Автор: Денис Аветисян
Новая система NarraScore создает динамичные саундтреки к видео, подстраиваясь под развитие сюжета и эмоциональную окраску кадров.
Представлен фреймворк, использующий модели «зрение-язык» и аффективные вычисления для генерации длинных музыкальных композиций, синхронизированных с видеоконтентом.
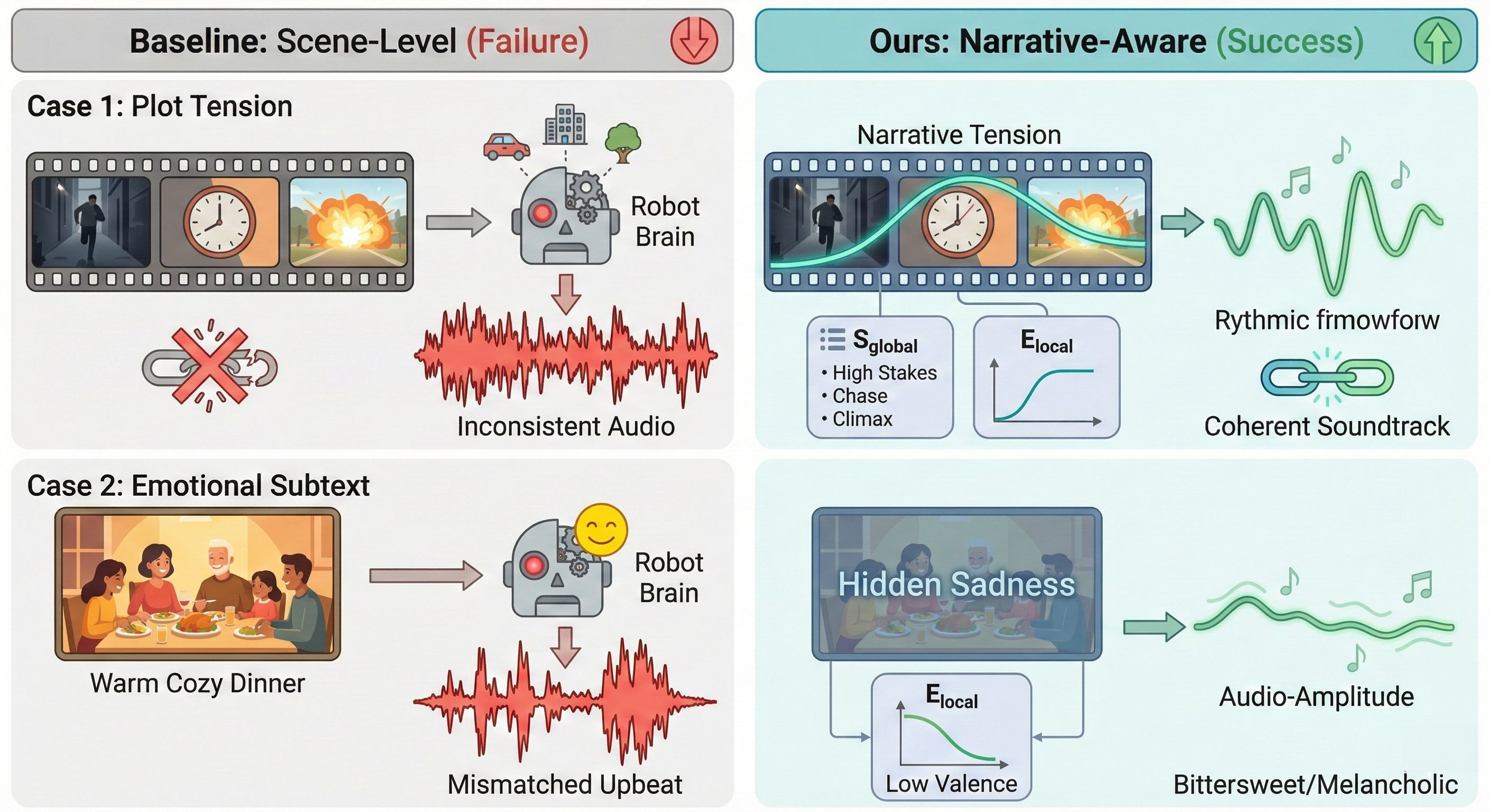
Создание связных музыкальных сопровождений для длинных видео остается сложной задачей, обусловленной проблемами масштабируемости, временной когерентности и, главное, недостаточным пониманием развития повествования. В данной работе, представленной под названием ‘NarraScore: Bridging Visual Narrative and Musical Dynamics via Hierarchical Affective Control’, предлагается инновационный фреймворк NarraScore, основанный на идее, что эмоции служат высокоплотным представлением логики повествования. Уникальным образом используя замороженные Визуально-Языковые Модели (VLM) в качестве сенсоров аффекта, NarraScore дистиллирует многомерные визуальные потоки в плотные траектории валентности-возбуждения, учитывающие нарратив. Способен ли этот подход открыть новую эру полностью автономного создания музыкального сопровождения для видеоконтента, динамически отражающего его эмоциональную и сюжетную составляющие?
