Автор: Денис Аветисян
Новый подход позволяет языковым и визуальным моделям глубже понимать окружающий мир, самостоятельно совершенствуя свои навыки предсказания и планирования.
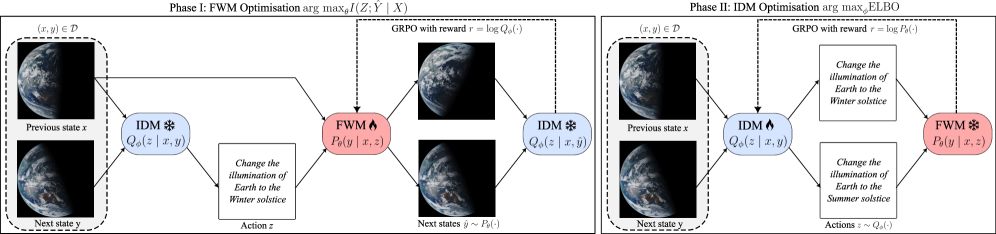
В статье представлена система SWIRL, использующая рекурсивное обучение с подкреплением для улучшения моделей мира путем оптимизации прямых и обратных динамических моделей на основе немаркированных последовательностей состояний.
Несмотря на значительные успехи в области больших языковых и зрительно-языковых моделей, обучение эффективного моделирования мира, необходимого для планирования и рассуждений, требует дорогостоящих размеченных данных о действиях. В данной работе, ‘Self-Improving World Modelling with Latent Actions’, предложен фреймворк SWIRL, который решает эту проблему путем итеративной оптимизации прямых и обратных динамических моделей из неразмеченных последовательностей состояний, рассматривая действия как латентные переменные. SWIRL использует подход взаимного обучения с подкреплением, демонстрируя значительное улучшение производительности на различных бенчмарках, включая AURORABench, ByteMorph и WorldPredictionBench. Возможно ли дальнейшее расширение возможностей SWIRL для создания более адаптивных и автономных интеллектуальных систем?
За пределами Последовательностей: Необходимость Внутренних Моделей Мира
Современные большие языковые модели (LLM) и модели, объединяющие зрение и язык (VLM), демонстрируют впечатляющую способность к распознаванию закономерностей в данных. Однако, несмотря на этот успех, им свойственен фундаментальный недостаток — отсутствие надежных внутренних моделей, отражающих принципы функционирования окружающего мира. Эти модели не обладают интуитивным пониманием физических законов, причинно-следственных связей или базовых свойств объектов. Вместо этого, они полагаются на статистические корреляции, выявленные в огромных объемах данных, что делает их уязвимыми в ситуациях, выходящих за рамки привычных шаблонов, и ограничивает возможности к эффективному планированию и решению задач, требующих реального понимания происходящего.
Несмотря на впечатляющие успехи в распознавании закономерностей, современные языковые и мультимодальные модели демонстрируют ограниченные возможности в обобщении знаний и эффективном планировании, особенно в динамично меняющихся условиях. Эта неспособность объясняется отсутствием у них внутренних моделей, отражающих принципы функционирования окружающего мира. В ситуациях, требующих предвидения последствий действий или адаптации к новым обстоятельствам, модели часто терпят неудачу, поскольку не способны логически вывести необходимые шаги или предсказать результаты. Таким образом, их «разумность» оказывается поверхностной, ограниченной заученными шаблонами, а не глубоким пониманием причинно-следственных связей, что препятствует развитию действительно интеллектуальных систем.
Современные подходы к созданию искусственного интеллекта часто опираются на обширные базы внешних знаний, что существенно ограничивает их адаптивность и увеличивает вычислительные затраты. Вместо того, чтобы самостоятельно формировать понимание принципов работы окружающего мира, системы вынуждены постоянно обращаться к этим внешним источникам для получения необходимой информации. Это не только замедляет процесс принятия решений, но и делает их уязвимыми к неполноте или искажениям во внешних данных. Такая зависимость от внешних знаний препятствует способности системы к обобщению и эффективному функционированию в новых, незнакомых ситуациях, требуя постоянного обновления и поддержания огромных объемов информации. По сути, система остается пассивным потребителем данных, а не активным исследователем и строителем собственной модели мира.
