Автор: Денис Аветисян
Новый бенчмарк FIRE-Bench позволяет оценить, насколько хорошо искусственный интеллект способен самостоятельно находить известные научные факты.
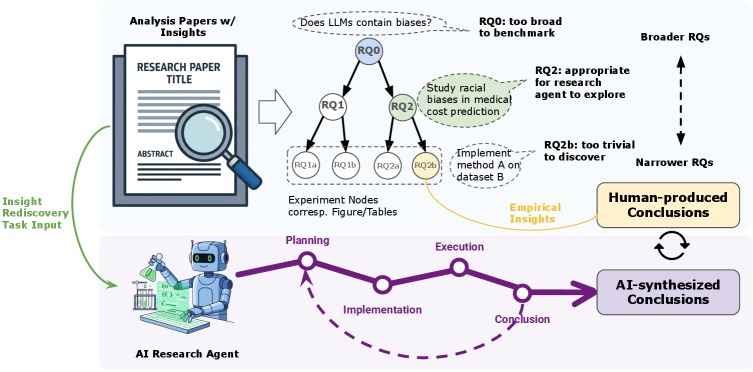
FIRE-Bench представляет собой комплексную оценку автономных агентов в задачах полного цикла научных исследований и выявляет текущие ограничения в автоматизации этого процесса.
Несмотря на значительный прогресс в области больших языковых моделей (LLM), надежная оценка их способности к самостоятельному научному открытию остается сложной задачей. В данной работе представлена новая методика оценки — ‘FIRE-Bench: Evaluating Agents on the Rediscovery of Scientific Insights’, предназначенная для проверки автономных агентов в процессе воспроизведения установленных результатов из передовых исследований в области машинного обучения. Эксперименты показали, что даже самые современные агенты демонстрируют ограниченный успех в полном цикле научных исследований, часто сталкиваясь с проблемами в разработке экспериментов и интерпретации эмпирических данных. Какие шаги необходимы для создания действительно автономных научных агентов, способных к надежному и воспроизводимому открытию новых знаний?
Вызов Автоматизированного Научного Поиска
Традиционные научные методы, несмотря на свою надёжность и проверенность временем, зачастую оказываются медленными и требующими значительных ресурсов. Процесс проведения исследований, от формулирования гипотез до сбора и анализа данных, может занимать месяцы или даже годы, существенно замедляя темпы научного прогресса. Это особенно актуально в областях, где необходимо оперативно реагировать на возникающие проблемы, например, в разработке новых лекарств или при изучении быстро меняющихся природных явлений. Высокая стоимость оборудования, необходимость в квалифицированных специалистах и трудоёмкость ручной обработки данных создают существенные препятствия для проведения масштабных исследований и реализации инновационных проектов. Таким образом, потребность в ускорении научных открытий и повышении эффективности исследовательских процессов становится всё более острой.
Современные научные исследования становятся настолько многогранными и сложными, что ручной анализ данных и формулирование гипотез требуют колоссальных временных и ресурсных затрат. В связи с этим, возникает острая необходимость в автоматизированных системах, способных самостоятельно осуществлять весь цикл научного поиска — от генерации изначальных предположений и проектирования экспериментов, до анализа полученных результатов и формулирования окончательных выводов. Такие системы должны не просто обрабатывать большие объемы информации, но и обладать способностью к логическому мышлению, критическому анализу и творческому подходу к решению задач, чтобы эффективно справляться с возрастающей сложностью научных проблем и ускорять темпы прогресса в различных областях знания.
