Автор: Денис Аветисян
Исследователи предлагают способ улучшить качество рассуждений искусственного интеллекта, фокусируясь не на ответах, а на самом процессе мышления.

Представлен MR-ALIGN – фреймворк, нацеленный на согласование процесса рассуждений больших языковых моделей для повышения их фактической точности, используя принципы мета-рассуждений и оптимизации, вдохновленные работами Канемана и Тверски.
Несмотря на впечатляющие возможности больших языковых моделей в сложном рассуждении, их способность к точным ответам на вопросы, требующие фактической проверки, остается ограниченной. В данной работе, ‘MR-Align: Meta-Reasoning Informed Factuality Alignment for Large Reasoning Models’, предложен новый подход к повышению достоверности ответов, фокусирующийся на выравнивании не просто конечного результата, а самого процесса рассуждения. MR-ALIGN определяет и корректирует вероятности переходов между состояниями в ходе логической цепочки, усиливая полезные паттерны и подавляя дефектные, что способствует повышению фактической корректности. Возможно ли, таким образом, существенно улучшить надежность больших моделей и снизить вероятность генерации вводящей в заблуждение информации?
Разрыв между Рассуждением и Результатом: Почему Модели Молчат
Несмотря на значительный прогресс в масштабировании языковых моделей, часто наблюдается так называемый “разрыв между рассуждениями и ответами”. Модели способны генерировать верные ответы в процессе внутреннего анализа, но последовательно выдавать их в качестве конечного результата им не удаётся. Данное несоответствие указывает на фундаментальное ограничение в способах обработки и выражения сложных этапов рассуждений. Модели могут “знать” ответ, но испытывают трудности с его коммуникацией.
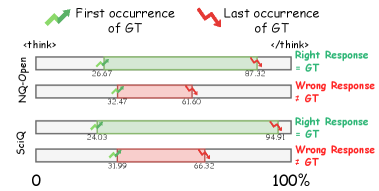
Традиционные методы, такие как Chain-of-Thought, демонстрируют лишь частичную эффективность. Это требует разработки более тонких архитектур, способных обеспечить связное представление этапов рассуждений. В конечном счёте, мы строим сложные системы, чтобы получать верные ответы, но забываем, что даже самая элегантная теория рухнет, если её нельзя воплотить в работающий продукт.
Мета-рассуждение: Моделирование Когнитивного Процесса
MR-ALIGN представляет собой мета-рассуждающую структуру, моделирующую переходы между когнитивными состояниями в процессе рассуждений. Данный подход выходит за рамки простого отображения «вход-выход», стремясь к более глубокому пониманию когнитивных процессов.
В основе структуры лежит представление рассуждений как последовательности «Атомарных Процессов Рассуждений». Такое разделение позволяет более точно зафиксировать нюансы сложного мышления и проследить логику принятия решений. Для навигации между состояниями используется «Матрица Переходов», определяющая вероятностные переходы между атомарными шагами. Такой подход обеспечивает гибкость и адаптивность, позволяя модели учитывать контекст и неопределенность.

Вероятностная природа матрицы переходов позволяет учитывать различные варианты интерпретации информации.
Согласование Предпочтений: Человеческий Фактор в Оценке Ответов
MR-ALIGN использует техники «Согласования предпочтений» для обеспечения соответствия ответов человеческим суждениям. В основе лежит применение методов, таких как «Прямая оптимизация предпочтений», позволяющих напрямую учитывать обратную связь от человека при обучении модели.
Ключевым нововведением является включение «Потерь, учитывающих человеческий фактор» – функций потерь, оценивающих ответы относительно базового уровня, отражая человеческое восприятие выигрыша или проигрыша. Это позволяет модели генерировать не только технически верные, но и интуитивно понятные ответы. Дальнейшее улучшение достигается за счет «Оптимизации по Каннеману-Тверски», использующей принципы теории перспектив для моделирования человеческой оценки результатов.
Валидация и Разнообразие Данных: Проверка на Прочность
В рамках оценки MR-ALIGN использовались различные наборы данных, включая NQ-Open и SciQ. Результаты демонстрируют способность системы к обобщению знаний и эффективной работе с разнообразными типами вопросов, что свидетельствует о её высокой адаптивности и потенциале для решения широкого спектра задач.
Архитектура MR-ALIGN предполагает использование нескольких языковых моделей, в числе которых GPT-5, DeepSeek-chat и GPT-4o, в качестве аннотаторов. Такой подход обеспечивает получение надежных и непредвзятых данных о предпочтениях, что критически важно для обучения и повышения точности системы. Как показано в Таблице 2, MR-ALIGN достигает лучших результатов среди методов, не использующих поиск, на нескольких наборах данных и демонстрирует конкурентоспособные показатели в сравнении с вариантами, дополненными поисковыми механизмами.

Применение Open-Vocabulary Descriptors позволяет более гибко и нюансированно выражать шаги рассуждений, что улучшает качество генерируемых объяснений. Каждая «революционная» технология завтра станет техдолгом.
Работа над MR-ALIGN, как и большинство проектов, демонстрирует закономерность: элегантная теория мета-рассуждений сталкивается с суровой реальностью практической реализации. Авторы стремятся оптимизировать не просто предсказания модели, а сам процесс рассуждений, фокусируясь на мета-состояниях и переходах. Это напоминает попытку построить идеальный мост, не учитывая при этом свойства грунта. Блез Паскаль однажды заметил: «Все проблемы человечества происходят от того, что люди не могут спокойно сидеть в одной комнате». В контексте MR-ALIGN, это можно интерпретировать как сложность согласования различных компонентов системы и обеспечения их стабильной работы. Идея оптимизации ‘как’ модель рассуждает, а не ‘что’ она предсказывает, кажется логичной, но, как показывает опыт, даже самые продуманные алгоритмы нуждаются в постоянной адаптации и патчинге. В конечном итоге, система либо стабильно падает, либо требует постоянного внимания – и в обоих случаях, она хотя бы последовательна.
Что Дальше?
Представленный подход, фокусирующийся на выравнивании не содержания, а процесса рассуждений, выглядит… любопытно. Всё, конечно, красиво ложится на теорию Канемана-Тверски, но опыт подсказывает: каждое элегантное решение порождает новый, более изощрённый класс ошибок. Пока модель оптимизирует “как” она думает, реальный мир найдёт способ сломать эту оптимизацию, представив ситуацию, где даже идеально выстроенная логика приводит к абсурдным результатам. Это, впрочем, и ожидаемо.
Настоящий вызов — не в улучшении мета-рассуждений как таковых, а в создании систем, способных диагностировать собственную некомпетентность. Модели, которые признают, что “здесь что-то не так”, и отказываются от принятия решения, а не упорно следуют ошибочной логике. Это, разумеется, потребует отхода от текущей парадигмы “больше параметров — лучше результат”.
В конечном итоге, вся эта работа — лишь ещё один шаг на пути к созданию иллюзии разумности. Иллюзии, которую продакшен, несомненно, рано или поздно развеет. Но разве это нас когда-либо останавливало? Мы не чиним продакшен — мы просто продлеваем его страдания.
Оригинал статьи: https://arxiv.org/pdf/2510.24794.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2025-11-04 22:20