Автор: Денис Аветисян
Новое исследование показывает, что небольшие языковые модели способны эффективно обрабатывать медицинский текст на итальянском языке, демонстрируя конкурентоспособные результаты.
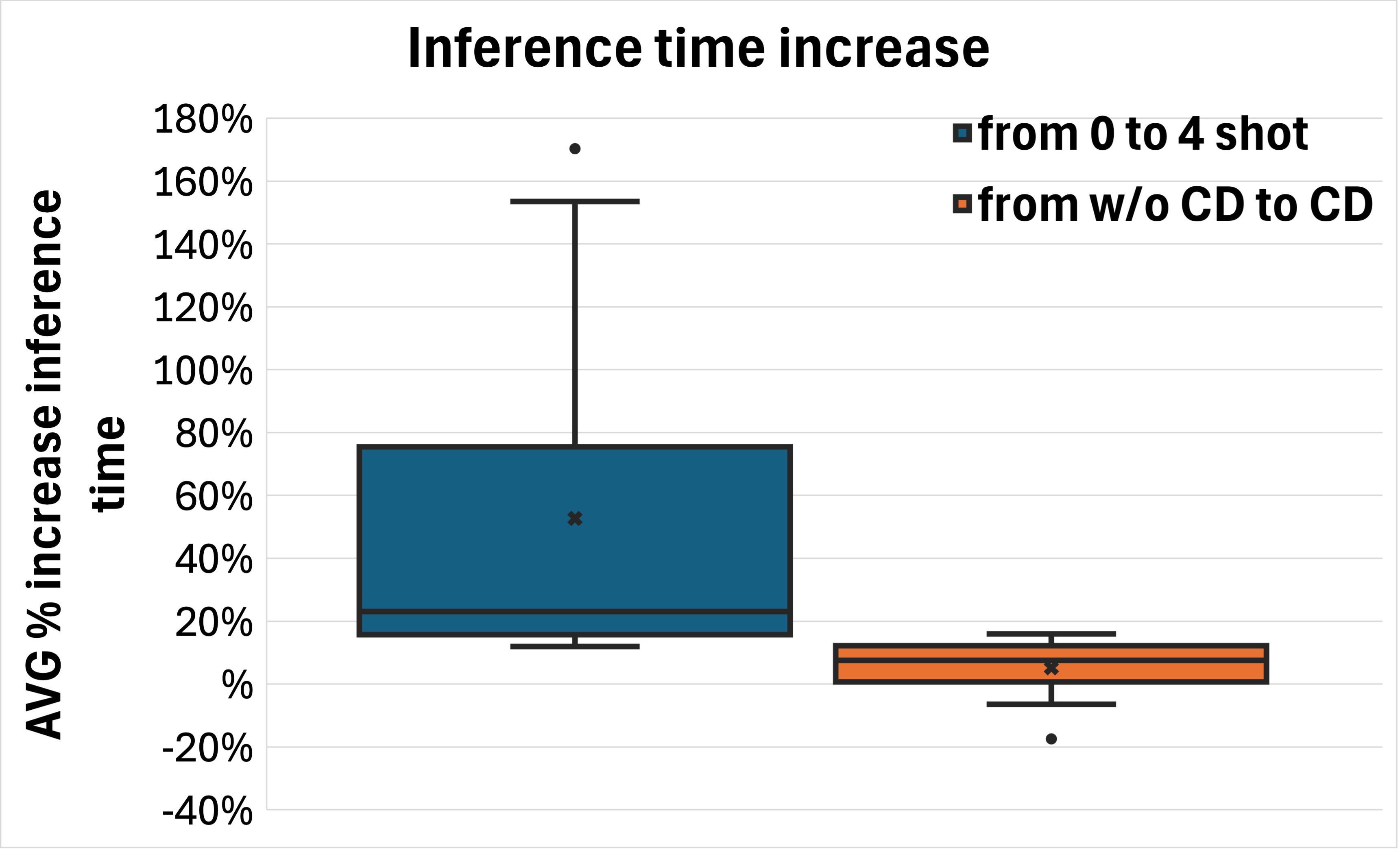
![В ходе исследования производительности больших языковых моделей <span class="katex-eq" data-katex-display="false">1B</span> в четырнадцати медицинских задачах установлено, что наиболее эффективным подходом является дообучение [FT], последовательно превосходящее базовую модель [Qwen3-32B] с использованием контекстного обучения [4-shot], в то время как непрерывное предварительное обучение [CPT] демонстрирует положительное влияние лишь в единичном случае [gemma-3-1b-it], а контекстное обучение [4-shot] стабильно превосходит декодирование с ограничениями [CD], причём их комбинирование даёт дополнительный выигрыш.](https://arxiv.org/html/2602.17475v1/training_methods.png)
Систематический анализ методов обучения с малым количеством данных, ограничением декодирования, тонкой настройкой и непрерывным предварительным обучением для компактных моделей обработки медицинского текста на итальянском языке.