Преодолевая Семантический Разрыв: Задача Видео-в-Музыку
Автоматическое создание музыкального сопровождения для видео, или задача видео-в-музыку, представляет собой сложную проблему, обусловленную трудностями сопоставления визуального повествования с эмоциональными звуковыми ландшафтами. Недостаточно просто синхронизировать звуки с происходящим на экране; истинный вызов заключается в том, чтобы музыка органично отражала и усиливала эмоциональную динамику видеоряда. Разработка алгоритмов, способных улавливать тонкие нюансы визуального повествования и преобразовывать их в соответствующие музыкальные фразы, требует глубокого понимания как визуальных, так и аудио-эстетических принципов. Эффективное решение данной задачи подразумевает создание музыки, которая не только сопровождает видео, но и активно участвует в формировании эмоционального опыта зрителя, создавая целостное и захватывающее впечатление.
Традиционные методы автоматической генерации музыки для видео зачастую сталкиваются с трудностями при улавливании тонких эмоциональных переходов, свойственных визуальному повествованию. В результате, создаваемые саундтреки нередко оказываются фрагментированными и лишенными глубины, не отражая в полной мере развитие сюжета и эмоциональное состояние зрителя. Существующие алгоритмы, ориентированные на простую синхронизацию звука с визуальными событиями, как правило, не способны уловить сложные нюансы, определяющие эмоциональную траекторию видео, что приводит к созданию музыкального сопровождения, не вызывающего должного эмоционального отклика и воспринимаемого как механическое дополнение к изображению.
Создание продолжительных музыкальных сопровождений к видеороликам требует не только синхронизации музыки с визуальными событиями, но и способности предвосхищать и отражать изменяющиеся эмоциональные состояния, представленные в видеоматериале. Исследования показывают, что простая привязка звука к конкретным действиям недостаточна для создания убедительного эмоционального отклика у зрителя. Успешные алгоритмы должны анализировать не только то, что происходит на экране, но и как это влияет на общее настроение видеоряда, учитывая такие факторы, как темп развития сюжета, визуальные метафоры и даже подтекст. Способность к прогнозированию эмоциональной дуги позволяет системе создавать музыкальные фразы, которые не просто реагируют на происходящее, но и создают атмосферу ожидания, напряжения или разрядки, значительно усиливая воздействие видеоконтента на аудиторию. В результате, музыкальное сопровождение становится не просто фоном, а полноценным участником повествования, способным глубоко резонировать с эмоциями зрителя.
Декодирование Визуальных Эмоций: Многомодальный Подход
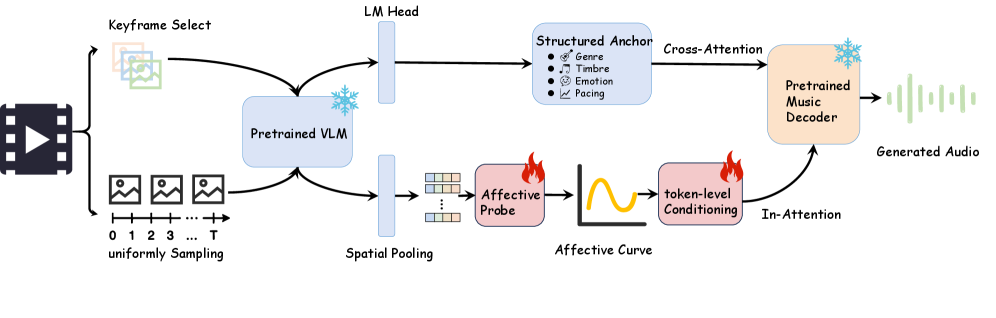
В рамках предлагаемой системы для анализа эмоциональной окраски видео используется потенциал видеo-языковых моделей, таких как VideoLlama. Эти модели позволяют извлекать богатые семантические признаки из видеопотока, идентифицируя ключевые моменты, характеризующиеся значимыми визуальными изменениями и контекстуальной информацией. Извлеченные признаки включают в себя объекты, действия, сцены и их взаимосвязи, что позволяет модели понимать содержание видео на более глубоком уровне. Идентификация ключевых моментов основана на анализе изменений в этих признаках, определяя фрагменты видео, наиболее важные для определения эмоционального состояния.
