Автор: Денис Аветисян
Исследователи предлагают единую генеративную модель, способную объединить различные визуальные навыки и демонстрировать впечатляющие результаты в решении задач, даже без обширного обучения.

Предложена унифицированная генеративная парадигма для мультимодального рассуждения, обеспечивающая согласование восприятия и эффективное обучение с минимальной супервизией.
Несмотря на значительный прогресс в области мультимодальных больших языковых моделей, существующие подходы часто ограничены узкими задачами и не демонстрируют обобщенных навыков рассуждения. В данной работе, ‘Omni-R1: Towards the Unified Generative Paradigm for Multimodal Reasoning’, предложен унифицированный генеративный подход, использующий промежуточные изображения для выполнения разнообразных визуальных задач в процессе рассуждения. Модель Omni-R1, реализованная на базе SFT+RL фреймворка с механизмом выравнивания восприятия, демонстрирует высокую эффективность в широком спектре мультимодальных задач, а ее вариация Omni-R1-Zero, работающая без мультимодальных аннотаций, достигает сопоставимых и даже превосходящих результатов. Не является ли генеративное рассуждение новым перспективным направлением для создания по-настоящему интеллектуальных мультимодальных систем?
Понимание за Пределами Текста: Эволюция Мультимодального Рассуждения
Традиционные методы обработки естественного языка, несмотря на свою мощь и эффективность в работе с текстом, демонстрируют ограниченные возможности при решении задач, требующих понимания и анализа визуальной информации. Эти методы, ориентированные на обработку последовательностей слов, испытывают трудности при интерпретации изображений, видео и других нетекстовых данных, что препятствует их применению в сценариях, где необходимо сопоставление визуального контента с текстовой информацией. Например, в задачах, требующих ответа на вопросы по изображениям или понимания происходящего в видеоролике, традиционные модели часто уступают более сложным подходам, способным интегрировать визуальные и текстовые данные на более глубоком уровне. Неспособность эффективно использовать визуальную информацию ограничивает их применимость в областях, где визуальное восприятие играет ключевую роль, таких как робототехника, автономное вождение и медицинская диагностика.
Эффективное мультимодальное рассуждение становится ключевым фактором в развитии таких передовых приложений, как ответы на вопросы по изображениям и управление роботами. В задачах визуального вопрошания, система должна не просто распознать объекты на изображении, но и понять их взаимосвязи и контекст, чтобы дать точный ответ на поставленный вопрос. Аналогично, для успешного манипулирования роботом в реальном мире, необходимо объединить зрительное восприятие окружающей среды с логическим анализом и планированием действий. Без способности интегрировать и обрабатывать информацию из различных источников, таких как зрение и язык, роботы остаются ограниченными в своей способности адаптироваться к сложным и непредсказуемым ситуациям, а системы ответа на вопросы по изображениям не могут достичь уровня понимания, сравнимого с человеческим.
Существующие методы, основанные на текстовом анализе, безусловно, заложили прочный фундамент для развития искусственного интеллекта, однако они часто оказываются недостаточно эффективными при глубокой интеграции визуальной информации. Хотя такие подходы способны обрабатывать текстовые данные с высокой точностью, они испытывают трудности в понимании сложных взаимосвязей между текстом и изображениями, что ограничивает их возможности в задачах, требующих полноценного мультимодального рассуждения. Например, при анализе изображений с текстовыми описаниями, системы, полагающиеся преимущественно на текстовые данные, могут упустить важные детали, представленные визуально, или неправильно интерпретировать контекст, что приводит к неточным или неполным ответам. Таким образом, для достижения подлинно эффективного мультимодального ИИ необходимы новые подходы, способные не просто добавлять изображения к тексту, а полноценно объединять и анализировать информацию из разных источников.
Необходимость в едином подходе к мультимодальному рассуждению обусловлена ограничениями существующих методов, которые часто сводятся к простому добавлению визуальной информации к текстовым данным. Такой подход не позволяет в полной мере использовать взаимосвязь между различными модальностями, что препятствует достижению истинного понимания. Вместо этого, требуется создание архитектур, способных интегрировать визуальные и текстовые данные на более глубоком уровне, выявляя скрытые корреляции и формируя целостное представление о происходящем. Такая унификация позволит системам не просто отвечать на вопросы о картинках, но и рассуждать о них, делать выводы и адаптироваться к новым ситуациям, приближая искусственный интеллект к человеческому уровню восприятия и понимания.

