Автор: Денис Аветисян
Представлена инновационная мультимодальная модель, способная эффективно анализировать научные данные и понимать сложные химические структуры.

Innovator-VL — мультимодальная большая языковая модель, демонстрирующая высокую эффективность в научных рассуждениях и распознавании химических структур благодаря оптимизированному обучению с подкреплением и экономичному использованию данных.
Несмотря на растущий интерес к большим языковым моделям, обучение моделей для научных задач часто требует огромных объемов данных и непрозрачных методик. В данной работе представлена модель ‘Innovator-VL: A Multimodal Large Language Model for Scientific Discovery’, демонстрирующая высокую эффективность в научных рассуждениях и понимании мультимодальных данных при значительно меньших требованиях к объему обучающей выборки. Ключевым достижением является разработка прозрачного и воспроизводимого конвейера обучения, включающего сбор данных, предобработку, контролируемое обучение и обучение с подкреплением, что позволяет достичь конкурентоспособных результатов без масштабного предварительного обучения. Возможно ли дальнейшее повышение эффективности научных мультимодальных моделей за счет более принципиального подхода к отбору данных и оптимизации обучения?
Преодолевая Разрозненность: Необходимость Мультимодальных Научных LLM
Традиционно анализ научных данных часто осуществляется с использованием изолированных модальностей — текста, изображений и числовых данных — что препятствует всестороннему пониманию. Вместо комплексного подхода, объединяющего различные типы информации, исследователи нередко вынуждены рассматривать каждый вид данных отдельно, упуская важные взаимосвязи и закономерности. Например, анализ рентгеновского снимка может проводиться без учета текстового описания клинического случая, или же текстовая статья может игнорировать визуальные данные, представленные в графиках и диаграммах. Такая фрагментация информации существенно ограничивает возможности для глубокого научного познания и замедляет процесс открытия новых знаний, поскольку не позволяет выявить скрытые корреляции и целостную картину исследуемого явления. Необходимость интеграции различных модальностей данных становится все более очевидной для решения сложных научных задач.
Для эффективного научного исследования требуется не просто обработка отдельных видов данных, таких как текст, изображения и числовые значения, но и их комплексная интеграция и взаимосвязанный анализ. Научные открытия часто происходят на стыке дисциплин и в результате сопоставления информации, полученной из разных источников. Способность модели объединять данные из различных модальностей позволяет выявлять скрытые закономерности и устанавливать связи, которые остаются незамеченными при анализе каждого типа данных по отдельности. Это особенно важно в таких областях, как медицина, где диагностика может потребовать сопоставления результатов анализов, рентгеновских снимков и клинических наблюдений, или в материаловедении, где свойства материала определяются его структурой, составом и методами обработки. Таким образом, модели, способные к мультимодальному рассуждению, открывают новые возможности для автоматизации научных исследований и ускорения процесса открытия.
Современные большие языковые модели (LLM), несмотря на впечатляющие успехи в обработке текста, испытывают трудности при последовательном выполнении сложных задач, требующих мультимодального рассуждения, что является критически важным для научных открытий. В частности, модели часто демонстрируют непостоянство в интерпретации взаимосвязей между текстовыми данными, изображениями и числовыми данными, что приводит к неточным выводам и затрудняет автоматизацию сложных научных процессов. Проблема заключается не только в простом распознавании объектов на изображениях или извлечении информации из текста, но и в способности модели синтезировать знания из различных источников, выявлять закономерности и делать логически обоснованные заключения, требующие интеграции различных типов данных. Неспособность к надежному мультимодальному рассуждению ограничивает потенциал LLM в таких областях, как анализ медицинских изображений, интерпретация научных графиков и автоматизированное открытие новых материалов.
