Автор: Денис Аветисян
Новое исследование углубленно анализирует метод Мюон и другие подходы к спектральной оптимизации, выявляя его сильные и слабые стороны.
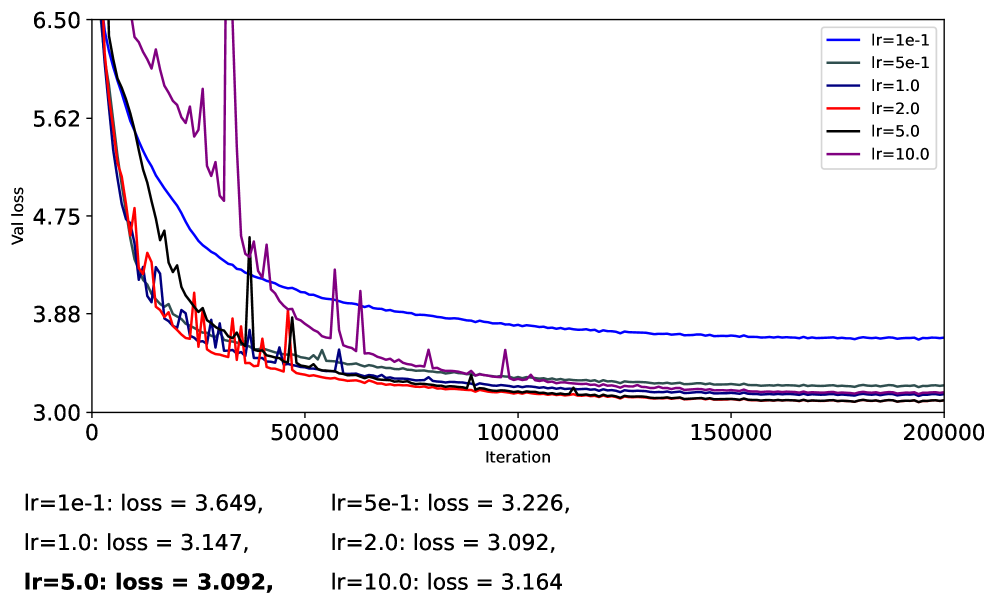
Анализ показывает, что, несмотря на стабилизирующий эффект, Мюон не всегда превосходит классические алгоритмы, такие как Adam, а частичная спектральная компрессия может обеспечить оптимальное сочетание стабильности и производительности.
Несмотря на впечатляющую эмпирическую производительность, механизмы оптимизатора Muon и его связь с адаптивными методами, такими как Adam, остаются недостаточно изученными. В работе ‘Delving into Muon and Beyond: Deep Analysis and Extensions’ предложен унифицированный спектральный подход, рассматривающий Muon как частный случай семейства спектральных преобразований, применяемых к обновлениям градиента. Показано, что нормализация на основе среднеквадратичного значения обеспечивает более стабильную оптимизацию, однако Muon не демонстрирует последовательного превосходства над Adam, а частичная спектральная компрессия может представлять собой более эффективный баланс между стабильностью и производительностью. Какие перспективы открываются для разработки новых спектральных методов оптимизации, способных превзойти существующие подходы в задачах глубокого обучения?
Масштабируемость и вызовы современных языковых моделей
Современные языковые модели, такие как nanoGPT, демонстрируют впечатляющие результаты в генерации и понимании текста, однако их обучение требует колоссальных объемов данных и вычислительных ресурсов. Для достижения высокого уровня производительности модели необходимо обрабатывать терабайты текстовой информации, например, из набора данных OpenWebText, что подразумевает использование мощных вычислительных кластеров и значительные затраты энергии. Такая зависимость от масштабных ресурсов ставит под вопрос возможность широкого распространения и применения этих моделей, особенно для исследователей и организаций с ограниченными ресурсами. Более того, сбор и обработка таких больших наборов данных сопряжены с этическими проблемами, связанными с авторскими правами и конфиденциальностью данных.
Современные языковые модели, несмотря на впечатляющие результаты, сталкиваются с серьезными трудностями при обучении из-за огромного количества параметров. Традиционные методы оптимизации, такие как стохастический градиентный спуск (SGD), оказываются неэффективными при навигации в этих многомерных пространствах параметров. Проблема заключается в том, что каждый шаг оптимизации требует обработки огромного объема данных и вычислений, что приводит к замедлению обучения и увеличению требуемых вычислительных ресурсов. По сути, алгоритм «теряется» в сложности пространства, и поиск оптимальных значений параметров становится крайне трудоемким и затратным процессом, ограничивающим масштабируемость и устойчивость современных подходов к обучению языковых моделей. Поиск более эффективных алгоритмов оптимизации является ключевой задачей для дальнейшего развития этой области.
