотъемлемой частью конструкции, а не добавлением после факта. Это означает разработку алгоритмов, способных не только предсказывать результаты, но и предоставлять понятные объяснения, какие факторы оказали наибольшее влияние на конкретное решение. Такой подход особенно важен в областях, где требуется высокая степень доверия и ответственности, например, в медицине, финансах или юриспруденции, где понимание причинно-следственных связей критически важно.
Структурная Сеть CFN: Функциональный Композиционный Подход
Структурная сеть StructuralCFN отличается от традиционных сетей, основанных на скалярном произведении (dot-product), использованием функциональной композиции для построения интерпретируемых моделей. В отличие от традиционных подходов, где связи между нейронами определяются весами, StructuralCFN строит сложные функции путем последовательного применения базовых функций к входным данным. Это позволяет не только аппроксимировать произвольные непрерывные функции, но и предоставляет возможность анализировать вклад каждой базовой функции в конечное предсказание, что значительно повышает интерпретируемость модели. Вместо оптимизации весов, StructuralCFN фокусируется на выборе и композиции подходящих функций для конкретной задачи, обеспечивая более прозрачный и понятный процесс моделирования.
В основе StructuralCFN лежит Композиционная Функциональная Сеть (CFN), использующая базисные функции для представления сложных взаимосвязей. Эти базисные функции включают в себя, например, полиномиальные и периодические узлы. Полиномиальные узлы, представляющие собой полиномы различных степеней, позволяют моделировать нелинейные зависимости, в то время как периодические узлы, основанные на тригонометрических функциях sin(x) и cos(x), эффективно моделируют циклические или повторяющиеся закономерности. Комбинируя эти и другие типы базисных функций посредством композиции, CFN способна аппроксимировать широкий спектр сложных функций и зависимостей, обеспечивая гибкость и выразительность модели.
Структурный подход StructuralCFN, основанный на функциональной композиции, обеспечивает аппроксимацию любой непрерывной функции. Это достигается путем последовательного комбинирования базисных функций, таких как полиномиальные и периодические узлы, позволяя модели представлять сложные зависимости. Теоретически, используя достаточное количество и комбинацию этих функций, можно достичь произвольной точности аппроксимации для любой непрерывной функции f(x) в заданном диапазоне, что делает StructuralCFN гибким и выразительным фреймворком для моделирования данных.
Раскрытие Структуры: Слои Зависимостей и Априорные Предположения
СтруктурныйCFN использует слой зависимостей (Dependency Layer) для обучения структурному априорному распределению — предположению о том, что значение каждой характеристики контекстуально определяется значениями её соседей. Этот подход позволяет модели учитывать взаимосвязи между признаками непосредственно из данных, а не полагаться на заранее заданные правила или экспертные знания. Обучение происходит путем анализа корреляций и зависимостей между признаками в обучающем наборе данных, что позволяет выявить и использовать структурные закономерности, присутствующие в данных. Такой подход особенно эффективен в задачах, где пространственная или контекстуальная информация играет важную роль в определении значений признаков.
Структурный априорный параметр в StructuralCFN реализуется посредством контекстно-зависимого механизма (Context-Gated Structural Prior), который позволяет модели динамически определять силу взаимосвязей между признаками. Вместо использования фиксированных весов для определения влияния соседних признаков, данный механизм применяет контекстно-зависимые вентили, определяемые входными данными. Это позволяет модели адаптировать степень влияния каждого признака на основе текущего контекста, обеспечивая более гибкое и точное моделирование взаимосвязей между признаками и повышая общую производительность модели. В результате, сила зависимостей между признаками не является статичной, а определяется в процессе обучения на основе данных.