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в обработке медицинского текста, их применение в реальных клинических условиях часто затруднено из-за высоких вычислительных требований. В работе ‘Small LLMs for Medical NLP: a Systematic Analysis of Few-Shot, Constraint Decoding, Fine-Tuning and Continual Pre-Training in Italian’ проведено систематическое исследование эффективности компактных LLM (около одного миллиарда параметров) для решения задач медицинской обработки естественного языка на итальянском языке. Полученные результаты демонстрируют, что такие модели, обученные с использованием методов тонкой настройки и декодирования с ограничениями, могут достигать сопоставимой, а в некоторых случаях и превосходящей, точности по сравнению с более крупными аналогами. Возможно ли, таким образом, создание экономически эффективных и доступных инструментов для автоматизации медицинских задач на базе компактных LLM?
Время и Эффективность: Вызовы Клинического Рассуждения в Эпоху Больших Языковых Моделей
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) обрабатывать клинический текст, их колоссальный размер создает существенные трудности при внедрении и применении. Огромное количество параметров, необходимое для достижения высокой точности, требует значительных вычислительных ресурсов и памяти, что ограничивает возможность развертывания БЯМ на стандартном медицинском оборудовании или в условиях ограниченной пропускной способности сети. Более того, масштабность моделей замедляет процесс логического вывода и анализа, что критически важно для оперативного принятия решений в клинической практике. Таким образом, эффективное использование БЯМ в здравоохранении требует разработки инновационных методов оптимизации и сжатия моделей без существенной потери качества обработки информации.
Традиционные методы обработки клинических данных, несмотря на свою эффективность, часто сталкиваются с проблемой баланса между точностью анализа и вычислительными затратами. Сложные задачи клинического мышления, требующие глубокого понимания контекста и анализа множества факторов, предъявляют высокие требования к ресурсам. В результате, применение стандартных алгоритмов может быть затруднено из-за значительного времени обработки и необходимости в мощном оборудовании. Это особенно критично в реальных клинических условиях, где требуется оперативное принятие решений. Поиск компромисса между производительностью и стоимостью вычислений остается ключевой задачей для успешного внедрения интеллектуальных систем в здравоохранение.
Малые Модели, Большой Потенциал: Путь к Эффективной Медицинской NLP
Малые языковые модели (SLM), содержащие приблизительно один миллиард параметров, представляют собой привлекательную альтернативу большим языковым моделям (LLM) для специализированных задач обработки естественного языка в медицине. В отличие от LLM, требующих значительных вычислительных ресурсов и больших объемов данных, SLM демонстрируют сравнимую производительность в узкоспециализированных областях, таких как извлечение информации из клинических записей или классификация медицинских текстов. Снижение количества параметров приводит к уменьшению требований к памяти и вычислительной мощности, что делает SLM более доступными для внедрения в клиническую практику и исследования, особенно в условиях ограниченных ресурсов. Это позволяет проводить обработку и анализ медицинских данных непосредственно на локальных серверах или даже на персональных компьютерах, обеспечивая конфиденциальность и безопасность данных.