Неэффективность существующих методов оптимизации при обучении современных языковых моделей ставит под вопрос их устойчивое развитие и масштабируемость. Обучение моделей, требующих колоссальных вычислительных ресурсов и огромных объемов данных, становится все более затратным и экологически неблагоприятным. По мере увеличения размеров моделей и сложности задач, традиционные алгоритмы, такие как стохастический градиентный спуск, сталкиваются с трудностями в эффективном исследовании многомерного пространства параметров. Это приводит к замедлению обучения, увеличению энергопотребления и, в конечном итоге, ограничивает возможности дальнейшего прогресса в области обработки естественного языка. Поиск более эффективных и устойчивых методов обучения становится критически важной задачей для обеспечения долгосрочной жизнеспособности и широкого распространения мощных языковых моделей.
Адаптивные стратегии оптимизации: за пределами градиентного спуска
Алгоритмы, такие как Adam и RMSprop, представляют собой усовершенствования базового стохастического градиентного спуска (SGD) за счет адаптивной настройки скорости обучения для каждого параметра модели. В основе этих методов лежат концепции First-Moment Updates (использование экспоненциально взвешенного среднего градиентов для оценки направления движения) и RMS-Normalized Updates (нормализация градиентов по экспоненциально взвешенному среднему квадратов градиентов для масштабирования скорости обучения). First-Moment Updates позволяют учитывать историю градиентов, что способствует более быстрому движению в направлении минимума, а RMS-Normalized Updates позволяют адаптировать скорость обучения для каждого параметра в зависимости от величины его градиентов, что особенно полезно при работе с разреженными градиентами или параметрами с разными масштабами. \hat{m}_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t представляет собой First-Moment Update, где g_t — градиент, а \beta_1 — коэффициент затухания. \hat{v}_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 — RMS-Normalized Update, где \beta_2 — коэффициент затухания.
Методы адаптивной оптимизации, такие как Adam и RMSprop, демонстрируют ускорение обучения и улучшение сходимости по сравнению со стандартным стохастическим градиентным спуском. Однако, несмотря на свою эффективность, эти алгоритмы по-прежнему оперируют со скалярными параметрами и испытывают трудности в оптимизации функций в высокоразмерных пространствах, характеризующихся сложными ландшафтами с множеством локальных минимумов и седловых точек. Это связано с тем, что адаптация скорости обучения происходит индивидуально для каждого параметра, но не учитывает глобальную структуру пространства параметров и потенциальные корреляции между ними, что может приводить к замедлению сходимости или даже застреванию в неоптимальных точках.
Регуляризация весов, или Weight Decay, является распространенной техникой, используемой в обучении нейронных сетей для предотвращения переобучения и повышения обобщающей способности модели. Данный метод заключается в добавлении к функции потерь штрафа, пропорционального сумме квадратов весов сети. Этот штраф заставляет алгоритм обучения стремиться к уменьшению величины весов, что способствует упрощению модели и снижению ее чувствительности к шуму в обучающих данных. Эффективность регуляризации весов проявляется особенно ярко при работе с небольшими наборами данных или при наличии большого количества параметров в модели. Коэффициент регуляризации, определяющий силу штрафа, является гиперпараметром, который необходимо настраивать для достижения оптимальной производительности.
