Автор: Денис Аветисян
Представлена семейство открытых языковых моделей, демонстрирующих конкурентоспособную производительность и расширенные возможности рассуждения и обработки длинного контекста.
Ministral 3 — это семейство моделей с открытым исходным кодом (3B, 8B, 14B параметров), обученных с использованием метода каскасной дистилляции, предлагающих высокую эффективность и расширенные возможности.
Несмотря на растущие требования к вычислительным ресурсам современных языковых моделей, сохранение эффективности остаётся критически важной задачей. В настоящей работе представлена серия моделей Ministral 3 — семейство параметрически-эффективных плотных языковых моделей объёмом 3B, 8B и 14B параметров, разработанных для работы в условиях ограниченных ресурсов. Ключевой особенностью является применение метода Cascade Distillation для обучения, позволяющего достичь конкурентоспособной производительности при меньшем объёме вычислений, а также наличие вариантов с поддержкой следования инструкциям, рассуждениями и обработкой изображений. Открывает ли эта архитектура новые перспективы для развертывания передовых языковых моделей на широком спектре устройств и платформ?
Разум в Машине: Представляем Ministral 3
Традиционные большие языковые модели (БЯМ) сталкиваются со значительными трудностями при увеличении способности к рассуждениям. По мере роста размеров модели и сложности задач, требуемые вычислительные ресурсы возрастают экспоненциально, что делает дальнейшее масштабирование непомерно дорогим и непрактичным. Это связано с тем, что увеличение количества параметров не всегда линейно коррелирует с улучшением логического мышления и способности к решению сложных задач. Более того, обучение и развертывание таких гигантских моделей требует огромных затрат энергии и инфраструктуры, что ограничивает их доступность и широкое применение. В результате, исследователи и разработчики постоянно ищут новые подходы, позволяющие повысить эффективность и снизить вычислительную сложность БЯМ без ущерба для их интеллектуальных возможностей.
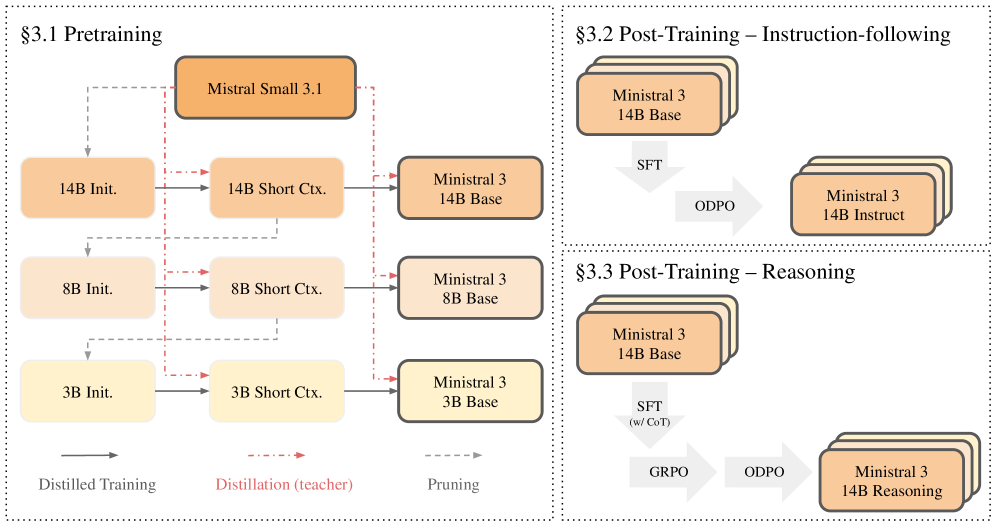
В основе Ministral 3 лежит инновационный метод обучения, заключающийся в итеративном уменьшении размера модели и последующей дистилляции знаний. Этот процесс позволяет существенно сократить вычислительные затраты, сохраняя при этом высокий уровень производительности. Вместо традиционного подхода к обучению огромных моделей, разработчики сосредоточились на создании компактной сети, способной эффективно усваивать и обобщать информацию. Итеративное сжатие модели сопровождается дистилляцией — передачей знаний от более крупной, «учительской» модели к более компактной, что позволяет ей сохранить ключевые способности к рассуждению и генерации текста. Такой подход открывает возможности для более широкого применения языковых моделей, в том числе на устройствах с ограниченными вычислительными ресурсами, и способствует развитию более эффективного искусственного интеллекта.
