Автор: Денис Аветисян
Новое исследование показывает, что использование высококачественных эталонных ответов может значительно повысить точность и соответствие моделей искусственного интеллекта заданным критериям.
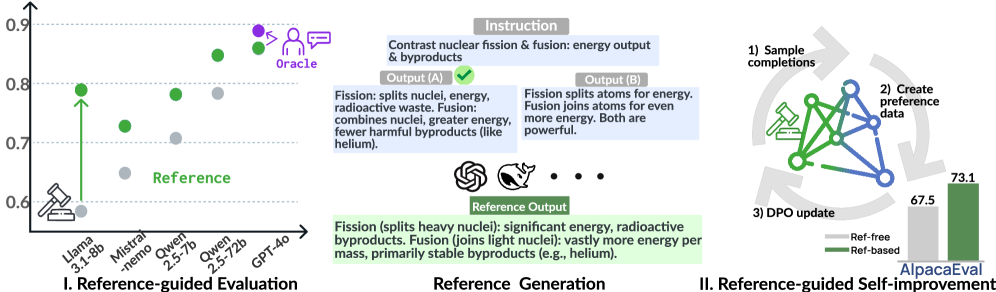
Использование эталонных данных для самосовершенствования языковых моделей позволяет достичь результатов, сравнимых с обучением на основе обратной связи от людей или других ИИ, без необходимости в дополнительном аннотировании.
Несмотря на эффективность обучения с подкреплением с использованием проверяемых наград в задачах рассуждения, его применение к неверифицируемым областям, таким как согласование больших языковых моделей (LLM), затруднено из-за отсутствия объективных критериев. В работе ‘References Improve LLM Alignment in Non-Verifiable Domains’ исследуется возможность использования LLM-оценщиков, управляемых эталонными выходами, в качестве своеобразных «верификаторов». Показано, что подход, основанный на эталонных данных, значительно повышает точность менее способных LLM-судей, а также улучшает работу более сильных моделей при использовании высококачественных, созданных человеком эталонов. Может ли этот метод, демонстрирующий сопоставимые результаты с обучением с подкреплением на основе специализированных моделей вознаграждения, стать ключевым шагом к эффективной постобработке LLM в задачах, где объективная оценка затруднена?
Пределы Современной Оценки LLM
Традиционные бенчмарки, такие как AlpacaEval и Arena-Hard, зачастую оказываются неспособными в полной мере оценить сложные когнитивные способности больших языковых моделей. Эти инструменты, ориентированные на сравнение ответов с эталонными, испытывают трудности при анализе ответов, требующих многоступенчатого логического вывода, креативного решения проблем или понимания контекста, выходящего за рамки прямого сопоставления с текстом. В результате, модели, демонстрирующие поверхностное сходство с правильными ответами, могут получать высокие оценки, в то время как модели, способные к более глубокому и осмысленному рассуждению, могут быть недооценены. Эта проблема подчеркивает необходимость разработки новых, более совершенных методов оценки, способных выявлять истинный потенциал языковых моделей в решении сложных задач.
Оценка больших языковых моделей (LLM) посредством привлечения экспертов-людей представляет собой значительную проблему, обусловленную как финансовыми, так и временными затратами. Процесс требует существенных ресурсов для привлечения, обучения и оплаты квалифицированных оценщиков, что замедляет темпы исследований и разработок. Более того, субъективность человеческих оценок неизбежно вносит погрешности и искажения, поскольку восприятие качества ответа может варьироваться в зависимости от индивидуального опыта и предубеждений. Это приводит к непоследовательным результатам и затрудняет объективное сравнение различных LLM, препятствуя быстрому прогрессу в области искусственного интеллекта и требуя разработки более надежных и автоматизированных методов оценки.
Существующие автоматизированные методы оценки качества ответов больших языковых моделей (LLM) зачастую оказываются неспособными уловить тонкие различия в их работе. Несмотря на прогресс в разработке метрик, таких как BLEU или ROUGE, они ориентированы на поверхностное соответствие текста и не учитывают смысловую точность, логическую последовательность или креативность ответа. Автоматические системы, как правило, испытывают затруднения в оценке ответов, требующих понимания контекста, здравого смысла или способности к абстрактному мышлению. Это приводит к тому, что модели, генерирующие формально корректные, но фактически неверные или бессмысленные ответы, могут получать высокие оценки, а действительно качественные и продуманные ответы — недооцениваться. В результате, полагаясь исключительно на автоматизированные метрики, сложно получить объективную и полную картину возможностей LLM, что препятствует дальнейшему развитию и совершенствованию этих технологий.