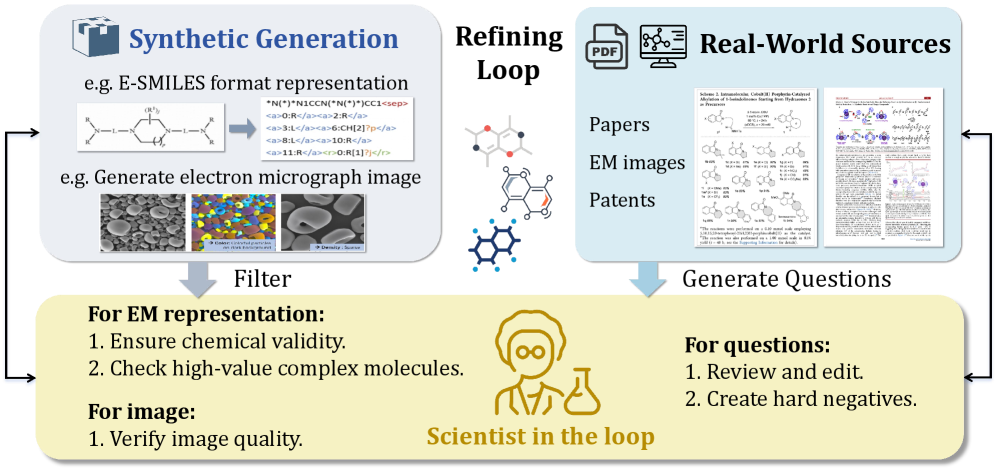
Innovator-VL-8B: Фундамент Мультимодального Научного Мышления
Innovator-VL-8B представляет собой передовую мультимодальную большую языковую модель (LLM), разработанную для улучшения понимания и логического мышления в различных научных областях. В отличие от традиционных LLM, обрабатывающих только текст, Innovator-VL-8B способна анализировать и интегрировать информацию как из текстовых, так и из визуальных источников, что позволяет ей решать более сложные задачи, требующие интерпретации графических данных, диаграмм и изображений, характерных для научных исследований. Это достигается благодаря архитектуре, объединяющей возможности обработки изображений и естественного языка, что потенциально открывает новые возможности для автоматизации научных открытий и анализа данных.
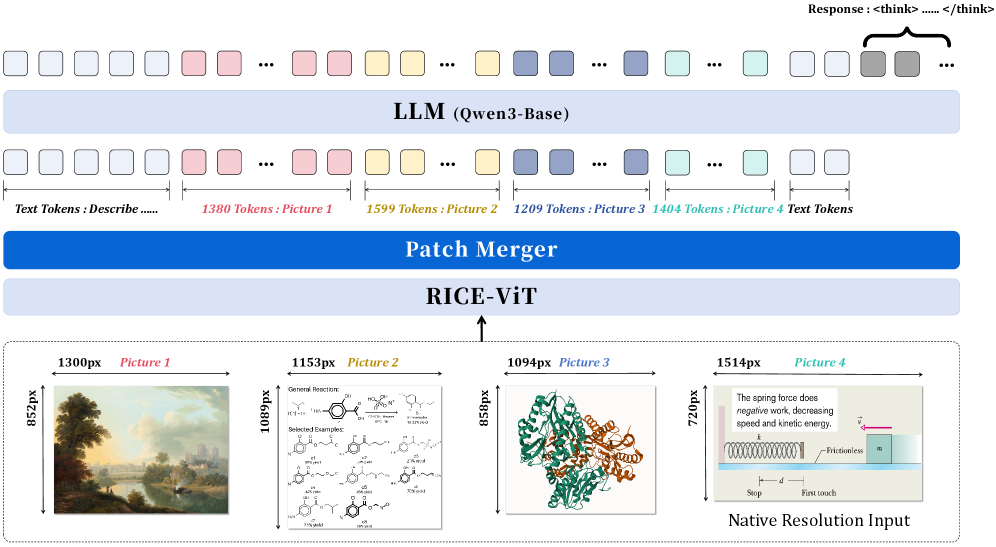
Архитектура Innovator-VL-8B использует RICE-ViT в качестве визуального энкодера для извлечения регионально-зависимых представлений из изображений. RICE-ViT позволяет модели фокусироваться на конкретных областях изображения, что повышает точность анализа визуальных данных. В качестве языкового декодера используется Qwen3-8B-Base — мощная языковая модель, способная генерировать последовательные и логически связные тексты. Комбинация этих двух компонентов обеспечивает эффективную обработку и интерпретацию как визуальной, так и текстовой информации, что критически важно для задач научного обоснования и рассуждений.