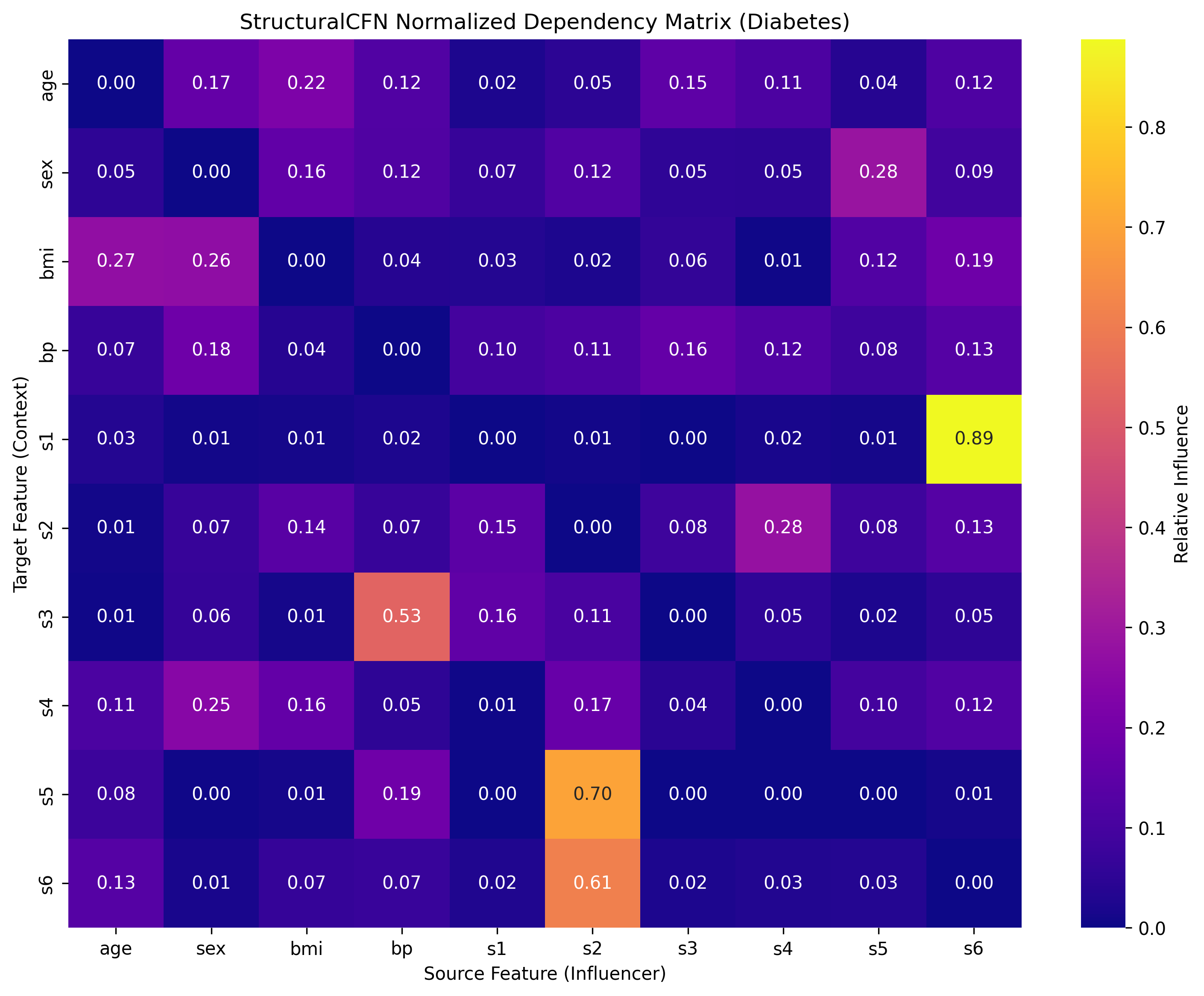
Изученные зависимости представлены в виде Матрицы Зависимостей, обеспечивающей наглядную визуализацию взаимосвязей между признаками. Эта матрица позволяет проводить целенаправленный анализ, выявляя, какие признаки оказывают наибольшее влияние друг на друга, и оценивать степень их взаимосвязи. Каждый элемент матрицы отражает силу зависимости между соответствующими признаками, что позволяет количественно оценить структурные связи в данных и использовать эту информацию для улучшения производительности модели и интерпретации результатов. Матрица Зависимостей служит инструментом для выявления ключевых признаков и понимания структуры данных.
Открытие Многообразий и Достижение Разреженности
Архитектура использует дифференцируемый адаптивный вентиль (Differentiable Adaptive Gate) для автоматического определения оптимальных характеристик многообразия, лежащих в основе данных, что позволяет повысить точность моделирования. Этот вентиль динамически адаптируется к входным данным, выявляя нелинейные зависимости и позволяя модели эффективно представлять сложные взаимосвязи. В отличие от статических методов, требующих предварительного определения характеристик многообразия, адаптивный вентиль обучается непосредственно из данных, минимизируя необходимость ручной настройки и повышая обобщающую способность модели. Данный подход особенно эффективен при работе с данными высокой размерности, где явное определение характеристик многообразия затруднительно.