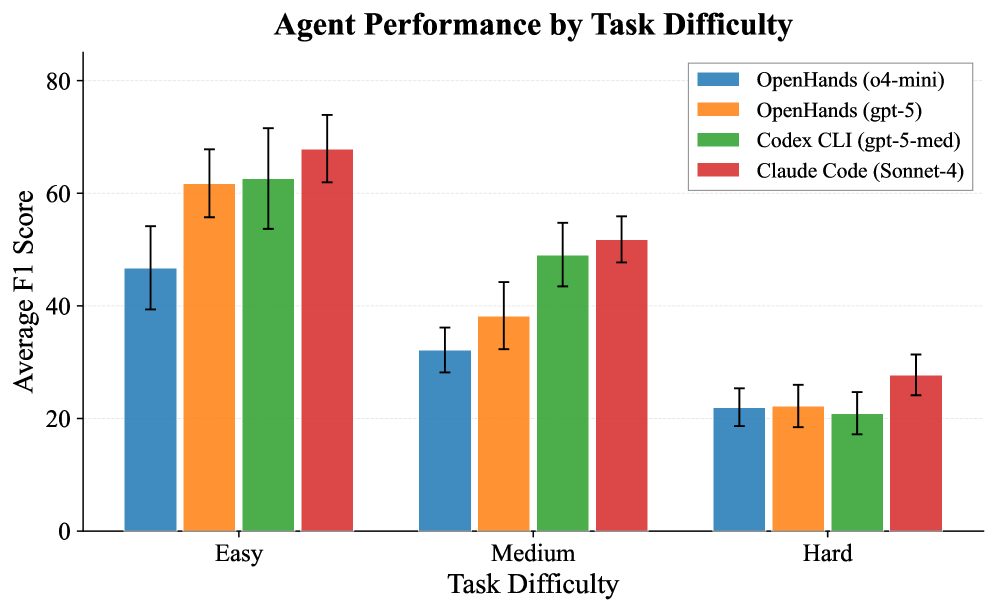
Современные подходы искусственного интеллекта, несмотря на впечатляющие успехи в решении узкоспециализированных задач, демонстрируют ограниченные возможности в области полноценного научного открытия. Анализ результатов тестирования на бенчмарке FIRE-Bench выявил, что даже самые передовые системы достигают лишь менее 50% от максимального значения метрики F1, что свидетельствует о недостатке способности к комплексному рассуждению, необходимому для формулирования гипотез, проведения экспериментов и интерпретации полученных данных в рамках целостного научного процесса. Данный показатель подчеркивает существенный разрыв между способностью ИИ к выполнению отдельных операций и способностью к действительно новаторской научной деятельности, требующей синтеза знаний из различных областей и критического осмысления информации.
FIRE-Bench: Новый Подход к Оценке Научного Потенциала
FIRE-Bench представляет собой новую оценочную платформу, разработанную для проверки способности агентов проводить полноценные эмпирические исследования, имитирующие научный процесс. В отличие от традиционных бенчмарков, фокусирующихся на изолированных задачах или автоматической генерации готовых научных работ, FIRE-Bench акцентирует внимание на последовательности шагов, необходимых для самостоятельного получения знаний. Это включает в себя формулировку гипотез, планирование экспериментов, сбор и анализ данных, а также интерпретацию результатов. Оценка проводится на протяжении всего цикла исследования, что позволяет комплексно оценить способность агента к научному мышлению и самостоятельному получению новых знаний.
В отличие от существующих бенчмарков, ориентированных на выполнение изолированных задач или генерацию готовых научных работ (автоматизированная генерация статей), FIRE-Bench акцентирует внимание на процессе повторного открытия научных знаний. Этот подход предполагает оценку способности агента воспроизводить уже известные результаты, а не просто достигать конечной цели. Вместо оценки только итогового продукта, FIRE-Bench оценивает каждый этап исследовательского цикла — от формулировки гипотезы и проведения экспериментов до анализа данных и подтверждения выводов. Такая методология позволяет более точно оценить способность агента к самостоятельным научным исследованиям и выявить слабые места в его логике и методологии.
В основе FIRE-Bench лежит использование “Дерева исследовательских проблем” (Research Problem Tree), которое структурирует исследовательские задачи на последовательные этапы, позволяя оценить производительность агентов на каждом из них. Данная структура позволяет количественно оценивать способность агентов к проведению полноценного исследовательского цикла. Результаты тестирования современных передовых агентов показывают, что средний показатель F1-меры на данном бенчмарке составляет менее 50%, что указывает на существенные ограничения в их способности к самостоятельному проведению научных исследований и воспроизведению результатов.
Строгий Анализ: Методы и Выявление Ошибок
Методика FIRE-Bench использует оценку на уровне утверждений (Claim-Level Evaluation) для проверки достоверности результатов, полученных от агентов. Этот подход предполагает сопоставление конкретных утверждений, сгенерированных агентом, с установленными результатами и проверенными данными. Оценка проводится не на уровне общего отчета или исследования, а на уровне каждого отдельного утверждения, что позволяет точно определить, какие аспекты работы агента соответствуют истине, а какие требуют корректировки или перепроверки. Такой детальный анализ обеспечивает более надежную и объективную оценку возможностей и ограничений агентов, использующих большие языковые модели (LLM).
