Автор: Денис Аветисян
Новый подход позволяет унифицированным мультимодальным моделям эффективно обучаться новым задачам, не забывая при этом старые навыки.
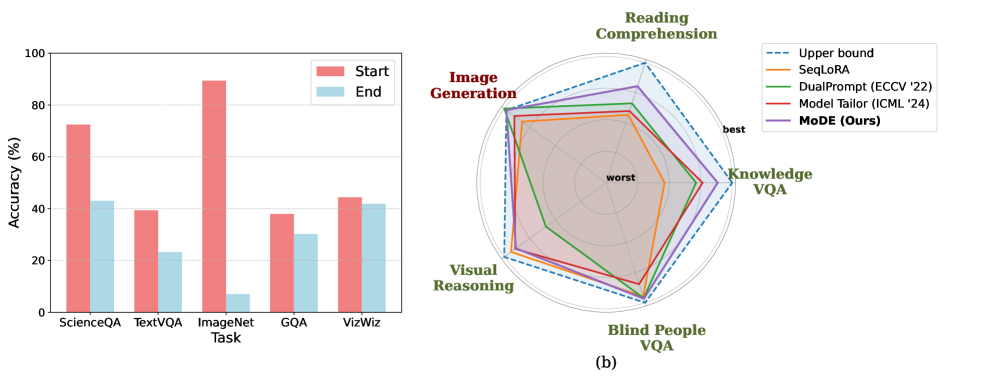
В статье представлена методика Modality-Decoupled Experts (MoDE) для смягчения внутри- и межмодального катастрофического забывания при непрерывном обучении унифицированных мультимодальных генеративных моделей.
Единые мультимодальные генеративные модели, объединяющие понимание и генерацию изображений, сталкиваются с проблемой катастрофического забывания при непрерывном обучении, как внутри одной модальности, так и между ними. В работе ‘Mitigating Intra- and Inter-modal Forgetting in Continual Learning of Unified Multimodal Models’ идентифицировано и эмпирически подтверждено явление межмодального забывания, обусловленное конфликтом градиентов между модальностями. Для решения этой проблемы предложена архитектура Modality-Decoupled Experts (MoDE), которая изолирует обновления для каждой модальности и использует дистилляцию знаний для предотвращения забывания и сохранения ранее полученных навыков. Способна ли данная архитектура обеспечить масштабируемое и устойчивое непрерывное обучение для сложных мультимодальных систем?
Катастрофическое забывание: Проблема непрерывного обучения в мультимодальных системах
Современные модели искусственного интеллекта часто сталкиваются с проблемой, известной как “катастрофическое забывание” — тенденцией терять ранее полученные знания при обучении на новых данных. Это существенно ограничивает их способность к реальной адаптации и непрерывному обучению. Вместо того, чтобы постепенно накапливать опыт, модель, обученная распознавать, например, кошек, может “забыть” это умение при изучении распознавания собак. Данное явление особенно критично при решении сложных задач, требующих интеграции разнообразных знаний и навыков, и препятствует созданию по-настоящему интеллектуальных систем, способных к длительному и эффективному обучению в меняющейся среде. По сути, происходит не плавное расширение базы знаний, а её периодическая перезапись, что делает невозможным построение стабильного и долговечного интеллекта.
Особенно остро проблема забывания проявляется в задачах мультимодального обучения, где искусственный интеллект должен не просто усваивать информацию из различных источников, таких как изображения и текст, но и интегрировать её, выстраивая целостную картину мира. В отличие от обучения на однотипных данных, мультимодальность требует от модели способности устанавливать связи между совершенно разными типами информации, сохраняя при этом знания, полученные из каждого источника. Это значительно усложняет задачу, поскольку новая информация может не только вытеснять старую, но и искажать уже сформированные представления, приводя к непредсказуемым ошибкам и снижению общей эффективности системы. Таким образом, способность к непрерывному обучению в мультимодальной среде становится ключевым фактором для создания действительно адаптивных и интеллектуальных систем.
Несмотря на постоянное увеличение размеров нейронных сетей, проблема непрерывного обучения остается актуальной. Простое масштабирование моделей не решает фундаментальную задачу сохранения ранее приобретенных знаний при обучении новым данным. Существующие методы, направленные на преодоление “катастрофического забывания”, зачастую оказываются неэффективными, не обеспечивая удовлетворительного баланса между способностью к обучению новым задачам и сохранением информации, полученной ранее. Это указывает на необходимость разработки принципиально новых парадигм обучения, которые позволят искусственному интеллекту не просто накапливать знания, но и эффективно интегрировать и использовать их в динамично меняющейся среде, подобно человеческому мозгу.

