Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий языковым моделям формировать и использовать скрытые представления для более эффективного решения сложных задач.
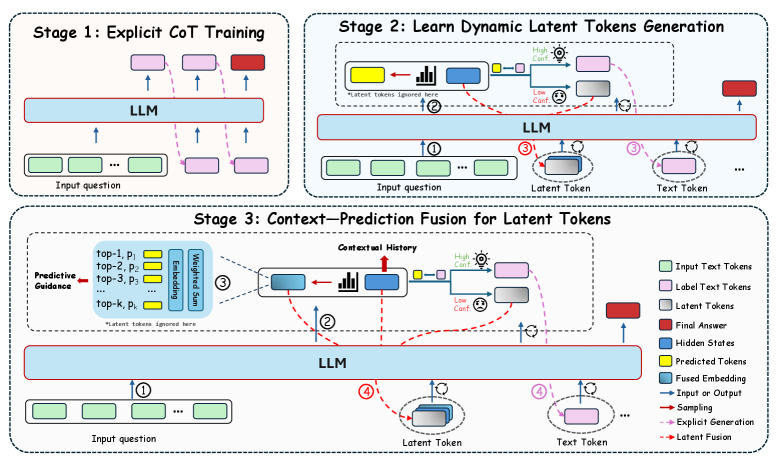
В статье представлен фреймворк Latent Thoughts Tuning (LT-Tuning), объединяющий контекст и рассуждения через слияние информации в скрытых токенах и обучение на основе уверенности, что позволяет преодолеть ограничения существующих подходов, такие как коллапс признаков и расхождение распределений.
Несмотря на эффективность явного рассуждения посредством цепочки мыслей (Chain-of-Thought), оно ограничивает большие языковые модели дискретным пространством токенов. В данной работе, посвященной ‘Latent Thoughts Tuning: Bridging Context and Reasoning with Fused Information in Latent Tokens’, предложен фреймворк LT-Tuning, использующий непрерывное латентное пространство для более гибкого и устойчивого рассуждения. Метод основан на механизме объединения контекста и предсказаний, что позволяет динамически переключаться между латентными и явными режимами мышления, эффективно решая проблему коллапса признаков. Сможет ли подобный подход значительно расширить возможности языковых моделей в решении сложных задач, требующих глубокого логического анализа?
Пределы Явного Рассуждения: Цена Чёткости
Традиционные методы рассуждений, такие как «Цепочка мыслей» (Chain-of-Thought), основываются на явной генерации текста, что создает значительные вычислительные затраты и повышает вероятность ошибок по мере углубления процесса рассуждений. Каждая ступень логической цепочки требует генерации нового текста, что экспоненциально увеличивает объем необходимых вычислений и потребляемых ресурсов. Более того, этот процесс становится особенно уязвимым к ошибкам: даже незначительная неточность на одной из стадий может привести к искажению всего результата. В результате, масштабирование подобных методов сталкивается с серьезными ограничениями при решении сложных задач, что стимулирует поиск более эффективных парадигм рассуждений, способных обойти эти вычислительные и логические препятствия.
По мере увеличения масштаба методов, основанных на явном рассуждении, таких как последовательность мыслей, выявляются существенные ограничения в решении сложных задач. Увеличение глубины рассуждений приводит к экспоненциальному росту вычислительных затрат и повышает вероятность ошибок, что делает подход неэффективным для проблем, требующих многоступенчатого анализа. Это стимулирует поиск альтернативных парадигм рассуждения, направленных на повышение эффективности и масштабируемости, включая методы, использующие неявные знания и ассоциативные связи для достижения более оптимальных результатов при решении сложных задач. Исследования в этой области сосредоточены на разработке систем, способных к более компактному и быстрому рассуждению, сохраняя при этом высокую точность и надежность.
