Автор: Денис Аветисян
Новая система, основанная на искусственном интеллекте, позволяет находить экспертов и рекомендовать совместные исследования внутри медицинских учреждений.
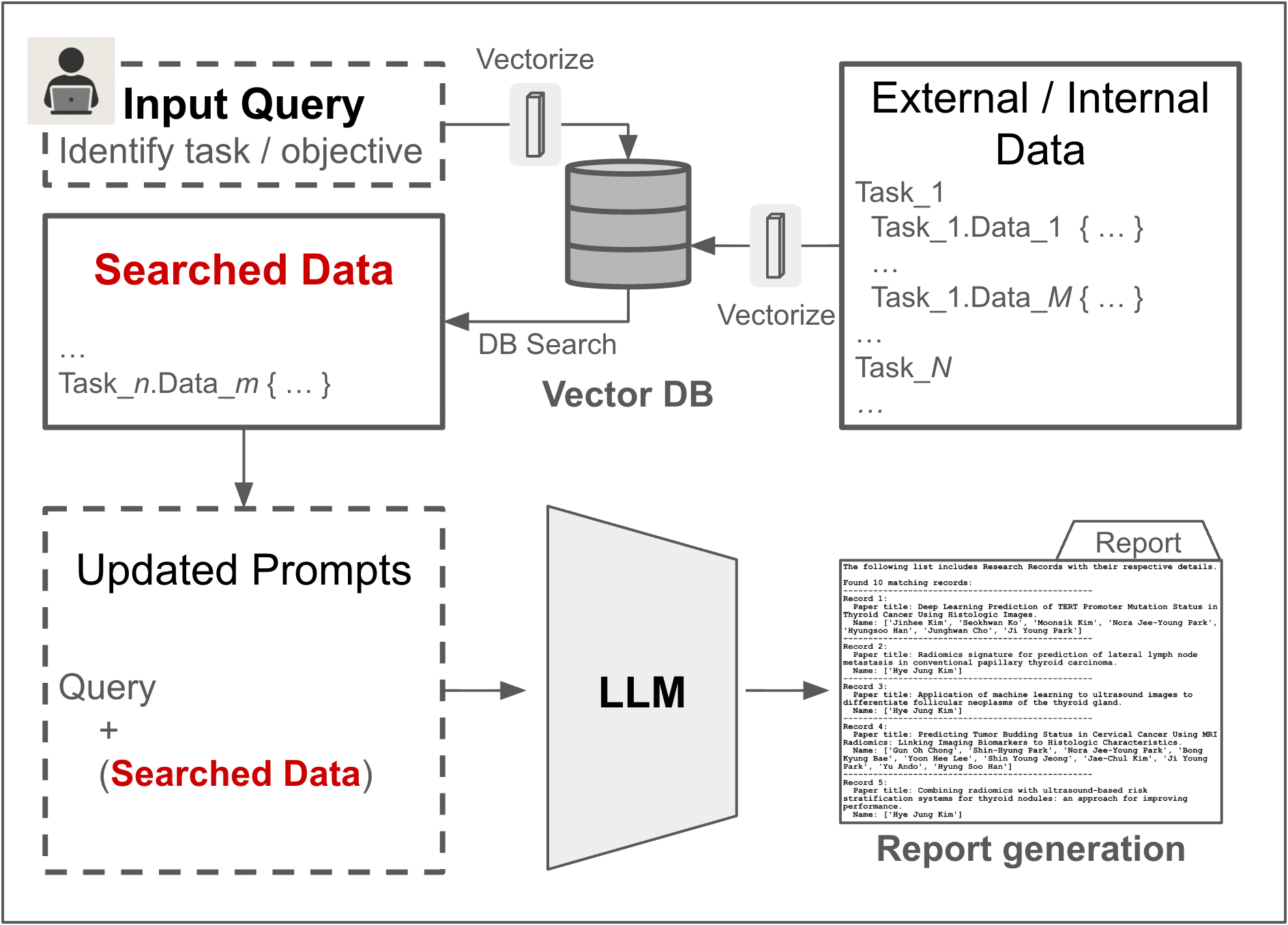
В статье описывается локально развертываемая система RAG, использующая PubMedBERT и LLaMA3.2 для рекомендаций по сотрудничеству в области медицинских исследований, обеспечивающая строгую конфиденциальность и безопасность данных.