В основе Ministral 3 лежит архитектура Decoder-Only Transformer, представляющая собой эффективный подход к построению языковых моделей. В отличие от некоторых предшественников, требующих значительных вычислительных ресурсов, данная архитектура оптимизирована для скорости и экономичности, не уступая при этом в качестве генерируемого текста. Принцип работы заключается в последовательном предсказании следующего токена в последовательности, что позволяет модели эффективно обрабатывать и генерировать текст различной сложности. Такой подход позволяет добиться высокой производительности при относительно небольшом количестве параметров, что особенно важно для развертывания модели на устройствах с ограниченными ресурсами и для снижения затрат на ее эксплуатацию, сохраняя при этом способность к сложному рассуждению и генерации связного и осмысленного текста.
Эффективность Масштабирования: Семейство Ministral 3
Семейство Ministral 3 включает модели с 3B, 8B и 14B параметрами, что позволяет пользователям выбирать оптимальный баланс между размером модели и скоростью ее работы. Модели с меньшим количеством параметров (3B и 8B) характеризуются более высокой скоростью инференса и меньшими требованиями к вычислительным ресурсам, что делает их подходящими для задач, где важна скорость отклика и развертывание на устройствах с ограниченными ресурсами. Модели с 14B параметрами, напротив, обеспечивают более высокую точность и качество генерации, но требуют больше вычислительной мощности и памяти. Такой подход позволяет адаптировать модель к конкретным требованиям задачи и доступным ресурсам, обеспечивая гибкость и эффективность использования.
В основе уменьшения размера моделей семейства Ministral 3 лежит метод каскадной дистилляции (Cascade Distillation). Данная техника предполагает последовательное обучение более компактных моделей на основе знаний, полученных от более крупной модели-учителя — в данном случае, Mistral Small 3.1. Процесс включает в себя передачу знаний от учителя к ученику, при этом ученик стремится воспроизвести поведение учителя, но с существенно меньшим количеством параметров. Каскадная дистилляция позволяет не только сжать модель, но и сохранить большую часть ее производительности, эффективно перенося знания от более сложной модели к более компактной.
Семейство Ministral 3 не просто представляет собой уменьшенные версии исходной модели Mistral Small 3.1; это результат целенаправленной оптимизации архитектуры и весов с целью снижения вычислительной сложности. При этом, благодаря применению продвинутых методов дистилляции, удалось сохранить сопоставимый уровень производительности по ключевым метрикам, достигая результатов, сравнимых с моделями значительно большего размера. Это позволяет эффективно использовать ресурсы при сохранении высокой точности и скорости обработки данных, что особенно важно для задач с ограниченными вычислительными возможностями.