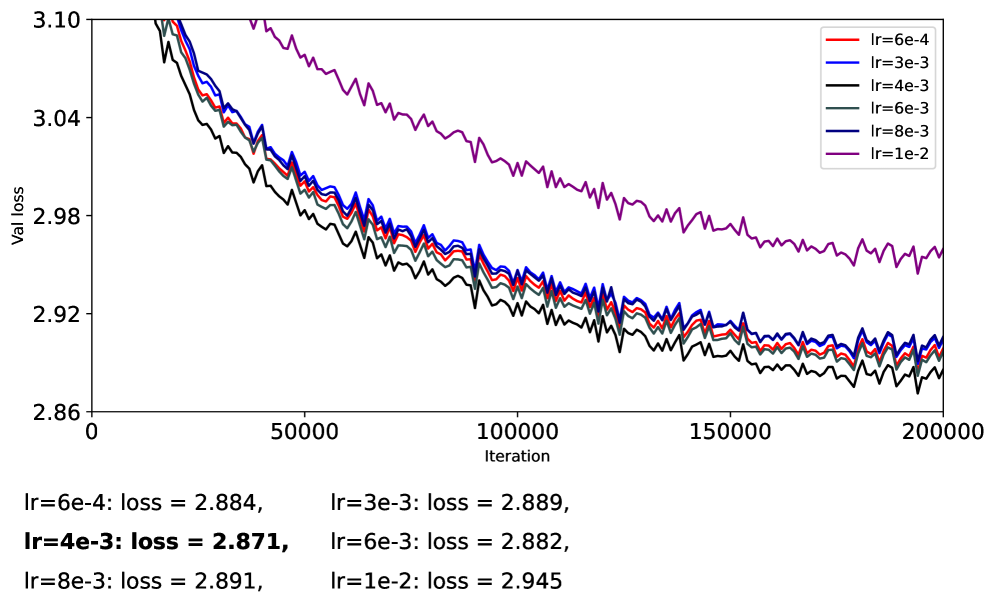
Матричная оптимизация: новый взгляд на проблему
Оптимизаторы, основанные на матричной работе, такие как Muon, отличаются от традиционных методов тем, что оперируют непосредственно с матрицей параметров модели, а не с индивидуальными скалярными градиентами. Вместо вычисления градиента для каждого параметра по отдельности, Muon рассматривает матрицу параметров как единое целое и применяет матричные операции для обновления. Это позволяет оптимизатору учитывать взаимосвязи между параметрами и потенциально улучшить процесс обучения, особенно в задачах с большим количеством параметров. Такой подход требует использования специализированных алгоритмов и вычислений, отличных от тех, что используются в оптимизаторах, основанных на градиентном спуске.
Оптимизатор Muon использует принципы спектральной компрессии и полярного разложения, полученные на основе сингулярного разложения (SVD), для обеспечения ортогональности и стабильности в процессе оптимизации. Сингулярное разложение позволяет разложить матрицу параметров модели на компоненты, что позволяет выявить и подавить доминирующие сингулярные числа, уменьшая тем самым условность матрицы и предотвращая взрыв или исчезновение градиентов. Полярное разложение, в свою очередь, позволяет выделить вращательную и масштабирующую компоненты матрицы, что способствует стабилизации процесса обучения за счет контроля над направлением обновления параметров. A = UPV^T — базовая формула сингулярного разложения, где A — исходная матрица, U и V — унитарные матрицы, а P — диагональная матрица сингулярных чисел.
Ключевым компонентом оптимизатора Muon является итерация Ньютона-Шульца, обеспечивающая эффективное вычисление необходимых матричных операций. Данный метод позволяет оптимизировать параметры модели путем непосредственной работы с матрицей параметров, а не со скалярными градиентами. Исследование показало, что, несмотря на стабилизацию оптимизации на основе импульса (momentum), Muon не демонстрирует превосходства над оптимизатором Adam в плане скорости сходимости и достигаемой точности. Итерация Ньютона-Шульца является итеративным методом для вычисления X в уравнении X^2 = A, где A — заданная матрица, и используется для обновления матрицы параметров модели в Muon.
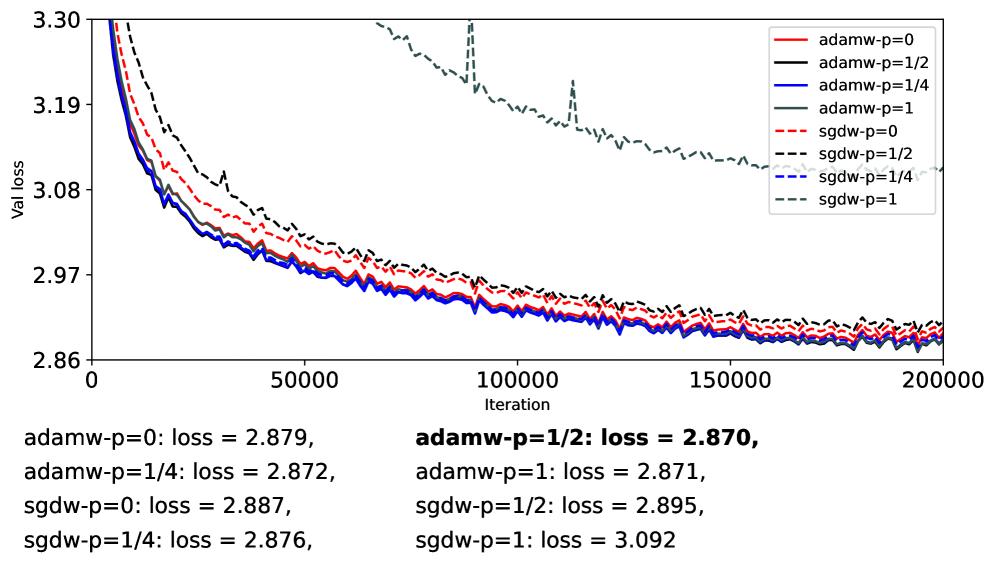
Влияние на масштабируемые и устойчивые языковые модели
Разработка оптимизаторов на основе матричной алгебры, таких как Muon, открывает перспективы для существенного снижения вычислительных затрат, связанных с обучением больших языковых моделей. Традиционные методы оптимизации часто требуют значительных ресурсов, ограничивая доступ к передовым технологиям обработки языка. Muon, манипулируя матрицами параметров модели, позволяет более эффективно использовать вычислительные мощности и, следовательно, делает обучение масштабных моделей более доступным для широкого круга исследователей и организаций. Это особенно важно в контексте постоянно растущих размеров и сложности современных языковых моделей, где даже незначительное снижение вычислительной нагрузки может привести к значительной экономии ресурсов и ускорению процесса разработки.
