Автор: Денис Аветисян
Новая система DeepEra позволяет значительно повысить точность ответов на научные вопросы, эффективно фильтруя нерелевантную информацию.
DeepEra — это агент, переупорядочивающий научные документы для улучшения работы систем генерации ответов с использованием поиска (Retrieval-Augmented Generation).
Несмотря на стремистый рост объемов научной литературы, достоверность ответов на вопросы, генерируемых с использованием методов извлечения и генерации (RAG), часто страдает из-за нерелевантных фрагментов текста. В статье ‘DeepEra: A Deep Evidence Reranking Agent for Scientific Retrieval-Augmented Generated Question Answering’ предложен агент DeepEra, который повышает точность отбора научных данных, фильтруя семантически похожие, но логически нерелевантные отрывки. Разработанный подход демонстрирует превосходство в ранжировании релевантных документов, а также подтверждается на новой масштабной базе данных SciRAG-SSLI, включающей около 300 тысяч вопросов по 10 научным дисциплинам. Сможет ли DeepEra стать ключевым компонентом в создании надежных и эффективных систем научного поиска и ответов на вопросы?
Поиск истины в море данных: вызовы современной науки
Поиск ответов на научные вопросы, несмотря на свою критическую важность для совершения новых открытий, представляет собой серьезную проблему из-за огромного объема и сложности современной научной литературы. Непрерывно растущий поток исследований, публикаций и данных создает ситуацию, когда даже экспертам трудно оперативно находить релевантную информацию. Эта задача усугубляется тем, что научные тексты часто характеризуются высокой степенью специализации, сложной терминологией и подразумевают глубокие знания предметной области. Эффективное извлечение знаний требует не просто поиска по ключевым словам, а способности понимать контекст, связи между концепциями и критически оценивать достоверность источников, что делает автоматизированное научное вопросно-ответное взаимодействие особенно сложной задачей.
Традиционные методы поиска научной информации зачастую оказываются неэффективными при работе с огромными объемами данных. В основе многих систем лежат алгоритмы, ориентированные на сопоставление ключевых слов, что приводит к игнорированию контекста и смысловых нюансов. Такой подход не позволяет выявить действительно релевантную информацию, поскольку научные тексты изобилуют синонимами, полисемией и сложными логическими конструкциями. В результате, система может выдавать множество ложных срабатываний или, напротив, упускать из виду важные исследования, которые не содержат заданных ключевых слов, но имеют непосредственное отношение к запросу. Эффективный анализ научной литературы требует не просто поиска соответствий по словам, а глубокого понимания смысла и взаимосвязей между различными научными концепциями.
Для существенного ускорения научного прогресса необходима система, способная к глубокому пониманию контекста и надежному извлечению доказательств. Современные научные публикации характеризуются огромным объемом и сложностью, требующими не просто поиска по ключевым словам, а анализа взаимосвязей между понятиями и аргументами. Такая система должна уметь различать нюансы в формулировках, выявлять противоречия и оценивать достоверность источников. Она должна эффективно обрабатывать различные типы данных, включая текст, таблицы и графики, и представлять полученные результаты в удобной для исследователя форме. В конечном итоге, подобный инструмент позволит ученым быстрее находить релевантную информацию, строить новые гипотезы и проводить более эффективные исследования, что приведет к прорывам в различных областях науки.
RAG: контекст как ключ к знаниям
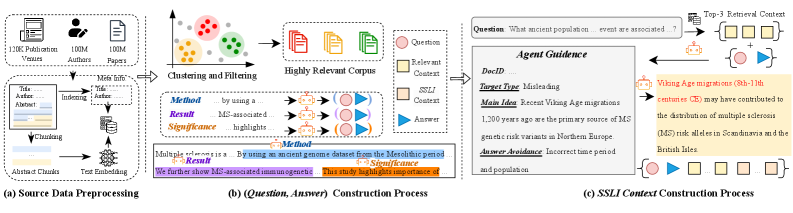
Технология Retrieval-Augmented Generation (RAG) объединяет возможности предварительно обученных больших языковых моделей (LLM) с внешними источниками знаний для генерации более точных и обоснованных ответов. В основе RAG лежит принцип дополнения LLM актуальной информацией, извлеченной из внешних баз данных или документов, что позволяет преодолеть ограничения, связанные с ограниченным объемом знаний, заложенным в модель во время обучения. Это достигается путем извлечения релевантных фрагментов информации из внешнего источника, которые затем используются LLM в качестве контекста для формирования ответа, что повышает его достоверность и соответствие текущей ситуации.