Omni-R1: Унифицированный Фреймворк для Последовательного Рассуждения
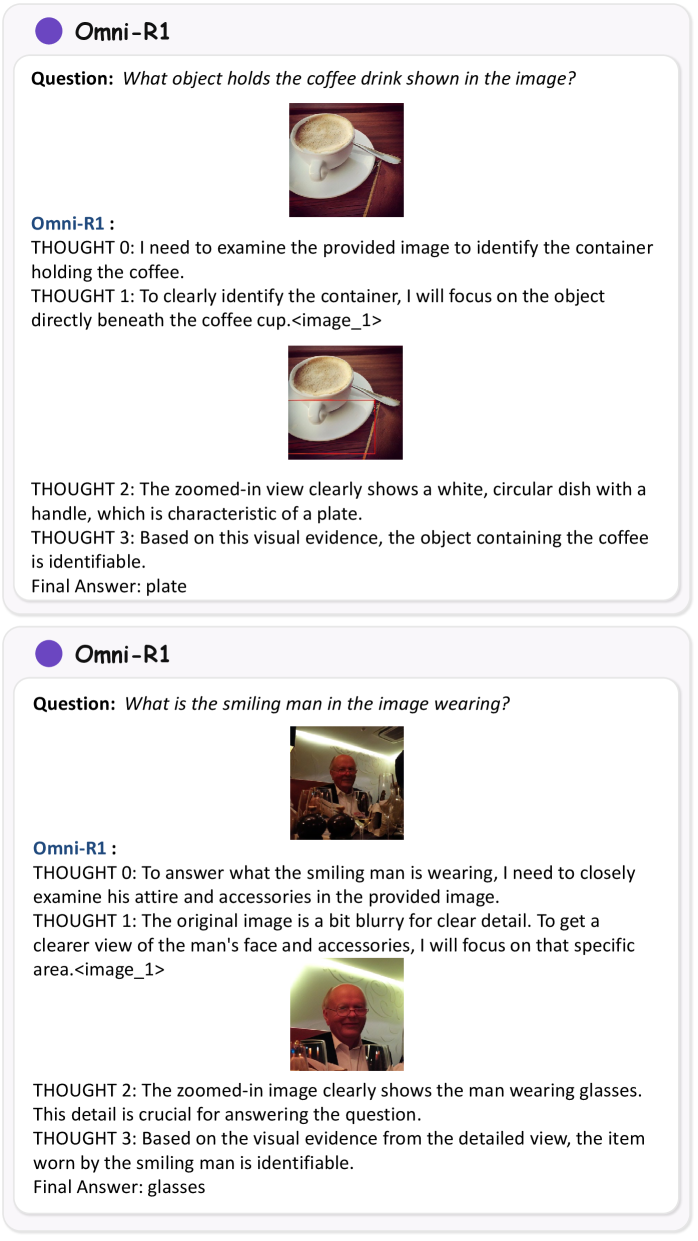
Фреймворк Omni-R1 представляет собой генеративную модель, объединяющую различные навыки мультимодального рассуждения в единую архитектуру. В отличие от традиционных подходов, требующих отдельных моделей для каждой задачи, Omni-R1 способен обрабатывать и интегрировать информацию из различных модальностей — таких как зрение и язык — для выполнения комплексных рассуждений. Это достигается за счет унифицированной структуры, позволяющей модели обмениваться информацией между различными модулями и применять общие принципы рассуждения к широкому спектру задач, включая визуальное вопросно-ответное взаимодействие, понимание инструкций и решение задач, требующих интеграции визуальной и текстовой информации.
В основе Omni-R1 лежит методика Perception-Aligned Supervised Fine-Tuning (PeSFT), предназначенная для начальной загрузки модели базовыми навыками рассуждения. PeSFT представляет собой процесс контролируемой тонкой настройки, в котором модель обучается на данных, содержащих как входные данные (например, изображения и текстовые вопросы), так и ожидаемые результаты рассуждений. Ключевым аспектом PeSFT является использование данных, тщательно отобранных и размеченных с учетом перцептивных особенностей, что позволяет модели установить начальную связь между визуальным восприятием и логическими выводами. Данный этап предварительной настройки существенно упрощает и ускоряет последующее обучение модели более сложным навыкам рассуждения и повышает ее общую эффективность.
Модель Omni-R1 совершенствуется посредством Perception-Calibrated Relative Policy Optimization (PeRPO), метода обучения с подкреплением, направленного на согласование визуального восприятия и логических выводов. PeRPO использует относительную политику оптимизации, где награда определяется не абсолютной правильностью ответа, а его соответствием визуальному контексту и задаче. Этот подход позволяет модели не просто генерировать правильные ответы, но и учитывать визуальную информацию при формировании логической цепочки рассуждений, что повышает надежность и согласованность результатов, особенно в задачах, требующих интерпретации визуальных данных.