Методы оптимизации, такие как Muon, демонстрируют потенциал повышения стабильности и устойчивости процесса обучения больших языковых моделей за счет обеспечения ортогональности весов. Это достигается путем регулирования направления обновления параметров, что предотвращает резкие изменения и способствует более плавному спуску к минимуму функции потерь. Эксперименты показали, что Muon позволяет использовать значительно более высокую скорость обучения — до 7 \times 10^{-3} — по сравнению со стандартными алгоритмами, такими как Adam, без потери стабильности. Более высокая скорость обучения, в свою очередь, ускоряет сходимость и может приводить к улучшению обобщающей способности модели, позволяя ей лучше справляться с новыми, ранее не встречавшимися данными. Таким образом, обеспечение ортогональности представляет собой перспективный подход к созданию более надежных и эффективных языковых моделей.
Исследование выявило, что использование матричных оптимизаторов, таких как Muon, позволяет глубже понять структуру пространства параметров больших языковых моделей. Анализ спектральных свойств показал, что частичное сжатие (при p=1/4) уменьшает спектральную анизотропию, что свидетельствует об улучшении обусловленности задачи оптимизации. Однако, несмотря на теоретические преимущества, полученные результаты демонстрируют, что AdamS достигает сопоставимых с Adam конечных потерь при обучении, указывая на ограниченность выигрыша от полного спектрального сжатия. Таким образом, хотя понимание спектральных характеристик пространства параметров и предоставляет ценные сведения, практическая польза от их полного использования для снижения потерь представляется не столь значительной, как можно было предположить.
Исследование, представленное в данной работе, подчеркивает важность целостного подхода к оптимизации, что перекликается с идеями Бертрана Рассела. Он говорил: «Чем больше я изучаю мир, тем больше убеждаюсь в том, что он построен на принципах простоты и ясности». В контексте Muon и других методов спектральной оптимизации, представленная работа демонстрирует, что стабильность обучения не всегда гарантирует превосходство над устоявшимися алгоритмами, такими как Adam. Эффективность достигается не за счет сложности, а благодаря балансу между стабильностью и производительностью, особенно при частичном спектральном сжатии. Таким образом, структура оптимизационного процесса определяет его поведение, и простота является ключом к надежным результатам.
Куда Ведет Муон?
Наблюдаемая стабилизация обучения, обеспечиваемая методом Муон, представляется скорее симптомом, нежели лекарством. Устойчивость системы не возникает из добавления сложности, а из четкого понимания ее границ и взаимодействия компонентов. Поиск оптимального алгоритма оптимизации, вероятно, требует отказа от универсальных решений в пользу более тонкой настройки, учитывающей специфику решаемой задачи и структуру данных. Успешная компрессия спектральных характеристик указывает на возможность упрощения без потери эффективности — экономное решение, которое, как ни странно, часто упускается из виду в погоне за вычислительной мощью.
Очевидным направлением для дальнейших исследований является изучение влияния различных форм спектральной компрессии на обобщающую способность моделей. Вопрос о том, как наиболее эффективно связать стабильность обучения с производительностью, остается открытым. Необходимо учитывать, что алгоритм, хорошо работающий в одном контексте, может оказаться неэффективным в другом. Требуется более глубокое понимание взаимосвязи между геометрией пространства параметров и динамикой алгоритма оптимизации.
В конечном итоге, ценность метода Муон, возможно, заключается не в его превосходстве над существующими алгоритмами, а в том, что он побуждает к переосмыслению фундаментальных принципов оптимизации. Подобно тому, как хороший инженер стремится к элегантности и простоте, так и разработчик алгоритмов должен искать решения, которые не только эффективны, но и понятны и предсказуемы.
Оригинал статьи: https://arxiv.org/pdf/2602.04669.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Генерация изображений: Новый взгляд на скорость и детализацию
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-05 20:14