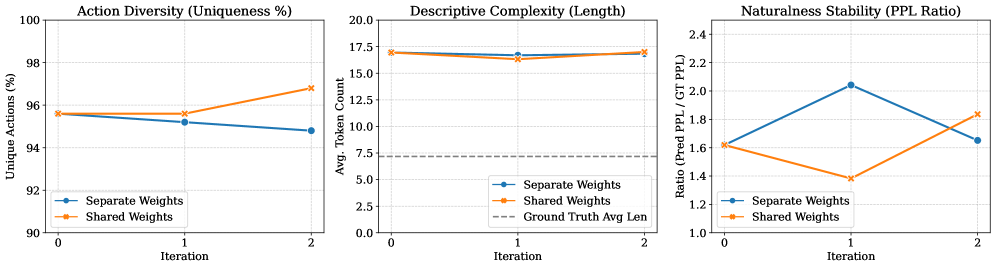
SWIRL: Рациональная Оптимизация Взаимного Влияния
SWIRL представляет собой новый подход к оптимизации, разработанный для улучшения возможностей внутреннего моделирования мира в больших языковых (LLM) и визуальных (VLM) моделях на основе последовательностей состояний. В отличие от традиционных методов, SWIRL позволяет моделям формировать представления об окружающей среде исключительно на основе наблюдений за изменениями состояний, без необходимости явного предоставления информации о действиях. Этот подход основан на одновременной оптимизации как прямой модели мира (Forward World Model, FWM), предсказывающей будущие состояния, так и обратной динамической модели (Inverse Dynamics Model, IDM), позволяющей восстанавливать латентные действия, приведшие к изменению состояния. Такая взаимная оптимизация способствует развитию более согласованного и предсказуемого внутреннего представления окружающей среды.
В основе SWIRL лежит одновременная оптимизация прямой модели мира (FWM) и обратной динамической модели (IDM). FWM предназначена для предсказания будущих состояний среды на основе текущего состояния, в то время как IDM позволяет выводить скрытые действия, которые могли привести к наблюдаемому изменению состояния. Такая совместная оптимизация позволяет модели не только прогнозировать развитие событий, но и понимать причинно-следственные связи в окружающей среде, что критически важно для построения надежной внутренней репрезентации мира и планирования действий.
Взаимный процесс обучения, основанный на Group Relative Policy Optimization (GRPO), способствует формированию связной и предсказуемой внутренней репрезентации окружающей среды. GRPO позволяет одновременно оптимизировать как предсказание будущих состояний, так и вывод скрытых действий, что приводит к более точному моделированию динамики среды. Этот подход обеспечивает согласованность между прямой и обратной моделями, позволяя модели не только предсказывать, что произойдет дальше, но и понимать, какие действия приводят к определенным результатам. Оптимизация осуществляется путем минимизации расхождений между предсказанными и фактическими состояниями, а также путем максимизации соответствия между действиями и их последствиями, что способствует созданию устойчивой и надежной внутренней модели.
