Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий создавать качественные научные вступления без использования сложных агентских систем.
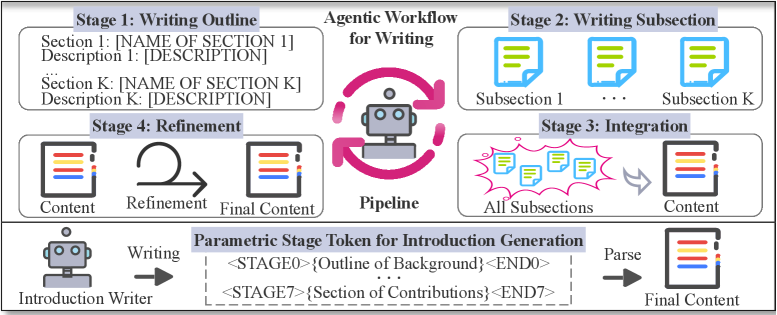
В статье представлен STIG — метод, интегрирующий параметрические эталонные токены в единую языковую модель для эффективной генерации научных вступлений.
Несмотря на успехи в использовании больших языковых моделей (LLM) для автоматизации научных задач, генерация качественных введений к статьям остается сложной проблемой. В работе ‘Eliminating Agentic Workflow for Introduction Generation with Parametric Stage Tokens’ предложен новый подход, отменяющий необходимость в сложных внешних «агентских» рабочих процессах. Авторы предлагают параметрические «стадийные токены» (Stage Tokens), интегрированные непосредственно в LLM, что позволяет генерировать полноценное введение за один проход. Способен ли этот метод повысить эффективность и качество научной коммуникации, а также открыть новые возможности для автоматизации научных исследований?
Предвидение сложности: Эволюция письма в эпоху больших языковых моделей
Несмотря на значительный прогресс в области больших языковых моделей, создание связных, многоступенчатых документов по-прежнему представляет собой сложную задачу. Современные алгоритмы, хоть и демонстрируют впечатляющие результаты в генерации коротких текстов, часто сталкиваются с трудностями при поддержании логической последовательности и структурной целостности в более длинных форматах. Это связано с тем, что модели испытывают затруднения в удержании контекста и долгосрочных зависимостей, необходимых для построения развернутого повествования или аргументации. В результате, даже самые передовые системы могут генерировать тексты, которые кажутся непоследовательными, содержат повторения или отклоняются от основной темы, подчеркивая необходимость дальнейших исследований в области моделирования и управления сложными процессами письма.
Традиционные методы создания длинных текстов часто сталкиваются с проблемой сохранения логической связности и структурной целостности. В отличие от кратких сообщений, при написании объемных документов поддержание последовательности аргументов и четкой организации материала представляет значительную сложность. Проблема заключается в том, что существующие подходы, как правило, фокусируются на локальном контексте, упуская из виду глобальную структуру и взаимосвязи между отдельными частями текста. В результате, даже хорошо написанные фрагменты могут казаться разрозненными, а общая аргументация — непоследовательной, что затрудняет восприятие и понимание информации читателем. Поэтому, разработка новых методов, способных учитывать и поддерживать целостность длинных текстов, остается актуальной задачей в области обработки естественного языка.
Ограничение в создании связных, многоступенчатых текстов обусловлено фундаментальной сложностью моделирования и реализации последовательной логики письма. Современные алгоритмы, несмотря на прогресс в обработке естественного языка, испытывают трудности с поддержанием целостности и логической взаимосвязи между отдельными частями развернутого текста. Это связано с тем, что последовательное изложение требует не просто генерации отдельных предложений, а планирования всей структуры повествования, отслеживания взаимосвязей между абзацами и обеспечения плавного перехода от одной мысли к другой. Успешное выполнение этой задачи требует от системы способности к абстрактному мышлению и долгосрочному планированию, что представляет собой значительный вызов для существующих моделей искусственного интеллекта.