Легковесный Латентный Аффективный Декодер (Lightweight Latent Affective Decoder) анализирует семантические признаки, извлеченные из видео, для формирования Траектории Аффекта на уровне кадров. Этот процесс заключается в сопоставлении визуальных данных с эмоциональными категориями и представлении изменений эмоциональной окраски во времени в виде непрерывной последовательности. Каждый кадр видео получает векторное представление, отражающее преобладающую в данный момент эмоциональную составляющую, что позволяет отслеживать динамику эмоционального состояния на протяжении всего видеоряда и выявлять даже незначительные изменения в эмоциональной выразительности.
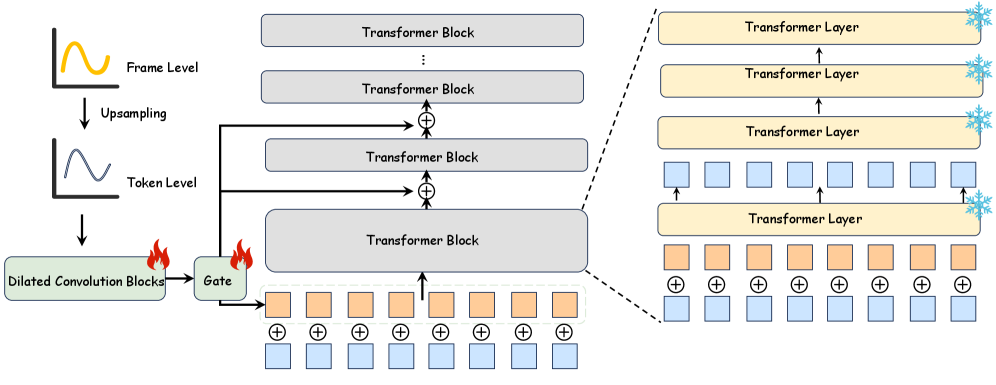
Для повышения точности построения траектории аффективных изменений во времени используются методы временного суперразрешения. Эти методы позволяют реконструировать высокочастотные компоненты сигнала, которые могут быть потеряны при стандартной обработке видео. В частности, применяется интерполяция между кадрами с использованием алгоритмов, учитывающих динамику визуальных признаков, что обеспечивает более детальное представление даже незначительных эмоциональных изменений. Реализация включает в себя модели, обученные на больших объемах данных, позволяющие точно восстанавливать промежуточные состояния и тем самым повышать разрешение временной шкалы аффективной траектории.
От Аффективной Траектории к Музыкальному Сопровождению
Для управления процессом генерации музыки используется адаптер аффективного воздействия на уровне токенов. Этот адаптер функционирует на основе двух измерений: валентности и возбуждения (Valence и Arousal), которые служат для количественной оценки эмоциональной окраски. Адаптер модулирует выходные данные базовой модели генерации музыки, обеспечивая соответствие сгенерированного аудио эмоциональным сигналам, извлеченным из входных данных. Изменение параметров адаптера, соответствующих значениям валентности и возбуждения, позволяет контролировать эмоциональную направленность и интенсивность генерируемой музыки, гарантируя ее соответствие желаемому эмоциональному профилю.
Адаптер использует механизм двойной инъекции (Dual-Branch Injection) для обеспечения согласованности музыкальной структуры на глобальном уровне и динамичности на локальном. Этот механизм позволяет одновременно учитывать общую композиционную логику и эмоциональные нюансы, задаваемые адаптером. Первая ветвь инъекции отвечает за поддержание глобальной когерентности, обеспечивая плавные переходы и логичную последовательность музыкальных фраз. Вторая ветвь обеспечивает локальную динамику, позволяя адаптировать музыкальные параметры — темп, громкость, инструменты — в соответствии с текущими эмоциональными сигналами. Такое сочетание обеспечивает генерацию музыки, которая одновременно является эмоционально выразительной и структурно цельной.