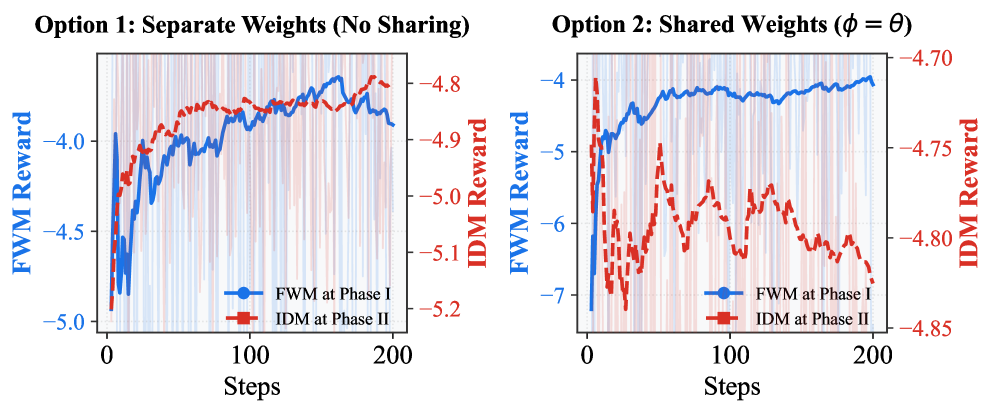
Оптимизация для Предсказания и Контроля
Оптимизация Forward Model (FWM) осуществляется путем максимизации условной взаимной информации (Conditional Mutual Information, CMI). Этот процесс направлен на обеспечение сильной связи между предсказанными состояниями и выведенными скрытыми действиями. CMI измеряет, насколько знание скрытого действия уменьшает неопределенность в отношении предсказанного состояния. Максимизация CMI гарантирует, что FWM способна генерировать точные прогнозы, тесно связанные с действиями, которые, по мнению модели, привели к этим состояниям. В результате модель лучше понимает причинно-следственные связи в окружающей среде, что критически важно для эффективного планирования и контроля.
Модель детерминированного вывода действий (IDM) оптимизируется путем максимизации нижней границы правдоподобия (Evidence Lower Bound, ELBO). ELBO представляет собой оценку логарифма маргинальной вероятности наблюдаемых переходов состояний и используется в качестве суррогатной функции для обучения. Максимизация ELBO способствует повышению точности IDM в процессе вывода действий, соответствующих наблюдаемым изменениям состояния системы. Фактически, это улучшает способность модели оценивать наиболее вероятные действия, приведшие к переходу из одного состояния в другое, основываясь на входных данных о переходе состояний. ELBO = \mathbb{E}_{q(z|x)}[log p(x|z)] - KL(q(z|x) || p(z)), где q(z|x) — апроксимированное распределение, а p(z) — априорное распределение.
Двойная стратегия оптимизации, максимизирующая как условную взаимную информацию (FWM), так и нижнюю оценку доказательств (IDM), способствует формированию согласованного и информативного внутреннего представления об окружающей среде. Это позволяет модели не только предсказывать будущие состояния на основе предполагаемых действий, но и точно выводить действия, вызванные наблюдаемыми