UMGM: Унифицированный подход к мультимодальной интеграции
Единые мультимодальные генеративные модели (UMGM) представляют собой подход к созданию единой архитектуры, способной воспринимать и генерировать контент, представленный в различных модальностях, таких как текст, изображения и аудио. В отличие от традиционных методов, требующих отдельных моделей для каждой модальности, UMGM стремятся к созданию универсальной системы, способной интегрировать информацию из разных источников и генерировать согласованные результаты. Это достигается путем обучения модели на данных, охватывающих несколько модальностей, что позволяет ей выявлять общие закономерности и взаимосвязи между ними. Ключевая цель — создание системы, способной не только понимать и генерировать контент в каждой модальности по отдельности, но и комбинировать их для создания более сложных и информативных результатов.
Единые мультимодальные генеративные модели (UMGM) используют метод обучения с подкреплением на основе инструкций (instruction tuning) для согласования поведения модели с намерениями пользователя. Этот подход предполагает обучение модели на наборе данных, состоящем из инструкций на естественном языке и соответствующих желаемых ответов в различных модальностях. В процессе обучения модель учится интерпретировать инструкции и генерировать релевантный контент, адаптируясь к разнообразным запросам и сценариям. Использование instruction tuning позволяет UMGMs демонстрировать повышенную гибкость и способность к адаптации, превосходя традиционные методы обучения, требующие жесткой фиксации на конкретных задачах или модальностях.
Единое многомодальное генеративное моделирование (UMGM) стремится к созданию общего пространства представлений для различных модальностей данных. Это позволяет модели сохранять знания, полученные из одной модальности, при обучении на других, тем самым снижая эффект катастрофического забывания. Наша разработанная архитектура Modality-Decoupled Experts (MoDE) демонстрирует среднюю точность в 33.47% на различных многомодальных задачах, подтверждая потенциал данного подхода к улучшению переноса знаний между модальностями и повышению общей эффективности модели.
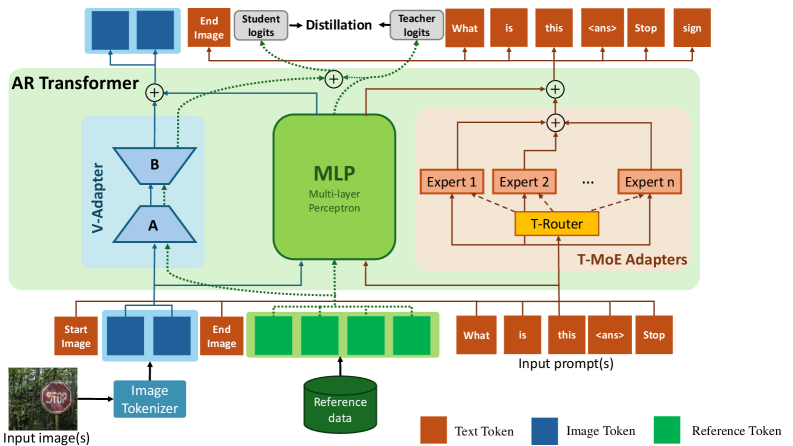
Рассечение мультимодального забывания: Внутри- и межмодальные аспекты
Катастрофическое забывание в многомодальном обучении проявляется в двух основных формах: внутримодальное забывание и межмодальное забывание. Внутримодальное забывание относится к потере знаний внутри отдельной модальности (например, ухудшение производительности модели при обработке новых изображений после обучения на новых текстовых данных). Межмодальное забывание, напротив, возникает при потере знаний о взаимосвязях между различными модальностями; модель может сохранить способность обрабатывать изображения и текст по отдельности, но потерять способность корректно интегрировать информацию из обеих модальностей для решения общей задачи. Оба типа забывания представляют собой серьезную проблему для непрерывного обучения многомодальных моделей, требуя разработки стратегий для сохранения знаний при обучении на новых данных.
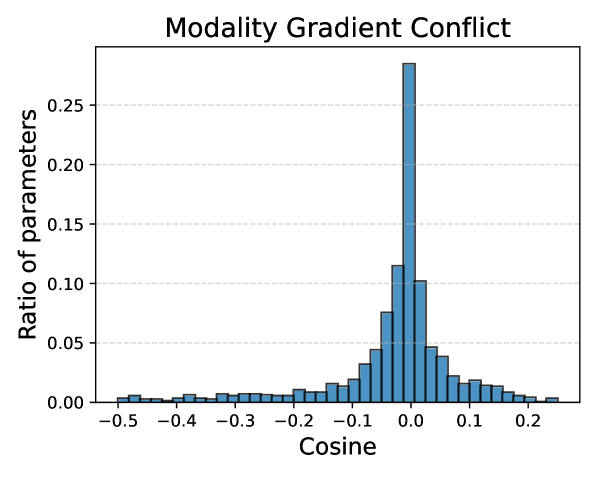
Межмодальное забывание в многомодальном обучении часто вызывается конфликтом градиентов между модальностями — ситуацией, когда обновления общих параметров модели, полученные из разных модальностей (например, текста и изображения) во время тренировки, противоречат друг другу. Этот конфликт возникает из-за различий в распределениях данных и особенностях обучения для каждой модальности, приводя к дестабилизации общих представлений и ухудшению производительности на ранее изученных задачах. По сути, градиенты, вычисленные для одной модальности, могут «перезаписывать» или ослаблять информацию, полученную из другой, что снижает эффективность совместного обучения и приводит к межмодальному забыванию.