В основе работы систем RAG лежит двухэтапный процесс. Сначала система извлекает релевантные документы из базы знаний, используя методы информационного поиска, такие как семантический поиск или поиск по ключевым словам. Извлеченные документы затем передаются в большую языковую модель (LLM) в качестве контекста. LLM анализирует предоставленную информацию и синтезирует её, формируя связный и релевантный ответ на запрос пользователя. Таким образом, LLM не генерирует ответ «с нуля», а использует внешние данные для обоснования и уточнения своей генерации.
Подход Retrieval-Augmented Generation (RAG) позволяет снизить присущие большим языковым моделям (LLM) ограничения, такие как склонность к галлюцинациям и устаревание информации. Вместо генерации ответов исключительно на основе внутренних параметров модели, RAG использует внешние базы знаний для извлечения релевантных документов. Это обеспечивает привязку ответов к проверенным и актуальным данным, повышая их достоверность и снижая вероятность выдачи ложной или неточной информации. Таким образом, RAG обеспечивает возможность генерации ответов, подкрепленных фактическими доказательствами, что критически важно для приложений, требующих высокой точности и надежности.
DeepEra: агентский переранжировщик для повышения точности
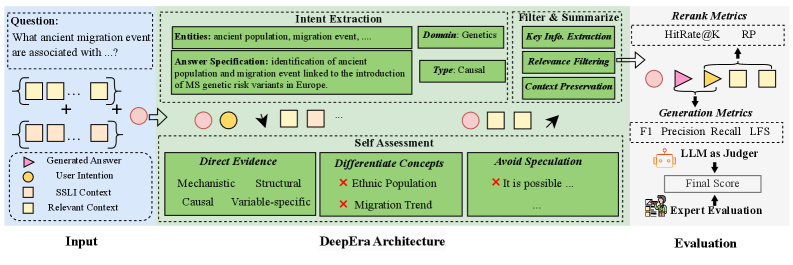
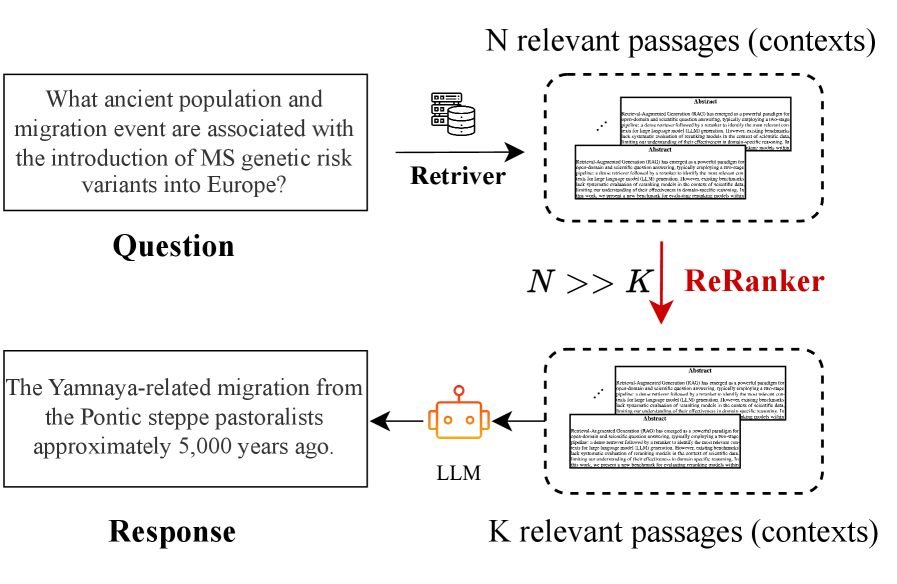
DeepEra представляет собой инновационный агентский переранжировщик, разработанный для повышения точности и надежности ответов на научные вопросы в системах RAG (Retrieval-Augmented Generation). В отличие от традиционных методов, основанных на простом сопоставлении ключевых слов, DeepEra использует большие языковые модели (LLM) для переоценки извлеченных фрагментов текста. Это позволяет системе учитывать семантическую релевантность, логическую согласованность и фактическое обоснование каждого фрагмента, что в конечном итоге приводит к более точным и надежным ответам на сложные научные запросы.
