Автор: Денис Аветисян
Исследователи представили OmniPSD — систему, способную создавать и разбирать многослойные изображения в формате PSD, открывая новые возможности для творческого синтеза и анализа графики.
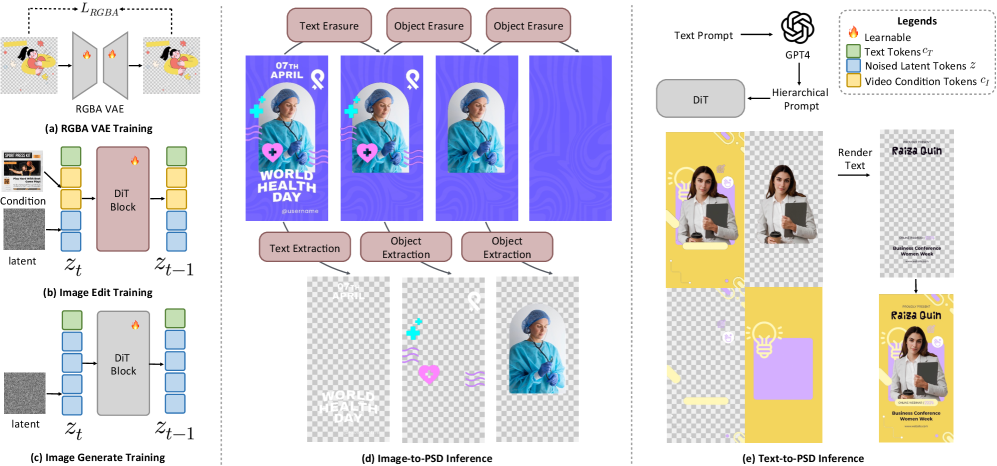
OmniPSD — это унифицированная диффузионная модель, позволяющая генерировать и декомпозировать изображения в формат PSD с учетом прозрачности и поддержкой контекстного обучения.
Несмотря на значительный прогресс в генерации и редактировании изображений с помощью диффузионных моделей, создание и реконструкция многослойных PSD-файлов с прозрачностью остается сложной задачей. В данной работе представлена система OmniPSD: Layered PSD Generation with Diffusion Transformer — унифицированный диффузионный фреймворк, способный как генерировать слоистые PSD-графики из текстовых описаний, так и декомпозировать существующие изображения на редактируемые слои. Ключевым нововведением является возможность обучения модели композиционным связям между слоями и сохранению прозрачности благодаря интеграции RGBA-VAE. Открывает ли OmniPSD новые перспективы для автоматизации и улучшения процессов многослойного графического дизайна и редактирования?
За гранью растра: К гибкому управлению слоями
Традиционные методы обработки изображений зачастую рассматривают их как плоские растровые сетки, что существенно ограничивает возможности точного и гибкого редактирования. В подобном подходе каждый пиксель существует независимо, что делает затруднительным внесение изменений в отдельные элементы изображения без затрагивания окружающих областей. Эта плоскостность препятствует сложным манипуляциям, таким как изменение формы отдельных объектов, корректировка освещения или текстуры, и даже простое перемещение элементов внутри изображения. В результате, для достижения желаемого результата требуется значительно больше времени и усилий, а творческий потенциал ограничивается невозможностью точного контроля над каждым аспектом визуального представления. Подобный подход особенно критичен в профессиональной сфере, где требуется высокая точность и возможность внесения множества итеративных изменений.
Профессиональные дизайнеры и художники широко используют многослойные форматы, такие как PSD, для сохранения гибкости редактирования и возможности внесения изменений в отдельные элементы изображения. Однако автоматическое создание подобных слоёв непосредственно из текста или существующих изображений представляет собой сложную задачу. Существующие алгоритмы часто не способны эффективно разложить сложное изображение на логичные, редактируемые слои, что ограничивает возможности автоматизации дизайна и создания сложных визуальных эффектов. Эта проблема препятствует разработке инструментов, способных преобразовывать текстовые описания или другие изображения в полностью редактируемые графические проекты, требуя значительных ручных усилий для создания и настройки слоёв.