Расширение Возможностей: Модели, Следующие Инструкциям и Способные к Рассуждениям
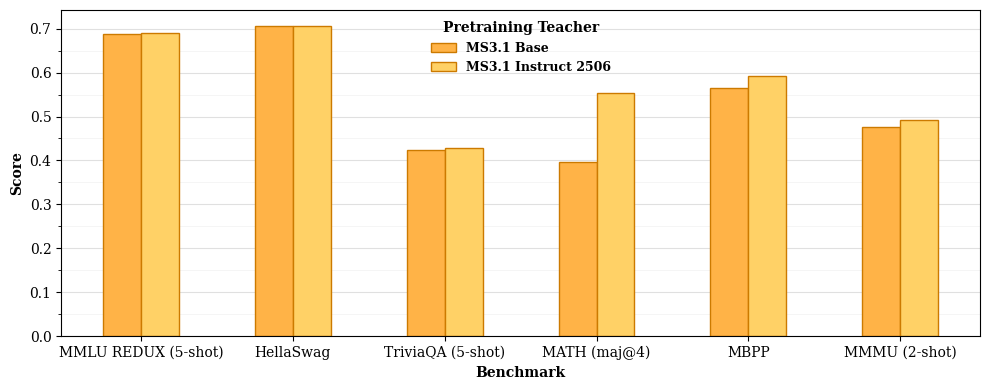
Модели Ministral 3 подвергаются дальнейшей специализации посредством тонкой настройки (fine-tuning), что позволяет создавать варианты, оптимизированные для следования инструкциям и улучшения рассуждений. Этот процесс включает в себя обучение модели на специализированных наборах данных, адаптированных к конкретным задачам, таким как выполнение сложных инструкций или решение логических задач. В результате тонкой настройки достигается повышение точности и эффективности модели в целевых областях, что позволяет создавать специализированные варианты для различных приложений, требующих высокой степени понимания и способности к логическому мышлению.
Обучение с учителем (Supervised Fine-Tuning, SFT) представляет собой метод адаптации предварительно обученных языковых моделей путем обучения на размеченном наборе данных, состоящем из входных запросов и желаемых ответов. Этот процесс позволяет модели лучше понимать намерения пользователя и генерировать ответы, соответствующие заданным инструкциям. SFT фокусируется на минимизации расхождения между сгенерированным моделью текстом и эталонными ответами, что достигается путем корректировки весов модели с использованием алгоритмов оптимизации. В результате, модели, прошедшие SFT, демонстрируют улучшенную способность к обработке сложных инструкций и генерации более релевантных и точных ответов.
Для повышения производительности моделей в задачах, требующих логического мышления, применяются такие методы, как Chain-of-Thought (CoT) и Group Relative Policy Optimization (GRPO). CoT стимулирует модель генерировать промежуточные этапы рассуждений, представляя пошаговое объяснение решения, что улучшает её способность к решению сложных задач. GRPO, в свою очередь, использует оптимизацию политики, ориентированную на группы, для улучшения согласованности и эффективности рассуждений модели, особенно в сценариях, требующих последовательного принятия решений. Оба метода направлены на повышение прозрачности и интерпретируемости процесса рассуждений модели, что облегчает отладку и улучшение её производительности.
Производительность и Валидация: Сравнение с Конкурентами
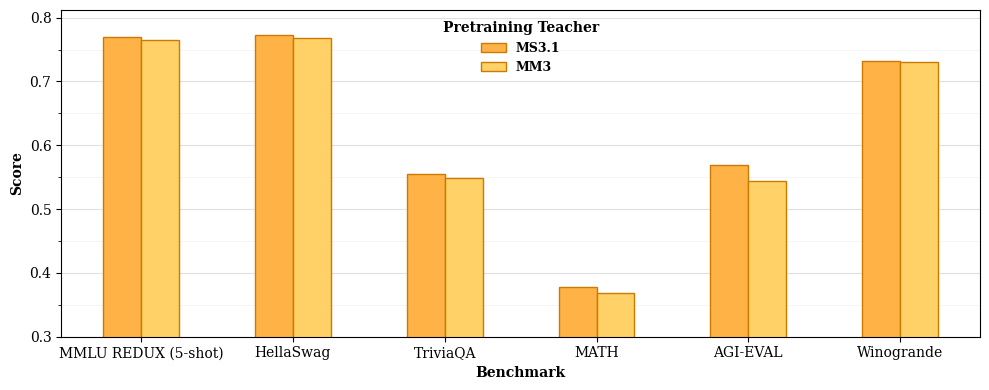
Модели Ministral 3 демонстрируют высокую производительность на бенчмарке MMLU (Massive Multitask Language Understanding), что свидетельствует об их способности к обобщению знаний в различных областях. MMLU оценивает понимание широкого спектра тем, включая гуманитарные, социальные и естественнонаучные дисциплины, представляя собой комплексный тест на знания и логическое мышление. Достижение высоких результатов на MMLU указывает на эффективную архитектуру моделей и стратегию обучения, позволяющие им успешно решать задачи, требующие глубокого понимания и применения знаний из разных областей. Этот результат подтверждает способность моделей к переносу знаний и адаптации к новым, ранее не встречавшимся задачам.