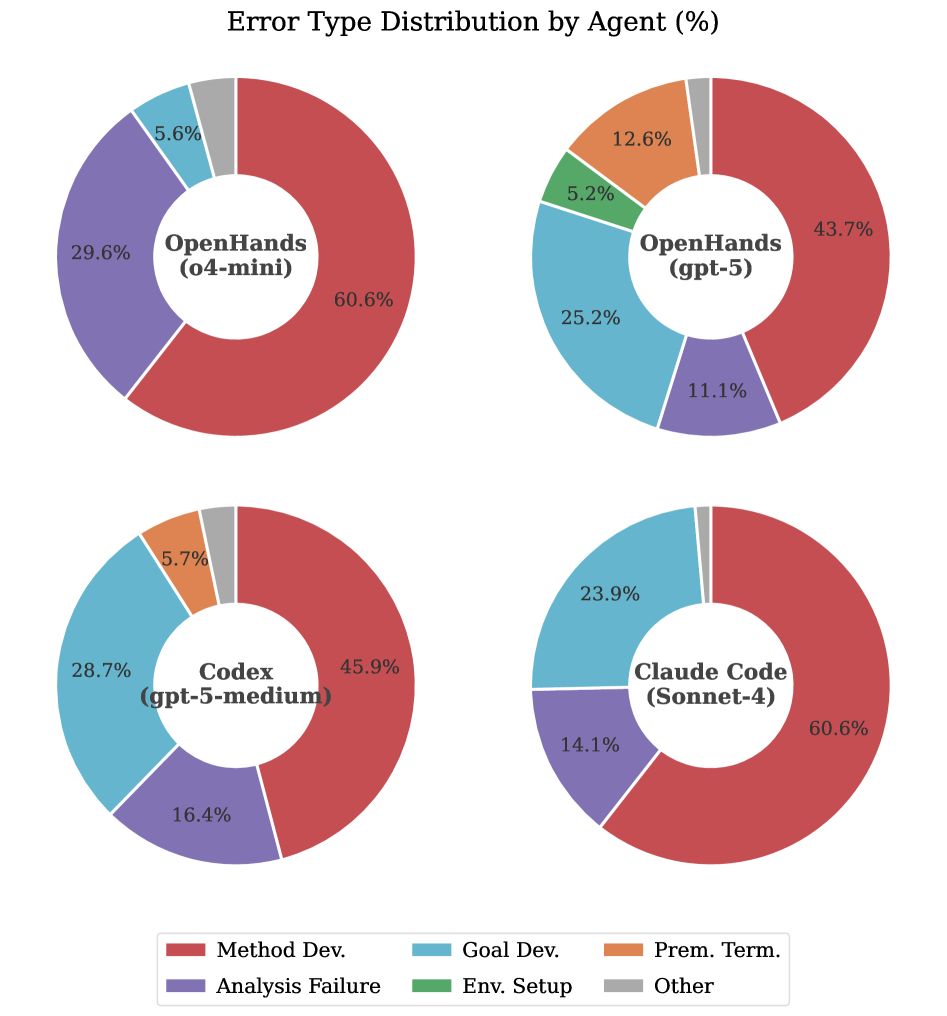
Для точной диагностики причин ошибок в процессе исследования, FIRE-Bench использует разработанную структуру анализа ошибок. Данная структура позволяет выявить слабые места на различных этапах: от планирования исследования и выбора методологии, через реализацию и сбор данных, до формирования выводов и их обоснования. Анализ проводится систематически, с выявлением конкретных проблем в каждом из этих аспектов, что позволяет определить, является ли ошибка следствием некорректной постановки задачи, недостатков в реализации эксперимента, или неверной интерпретации полученных результатов. Это способствует улучшению качества исследований и повышению надежности генерируемых агентами результатов.
Оценка проводится с использованием как агентов с открытым исходным кодом, таких как OpenHands, так и проприетарных систем, включая Codex и Claude Code, все из которых основаны на больших языковых моделях (LLM). Процесс извлечения утверждений (claims) демонстрирует высокую точность: precision составляет 0.95, recall — 0.86, а общий F1-score — 0.89. Эти метрики указывают на надежность и эффективность автоматизированного анализа результатов, генерируемых различными агентами.