Ключевым элементом обучения Omni-R1 является функция потерь согласования восприятия (Perception Alignment Loss), предназначенная для стабилизации генерации изображений в процессе обучения. Данная функция минимизирует расхождение между визуальными признаками, извлеченными из сгенерированных изображений, и ожидаемыми признаками, соответствующими функциональному назначению задачи. Это позволяет модели создавать визуально связные и функционально корректные изображения, предотвращая генерацию артефактов или нереалистичных элементов, которые могли бы повлиять на последующие этапы рассуждений и принятия решений. Согласование восприятия особенно важно для мультимодальных задач, где визуальная информация играет критическую роль в определении контекста и успешном выполнении задания.
![Обучение моделей Omni-R1 и Omni-R1-Zero включает два этапа: сначала выполняется контролируемая тонкая настройка ([PeSFT]) на основе ограниченных аннотаций или синтетических траекторий, а затем ([PeRPO]) политика уточняется с использованием унифицированных задач и составной награды, включающей точность, формат и восприятие.](https://arxiv.org/html/2601.09536v1/x3.png)
Подтверждение Эффективности: Оценка на Эталонных Наборах Данных
Оценка производительности Omni-R1 осуществляется с использованием Omni-Bench — эталонного набора данных, разработанного для всесторонней оценки возможностей мультимодального рассуждения. Omni-Bench включает в себя разнообразные задачи, требующие одновременной обработки и интеграции информации из различных модальностей, таких как текст и изображения. Эталон предназначен для объективной оценки способности модели к логическому выводу, решению проблем и пониманию сложных взаимосвязей между различными типами данных, что позволяет точно измерить её эффективность в задачах, требующих комплексного анализа.
В процессе PeRPO (Prompt-enhanced Reasoning and Planning Optimization) для повышения навыков рассуждения модели Omni-R1 используются специализированные наборы данных, такие как ArxivQA и Geometry3K. ArxivQA представляет собой набор вопросов и ответов, требующих понимания научных статей, что способствует развитию способности модели к анализу и синтезу информации из сложных текстовых источников. Geometry3K, в свою очередь, содержит геометрические задачи, требующие визуального и логического мышления для решения, что улучшает способность модели к пространственному рассуждению и решению задач, связанных с геометрией. Использование этих наборов данных позволяет модели более эффективно выполнять сложные задачи, требующие комбинации визуальной информации и логических выводов.
Фреймворк продемонстрировал выдающиеся результаты в различных задачах, достигнув передовых показателей на стандартных мультимодальных бенчмарках. В частности, были зафиксированы state-of-the-art результаты на MME (Multimodal Multiple-Choice Evaluation), MM-Vet (Multimodal Veterinary Question Answering), V*-Bench (Video-based Visual Question Answering Benchmark), POPE (Point-to-Object Parsing Evaluation), MMVP (Multimodal Visual Prompting) и BLINK (Beyond Language and Knowledge). Эти результаты подтверждают высокую эффективность предложенного подхода в обработке и понимании мультимодальных данных, превосходя существующие аналоги в задачах, требующих комплексного анализа визуальной и текстовой информации.
Для демонстрации возможностей модели в решении базовых задач компьютерного зрения использовался Uni-Skills, включающий в себя четыре ключевых теста: классификация изображений, обнаружение объектов, семантическая сегментация и оценка глубины. В ходе тестирования модель показала превосходство над базовыми решениями во всех четырех Uni-Tasks, что подтверждает ее способность эффективно выполнять широкий спектр визуальных задач и демонстрирует улучшенные показатели по сравнению с существующими подходами в данной области.
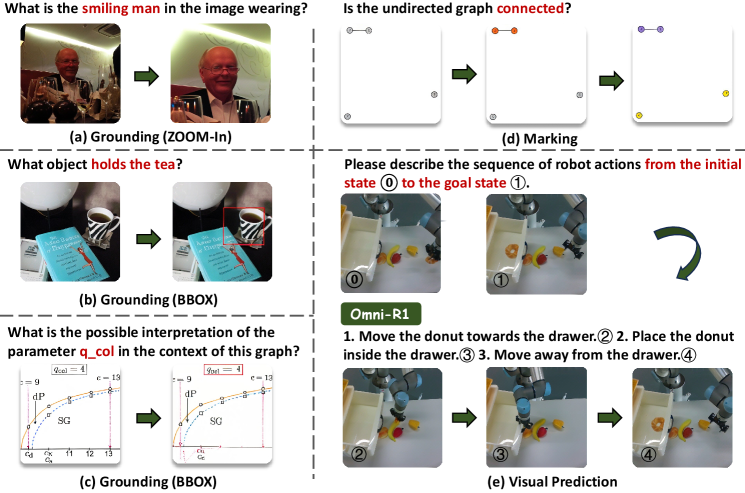
К Нулевому Рассуждению: Возможности Omni-R1-Zero
Omni-R1-Zero отказывается от необходимости в аннотациях для логических цепочек, требующих одновременной обработки нескольких модальностей данных (например, текста и изображений), благодаря использованию метода самообучения (bootstrapping). Вместо ручной разметки, система генерирует синтетические данные, основываясь на существующих текстовых рассуждениях типа Chain-of-Thought. Этот подход позволяет модели обучаться решению задач, требующих сопоставления различных типов данных, без предварительной необходимости в размеченных примерах, что существенно снижает затраты и упрощает процесс обучения.