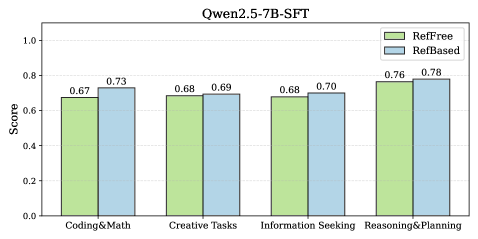
Усиление Оценки LLM с Помощью AI-Обратной Связи
Методы оценки LLM с использованием других LLM в качестве судей (LLM-as-Judge) предоставляют масштабируемую альтернативу ручной оценке, однако их точность напрямую зависит от качества модели, выполняющей роль судьи. Более слабые или недостаточно обученные LLM-судьи могут демонстрировать низкую согласованность с человеческими оценками и приводить к неверным результатам. Поэтому, выбор и настройка LLM-судьи, включая его размер, архитектуру и процесс обучения, являются критическими факторами для обеспечения надежности и валидности автоматизированной оценки. Качество LLM-судьи оказывает существенное влияние на корреляцию с человеческими оценками и, следовательно, на пригодность автоматизированной оценки для практических целей.
Методика Chain-of-Thought (CoT) и подходы, такие как Reference-Guided LLM-as-Judge, повышают надежность оценки больших языковых моделей (LLM) за счет акцентирования внимания на последовательности рассуждений. Вместо простой оценки конечного результата, CoT стимулирует LLM к детализации шагов, приведших к ответу. Reference-Guided LLM-as-Judge дополнительно использует высококачественные эталонные ответы для сравнения не только финального результата, но и логики, использованной для его получения. Такой подход позволяет более точно выявлять ошибки в рассуждениях и обеспечивает более объективную и последовательную оценку качества ответов LLM.
Для обеспечения точной и последовательной оценки больших языковых моделей (LLM) критически важно использование высококачественных эталонных (Reference) ответов. Эти ответы, сгенерированные продвинутыми моделями, такими как DeepSeek-V3 или GPT-4, служат стандартом для сравнения и анализа результатов, полученных оцениваемой LLM. Использование эталонных ответов позволяет минимизировать субъективность оценки и повысить ее надежность, поскольку LLM-судья сравнивает не просто правильность ответа, а соответствие логике и структуре, заложенным в эталоне. Качество эталонных ответов напрямую влияет на достоверность автоматизированной оценки, что делает их ключевым компонентом в процессе тестирования и улучшения LLM.
Исследования показали, что использование LLM в качестве оценочной модели (LLM-as-Judge) с применением референсных ответов (Reference-Guided LLM-judges) демонстрирует абсолютное повышение точности на 6,8% по сравнению с моделями, работающими без референсов. Данный результат был получен при анализе результатов работы 11 различных LLM-оценочных моделей, что подтверждает статистическую значимость улучшения. Применение высококачественных референсных ответов, сгенерированных продвинутыми моделями, является ключевым фактором повышения надежности и консистентности автоматической оценки.

Прямая Оптимизация Предпочтений для Настройки Согласованности
Прямая оптимизация предпочтений (DPO) представляет собой эффективный подход к согласованию больших языковых моделей (LLM) с желаемым поведением, основанный на использовании данных о предпочтениях. В отличие от традиционных методов, таких как обучение с подкреплением на основе обратной связи от человека (RLHF), DPO напрямую оптимизирует политику LLM на основе пар предпочтений, указывающих, какой вывод предпочтительнее. Это позволяет упростить процесс обучения, избегая необходимости в обучении отдельной модели вознаграждения и последующей оптимизации политики с ее использованием. Вместо этого, DPO использует функцию потерь, которая непосредственно максимизирует вероятность выбора предпочтительного ответа, что обеспечивает более стабильное и эффективное обучение.
Метод Direct Preference Optimization (DPO) является развитием техник обучения с подкреплением на основе обратной связи от человека (RLHF) и обучения с подкреплением на основе обратной связи от ИИ (RLAIF), однако отличается упрощением процесса обучения и повышением его стабильности. В отличие от RLHF и RLAIF, требующих обучения модели вознаграждения и последующей оптимизации политики, DPO напрямую оптимизирует политику LLM, используя данные о предпочтениях. Это достигается за счет переформулировки задачи обучения как задачи классификации, где модель обучается предсказывать предпочтительный ответ на основе пар ответов, что устраняет необходимость в отдельной модели вознаграждения и снижает вычислительную сложность. Упрощение процесса обучения способствует более стабильной сходимости и снижает риск переобучения, что делает DPO более надежным методом для тонкой настройки LLM в соответствии с желаемым поведением.