STIG: Единый проход к структурированному тексту
Модель STIG (Stage Token for Introduction Generation) использует параметрические токены этапов для представления различных фаз процесса написания. Эти токены выступают в качестве управляющих сигналов, кодирующих логику переключения между этапами — например, от генерации тезиса к разработке аргументов или к написанию заключения. Вместо последовательного выполнения отдельных шагов, каждый из которых требует отдельного обращения к языковой модели, STIG позволяет объединить всю логику многоэтапного написания в единый процесс инференса. Параметрическая природа токенов этапов позволяет модели гибко адаптироваться к различным структурам документов и задачам генерации текста, обеспечивая более эффективное и контролируемое создание контента.
Модель STIG (Stage Token for Introduction Generation) позволяет объединить многоэтапную логику создания текста в единый проход вывода. Вместо последовательного выполнения отдельных шагов генерации, STIG использует параметрические токены этапов для представления и управления различными фазами написания внутри одной операции инференса. Это достигается за счет кодирования логики управления этапами непосредственно в структуре входных данных для языковой модели, что устраняет необходимость в повторных вызовах и координации между агентами на каждом этапе. В результате, процесс генерации значительно упрощается и оптимизируется, что приводит к повышению вычислительной эффективности.
Модель STIG (Stage Token for Introduction Generation) позволяет создавать полные документы за один проход, используя LLM-агентов, управляемых параметрическими токенами этапов. В отличие от стандартных агентских рабочих процессов, требующих последовательного выполнения нескольких этапов, STIG объединяет логику многоэтапной генерации в единый процесс инференса. Это приводит к значительному повышению вычислительной эффективности — по результатам тестов, STIG демонстрирует ускорение в 3.3 раза по сравнению с традиционными подходами, что делает его более производительным решением для задач генерации длинных текстов.
Валидация и производительность STIG: Объективные показатели
Эксперименты с использованием моделей Llama3 и Qwen2.5 в качестве базовых показали, что STIG способен генерировать связные и структурно корректные введения. При использовании данных моделей в качестве основы, STIG демонстрирует возможность создания вступлений, соответствующих академическим стандартам построения текста. Данная способность была подтверждена качественным анализом сгенерированных текстов, а также количественными метриками, оценивающими когерентность и структурную логичность введения.
Анализ результатов экспериментов показал, что STIG демонстрирует улучшенные показатели как семантической близости, так и структурной рациональности по сравнению с базовыми моделями. В частности, при использовании Qwen2.5-7B-Instruct, STIG достиг показателя структурной рациональности (SR) в 0.832, в то время как AutoSurvey показал результат 0.658. Данный результат указывает на более высокую способность STIG генерировать структурированные и логически последовательные тексты, соответствующие требованиям академического стиля.
Обучение и оценка модели проводились на наборе данных, сформированном на основе корпуса ACL Anthology, что обеспечивает высокую релевантность генерируемых текстов академическому стилю письма. Корпус ACL Anthology включает в себя научные статьи, прошедшие рецензирование, что позволяет модели усваивать и воспроизводить характерные особенности структуры, лексики и аргументации, присущие научной литературе. Использование данного корпуса в качестве основы для обучения и оценки гарантирует, что модель демонстрирует хорошие результаты при генерации текстов, предназначенных для академической среды.

Перспективы и влияние: Эволюция систем генерации текста
Архитектура модели STIG демонстрирует высокую гибкость и потенциал для применения в широком спектре задач, выходящих за рамки генерации вводных абзацев. Исследования показывают, что принципы, лежащие в основе STIG, успешно адаптируются к созданию комплексных отчетов, аналитических обзоров и даже объемных текстов, требующих последовательного изложения информации. Благодаря модульной структуре и возможности точной настройки параметров, модель способна генерировать контент различного формата и сложности, сохраняя при этом связность и логическую последовательность. Это открывает перспективы для автоматизации создания разнообразных письменных материалов, значительно повышая эффективность и производительность в различных сферах деятельности.