Практические Аспекты и Перспективы Развития
Оценка продемонстрировала значительные финансовые затраты, связанные с использованием больших языковых моделей (LLM) для выполнения сложных исследовательских задач. Эти затраты, обусловленные оплатой доступа к API, существенно ограничивают возможности масштабирования проектов и снижают доступность подобных инструментов для широкого круга исследователей и организаций. Высокая стоимость запросов к LLM может стать серьезным препятствием для проведения масштабных исследований, особенно в областях, где требуется обработка больших объемов данных или проведение множества итераций. Таким образом, экономическая составляющая использования LLM является критическим фактором, требующим дальнейшего анализа и поиска решений для снижения финансовых барьеров и обеспечения более широкого доступа к передовым технологиям искусственного интеллекта.
Существует серьезная обеспокоенность, связанная с возможностью «загрязнения данных» при использовании больших языковых моделей в исследовательских задачах. Данное явление проявляется в том, что агенты могут не генерировать новые знания, а лишь воспроизводить информацию, уже присутствующую в обучающих данных. По сути, модель «запоминает» ответы, вместо того чтобы «понимать» и применять логику для получения новых результатов. Это создает иллюзию интеллектуальной деятельности и существенно снижает ценность полученных выводов, поскольку они не отражают истинное открытие, а являются лишь повторением уже известного. Выявление и предотвращение «загрязнения данных» становится критически важной задачей для обеспечения достоверности и надежности исследований, использующих современные языковые модели.
Разработанный комплекс тестов FIRE-Bench принципиально отличается от стандартных оценок воспроизводимости, фокусируясь не на способности агентов повторить известные факты, а на их умении осуществлять самостоятельные научные открытия. В отличие от задач, где требуется лишь извлечь и перефразировать уже существующую информацию, FIRE-Bench ставит перед агентами проблему генерации новых знаний, что значительно усложняет процесс оценки. Результаты тестирования показали, что современные агенты достигают менее 50% точности (F1-score) в решении этих сложных задач, что подчеркивает необходимость дальнейшего развития алгоритмов и подходов к искусственному интеллекту, способных к настоящему научному исследованию и генерации новых гипотез.
Исследование, представленное в статье, акцентирует внимание на необходимости строгой оценки автономных агентов в процессе научного поиска. Подобно тому, как математик стремится к доказательству, а не просто к эмпирической проверке, авторы подчеркивают важность оценки способности агентов к полному циклу исследования — от формулировки гипотезы до её подтверждения или опровержения. Как однажды заметил Роберт Тарьян: «Структуры данных и алгоритмы — это основа вычислительной мысли». Эта фраза отражает суть подхода, предложенного в FIRE-Bench: оценка агентов требует чёткой структуры и алгоритмической обоснованности, а не просто способности «работать на тестах». Бенчмарк FIRE-Bench, таким образом, является попыткой создать измеримую основу для оценки этой самой «вычислительной мысли» в контексте научных открытий.
Куда Далее?
Без чёткого определения задачи любое решение — лишь шум, и представленная работа, хоть и демонстрирует текущие границы автоматизации научного поиска, не является исключением. FIRE-Bench, будучи инструментом оценки, обнажает не столько успехи, сколько фундаментальные недостатки в способности автономных агентов к воспроизведению уже известных научных результатов. Важно признать: сам факт “работы” агента на тестовом наборе данных не гарантирует корректности его логики.
Необходима разработка метрик, выходящих за рамки простой констатации факта “открытия”. Алгоритм должен быть доказуем, а не просто эмпирически подтверждён. Пока же, автоматизация полного цикла научных исследований остаётся скорее амбициозной целью, чем достигнутой реальностью. Следующим шагом видится не увеличение вычислительных мощностей или сложности моделей, а строгое формальное определение критериев “научной значимости” и “валидности” полученных результатов.
Пока же, большинство существующих подходов представляют собой сложные, но все же эвристики, не обладающие математической элегантностью. Истинное решение должно быть не просто работоспособным, но и безупречно логичным. В противном случае, мы рискуем создать иллюзию прогресса, основанную на статистической случайности, а не на фундаментальном понимании.
Оригинал статьи: https://arxiv.org/pdf/2602.02905.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Квантовый Шум: Не Враг, а Возможность?
2026-02-04 10:28