Итеративный процесс прунинга, основанный на анализе главных компонент (PCA), позволяет минимизировать потери производительности при сжатии модели. PCA используется для идентификации и удаления наименее значимых параметров, что снижает вычислительные затраты и размер модели без существенного ухудшения точности. Данный процесс повторяется итеративно, что позволяет достичь оптимального баланса между степенью сжатия и сохранением ключевых характеристик модели, обеспечивая высокую эффективность и производительность даже после значительного уменьшения количества параметров.
При сравнительном анализе с моделями Gemma 3 и другими моделями с открытым исходным кодом, архитектура и методология обучения Ministral 3 демонстрируют конкурентные преимущества. В частности, модель Ministral 3 с 8 миллиардами параметров превосходит модель Gemma 3 с 12 миллиардами параметров по всем протестированным бенчмаркам. Кроме того, Ministral 3 превосходит модель Qwen 3 с 14 миллиардами параметров в задачах TriviaQA и MATH, что подтверждает эффективность применяемых методов оптимизации и обучения.

Расширение Контекста и Перспективы Развития
Модель Ministral 3 достигла значительного расширения контекстного окна, обрабатывая до 256 тысяч токенов, что особенно важно для задач, требующих анализа больших объемов информации. Это стало возможным благодаря применению инновационных методов, таких как YaRN (Yet another RNN) и масштабирование температуры softmax на основе позиции. YaRN позволяет модели более эффективно усваивать и удерживать информацию на протяжении длинных последовательностей, а Position-Based Softmax Temperature Scaling оптимизирует процесс обработки токенов в зависимости от их положения в контексте, улучшая точность и релевантность ответов. Для моделей, специализирующихся на рассуждениях, эффективный размер контекстного окна составляет 128 тысяч токенов, что обеспечивает достаточную основу для сложных логических операций. Такое увеличение контекстного окна открывает новые возможности для работы с длинными документами, книгами и сложными диалогами, позволяя модели поддерживать более связные и информативные ответы.
В архитектуре Ministral 3 интегрирован ViT Vision Encoder, что позволяет модели воспринимать и обрабатывать информацию не только в текстовом формате, но и визуальную. Этот подход открывает возможности для анализа и сопоставления данных, представленных в различных модальностях. Модель способна понимать содержание изображений и устанавливать связи между визуальной информацией и текстом, расширяя спектр решаемых задач. Например, она может генерировать описания изображений, отвечать на вопросы, касающиеся визуального контента, или использовать изображения в качестве контекста для более точного выполнения текстовых запросов. Интеграция ViT Vision Encoder значительно расширяет возможности модели в области мультимодального анализа данных и открывает новые перспективы для создания более интеллектуальных и адаптивных искусственных систем.