Несмотря на растущий потенциал больших языковых моделей (LLM) в медицине, строгие требования к конфиденциальности и безопасности данных ограничивают их применение в клинической практике. В статье ‘Leveraging Language Models and RAG for Efficient Knowledge Discovery in Clinical Environments’ представлен локально развернутый подход, использующий архитектуру Retrieval-Augmented Generation (RAG) для рекомендации потенциальных научных коллег. Система, основанная на моделях PubMedBERT и LLaMA3, демонстрирует возможность эффективного поиска и синтеза биомедицинской информации в условиях ограниченной инфраструктуры. Может ли подобный подход стать основой для создания персонализированных систем поддержки принятия решений в здравоохранении, соблюдая при этом все необходимые нормативные требования?
Поиск Знаний: Преодолевая Ограничения Ключевых Слов
Для поступательного развития науки выявление потенциальных соавторов играет первостепенную роль, однако существующие подходы зачастую ограничиваются простым поиском по ключевым словам. Такой метод, хотя и широко распространен, не позволяет в полной мере отразить смысловую нагрузку научных работ и специфику исследовательских интересов. Ученые нередко сталкиваются с ситуацией, когда релевантные эксперты остаются незамеченными из-за несоответствия ключевых слов в публикациях или из-за сложности и многогранности тематики исследований. Это приводит к упущенным возможностям для сотрудничества, дублированию усилий и замедлению темпов научного прогресса, подчеркивая необходимость разработки более эффективных инструментов для поиска и установления контактов между исследователями.
Традиционные методы поиска научных коллабораторов, основанные на ключевых словах, зачастую оказываются неэффективными из-за неспособности уловить смысловые оттенки и контекст научных исследований. Простое сопоставление терминов игнорирует сложные взаимосвязи между концепциями, что приводит к упущению потенциально ценных специалистов и возможностей для сотрудничества. В результате, исследователям приходится тратить значительное время на поиск релевантной экспертизы, а ценные идеи могут остаться нереализованными из-за сложностей в обнаружении подходящих партнеров. Эта проблема особенно актуальна в междисциплинарных областях, где ключевые слова могут быть неоднозначными или не отражать истинную направленность работы.
Для эффективного выявления релевантной экспертизы необходима система, способная к глубокому анализу содержания научных публикаций и исследовательских интересов ученых. Простого сопоставления ключевых слов недостаточно, поскольку оно не учитывает контекст и семантические связи между различными областями знаний. Разработанные алгоритмы должны выходить за рамки формального поиска, применяя методы обработки естественного языка и машинного обучения для извлечения скрытых связей между работами, определения тематической близости и выявления неявных компетенций. Такой подход позволит не только находить специалистов, работающих непосредственно в интересующей области, но и обнаруживать экспертов, обладающих смежными знаниями и способных внести ценный вклад в решение сложных научных задач. Это способствует формированию новых междисциплинарных коллабораций и ускоряет темпы научных открытий.

RAG: Семантическая Основа для Коллаборации
В основе системы лежит архитектура RAG (Retrieval-Augmented Generation), объединяющая возможности информационного поиска и генеративного моделирования языка. Данный подход позволяет преодолеть ограничения, присущие исключительно генеративным моделям, такие как склонность к галлюцинациям и неспособность оперировать информацией, отсутствующей в процессе обучения. В RAG сначала выполняется поиск релевантных документов из внешних источников, а затем эти документы используются в качестве контекста для генеративной модели, что обеспечивает более точные, обоснованные и контекстуально соответствующие ответы. Это позволяет системе не только генерировать текст, но и подкреплять его фактической информацией, извлеченной из надежных источников.
В основе системы лежит семантический поиск, который определяет релевантные публикации, анализируя смысл запроса пользователя, а не просто сопоставляя ключевые слова. Этот подход использует векторное представление запроса и документов, вычисляя степень семантической близости между ними. В отличие от традиционного поиска по ключевым словам, семантический поиск позволяет находить публикации, которые концептуально связаны с запросом, даже если в них не используются те же самые слова. Это достигается за счет использования моделей машинного обучения, обученных на больших объемах текстовых данных, для понимания и представления семантики текста.