Явное рассуждение, несмотря на свою кажущуюся прозрачность, часто сталкивается с проблемами применимости к новым, незнакомым данным. Это связано с явлениями несоответствия распределений и коллапса признаков, когда модель, обученная на определенном наборе данных, теряет способность обобщать полученные знания. Несоответствие распределений возникает, когда тестовые данные значительно отличаются от данных, использованных при обучении, приводя к снижению точности. Коллапс признаков, в свою очередь, характеризуется потерей различительной способности признаков, что затрудняет классификацию и прогнозирование. В результате, модель, демонстрирующая высокие показатели на обучающей выборке, может оказаться неэффективной при работе с данными, выходящими за рамки ее первоначального опыта, что ограничивает ее практическую применимость и требует разработки более устойчивых методов рассуждения.
Латентное Рассуждение: Новый Взгляд на Интеллект
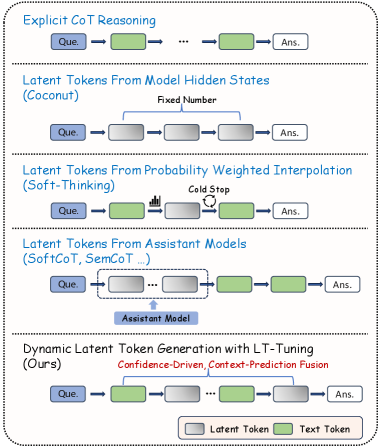
Латентное рассуждение представляет собой подход к решению задач, основанный на выполнении вычислений в непрерывных латентных пространствах. В отличие от традиционных методов, оперирующих с дискретными текстовыми представлениями, латентное рассуждение позволяет обрабатывать информацию в виде векторов в многомерном пространстве. Это обеспечивает значительные преимущества с точки зрения эффективности, поскольку операции над векторами могут выполняться параллельно и требуют меньше вычислительных ресурсов. Кроме того, непрерывность латентного пространства способствует повышению устойчивости к шуму и вариациям входных данных, обеспечивая более надежные результаты даже при неполной или неточной информации. Такой подход позволяет моделировать сложные взаимосвязи и зависимости между элементами данных, что особенно важно для решения задач, требующих абстрактного мышления и обобщения.
Методы, такие как Coconut и Soft-Thinking, развивают концепцию вычислений в скрытых пространствах, осуществляя рассуждения непосредственно на основе скрытых состояний языковой модели. В отличие от традиционных подходов, требующих явной генерации текста на каждом шаге рассуждения, Coconut и Soft-Thinking манипулируют этими внутренними представлениями, что позволяет значительно повысить эффективность и снизить вычислительные затраты. Это достигается за счет использования операций над векторами скрытых состояний, что позволяет модели выполнять логические выводы и извлекать информацию без необходимости генерировать промежуточные текстовые фрагменты. Такой подход особенно полезен при решении задач, требующих сложных рассуждений и обработки большого объема информации.
В отличие от традиционных подходов, основанных на явной генерации текста для представления промежуточных этапов рассуждений, метод скрытого (латентного) рассуждения обходит ограничения, связанные с дискретностью и вычислительной сложностью текстовых моделей. Избегая необходимости последовательного создания и обработки текстовых токенов, этот подход позволяет оперировать непосредственно в непрерывном латентном пространстве, что потенциально обеспечивает более эффективное и тонкое моделирование сложных когнитивных процессов и, как следствие, возможность решения задач, требующих более глубокого понимания и анализа информации, чем это возможно при использовании исключительно текстовых представлений.
LT-Tuning: Динамическое Переплетение Мысли и Текста
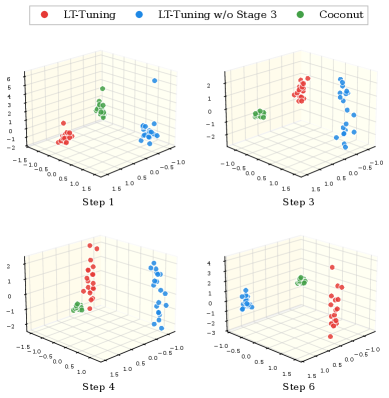
Метод LT-Tuning (Latent Thoughts Tuning) представляет собой новый подход к интеграции скрытых (латентных) рассуждений с явной генерацией текста. В отличие от традиционных методов, где рассуждения и генерация текста выполняются последовательно, LT-Tuning позволяет динамически переключаться между этими процессами. Это достигается за счет использования скрытых токенов, которые представляют собой промежуточные рассуждения, и их бесшовного включения в процесс генерации текста, что позволяет модели одновременно использовать как явные знания, представленные в тексте, так и скрытые рассуждения для повышения точности и эффективности генерации.