Для обеспечения точного понимания клинических текстов малые языковые модели (SLM) требуют специализированных знаний, которые эффективно приобретаются посредством методов дообучения и непрерывного предварительного обучения. Дообучение, или fine-tuning, позволяет адаптировать SLM к конкретным задачам и типам данных, используя размеченные наборы данных медицинской тематики. Непрерывное предварительное обучение, в свою очередь, предполагает дальнейшее обучение модели на неразмеченных клинических текстах, что позволяет ей расширить свой словарный запас и улучшить понимание нюансов медицинской терминологии и контекста. Комбинирование этих подходов позволяет значительно повысить производительность SLM в задачах обработки естественного языка в медицинской сфере, приближая её к результатам, достижимым с использованием более крупных языковых моделей.
Методы параметро-эффективной тонкой настройки, такие как LoRA (Low-Rank Adaptation), значительно повышают практичность использования малых языковых моделей (SLM) в задачах медицинской обработки естественного языка. LoRA позволяет адаптировать предварительно обученную модель к конкретной клинической задаче, изменяя лишь небольшое количество параметров, что существенно снижает вычислительные затраты и потребление памяти по сравнению с полной тонкой настройкой. Вместо обновления всех параметров модели, LoRA вводит низкоранговые матрицы, которые обучаются параллельно с исходными весами, что позволяет добиться сопоставимой производительности при значительно меньших требованиях к ресурсам. Это делает SLM, адаптированные с помощью LoRA, особенно привлекательными для развертывания в условиях ограниченных вычислительных мощностей или при необходимости быстрой адаптации к новым данным.
Проверка на Прочность: Оценка Малых Моделей в Клинических Задачах
В ходе исследования были оценены малые языковые модели (SLM), включая Qwen-3-1.7B, Llama-3.2-1B и Gemma-3-1B, на предмет их эффективности в решении задач, связанных с обработкой клинических текстов. Оценка проводилась по задачам извлечения именованных сущностей (Named Entity Recognition), извлечения отношений (Relation Extraction) и анализа аргументации (Argument Mining). Данные задачи были выбраны для определения способности моделей к пониманию и структурированию медицинской информации, необходимой для дальнейших клинических приложений.
В ходе исследования было установлено, что небольшие языковые модели (SLM), при надлежащей подготовке, демонстрируют конкурентоспособные результаты в задачах заполнения форм отчетов о клинических случаях, ответов на медицинские вопросы и других критически важных приложениях. В частности, модель Qwen3-1.7B превзошла более крупную модель Qwen3-32B на 9.2 пункта в задачах обработки естественного языка (NLP) для итальянского языка, что указывает на потенциал оптимизации размеров моделей для достижения высокой производительности в специфических медицинских областях.
В ходе исследований было установлено, что применение метода Sequence Packing, поддерживаемого технологией Flash Attention 2, значительно повысило эффективность процесса непрерывного предварительного обучения, особенно при работе с итальянскими корпусами текстов медицинской тематики. Последующая контролируемая тонкая настройка (Supervised Fine-tuning) демонстрировала стабильно наилучшие результаты по всем моделям и задачам, приводя к улучшению показателей F1 для обобщенных данных (out-of-distribution) на +11.9% для Llama-3.2-1B, +6.1% для Qwen3 и +3.9% для Gemma-3. Это указывает на важность контролируемой тонкой настройки для достижения высокой производительности моделей в клинических задачах.
Перспективы и Влияние: Малые Модели в Экосистеме Здравоохранения
Полученные результаты демонстрируют, что малые языковые модели (SLM) обладают значительным потенциалом для внедрения решений в области обработки естественного языка (NLP) в медицинских учреждениях с ограниченными ресурсами. В отличие от крупных моделей, требующих значительных вычислительных мощностей и энергии, SLM могут эффективно работать на менее производительном оборудовании, что делает их доступными для клиник и больниц, особенно в регионах с ограниченной инфраструктурой. Это открывает возможности для автоматизации рутинных задач, таких как извлечение информации из медицинских записей, поддержка принятия клинических решений и улучшение качества обслуживания пациентов, даже в условиях ограниченного бюджета и технических возможностей. Таким образом, SLM представляют собой перспективный инструмент для расширения доступа к передовым технологиям NLP в здравоохранении, делая качественную медицинскую помощь более доступной и эффективной.