В основе системы поиска релевантной информации лежит использование двух ключевых источников данных: базы биомедицинской литературы PubMed и структурированной Институциональной Базы Знаний. PubMed предоставляет доступ к обширному объему опубликованных научных статей, обеспечивая широкий контекст для ответов на запросы. Институциональная База Знаний, в свою очередь, содержит курированные данные, специфичные для организации, позволяющие формировать целевые рекомендации и учитывать внутреннюю экспертизу. Комбинация этих двух источников обеспечивает как полноту, так и точность предоставляемой информации.
В архитектуре системы используется модель LLaMA3.2 с 3 миллиардами параметров для генеративных задач. Выбор данной модели обусловлен ее относительной легковесностью, что позволяет эффективно выполнять генерацию текста при ограниченных вычислительных ресурсах. Несмотря на меньший размер по сравнению с более крупными языковыми моделями, LLaMA3.2 демонстрирует достаточную производительность для поставленных задач, обеспечивая баланс между скоростью обработки и качеством генерируемого контента. Это позволяет масштабировать систему и обеспечивать быстрый отклик на запросы пользователей.

Биомедицинские Векторные Представления: Механика Семантического Поиска
Для генерации биомедицинских семантических представлений (embeddings) используются модели семейства PubMedBERT, представляющие собой энкодеры, предварительно обученные на большом корпусе текстов из базы данных PubMed. PubMedBERT, в отличие от общих языковых моделей, специализируется на понимании научной терминологии и контекста биомедицинских исследований. В процессе обработки, абстракты статей из PubMed преобразуются в векторы фиксированной размерности, отражающие семантическое содержание текста. Эти векторные представления позволяют количественно оценивать сходство между различными статьями, основываясь на их содержании, а не только на совпадении ключевых слов.
Векторные представления, полученные на основе PubMedBERT, кодируют семантическое значение научных статей, что позволяет проводить осмысленное сравнение их содержания. В отличие от простого сопоставления ключевых слов, эти представления учитывают контекст и взаимосвязи между терминами, обеспечивая более точную оценку релевантности. Это достигается путем преобразования текста в многомерные векторы, где близость векторов отражает семантическую схожесть соответствующих статей. Такой подход позволяет выявлять публикации, которые концептуально связаны, даже если они не используют одинаковые термины, что существенно повышает эффективность поиска и извлечения релевантной информации.
Для количественной оценки релевантности извлеченных документов к запросу пользователя используется метрика косинусного сходства. В процессе тестирования, при поиске идентичных публикаций, достигнут показатель в 0.9964137. Косинусное сходство вычисляется как косинус угла между векторами, представляющими запросы и документы в многомерном семантическом пространстве, где \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|}. Более высокие значения косинусного сходства указывают на более тесную семантическую связь между запросом и документом, обеспечивая точный отбор релевантной информации.
Надежный процесс поиска релевантных документов является основой для последующего этапа генерации. Он обеспечивает подачу языковой модели контекста, необходимого для формирования осмысленного ответа. Полученные в результате поиска публикации, отобранные на основе семантической близости, служат входными данными для генеративной модели, определяя её способность производить точные и актуальные результаты. Эффективность данного процесса поиска напрямую влияет на качество генерируемого текста, гарантируя, что модель оперирует проверенной и релевантной информацией, а не случайными данными.
Генерация Рекомендаций: Формирование Запроса для Языковой Модели
Формирование запроса представляет собой ключевой этап в процессе генерации рекомендаций, объединяющий ввод пользователя с извлеченными релевантными документами для обеспечения языковой модели необходимым контекстом. Этот подход позволяет не просто сопоставлять ключевые слова, а создавать полноценную информационную основу, в которой модель может анализировать запросы в свете фактических исследований и экспертных знаний. Эффективное конструирование запроса гарантирует, что языковая модель получит не только суть вопроса, но и достаточный объем данных для формирования обоснованных и содержательных рекомендаций по поиску потенциальных соавторов, что значительно повышает качество и точность результатов.