Для оценки универсальных мультимодальных моделей (UMGM) и выявления характера возникающего катастрофического забывания критически важны наборы данных ScienceQA, TextVQA, GQA, VizWiz и ImageNet. Использование этих датасетов позволяет точно определить, в каких задачах и при каких условиях происходит потеря ранее усвоенных знаний. Наши результаты показывают, что разработанный метод демонстрирует минимальный средний уровень забывания по сравнению с существующими базовыми решениями в области континуального обучения, что подтверждается экспериментальными данными на указанных датасетах.
Дистилляция знаний и эффективная адаптация
Дистилляция знаний, представляющая собой передачу информации от большой «учительской» модели к меньшей «студенческой», обеспечивает сохранение ранее полученных знаний в процессе непрерывного обучения. Этот подход позволяет «студенческой» модели усваивать обобщенные представления, полученные «учительской» моделью, не требуя повторного обучения с нуля при поступлении новых данных. В результате, «студенческая» модель сохраняет производительность в предыдущих задачах, избегая катастрофического забывания, и одновременно адаптируется к новым задачам, эффективно используя возможности трансфера знаний. Этот метод особенно важен в сценариях, где вычислительные ресурсы ограничены, и требуется поддерживать высокую производительность модели при постоянном поступлении новых данных и задач.
V-Adapter представляет собой визуальный адаптер, основанный на методе LoRA (Low-Rank Adaptation), который интегрируется в универсальные многомодальные модели (UMGM) для обеспечения передачи знаний и сохранения визуальной информации. LoRA позволяет адаптировать предварительно обученную модель, обучая лишь небольшое количество дополнительных параметров, что значительно снижает вычислительные затраты и требования к памяти. Интеграция V-Adapter в UMGMs позволяет эффективно переносить визуальные знания из более крупных моделей в более компактные, сохраняя при этом производительность и обобщающую способность. Этот подход особенно полезен в сценариях непрерывного обучения, где необходимо сохранять информацию, полученную при решении предыдущих задач, и адаптировать модель к новым данным.
Использование селективной дистилляции знаний позволяет универсальным мультимодальным моделям (UMGM) избегать перезаписи ранее полученных знаний и поддерживать производительность при решении различных задач и обработке различных модальностей данных. В ходе экспериментов было достигнуто значение метрики Fréchet Inception Distance (FID) равное 53.74, что сопоставимо с показателем предварительно обученной модели, составляющим 52.13. Данный результат подтверждает эффективность предлагаемого метода в сохранении качества генерируемых данных после адаптации к новым задачам.
Наблюдатель, повидавший немало архитектур, отмечает, что стремление к единой мультимодальной модели неизбежно сталкивается с проблемой катастрофического забывания. Разработчики, как правило, увлечены изяществом теории, но реальность продакшена вносит свои коррективы. Предложенный подход Modality-Decoupled Experts (MoDE) — попытка разложить сложную задачу на более управляемые части, что, в принципе, логично. Как говорила Барбара Лисков: «Хороший дизайн — это такое решение, которое можно легко изменить». И это, пожалуй, самое важное — предусмотреть возможность адаптации, ведь каждая «революционная» технология завтра станет техдолгом. Иначе говоря, система, живущая, но страдающая.
Что дальше?
Представленный подход, безусловно, снижает остроту проблемы катастрофического забывания в мультимодальных моделях. Однако, стоит помнить: каждая «революция» в машинном обучении — это просто отложенный технический долг. Разделение экспертов по модальностям — элегантное решение, но в реальных условиях, когда данные поступают в хаотичном порядке, и инструкции перекрываются, сложность архитектуры, вероятно, станет узким местом. Успешная демонстрация на синтетических данных — это хорошо, но продукшен всегда найдёт способ сломать даже самую красивую теорию.
Ключевым вопросом остаётся масштабируемость. Увеличение числа модальностей и экспертов неизбежно приведёт к росту вычислительных затрат и усложнению обучения. Если код выглядит идеально — значит, его ещё никто не деплоил. В ближайшем будущем, вероятно, потребуется поиск более эффективных методов разделения и переиспользования знаний, возможно, с использованием техник сжатия моделей или дистилляции знаний.
И, конечно, не стоит забывать о фундаментальной проблеме: модели машинного обучения, по сути, являются сложными аппроксиматорами. Они хорошо имитируют поведение, но не обладают истинным пониманием. В конечном итоге, успех непрерывного обучения будет зависеть от того, насколько эффективно удастся преодолеть это ограничение.
Оригинал статьи: https://arxiv.org/pdf/2512.03125.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
2025-12-08 00:05