DeepEra использует большие языковые модели (LLM) для оценки релевантности кандидатов в ответах, выходя за рамки простого сопоставления ключевых слов. Оценка производится на основе семантической близости запроса и отрывка текста, логической связности представленной информации и наличия фактического обоснования утверждений. LLM анализирует смысл текста, а не только наличие определенных терминов, что позволяет более точно определять, действительно ли отрывок содержит ответ на вопрос и является ли он надежным источником информации. Этот подход обеспечивает более глубокое понимание содержания и позволяет исключить отрывки, которые формально соответствуют запросу, но не несут полезной информации или содержат противоречия.
Ключевые компоненты DeepEra включают в себя распознавание намерений (Intention Recognition) для анализа нюансов запроса, фильтрацию доказательств (Evidence Filtering) для удаления нерелевантного контента и суммирование доказательств (Evidence Summarization) для сжатия сохраненных фрагментов текста. В процессе работы система оценивает семантическую релевантность, логическую согласованность и обоснованность доказательств, что позволяет повысить устойчивость извлечения информации и точность ответов на научные вопросы. В результате тестирования DeepEra показала относительное улучшение до 8% в устойчивости поиска и точности ответов на научные вопросы.

SciRAG-SSLI: проверка надежности в условиях сложной реальности
Набор данных SciRAG-SSLI представляет собой сложную платформу для оценки, поскольку он объединяет в себе как естественно извлеченные научные тексты, так и отвлекающие факторы, сгенерированные большими языковыми моделями. Такой подход позволяет проверить способность моделей к ранжированию не только в условиях поиска релевантной информации, но и к фильтрации искусственно созданных, но правдоподобных отвлечений. Эта особенность делает SciRAG-SSLI особенно ценным инструментом для оценки надежности и точности систем, предназначенных для работы с научными знаниями, поскольку имитирует реальные сложности поиска информации в условиях перегруженности данными и потенциального влияния неточных или вводящих в заблуждение источников.
Разработанный набор данных SciRAG-SSLI представляет собой уникальную платформу для всесторонней оценки эффективности алгоритмов переранжирования. Его особенность заключается в сочетании реальных научных текстов, полученных в результате поиска, и искусственно сгенерированных отвлекающих факторов, созданных с помощью больших языковых моделей. Такой подход позволяет не просто измерить способность системы находить релевантную информацию, но и оценить её устойчивость к шуму и дезинформации. Использование SciRAG-SSLI позволяет выявить слабые места в существующих моделях и стимулирует разработку новых, более совершенных алгоритмов, способных решать сложные задачи в области научного поиска и анализа информации, тем самым расширяя границы современных технологий.
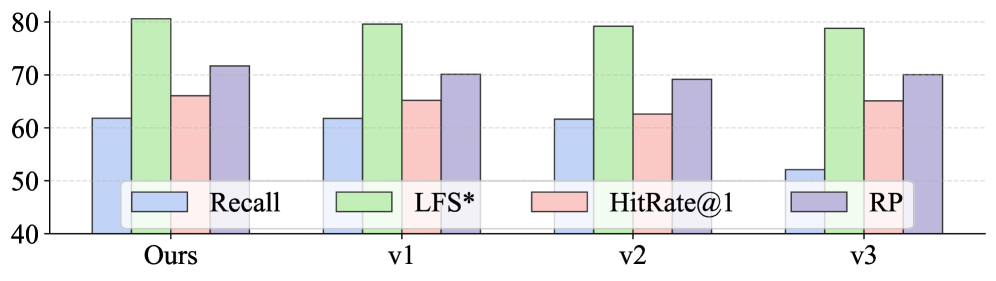
На сложном подмножестве SSLI датасета SciRAG-SSLI, система DeepEra продемонстрировала впечатляющие результаты, подтверждающие её эффективность в задаче переранжирования научных документов. Достигнутый показатель HitRate@1 составил 66.6%, что означает, что в 66.6% случаев правильный ответ находился на первом месте в отранжированном списке. Более того, показатель HitRate@3 достиг 76.4%, указывая на то, что правильный ответ находится в топ-3 результатах в 76.4% случаев. Значение Relative Position (RP) составило 71.96, а F1 Score — 43.38, что свидетельствует о высокой точности и полноте системы. Оценка, полученная с помощью LLM (Large Language Model), составила 3.94, подтверждая, что система генерирует релевантные и логически обоснованные результаты, что в совокупности демонстрирует существенный прогресс по сравнению с существующими методами в данной области.