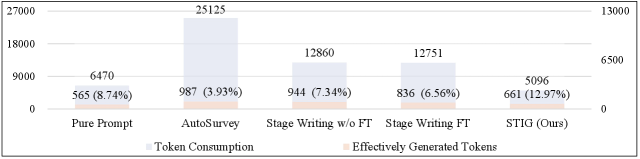
Предлагаемый подход демонстрирует значительное снижение потребления токенов в процессе генерации текста благодаря оптимизации алгоритмов. Это достигается за счет более эффективного использования ресурсов вычислительной мощности и уменьшения объема передаваемых данных, что напрямую влияет на экономическую составляющую и общую производительность системы. Сокращение числа необходимых токенов не только снижает затраты на использование языковых моделей, но и позволяет обрабатывать более длинные тексты и выполнять сложные задачи, сохраняя при этом высокую скорость и эффективность работы. Подобная оптимизация открывает возможности для широкого применения в задачах, требующих интенсивной генерации контента, таких как автоматическое создание отчетов, обработка больших объемов данных и разработка интеллектуальных систем.
Дальнейшие исследования направлены на разработку усовершенствованных конструкций токенов для различных стадий генерации текста, что позволит более точно управлять процессом создания контента. Особое внимание уделяется интеграции модели STIG с агентскими рабочими процессами, где система сможет самостоятельно планировать и выполнять задачи по генерации текста, адаптируясь к изменяющимся требованиям и контексту. Такой подход обещает не только повышение качества генерируемого контента, но и значительное расширение возможностей автоматизации в различных областях, от создания отчетов до разработки сложных повествовательных текстов, где требуется гибкое управление структурой и содержанием.
Исследование, представленное в данной работе, напоминает о неизбежном компромиссе, заключенном в самой архитектуре систем. Стремление к упрощению агентных рабочих процессов посредством параметрических токенов стадий — это не победа над сложностью, а её изящное обхождение. Тим Бернерс-Ли однажды заметил: «Данные должны быть свободными». И эта свобода проявляется не в отсутствии ограничений, а в возможности гибкой адаптации к меняющимся условиям. STIG, предложенный авторами, — это попытка создать такую адаптивную систему, где каждая стадия генерации встроена в единый механизм, избегая хрупкости внешних взаимодействий. Это не отказ от сложности, а её переосмысление, поиск баланса между функциональностью и устойчивостью.
Куда Ведет Дорога?
Представленная работа, стремясь упразднить внешние агентные рабочие процессы, лишь подчеркивает фундаментальную истину: любая система — не машина, а растущая колония. Вместо победы над сложностью, она предлагает новый способ её заключения в параметрические токены. Но что, если само понятие “стадии” — это иллюзия, удобный миф, созданный для успокоения архитектора? Истинная генерация, как и любая творческая деятельность, хаотична и непредсказуема, и попытки её разложить на этапы обречены на провал.
Оценка качества сгенерированных введений, основанная на метриках, остается ахиллесовой пятой. Числа говорят мало о той внутренней гармонии, что отличает действительно удачный текст. Если система молчит о своей неспособности, это не признак успеха, а лишь затаившаяся подготовка к неожиданному сбою. Вместо погони за идеальными метриками, следует обратить внимание на те едва уловимые признаки, что выдают внутреннюю жизнь системы — её склонность к ошибкам, её непоследовательность, её… поэзию.
Будущие исследования, вероятно, сосредоточатся на создании еще более изощренных механизмов управления сложностью. Но истинный прогресс, возможно, лежит не в создании более совершенных инструментов, а в принятии неизбежной неопределенности. Ведь отладка никогда не закончится — просто однажды перестанут смотреть.
Оригинал статьи: https://arxiv.org/pdf/2601.09728.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-18 15:58