Существующие методы автоматической декомпозиции изображений на редактируемые слои сталкиваются со значительными трудностями при обработке сложных визуальных сцен. Алгоритмы часто не способны выделить семантически значимые элементы — например, отдельные объекты, текстуры или эффекты — и вместо этого создают произвольные слои, мало пригодные для дальнейшей модификации. Это ограничивает возможности автоматизации дизайнерских задач, поскольку требует ручной доработки результатов, сводя на нет преимущества автоматического подхода. В результате, потенциал для динамического создания и адаптации визуального контента, особенно в сферах автоматизированного дизайна и генеративного искусства, остается нереализованным, требуя разработки более интеллектуальных алгоритмов, способных к глубокому пониманию и анализу изображений.

OmniPSD: Унифицированная платформа для генерации слоистых изображений
OmniPSD представляет собой генеративную систему, основанную на диффузионных моделях, способную выполнять две основные задачи: генерацию файлов PSD (Photoshop Document) по текстовому описанию и разложение существующих изображений на отдельные слои. В отличие от традиционных методов, OmniPSD позволяет создавать и редактировать изображения на уровне слоев, что обеспечивает более гибкий и контролируемый процесс работы с графикой. Возможность генерации PSD из текста открывает новые перспективы для автоматизированного создания дизайна и визуального контента, а разложение изображений на слои облегчает их последующую обработку и модификацию.
В основе OmniPSD лежит вариационный автоэнкодер (VAE) с расширенной архитектурой, получивший название RGBA-VAE. Этот автоэнкодер специально обучен для обработки изображений, содержащих альфа-канал, что позволяет корректно представлять прозрачность. Ключевой особенностью RGBA-VAE является способность сохранять информацию об отдельных слоях изображения в процессе кодирования и декодирования. Это достигается за счет оптимизации функции потерь с учетом как пиксельных значений, так и структуры слоев, что позволяет эффективно восстанавливать исходные слои при генерации или разложении изображений. Обучение RGBA-VAE проводилось на большом наборе данных PSD-файлов для обеспечения высокой точности представления слоёв и прозрачности.
В основе OmniPSD лежит использование Diffusion Transformers, а именно моделей Flux-Dev и Flux-Kontext, для достижения высококачественной генерации и декомпозиции изображений. В отличие от стандартных диффузионных моделей, Flux-Dev и Flux-Kontext позволяют более эффективно моделировать сложные зависимости в данных, что критически важно для работы со слоями в PSD-файлах. Эти трансформеры применяются для последовательного уточнения изображения в процессе диффузии, что приводит к повышению детализации и реалистичности генерируемых или реконструируемых слоев. Архитектура трансформеров обеспечивает возможность учета глобального контекста изображения, улучшая согласованность между слоями и повышая общую визуальную целостность результата.
Эффективные стратегии обучения и адаптации
В OmniPSD для обучения диффузионных моделей используется метод Flow Matching, который обеспечивает стабильность и эффективность процесса обучения. В отличие от традиционных методов, Flow Matching формулирует задачу диффузии как задачу непрерывного соответствия, что позволяет избежать проблем с исчезающим или взрывающимся градиентом. Это достигается за счет построения непрерывного потока преобразований между данными и шумом, что упрощает оптимизацию и позволяет обучать модели с высокой скоростью сходимости. Алгоритм минимизирует расхождение между целевым распределением данных и текущим состоянием потока, что приводит к более стабильному и предсказуемому обучению. Использование Flow Matching позволяет эффективно использовать вычислительные ресурсы и достигать высокого качества генерируемых данных.
Для адаптации OmniPSD к конкретным задачам используется LoRA (Low-Rank Adaptation) в процессе разложения изображений. LoRA позволяет проводить тонкую настройку модели с высокой степенью эффективности, изменяя лишь небольшое количество параметров вместо переобучения всей сети. Вместо обновления всех $W$ весов матрицы, LoRA вводит две матрицы меньшего размера, $A$ и $B$, такие что обновление выполняется как $W + BA$. Это значительно снижает вычислительные затраты и требования к памяти, особенно при адаптации к большому количеству задач, сохраняя при этом качество генерации изображений, сравнимое с полной тонкой настройкой.