В архитектуре модели применена L1-регуляризация, представляющая собой добавление к функции потерь суммы абсолютных значений весов параметров. Это приводит к тому, что некоторые веса стремятся к нулю, тем самым создавая разреженную модель. Разреженность способствует улучшению обобщающей способности модели, предотвращая переобучение на тренировочных данных, и повышает интерпретируемость, поскольку уменьшает количество значимых параметров, влияющих на результат. Математически, L1-регуляризация добавляет член λ \sum_{i=1}^{p} |w_i| к функции потерь, где λ — коэффициент регуляризации, а w_i — i-ый вес параметра.
В агрегационном слое используется гибридный функциональный комитет, который эффективно объединяет линейные и нелинейные функциональные головы для повышения устойчивости прогнозов. Данная архитектура позволяет модели использовать преимущества как линейной аппроксимации — обеспечивающей скорость и простоту — так и нелинейной аппроксимации, способной моделировать более сложные зависимости в данных. Комбинирование этих подходов достигается за счет параллельной обработки входных данных обеими функциональными головами, выходные сигналы которых затем объединяются с использованием взвешенной суммы или другого механизма агрегации. Это позволяет модели адаптироваться к различным типам данных и повышает её способность к обобщению, что приводит к более надежным и точным прогнозам.
К Объяснимым и Надежным Системам Искусственного Интеллекта
Структурная сеть CFN представляет собой значительный прогресс в области интерпретируемого искусственного интеллекта, предоставляя возможность пользователям понять логику, лежащую в основе каждого прогноза модели. В отличие от многих современных систем, функционирующих как «черные ящики», CFN позволяет отследить, какие именно факторы и их взаимосвязи привели к конкретному результату. Это достигается благодаря уникальной архитектуре, моделирующей структурные зависимости между признаками, делая процесс принятия решений прозрачным и понятным. Возможность интерпретации не только повышает доверие к модели, но и позволяет выявлять потенциальные ошибки или предвзятости, что особенно важно в критически важных областях, таких как медицина или финансы. Таким образом, StructuralCFN открывает новые горизонты в создании искусственного интеллекта, который не просто предсказывает, но и объясняет свои решения.
В отличие от современных моделей искусственного интеллекта, требующих миллионы параметров для достижения высокой производительности, StructuralCFN демонстрирует сопоставимые результаты, используя лишь приблизительно 300 параметров. Такая компактность достигается благодаря архитектуре, ориентированной на моделирование структурных зависимостей в данных, что позволяет эффективно извлекать ключевую информацию, не прибегая к избыточному количеству связей. Этот подход не только снижает вычислительные затраты и требования к памяти, но и способствует повышению обобщающей способности модели, делая её более устойчивой к переобучению и способной к эффективной работе с ограниченным объемом данных. В результате, StructuralCFN представляет собой перспективное решение для задач, где важны как высокая производительность, так и экономичность и интерпретируемость.
В ходе тестирования на наборе данных о диабете, разработанная модель StructuralCFN продемонстрировала превосходство над алгоритмом LightGBM. Достигнутый показатель производительности составил 0.488, в то время как LightGBM показал результат 0.520. Статистический анализ подтвердил значимость этого различия (p < 0.05), указывая на то, что улучшение производительности не является случайным. Это свидетельствует о способности StructuralCFN более эффективно выявлять и использовать ключевые факторы риска диабета в данных, что потенциально может привести к более точной диагностике и прогнозированию.
В ходе сравнительного анализа на наборах данных о раке молочной железы и сердечно-сосудистых заболеваниях, разработанная модель StructuralCFN продемонстрировала превосходство над алгоритмом LightGBM. На наборе данных о раке молочной железы StructuralCFN достиг показателя в 0.062, в то время как LightGBM — более высокого значения. Аналогично, при анализе данных о сердечно-сосудистых заболеваниях, StructuralCFN показал результат 0.440, превзойдя LightGBM. Статистическая значимость этих различий подтверждена p-уровнем, который оказался меньше 0.05, что указывает на надежность полученных результатов и потенциальную применимость StructuralCFN в задачах медицинской диагностики и прогнозирования.