Метод декодирования с ограничениями значительно повышает надежность результатов, полученных с помощью небольших языковых моделей (SLM) при анализе клинических текстов. Внедрение ограничений, основанных на структуре и содержании медицинских данных, позволяет модели избегать нелогичных или нерелевантных извлечений информации. Это особенно важно при работе с неструктурированными данными, такими как истории болезни, где точность извлечения ключевых фактов, например, диагнозов, лекарств или симптомов, имеет решающее значение. Благодаря такому подходу, SLM способны предоставлять более структурированные и достоверные данные, что открывает возможности для автоматизации клинических задач и поддержки принятия решений врачами.
Перспективные исследования направлены на интеграцию небольших языковых моделей (SLM) с внешними базами знаний, что позволит значительно расширить их возможности в области клинических рассуждений и поддержки принятия решений. Подобный симбиоз позволит SLM не только извлекать информацию из клинических текстов, но и сопоставлять её с актуальными медицинскими руководствами, фармакологическими данными и результатами исследований, обеспечивая более точную и обоснованную интерпретацию. Особенно важным представляется использование структурированных баз знаний, таких как онтологии и графы знаний, для представления медицинских концепций и связей между ними, что позволит SLM осуществлять сложные логические выводы и предлагать персонализированные рекомендации, повышая качество и эффективность медицинской помощи. Дальнейшие разработки в этой области могут привести к созданию интеллектуальных систем, способных оказывать поддержку врачам в решении сложных диагностических и терапевтических задач.
Исследование демонстрирует, что даже относительно небольшие языковые модели, при правильной адаптации, способны достигать впечатляющих результатов в специализированных областях, таких как медицинская обработка естественного языка на итальянском языке. Этот процесс напоминает мудрое старение системы — не в борьбе с неизбежным, а в изящном приспособлении к изменяющимся условиям. Как заметил Карл Фридрих Гаусс: «Я не знаю, как мир устроен, но мне кажется, что он устроен весьма элегантно». Элегантность проявляется и здесь — в способности небольших моделей эффективно использовать ресурсы и превосходить более крупные аналоги благодаря методам тонкой настройки и декодирования с ограничениями. Подобно тому, как система учится дышать вместе с энтропией, эти модели учатся извлекать максимум пользы из ограниченных данных и вычислительных мощностей.
Что дальше?
Представленная работа демонстрирует, что даже относительно скромные языковые модели, порядка миллиарда параметров, способны на конкурентоспособные результаты в области медицинской обработки естественного языка на итальянском языке. Каждый коммит в эволюции этих моделей — это запись в летописи, а каждая версия — глава, повествующая о новых возможностях. Однако, стоит признать, что достижение этой конкурентоспособности требует значительных усилий по адаптации — тонкой настройке, предварительному обучению, использованию ограничений декодирования. Эта «плата за амбиции» напоминает о том, что универсальных решений не существует, и каждая задача требует индивидуального подхода.
Очевидным направлением для дальнейших исследований является расширение спектра решаемых задач и языков. Переход от специализированных задач к более общим, требующим более глубокого понимания контекста и здравого смысла, представляется неизбежным. Задержка в решении этих задач — это налог на амбиции, но и стимул для поиска новых, более эффективных методов. Особый интерес представляет изучение методов, позволяющих моделям не просто «запоминать» информацию, но и «понимать» её.
В конечном счёте, все системы стареют — вопрос лишь в том, делают ли они это достойно. Время — не метрика, а среда, в которой существуют эти системы. Задача исследователей — не просто создавать всё более мощные модели, но и обеспечивать их долговечность и адаптивность к меняющимся условиям. И, возможно, самое главное — помнить, что даже самые совершенные инструменты — лишь средства для достижения более высоких целей.
Оригинал статьи: https://arxiv.org/pdf/2602.17475.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Квантовый скачок: от лаборатории к рынку
- Квантовый шум: за пределами стандартных моделей
- Виртуальная примерка без границ: EVTAR учится у образов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
2026-02-22 05:49