изменениями состояния. Согласованность между предсказаниями и выводами, обеспечиваемая данной оптимизацией, является ключевым фактором для обеспечения надежного принятия решений в сложных и динамичных условиях, поскольку позволяет модели адекватно реагировать на новые ситуации и избегать неверных интерпретаций.
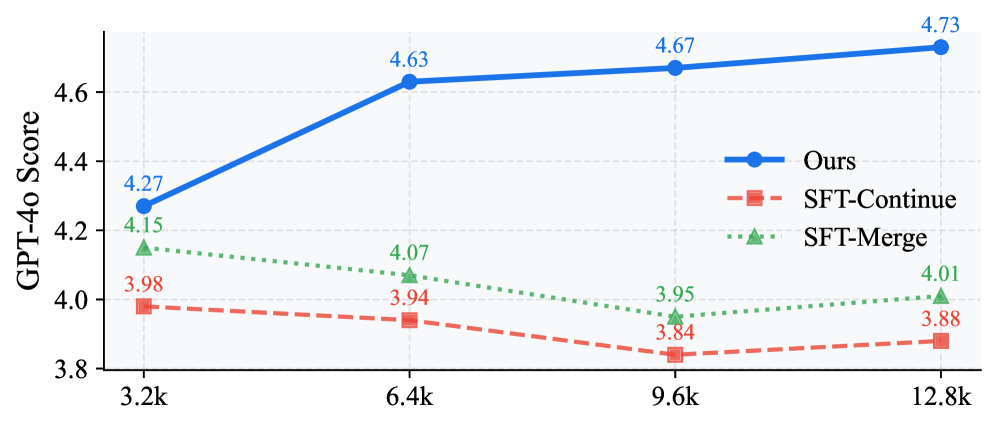
Широкая Валидация в Разнообразных Средах
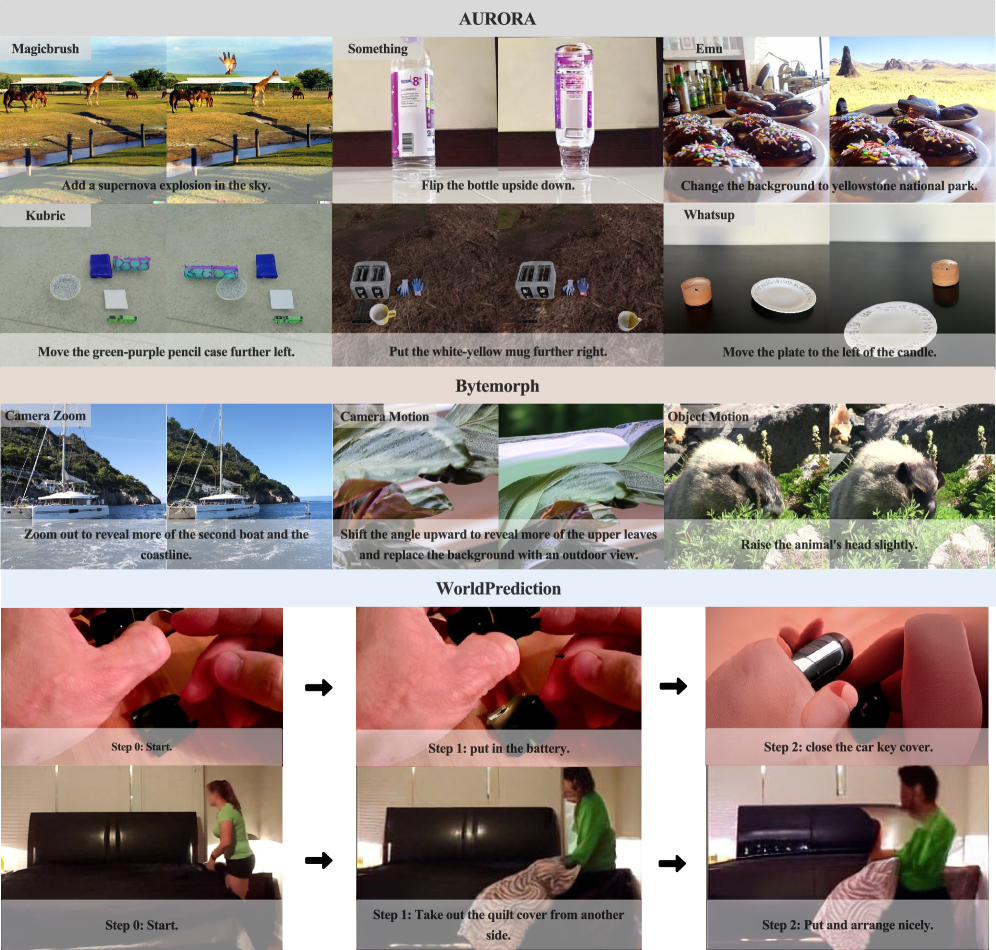
Проведенная оценка производительности SWIRL на авторитетных бенчмарках, таких как Aurora-Bench, ByteMorph, ScienceWorld и WorldPredictionBench, наглядно продемонстрировала способность системы эффективно моделировать как визуальные, так и текстовые окружения. Данные тесты позволили установить, что SWIRL обладает выдающимися возможностями в понимании и прогнозировании изменений в различных средах, успешно интегрируя информацию, полученную из разных источников. Способность к комплексному анализу визуальных и текстовых данных открывает перспективы для создания более интеллектуальных и адаптивных ИИ-систем, способных эффективно функционировать в сложных и динамичных условиях.
Исследования показали, что SWIRL демонстрирует выдающиеся способности в области использования инструментов и взаимодействия с веб-интерфейсами, что подтверждается результатами тестов на Mind2Web и StableToolBench. Эта способность позволяет модели не только понимать задачи, требующие внешних инструментов, но и эффективно применять их для достижения поставленных целей, например, поиск информации в сети или выполнение сложных операций через веб-приложения. В частности, SWIRL успешно справляется с задачами, требующими последовательного использования различных инструментов и адаптации к изменяющимся условиям веб-среды, что свидетельствует о высоком уровне ее интеллектуальной гибкости и потенциале для создания более продвинутых и автономных систем искусственного интеллекта.