Механизм Context-Prediction Fusion в LT-Tuning создает динамические латентные токены путем комбинирования контекстуальных скрытых состояний с предсказательными семантическими ориентирами. Этот процесс позволяет модели учитывать как текущий контекст входных данных, представленный в скрытых состояниях, так и предсказуемые семантические связи, направляющие процесс рассуждения. В результате формируются латентные токены, которые отражают не только непосредственный контекст, но и более глубокое понимание задачи, улучшая качество генерируемых ответов и повышая точность рассуждений.
Механизм Confidence-Driven Insertion обеспечивает динамическое переключение между генерацией текста и латентным рассуждением, оптимизируя эффективность и точность модели. Этот подход основан на оценке уверенности модели в текущем контексте; когда уверенность в продолжении генерации текста снижается, происходит переключение на латентное рассуждение для более глубокого анализа и поиска решения. После получения результата латентного рассуждения, модель возвращается к генерации текста. Такое адаптивное переключение позволяет избежать неточностей, возникающих при чрезмерном использовании одного из подходов, и максимизировать общую производительность системы.
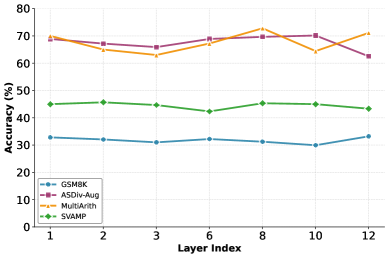
Эксперименты, проведенные с использованием моделей Llama-3.2-1B, Llama-3.2-3B и Llama-3.1-8B, продемонстрировали эффективность LT-Tuning на бенчмарке GSM8K, специализирующемся на задачах математического рассуждения. В ходе тестирования наблюдалось среднее увеличение точности на 4.3% при использовании данной методики. В частности, модель 8B достигла точности 68.8%, а модель 1B — 36.4%, в то время как модель 3B показала результат в 52.4%. Использование адаптерного слоя позволило увеличить точность модели 8B до 70.3%.
В ходе экспериментов с использованием моделей Llama-3.2-1B, Llama-3.2-3B и Llama-3.1-8B, фреймворк LT-Tuning продемонстрировал следующие результаты точности на бенчмарке GSM8K: модель 8B достигла точности 68.8%, модель 1B — 36.4%, а модель 3B — 52.4%. Дополнительное использование адаптерного слоя позволило повысить точность модели 8B до 70.3%.
Расширяя Горизонты: Адаптация и Будущие Исследования
Предлагаемая схема может быть значительно усилена за счет интеграции адаптерных модулей, что позволяет эффективно смягчать последствия расхождений в распределении данных и, как следствие, повышать обобщающую способность модели. Эти модули, не прибегая к совместному использованию параметров, предоставляют более тонкий контроль над процессом обучения и позволяют модели адаптироваться к новым, ранее не встречавшимся данным, избегая проблем, связанных с жесткой привязкой весов. В результате, модель демонстрирует повышенную устойчивость к изменениям в данных и улучшенную производительность при работе с разнообразными задачами, требующими высокой степени адаптивности и обобщения.
Модули-адаптеры, избегая совместного использования параметров, позволяют преодолеть ограничения, связанные с общими весами в традиционных моделях. Такой подход обеспечивает более детальный контроль над процессом адаптации к новым данным и задачам, поскольку каждый модуль может независимо оптимизировать свои параметры. Это особенно важно при работе с данными, отличающимися от тех, на которых модель была изначально обучена, поскольку позволяет избежать нежелательного переноса знаний и повысить эффективность обучения. Вместо того чтобы полагаться на единый набор весов, разделяемый всеми задачами, модули-адаптеры предоставляют возможность тонкой настройки для каждой конкретной ситуации, что приводит к более устойчивым и точным результатам.