В основе генерации музыки используется модель MusicGen, выступающая в роли акустического ядра системы. MusicGen отвечает за непосредственное создание звукового сигнала, при этом его работа модулируется адаптером, анализирующим эмоциональную окраску входных данных. Адаптер, основанный на измерениях валентности и возбуждения, предоставляет MusicGen направляющие сигналы, позволяющие формировать музыкальное произведение, соответствующее заданным эмоциональным характеристикам. Таким образом, MusicGen обеспечивает реализацию акустической составляющей, а адаптер — эмоциональное наполнение генерируемого музыкального контента.
Масштабирование для Длинных Видео и Обеспечение Качества
Для эффективной обработки продолжительных видеоматериалов используется метод скользящего окна (Sliding Window Inference), позволяющий разбивать длинные последовательности на управляемые фрагменты для анализа и синтеза звукового сопровождения. Параллельно, для обеспечения согласованности между визуальным рядом и генерируемой музыкой, применяется ImageBind — модель, способная устанавливать связи между различными модальностями данных. Это позволяет системе не просто создавать звуковую дорожку, но и поддерживать ее соответствие происходящему на экране, даже в длинных видео, благодаря установлению прочных межмодальных соответствий и поддержанию семантической целостности на протяжении всей последовательности.
Система демонстрирует способность улавливать и сохранять глобальный семантический якорь видео, что позволяет поддерживать последовательную стилистическую идентичность на протяжении всей создаваемой звуковой дорожки. Это достигается за счёт анализа не только визуального ряда, но и понимания общего контекста и настроения видео, что позволяет генерировать музыку, гармонично сочетающуюся с происходящим на экране и сохраняющую единый художественный замысел. По сути, система не просто подбирает музыку к отдельным сценам, а создает звуковое сопровождение, которое служит продолжением визуального повествования и усиливает его эмоциональное воздействие, обеспечивая целостность восприятия.
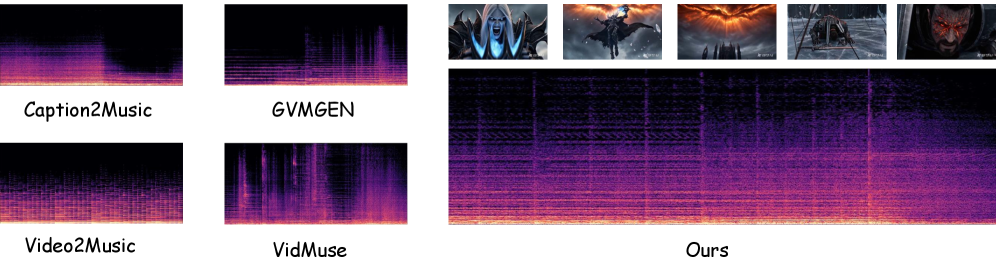
Количественная оценка с использованием метрик, таких как расстояние Фреше (Fréchet Audio Distance) и расхождение Кулбака-Лейблера, подтверждает высокую точность и качество генерируемых системой музыкальных сопровождений. Полученные результаты демонстрируют более низкие значения FAD, что указывает на большую реалистичность и соответствие сгенерированного звука исходному видеоряду, а также более высокие показатели ImageBind, свидетельствующие об улучшенной мультимодальной согласованности между визуальным и звуковым контентом. Данные метрики позволяют объективно сравнить эффективность разработанной системы с существующими подходами, подтверждая её превосходство в создании аутентичных и гармоничных музыкальных решений для видеоматериалов.
Будущее Иммерсивных Медиа: Эмоционально Интеллектуальные Саундтреки
Работа направлена на преодоление разрыва между визуальным повествованием и эмоциональным звучанием, что открывает новые возможности для создания более захватывающих и глубоких медиа-опытов. Исследователи разработали систему, способную анализировать видеоконтент и автоматически генерировать музыкальное сопровождение, точно соответствующее эмоциональной окраске сцен. Это позволяет не просто дополнить изображение звуком, а создать целостное, гармоничное восприятие, усиливающее эмоциональное воздействие на зрителя. Подобный подход имеет потенциал для революционных изменений в кинематографе, игровой индустрии и виртуальной реальности, где эмоциональная вовлеченность пользователя является ключевым фактором успеха.