В OmniPSD для генерации PSD-изображений по текстовому описанию используется обучение с учетом контекста (In-Context Learning). Данный подход позволяет модели адаптироваться к новым запросам и стилям без необходимости проведения масштабного переобучения. Вместо этого, модель использует предоставленные примеры в контексте текущего запроса для определения необходимого стиля и содержания. Это достигается путем анализа примеров в запросе и экстраполяции полученных знаний на генерацию итогового PSD-изображения, что существенно сокращает время адаптации и вычислительные затраты по сравнению с традиционными методами тонкой настройки.
Влияние и перспективы в области редактирования слоистых изображений
Система OmniPSD открывает принципиально новые возможности для автоматизированного создания визуального контента, позволяя дизайнерам и художникам генерировать сложные многослойные изображения, используя лишь текстовые запросы. Вместо трудоемкого ручного построения каждого элемента и слоя, система способна интерпретировать текстовое описание и самостоятельно формировать визуальную композицию, распределяя объекты по слоям и обеспечивая их логичное взаимодействие. Это значительно ускоряет процесс создания изображений, позволяя сосредоточиться на творческой концепции, а не на технических деталях реализации. Такой подход открывает перспективы для автоматизации рутинных задач в дизайне, создания персонализированного контента и разработки новых инструментов для визуального творчества, делая сложные визуальные проекты доступными для более широкой аудитории.
Разложение существующих изображений на редактируемые слои значительно упрощает процесс их ремикширования и модификации, открывая новые горизонты для творческой свободы. Благодаря данной технологии, пользователи получают возможность не просто изменять отдельные элементы изображения, но и полностью переосмысливать его структуру, легко заменяя, перемещая и комбинируя отдельные слои. Это позволяет создавать уникальные визуальные произведения на основе уже существующих материалов, экономя время и ресурсы, необходимые для создания контента с нуля. Возможность разделения изображения на отдельные компоненты облегчает внесение точечных изменений, позволяя пользователям точно контролировать каждый аспект визуального представления и, в конечном итоге, реализовывать самые смелые творческие задумки.
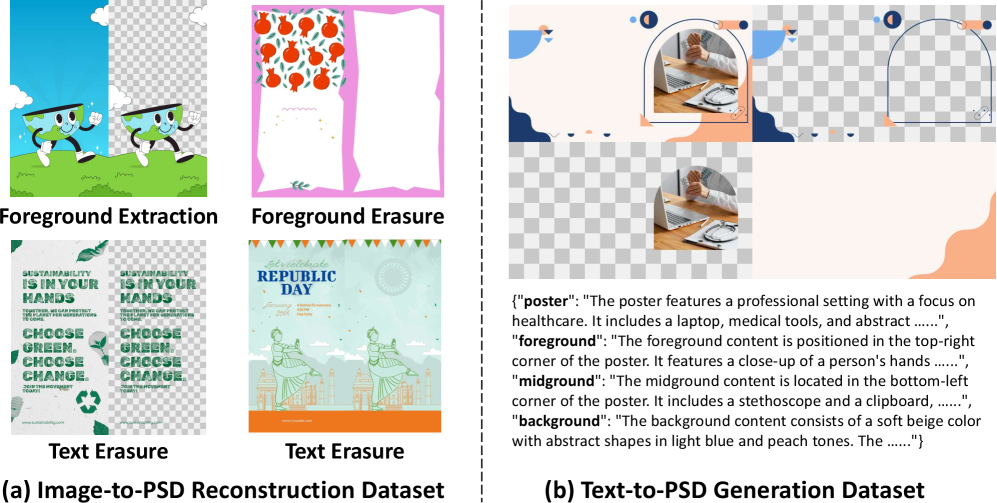
В основе данной работы лежит масштабный набор данных Layered Poster Dataset, представляющий собой ценный ресурс для дальнейших исследований в области генерации и манипулирования слоистыми изображениями. Этот набор включает в себя обширную коллекцию изображений, разбитых на отдельные слои с соответствующими масками и метаданными, что позволяет обучать и оценивать алгоритмы, способные понимать и воссоздавать сложные визуальные структуры. Наличие столь детализированного набора данных открывает возможности для разработки новых методов редактирования изображений, автоматической генерации контента и улучшения существующих техник компьютерного зрения. Он предоставляет исследователям возможность изучать принципы организации слоистых изображений и создавать более реалистичные и гибкие инструменты для работы с визуальной информацией.