Эффективность обучения на основе предпочтений значительно повышается при использовании специализированных моделей вознаграждения, таких как ArmoRM, и наборов данных, например UltraFeedback. ArmoRM предоставляет надежную оценку качества генерируемого текста, что позволяет более точно настраивать языковые модели в соответствии с желаемым поведением. Набор данных UltraFeedback, в свою очередь, содержит высококачественные данные о предпочтениях пользователей, полученные путем сравнения различных ответов модели, что позволяет обучать модели генерировать ответы, более соответствующие ожиданиям пользователей. Комбинация этих инструментов позволяет добиться существенного улучшения показателей производительности, включая повышение оценок AlpacaEval до 73.1 (Llama-3) и 70.0 (Qwen2.5) и Arena-Hard до 58.7 (Llama-3) и 74.1 (Qwen2.5) по сравнению с базовым уровнем SFT-дистилляции.
Методы самосовершенствования, основанные на оптимизации прямых предпочтений (DPO), демонстрируют значительное повышение производительности больших языковых моделей. В частности, использование DPO позволило добиться результатов до 73.1 балла по метрике AlpacaEval для модели Llama-3 и до 70.0 баллов для Qwen2.5. Эти показатели на 19.2 пункта выше, чем у моделей, обученных методом дистилляции SFT (Supervised Fine-Tuning), что свидетельствует о превосходстве DPO в задачах выравнивания и улучшения качества генерируемого текста.
При применении Direct Preference Optimization (DPO) для тонкой настройки моделей, результаты оценивались с использованием метрики Arena-Hard. Модель Llama-3 достигла показателя 58.7, а Qwen2.5 — 74.1, что демонстрирует улучшение на 16.5 пунктов по сравнению с базовой линией Supervised Fine-Tuning (SFT) дистилляции. Данные показатели Arena-Hard отражают способность моделей генерировать более предпочтительные ответы в сложных сценариях, где требуется более тонкое понимание контекста и более точное соответствие предпочтениям пользователей.
Будущее Оценки и Согласования LLM
Автоматизированные конвейеры оценки, основанные на методах Direct Preference Optimization (DPO) и Reference-Guided LLM-as-Judge, обещают значительно ускорить циклы разработки больших языковых моделей. Вместо трудоемкой ручной оценки, системы, использующие DPO, обучаются на предпочтениях пользователей, позволяя им автоматически ранжировать различные ответы моделей. Подход Reference-Guided LLM-as-Judge, в свою очередь, использует другую языковую модель в качестве судьи, сравнивая сгенерированный текст с эталонными ответами и вынося оценку, что позволяет автоматизировать процесс проверки качества и соответствия требованиям. Такое сочетание технологий не только снижает затраты времени и ресурсов на тестирование, но и обеспечивает более быструю итерацию и улучшение моделей, открывая путь к созданию более совершенных и полезных систем искусственного интеллекта.
Современные языковые модели (LLM) все чаще оснащаются механизмами непрерывного самосовершенствования, позволяющими им адаптироваться к изменяющимся запросам пользователей и поддерживать оптимальную производительность. Данный подход предполагает создание замкнутых циклов обучения, в которых модель анализирует взаимодействие с пользователями, выявляет закономерности в предпочтениях и автоматически корректирует собственные параметры для повышения релевантности и точности ответов. Подобные системы не только обеспечивают постоянное улучшение качества генерации текста, но и позволяют LLM динамически подстраиваться под индивидуальные потребности каждого пользователя, предлагая персонализированный опыт взаимодействия. В результате, языковые модели становятся все более отзывчивыми, полезными и надежными, раскрывая свой потенциал в широком спектре приложений — от автоматизированной поддержки клиентов до создания креативного контента.
Достижения в области оценки и согласования больших языковых моделей (LLM) открывают перспективы для создания более надёжных, заслуживающих доверия и соответствующих ожиданиям систем. Это позволит раскрыть весь потенциал LLM в самых разных областях — от автоматизации рутинных задач и предоставления персонализированной информации до поддержки принятия решений в критически важных сферах, таких как медицина и финансы. Повышение надёжности и соответствия LLM этическим нормам и пользовательским предпочтениям не только улучшит пользовательский опыт, но и снизит риски, связанные с предвзятостью, дезинформацией и нежелательными последствиями, тем самым способствуя более широкому и ответственному внедрению этих мощных технологий.