Будущее интеллектуального научного поиска: к новым горизонтам знаний
Дальнейшее совершенствование агентивных переранжировщиков, подобных DeepEra, в сочетании с надежными оценочными наборами данных, такими как SciRAG-SSLI, представляется ключевым фактором для раскрытия всего потенциала научных знаний. Эти системы, способные активно оценивать и переупорядочивать результаты поиска, позволяют значительно повысить точность и релевантность научной информации, предоставляемой исследователям. Создание и использование строгих, всесторонних наборов данных для оценки производительности этих систем крайне важно для обеспечения их надежности и объективности. В результате, усовершенствованные агентивные переранжировщики, протестированные на высококачественных данных, способны существенно ускорить процесс научных открытий, предоставляя ученым более эффективные инструменты для анализа и синтеза информации, а также выявления новых закономерностей и связей.
Расширение использования открытых репозиториев научных метаданных, таких как OpenAlex, представляет собой ключевой фактор для создания более масштабных и разнообразных наборов данных, необходимых для обучения современных моделей искусственного интеллекта. Эти репозитории аккумулируют информацию о научных публикациях, авторах, аффилиациях и ссылках, предоставляя структурированные данные, которые позволяют алгоритмам понимать связи между различными областями знаний. Более полные и разнообразные данные, полученные из таких источников, позволяют создавать более точные и надежные модели, способные выявлять новые закономерности и ускорять процесс научных открытий. В перспективе, доступ к таким данным позволит исследователям автоматизировать процесс анализа научной литературы, выявлять пробелы в знаниях и генерировать новые гипотезы, значительно повышая эффективность научных исследований.
В конечном итоге, прогресс в области интеллектуальных систем анализа научных данных обещает предоставить исследователям инструменты нового поколения, способные значительно ускорить темпы научных открытий и стимулировать инновации. Эти системы, основанные на передовых алгоритмах и обширных базах открытых научных данных, позволят автоматизировать рутинные задачи, выявлять неочевидные закономерности и предлагать новые гипотезы. Благодаря этому ученые смогут сосредоточиться на наиболее творческих аспектах своей работы, расширяя границы знаний и разрабатывая прорывные технологии в различных областях науки и техники. Возможность быстрого и эффективного анализа огромных объемов информации станет ключевым фактором для решения сложнейших задач, стоящих перед современным человечеством.
Исследование представляет DeepEra — систему, стремящуюся к повышению точности ответов на научные вопросы. Данный подход акцентирует внимание на фильтрации нерелевантной информации и выделении логически связанных доказательств, что особенно важно в контексте Retrieval-Augmented Generation (RAG). Как однажды заметил Джон Маккарти: «Каждая сложность требует алиби.» Именно эту простоту и ясность, избавление от излишнего, стремится обеспечить DeepEra, отсекая шум и фокусируясь на существенном. Система, по сути, демонстрирует принцип, согласно которому эффективное решение задачи требует не добавления сложности, а её целенаправленного сокращения.
Что дальше?
Представленная работа, хотя и демонстрирует улучшение в области научного поиска и генерации ответов, лишь слегка приоткрывает завесу над истинной сложностью проблемы. Упор на логическую релевантность, безусловно, шаг в правильном направлении, однако он не решает фундаментальную неоднозначность, присущую научному дискурсу. Смысл часто ускользает, даже когда логика безупречна. Очевидно, что будущие исследования должны быть направлены на более глубокое понимание контекста и намерений, стоящих за запросом, а не просто на сопоставление ключевых слов и логических связей.
Ограничения существующих языковых моделей в обработке нюансов и неявных знаний остаются серьезным препятствием. Достижение подлинной «интеллектуальной честности» в системах, генерирующих ответы, требует не просто фильтрации нерелевантной информации, но и способности к самокритике, к признанию границ собственной компетентности. Предлагаемые агентные подходы, несомненно, перспективны, но их эффективность напрямую зависит от качества и разнообразия данных, используемых для обучения.
В конечном счете, истинный прогресс в этой области будет заключаться не в создании все более сложных алгоритмов, а в признании пределов машинного понимания. Попытка имитировать человеческий разум — занятие тщеславное. Гораздо более полезным представляется создание систем, которые помогают человеку лучше понимать себя и окружающий мир, а не заменяют его.
Оригинал статьи: https://arxiv.org/pdf/2601.16478.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Квантовый скачок из Андхра-Прадеш: что это значит?
- LLM: математика — предел возможностей.
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Почему ваш Steam — патологический лжец, и как мы научили компьютер читать между строк
2026-01-27 00:34