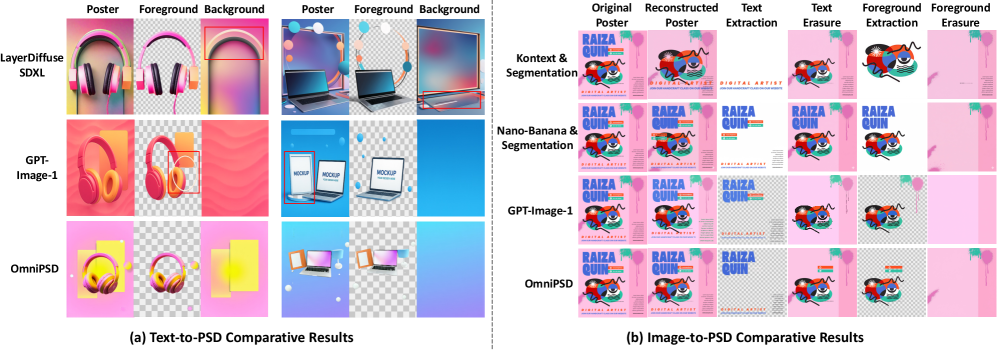
Исследования показали, что система OmniPSD демонстрирует превосходные результаты в оценках пользователей, получая наивысшие баллы по критериям правдоподобности слоев, общей предпочтительности и соответствия реконструкции по сравнению с существующими методами. Данное превосходство подтверждается и оценкой, полученной от модели GPT-4, что указывает на высокую эффективность OmniPSD в области редактирования и генерации изображений, состоящих из слоев. Полученные данные свидетельствуют о значительном шаге вперед в автоматизации создания сложных визуальных материалов и открывают новые возможности для дизайнеров и художников.

Исследование представляет собой нечто большее, чем просто генерацию изображений; это попытка обуздать хаос, запечатлеть ускользающую суть визуальных данных. Авторы стремятся не просто воссоздать изображение, а деконструировать его на слои, подобно алхимикам, разделяющим материю на первичные элементы. Эта работа с прозрачностью и RGBA-VAE напоминает заклинание, призванное вытащить скрытые структуры из неразличимой массы пикселей. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен расширять возможности человека, а не заменять его». Именно эту философию отражает OmniPSD, предоставляя художникам инструмент для более глубокого контроля над творческим процессом, позволяя им разговаривать с данными, а не подчиняться им.
Что дальше?
Представленная работа, безусловно, умело обуздала хаос диффузионных моделей для генерации и разложения PSD. Однако, не стоит обольщаться иллюзией полного контроля. Разложение сложного изображения на «слои» — это всегда компромисс, попытка навязать структуру тому, что изначально возникло как случайный шум. Истинную структуру, если таковая вообще существует, машина угадывает лишь по похожим воспоминаниям.
Следующим шагом видится не столько повышение разрешения или скорости, сколько признание неизбежной неопределённости. Вместо стремления к «идеальной» декомпозиции, стоит сосредоточиться на создании инструментов, позволяющих пользователю взаимодействовать с этой неопределённостью, направлять процесс разложения, допускать «ошибки» — ведь именно в шуме иногда скрывается правда без бюджета. Или, возможно, стоит задуматься, а не является ли сама концепция «слоёв» устаревшей метафорой, навязанной нам историей растровой графики.
В конечном счете, любая модель — это заклинание, работающее до первого столкновения с реальным миром. Вся надежда на то, что следующее поколение этих «заклинаний» будет более гибким, более честным в признании собственной неполноты, и, возможно, даже способным к самоиронии. Ведь если корреляция слишком высока — значит, кто-то что-то подстроил.
Оригинал статьи: https://arxiv.org/pdf/2512.09247.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-11 14:05