Процесс создания синтетических данных в Omni-R1-Zero основан на методе последовательной визуализации с загрузкой (Bootstrapping Step-wise Visualization). Суть заключается в генерации данных для мультимодального рассуждения, исходя из текстовых цепочек рассуждений (Chain-of-Thought). Изначально используется только текстовая информация, на основе которой формируются этапы логического вывода. Затем, эти этапы используются для создания синтетических данных, содержащих как текст, так и визуальные элементы, имитирующие процесс рассуждения. Данный подход позволяет обойти необходимость в ручной аннотации данных для мультимодального рассуждения, используя текстовые рассуждения в качестве основы для генерации синтетических примеров.
В процессе обучения модели Omni-R1-Zero используется датасет M3CoT, содержащий 791 образец синтетических данных, имитирующих взаимодействие между текстом и визуальной информацией. Эти данные генерируются на основе логических цепочек рассуждений (Chain-of-Thought) и служат для инициации процесса самообучения (bootstrapping). Использование синтетических данных позволяет модели приобретать навыки мультимодального рассуждения без необходимости в размеченных примерах, что делает возможным обучение в режиме zero-shot, то есть способность решать задачи, для которых модель не получала прямых обучающих данных.
Снижение требований к аннотированию данных, обеспечиваемое Omni-R1-Zero, значительно расширяет возможности масштабирования и развертывания систем мультимодального рассуждения. Традиционно, создание таких систем требует больших объемов размеченных данных, что является дорогостоящим и трудоемким процессом. Уменьшение зависимости от ручной аннотации позволяет быстрее создавать и адаптировать модели к новым задачам и доменам, снижая затраты на разработку и обслуживание. Это особенно важно для приложений, требующих обработки разнообразных типов данных, таких как изображения, текст и звук, поскольку получение размеченных мультимодальных данных является сложной задачей. Упрощение процесса обучения также способствует более широкому распространению и внедрению мультимодальных систем в различных областях, включая робототехнику, автоматизированный анализ данных и системы поддержки принятия решений.
Исследование, представленное в данной работе, стремится к упрощению сложной задачи мультимодального рассуждения. Авторы предлагают унифицированный генеративный подход, где различные визуальные навыки интегрируются в единую модель. Этот акцент на ясности и объединении принципов находит отклик в словах Тима Бернерса-Ли: «Всегда ищите способ упростить». Подобно тому, как он стремился к упрощению доступа к информации в сети, данная работа демонстрирует, что эффективность достигается не за счет добавления сложности, а благодаря элегантной интеграции существующих возможностей и применению методов, таких как выравнивание восприятия, для достижения высокой производительности даже при ограниченном обучении.
Что дальше?
Предложенный подход к унифицированному генеративному моделированию, безусловно, элегантен в своей простоте. Однако, не стоит обольщаться иллюзией всеохватности. Способность модели к «нулевому обучению» — это не признак интеллекта, а скорее свидетельство умения ловко компилировать существующие знания. Истинная проверка ждёт впереди: как система справится с задачами, требующими не просто воспроизведения, а истинного понимания, с выходом за рамки предопределённых шаблонов?
Основное ограничение, как и всегда, — это данные. Даже самая изящная архитектура бессильна без качественных и репрезентативных обучающих примеров. Упор на выравнивание восприятия — шаг в верном направлении, но необходимо помнить: реальный мир гораздо сложнее и хаотичнее, чем аккуратно размеченные датасеты. Следующим этапом, вероятно, станет разработка методов, позволяющих модели самостоятельно извлекать знания из неструктурированных источников, минуя этап ручной аннотации.
И в конечном итоге, вопрос не в том, чтобы создать «универсальную» модель, способную решать все задачи сразу. Красота заключается в компрессии без потерь, а значит, необходимо сосредоточиться на создании специализированных систем, оптимизированных для конкретных целей. Унификация — это лишь инструмент, а не самоцель. Важнее — умение убрать лишнее, так, чтобы никто не заметил.
Оригинал статьи: https://arxiv.org/pdf/2601.09536.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-16 03:42