В контексте стремительного развития больших языковых моделей (LLM) особую значимость приобретают комплексные системы оценки их производительности и соответствия задачам. В этом ключе бенчмарки, подобные LLMBar, выступают в роли критически важных инструментов для мониторинга прогресса и обеспечения надежности новых методов оценки. LLMBar позволяет систематически измерять и сравнивать различные модели по широкому спектру параметров, выявляя сильные и слабые стороны каждой из них. Этот подход не только способствует улучшению существующих моделей, но и задает стандарты для будущих разработок, гарантируя, что LLM действительно соответствуют требованиям пользователей и этическим нормам. Регулярное использование LLMBar как эталона позволяет отслеживать динамику улучшения качества моделей и подтверждать эффективность внедряемых инноваций в области оценки и выравнивания LLM.
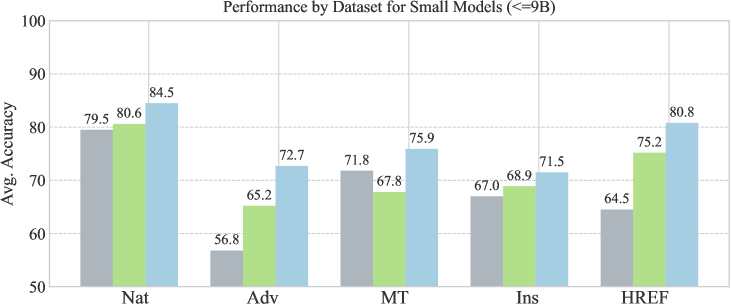
Исследование показывает, что наделение языковой модели качественными эталонными выходами позволяет добиться значительного улучшения её согласованности, особенно в областях, где верификация затруднена. Это напоминает о важности органичного развития систем, а не попыток жёсткого контроля. Как говорил Андрей Колмогоров: «Математика — это искусство видеть невидимое». Подобно тому, как математик ищет скрытые закономерности, так и данная работа демонстрирует, что истинная согласованность возникает не из прямого программирования, а из способности модели учиться на примерах и самосовершенствоваться, подобно экосистеме, растущей из заданных условий. Отказ от необходимости ручной или ИИ-оценки лишь подчеркивает эту идею саморегуляции и адаптации.
Куда Ведет Эта Тропа?
Представленная работа демонстрирует любопытную тенденцию: система, ориентирующаяся на образцы, пусть и созданные другим инструментом, способна к самокоррекции. Однако, это не решение проблемы выравнивания, а лишь перенос её на создателей этих самых образцов. В конечном итоге, система лишь отражает предубеждения и ограничения тех, кто её «обучил» косвенным путем. Ситуация напоминает зеркало, отражающее другое зеркало — бесконечная регрессия, лишенная истинного основания.
Упор на «качество образцов» звучит как заклинание, скрывающее глубокую проблему: как определить это качество без внешнего, субъективного наблюдателя? И что произойдет, когда система столкнется с ситуацией, не представленной в этих образцах? Она не изобретет решение, она лишь экстраполирует существующее, усугубляя предсказуемые ошибки. Система, которая никогда не ошибается, — мертва, но система, которая предсказуемо ошибается — опасна.
Будущие исследования, вероятно, сосредоточатся на автоматизации создания этих «эталонных» образцов, что лишь замкнет круг. В идеальном решении не останется места для людей, но и система, полностью лишенная человеческого вмешательства, станет монолитной структурой, неспособной к адаптации. Возможно, истинный прогресс заключается не в создании идеальных систем, а в разработке инструментов для управления их неизбежными сбоями.
Оригинал статьи: https://arxiv.org/pdf/2602.16802.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Серебро и медь: новый взгляд на наноаллои
- Оживший аватар: Генерация видео в реальном времени по голосу
- Искусственный интеллект и квантовая физика: кто кого?
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Quantum Musings: A Conversation with Bert de Jong
- Проверка логики: как повысить надежность больших языковых моделей
- Понять Мысли Ученика: Как Искусственный Интеллект Расшифровывает Решения по Математике?
- Искусственный интеллект и мозг: пять важных аналогий
2026-02-20 08:33