В ходе экспериментов с синтетическими данными, разработанная архитектура StructuralCFN продемонстрировала исключительную способность к восстановлению исходных математических зависимостей. В двадцати независимых испытаниях, модель безошибочно определяла f(x), лежащую в основе сгенерированных данных, что свидетельствует о её высокой точности и способности к логическому выводу. Этот результат подтверждает, что StructuralCFN не просто запоминает данные, но и действительно понимает скрытые закономерности, что является ключевым шагом к созданию по-настоящему объяснимого искусственного интеллекта и надежных систем, способных к обобщению знаний.
Архитектура StructuralCFN демонстрирует выдающуюся способность моделировать структурные зависимости в данных, что делает её особенно ценной в приложениях, где понимание взаимосвязей между признаками имеет решающее значение. В отличие от многих современных моделей, фокусирующихся исключительно на предсказательной точности, StructuralCFN позволяет выявлять и анализировать, как различные признаки взаимодействуют друг с другом для формирования конечного результата. Это свойство открывает возможности для глубокого понимания механизмов, лежащих в основе данных, например, в медицинских диагностических системах, где важно понимать, какие факторы риска совместно влияют на вероятность заболевания, или в финансовых моделях, где необходимо учитывать сложные взаимодействия между экономическими показателями. Способность StructuralCFN выявлять эти скрытые связи значительно повышает доверие к модели и позволяет использовать её результаты для принятия обоснованных решений.
Разработка StructuralCFN представляет собой значительный шаг к созданию искусственного интеллекта, который не только демонстрирует высокую производительность, но и обеспечивает прозрачность своих решений. В отличие от многих современных моделей, требующих миллионов параметров, StructuralCFN достигает сопоставимых результатов, используя лишь около 300 параметров, что делает его более эффективным и доступным для анализа. Данная архитектура способна выявлять и моделировать структурные зависимости между признаками, что особенно важно в задачах, где понимание взаимодействия факторов критически необходимо. Результаты, полученные на различных наборах данных, включая Diabetes, Breast Cancer и Heart Disease, демонстрируют превосходство StructuralCFN над алгоритмом LightGBM, а успешное восстановление математических зависимостей в синтетических данных подтверждает его способность к осмысленному анализу. Таким образом, StructuralCFN открывает новые возможности для создания надежных, понятных и заслуживающих доверия систем искусственного интеллекта, способных обосновать свои прогнозы и обеспечить более эффективное взаимодействие с человеком.
Исследование, представленное в статье, акцентирует внимание на построении интерпретируемых моделей для табличных данных, используя концепцию структурных композиционных функциональных сетей. Этот подход направлен на явное моделирование математических связей между признаками, что позволяет не только повысить точность прогнозов, но и обеспечить прозрачность работы алгоритма. Как отмечал Марвин Минский: «Наиболее важные возможности компьютера — это те, которые мы еще не открыли». Данная работа как раз и демонстрирует потенциал для раскрытия новых возможностей в области машинного обучения, предлагая архитектуру, которая стремится к элегантности и понятности, а не к слепому увеличению сложности.
Что впереди?
Представленная архитектура, как и любая другая, обречена на старение. Внедрение структурного априори и обучение явным функциональным связям — лишь одна из попыток замедлить этот процесс, но не остановить его. Эффективность StructuralCFN в работе с табличными данными, несомненно, заслуживает внимания, однако истинный вызов заключается не в достижении максимальной точности на текущих наборах данных, а в адаптации к неизбежно меняющемуся ландшафту информации. Каждая архитектура проживает свою жизнь, а мы лишь свидетели.
Очевидным направлением развития является расширение возможностей StructuralCFN для работы с данными, имеющими более сложные зависимости и скрытые взаимосвязи. Текущая версия, вероятно, ограничена в своей способности к обобщению на данные, значительно отличающиеся от тех, на которых она обучалась. Необходимо исследовать способы интеграции с другими подходами, такими как символьная регрессия и дифференцируемое программирование, чтобы создать более гибкую и адаптивную систему. Улучшения стареют быстрее, чем мы успеваем их понять.
В конечном итоге, вопрос заключается не в создании идеальной модели, а в понимании границ применимости каждой из них. Все системы стареют — вопрос лишь в том, делают ли они это достойно. Исследование устойчивости и надежности StructuralCFN в долгосрочной перспективе представляется не менее важным, чем повышение ее точности на краткосрочных задачах.
Оригинал статьи: https://arxiv.org/pdf/2601.20037.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-29 18:03