Предоставление релевантного контекста играет ключевую роль в формировании обоснованных и содержательных рекомендаций по сотрудничеству с использованием языковой модели LLaMA3.2. Система, обогащенная информацией из извлеченных документов, способна не просто сопоставлять ключевые слова, но и анализировать исследовательские интересы и экспертные знания, что позволяет выявлять потенциальных коллег на основе более глубокого понимания их деятельности. Этот подход позволяет LLaMA3.2 генерировать предложения, выходящие за рамки поверхностного поиска, и предлагать действительно полезные и значимые связи для совместной работы, значительно повышая эффективность поиска партнеров в научной среде.
Система продемонстрировала впечатляющую способность к точному поиску релевантных документов, что подтверждается высокими значениями косинусной близости. Анализ результатов показал, что четыре наиболее релевантных документа имеют показатели сходства 0.9859726, 0.9858602, 0.9848883 и 0.9842814 соответственно. Такие высокие значения указывают на то, что алгоритм эффективно выявляет документы, содержащие информацию, тесно связанную с запросом, и способен различать нюансы в содержании, а не просто полагаться на совпадение ключевых слов. Это позволяет системе предлагать потенциальных коллабораторов на основе глубокого понимания их исследовательских интересов и экспертизы.
В отличие от традиционных методов поиска, основанных на простом сопоставлении ключевых слов, представленный подход позволяет выявлять потенциальных соавторов, учитывая глубинные связи между их научными интересами и областью экспертизы. Система анализирует содержание научных работ, а не только отдельные термины, что позволяет обнаруживать исследователей, чья деятельность косвенно связана с запросом, но может быть весьма ценной для сотрудничества. Такой анализ выходит за рамки поверхностного сравнения и позволяет учитывать нюансы научных исследований, что значительно повышает релевантность предлагаемых кандидатур и способствует формированию продуктивных исследовательских связей.
Исследование демонстрирует стремление к упрощению доступа к специализированным знаниям в медицинской сфере. Авторы предлагают систему, основанную на принципах поиска и генерации, что позволяет эффективно извлекать релевантную информацию из больших объемов данных. Как однажды заметил Джон Маккарти: «Наилучний способ найти хорошую идею — генерировать много идей». Данный подход перекликается с представленной работой, поскольку система RAG, использующая PubMedBERT и LLaMA3.2, направлена на генерацию полезных рекомендаций по сотрудничеству, опираясь на семантический поиск и извлечение информации. Акцент на локальном развертывании подчеркивает важность сохранения конфиденциальности и безопасности данных, что соответствует принципам структурной честности и ясности, а не избыточной сложности.
Куда же дальше?
Представленная работа, несомненно, демонстрирует возможность локального развертывания систем поиска и генерации знаний в клинической среде. Однако, следует признать, что сама по себе возможность — это лишь начальная точка. Истинная сложность заключается не в реализации, а в преодолении избыточности. Бесконечное наращивание параметров моделей и баз данных не является решением, а лишь отсрочкой неизбежного столкновения с ограниченностью восприятия. Задача состоит не в том, чтобы «узнать» больше, а в том, чтобы извлечь суть из уже известного.
Будущие исследования должны сосредоточиться на принципах минимализма. Использование более компактных, специализированных моделей, обученных на тщательно отобранных данных, представляется более перспективным путем, чем погоня за универсальностью. Необходимо разработать метрики, оценивающие не объем сгенерированных текстов, а их ясность и полезность для конкретного клинического случая. Рекомендация коллабораций — лишь один из возможных сценариев. Более важным представляется создание систем, способных выявлять скрытые взаимосвязи между данными, которые ускользают от человеческого внимания.
В конечном счете, успех подобных систем будет определяться не их технологической сложностью, а способностью к самоочищению. Избавление от лишнего — это не ограничение возможностей, а демонстрация глубокого понимания. Поиск простоты — это не наивность, а признак зрелости.
Оригинал статьи: https://arxiv.org/pdf/2601.04209.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-11 20:47