Результаты исследований демонстрируют значительное улучшение возможностей предсказания визуальной информации на длинных временных горизонтах, подтвержденное относительным приростом в 14.4% на бенчмарке WorldPredictionBench. Средний показатель GPT-4o, полученный по всем тестовым наборам, составил 4.73, что превосходит базовый результат в 4.27. Особенно заметно превосходство на WorldPredictionBench (Turn 4), где был достигнут показатель 1.59 при базовом значении 1.17, а также на Aurora-Bench с конфигурацией раздельных весов, где результат составил 5.06. Эти данные свидетельствуют об эффективности разработанного подхода в расширении возможностей моделирования мира для больших языковых и визуальных моделей, открывая перспективы для создания более интеллектуальных и адаптивных систем искусственного интеллекта.
Полученные результаты однозначно подтверждают, что SWIRL значительно улучшает возможности языковых и визуально-языковых моделей в области моделирования мира. Это достигается за счет более глубокого понимания контекста и взаимосвязей в данных, что позволяет создавать более интеллектуальные и адаптивные системы искусственного интеллекта. Повышенная способность к прогнозированию и взаимодействию с окружающей средой открывает перспективы для разработки агентов, способных эффективно решать сложные задачи в различных областях, от робототехники до автоматизации веб-сервисов. В конечном итоге, SWIRL способствует созданию систем, способных не просто реагировать на входные данные, а активно понимать и предвидеть развитие событий.
Исследование демонстрирует, что эффективное моделирование мира требует не просто предсказания следующего состояния, но и понимания скрытых действий, приводящих к этому состоянию. Это особенно заметно в рамках предложенного подхода SWIRL, который итеративно оптимизирует как прямые, так и обратные динамические модели. Как метко заметил Джон Маккарти: «Искусственный интеллект — это изучение того, как сделать машины, чтобы они делали то, что люди делают лучше». В контексте данной работы, это означает создание систем, способных не только имитировать действия, но и учиться на них, улучшая свои модели мира и принимая более обоснованные решения, подобно человеческому разуму. Структура, определяющая взаимодействие между прямыми и обратными моделями, напрямую влияет на способность системы к самосовершенствованию.
Куда двигаться дальше?
Представленная работа, стремясь к самосовершенствованию моделей мира, неизбежно наталкивается на фундаментальный вопрос: достаточно ли оптимизировать отдельные компоненты, если сама архитектура системы уязвима? Если модель мира держится на «костылях» из сложных взаимосвязей, это лишь свидетельствует о чрезмерной сложности, а не об истинном понимании. Модульность, без учета контекста и принципов системной интеграции, — иллюзия контроля, а не реальное решение.
Перспективы развития лежат не только в улучшении точности предсказания динамики, но и в исследовании более элегантных, принципиально новых подходов к моделированию. Необходимо переосмыслить само понятие «модели мира» — не как статичную репрезентацию, а как развивающийся процесс адаптации к окружающей среде. Важным направлением представляется интеграция с системами причинно-следственного вывода, позволяющими не просто предсказывать, но и понимать взаимосвязи между событиями.
В конечном итоге, успех в данной области зависит не от количества параметров модели, а от её способности к обобщению и экстраполяции. Простая, но глубокая модель, способная к самообучению и адаптации, всегда будет превосходить сложную, но хрупкую конструкцию. Следующим шагом видится отказ от попыток «закодировать» мир и переход к созданию систем, способных его «понимать».
Оригинал статьи: https://arxiv.org/pdf/2602.06130.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Переворот: От Теории к Реальности
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
- Самообучающиеся агенты: новый подход к автономным системам
- Плоские зоны: от теории к новым материалам
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Искусственный интеллект на службе редких болезней
- Понимание мира в динамике: новая модель для анализа 4D-данных
- Квантовые амбиции: Иран вступает в гонку
2026-02-09 16:37