Динамические латентные токены представляют собой инновационный подход к оптимизации вычислительных процессов в нейронных сетях. Данная методика позволяет модели адаптироваться к различным задачам, гибко переключаясь между явным и латентным вычислением. В отличие от традиционных методов, где вычислительные ресурсы распределяются статически, система с динамическими токенами способна динамически определять, какие части вычислений следует выполнять явно, а какие — скрыто, в латентном пространстве. Это обеспечивает более эффективное использование ресурсов и позволяет добиться повышения производительности при решении разнообразных задач, требующих разного уровня вычислительной сложности и детализации. Такой подход позволяет модели не только быстрее обрабатывать данные, но и улучшать качество результатов, подстраиваясь под специфику каждой конкретной задачи.
Перспективные исследования направлены на расширение возможностей LT-Tuning путем применения к моделям еще большего масштаба. Особое внимание уделяется адаптации данной методики для решения сложных задач, требующих продвинутых навыков рассуждения и логического мышления. Предполагается, что увеличение размера модели в сочетании с тонкой настройкой с использованием динамических латентных токенов позволит достичь качественно нового уровня производительности в задачах, где ранее возникали трудности с обобщением и интерпретацией информации. Дальнейшая работа будет сосредоточена на изучении возможностей адаптации LT-Tuning к различным архитектурам нейронных сетей и оптимизации процесса обучения для достижения максимальной эффективности в решении широкого спектра когнитивных задач.

Исследование демонстрирует стремление к взлому системы познания, подобно вскрытию сложного механизма. Авторы предлагают метод LT-Tuning, который, подобно тонкой настройке инструментов, позволяет языковым моделям оперировать в скрытом пространстве, динамически адаптируясь к контексту. Этот подход, основанный на слиянии предсказаний и уверенном обучении, направлен на преодоление ограничений существующих методов, таких как коллапс признаков. Как заметил Марвин Минский: «Лучший способ понять — это создать». Создание LT-Tuning — это и есть попытка создать более совершенную систему рассуждений, позволяющую моделям не просто обрабатывать информацию, но и понимать её глубинную структуру.
Что дальше?
Представленный подход, манипулируя латентным пространством и объединяя предсказания контекста, несомненно, открывает новые пути для улучшения рассуждений больших языковых моделей. Однако, возникает вопрос: а что, если кажущийся «коллапс признаков» — это не ошибка реализации, а закономерность, отражающая фундаментальные ограничения самой архитектуры? Возможно, проблема не в тонкой настройке латентных токенов, а в самой идее представления знаний в дискретном, символьном виде.
Перспективы дальнейших исследований, вероятно, лежат в исследовании динамики латентного пространства. Вместо того, чтобы просто «настраивать» его, стоит задуматься о способах активного формирования этого пространства, возможно, используя принципы самоорганизации или вдохновляясь нейронными сетями с импульсной активностью. Ключевым моментом представляется разработка метрик, способных улавливать не просто «правильность» ответа, но и степень «уверенности» модели в его обоснованности — ведь даже ошибочные выводы могут быть информативны, если они сопровождаются признанием собственной неопределенности.
И, конечно, необходимо помнить о практической стороне вопроса. Эффективность представленного метода должна быть подтверждена на широком спектре задач и данных, а также оценена с точки зрения вычислительных затрат и возможности масштабирования. В конечном итоге, ценность любой теории определяется её способностью предсказывать и объяснять реальные явления, а не просто создавать иллюзию понимания.
Оригинал статьи: https://arxiv.org/pdf/2602.10229.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
- Симуляция, которая видит себя: новый подход к физическому моделированию
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
- Моделирование кровотока мозга: новый взгляд на скорость и точность
- Favia: Искусственный интеллект на страже безопасности кода
2026-02-13 01:26