Автоматическое создание музыкального сопровождения, соответствующего эмоциональному контексту визуального повествования, открывает широкие перспективы для различных сфер применения. В кинематографе и игровой индустрии это позволит значительно усилить эффект погружения, создавая более реалистичные и захватывающие впечатления. В виртуальной реальности эмоционально-адаптированная музыка способна формировать более глубокую связь между пользователем и цифровым миром, усиливая ощущение присутствия. Персонализированные развлекательные системы, использующие данную технологию, смогут адаптировать музыкальное сопровождение к индивидуальному эмоциональному состоянию зрителя или игрока, обеспечивая уникальный и более приятный опыт. Таким образом, автоматическое формирование эмоционально-согласованного саундтрека является ключевым шагом к созданию по-настоящему иммерсивных и адаптивных медиа-систем.
Дальнейшие исследования направлены на повышение эмоциональной детализации системы, позволяя ей более точно и нюансированно отражать широкий спектр чувств. Особое внимание уделяется разработке интерактивной музыки, способной динамически реагировать на действия и эмоциональное состояние пользователя. Предполагается, что такая система сможет не просто сопровождать происходящее, но и активно участвовать в формировании эмоционального опыта, создавая по-настоящему персонализированные и захватывающие медиа-окружения. В перспективе это откроет возможности для создания адаптивных саундтреков в фильмах, играх и виртуальной реальности, где музыка будет не просто фоном, а активным участником повествования, усиливающим эмоциональное воздействие на зрителя или игрока.
Представленная работа демонстрирует изящный подход к созданию музыкального сопровождения, динамически созвучного визуальному повествованию. Система NarraScore, подобно мудрой сущности, не стремится навязать эмоции, а скорее учится дышать в унисон с развитием сюжета. Как отметил Бертранд Рассел: «В конечном счете, все, что имеет значение, — это то, как мы проводим свое время». Подобно этому, система не столько генерирует музыку, сколько наполняет временное пространство видео смыслом и эмоциональной глубиной, подчеркивая ключевые моменты и создавая целостное восприятие. Управление аффективным состоянием, предложенное в данной работе, позволяет достичь гармонии между визуальным рядом и звуковым сопровождением, обеспечивая более глубокое погружение зрителя в повествование.
Куда Ведет Дорога?
Представленный подход, безусловно, демонстрирует возможность синхронизации звуковой дорожки с визуальным повествованием. Однако, иллюзия стабильности этой синхронизации, как и любой другой системы, ограничена временем. Задержка между визуальным стимулом и музыкальной реакцией, пусть и минимальная, остается неизбежным налогом каждого запроса, напоминанием о конечности ресурсов. Следующим шагом видится не столько улучшение точности соответствия, сколько исследование способов намеренного нарушения этой синхронизации, введение контролируемого диссонанса для усиления драматического эффекта или передачи подтекста.
Более фундаментальной проблемой остается субъективность аффекта. Любая попытка количественно оценить и воспроизвести эмоции неизбежно приводит к упрощению, к созданию карикатуры на истинное чувство. Вместо стремления к идеальной эмоциональной точности, возможно, стоит сосредоточиться на создании систем, способных к адаптации, к обучению на ошибках и к спонтанному выражению, пусть и несовершенному. Ведь любое произведение, чтобы оставаться значимым, должно нести в себе отпечаток энтропии.
В конечном итоге, задача не в создании идеального музыкального сопровождения к видео, а в разработке систем, способных к долгосрочному сосуществованию с человеческим восприятием, систем, которые стареют достойно, сохраняя способность удивлять и вызывать отклик даже после неизбежного ухудшения параметров. Иллюзия контроля над временем прекрасна, но истинная сила заключается в принятии его неумолимого течения.
Оригинал статьи: https://arxiv.org/pdf/2602.09070.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Искусственный интеллект на службе физики высоких энергий
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
- Квантовая неопределенность: новый взгляд на измерения
- Квантовые машины Больцмана для обучения с подкреплением: новый подход
- Квантовые Иллюзии и Практические Шаги
- Геном под контролем: Ускорение анализа данных для персонализированной медицины
- Вероятностный интеллект на скорости света: новые горизонты машинного обучения
2026-02-15 07:06