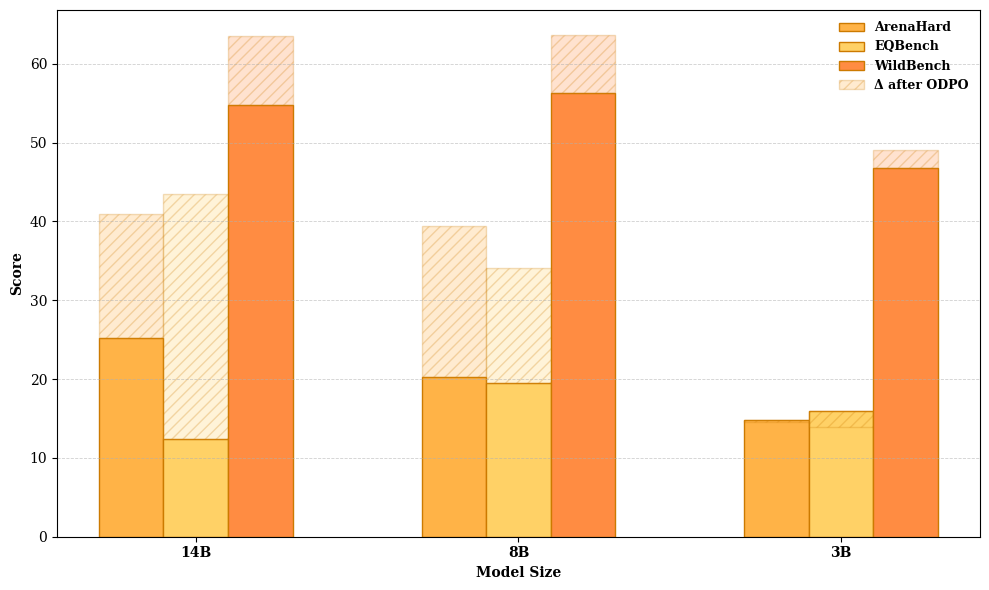
Онлайн-оптимизация предпочтений (ODPO) представляет собой инновационный подход к обучению языковых моделей, позволяющий им непрерывно совершенствоваться на основе прямых отзывов пользователей. В отличие от традиционных методов, требующих сбора больших объемов размеченных данных, ODPO использует сигналы предпочтений, полученные непосредственно в процессе взаимодействия с моделью. Это позволяет ей адаптироваться к нюансам человеческого восприятия и генерировать ответы, более соответствующие ожиданиям и потребностям. Такой метод обучения открывает перспективы для создания действительно интеллектуальных и отзывчивых систем искусственного интеллекта, способных не только понимать запросы, но и предвосхищать намерения пользователя, обеспечивая максимально комфортное и эффективное взаимодействие.
Исследование представляет семейство языковых моделей Ministral 3, демонстрируя, что эффективность и производительность не всегда требуют огромных размеров. Авторы успешно применили метод каскационной дистилляции, позволяющий достичь сопоставимых результатов с более крупными моделями, при этом значительно снижая вычислительные затраты. Этот подход особенно ценен в контексте развития открытых весов моделей, поскольку он делает передовые технологии доступнее для широкого круга исследователей и разработчиков. Как однажды заметила Барбара Лисков: «Программы должны быть спроектированы таким образом, чтобы изменения в одной части не влияли на другие». Подобно этому, Ministral 3 стремится к модульности и эффективности, где каждый компонент работает согласованно, не требуя чрезмерных ресурсов.
Что Дальше?
Представленная работа, как и многие другие в области больших языковых моделей, поднимает больше вопросов, чем дает ответов. Эффективность Cascade Distillation, безусловно, заслуживает внимания, но истинный вызов заключается не в сжатии модели, а в понимании принципов, лежащих в основе её работы. Каждый эксплойт начинается с вопроса, а не с намерения. Возможно, дальнейшее исследование должно быть направлено не на увеличение масштаба, а на разработку принципиально новых архитектур, имитирующих не структуру мозга, а принципы его самоорганизации.
Обещанные возможности работы с длинным контекстом и следование инструкциям — это лишь первые шаги. Истинная проверка ждет в задачах, требующих не просто генерации текста, а реального понимания, адаптации и даже предвидения. Игнорирование базовых ограничений, таких как необходимость в огромных объемах данных для обучения, лишь откладывает неизбежное столкновение с реальностью.
Настоящий прорыв, вероятно, потребует отхода от парадигмы обучения на текстах и перехода к моделям, способным к активному обучению и взаимодействию с миром. Модель, которая не просто отражает знания, но и способна их создавать, — вот где кроется потенциал, способный изменить правила игры. И это, конечно, потребует не только новых алгоритмов, но и совершенно иного взгляда на природу интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2601.08584.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-14 14:35