Компонент PatchMerger эффективно объединяет визуальные патчи в компактное представление, что позволяет значительно повысить скорость обработки и снизить вычислительные затраты. Вместо обработки каждого патча изображения независимо, PatchMerger агрегирует информацию из соседних патчей, создавая более обобщенные и лаконичные векторы признаков. Этот процесс уменьшает размер входных данных для языковой модели, снижая требования к памяти и вычислительным ресурсам, при этом сохраняя важную визуальную информацию. В результате, модель может обрабатывать изображения быстрее и эффективнее, что особенно важно для задач, требующих анализа большого объема визуальных данных.
Трехэтапная Подготовка: Обучение Модели Научной Экспертизе
Модель проходит этап высококачественного промежуточного обучения (Mid-Training), в процессе которого используется крупномасштабный мультимодальный корпус данных. Этот корпус включает в себя разнообразные типы информации, такие как текст, изображения и структурированные данные, что позволяет модели усвоить широкий спектр научных знаний. Целью данного этапа является не специализированная подготовка к конкретным задачам, а формирование обширной базы общих научных понятий и фактов, необходимых для дальнейшей тонкой настройки и обучения с подкреплением. Объем и разнообразие данных в корпусе критически важны для обеспечения обобщающей способности модели и ее способности к решению новых, ранее не встречавшихся научных проблем.
Для дальнейшей оптимизации производительности в решении конкретных научных задач используется этап контролируемого обучения (Supervised Fine-Tuning, SFT). В процессе SFT модель обучается на специализированных наборах данных, содержащих расширенные представления химических структур в формате Extended SMILES (E-SMILES). E-SMILES позволяет кодировать сложные молекулярные структуры, включая информацию о стереохимии и других важных характеристиках, что необходимо для точного моделирования и предсказания химических свойств и реакций. Использование E-SMILES в обучающих данных обеспечивает более эффективное освоение моделью принципов химической номенклатуры и структуры.
Обучение с подкреплением (RL) используется для существенного улучшения возможностей модели в области долгосрочного рассуждения. В процессе обучения используется датасет, основанный на выявлении расхождений (Discrepancy-Driven RL Dataset), который позволяет модели учиться на ошибках и улучшать свои прогнозы. Для оптимизации политики обучения применяется алгоритм Group Sequence Policy Optimization (GSPO), позволяющий эффективно обрабатывать последовательности действий и повышать стабильность обучения. GSPO способствует более эффективному исследованию пространства стратегий, что критически важно для задач, требующих планирования и прогнозирования на больших временных горизонтах. Использование данного подхода позволило добиться значительного улучшения результатов в задачах, требующих комплексного анализа и построения логических цепочек.
Усиленное Мышление и Эффективность: Ключевые Преимущества Innovator-VL-8B
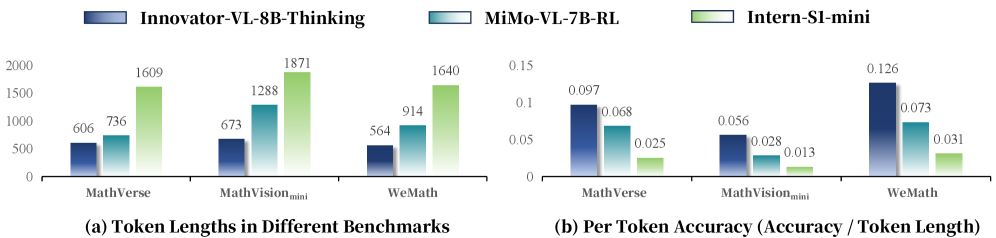
Инновационная модель Innovator-VL-8B демонстрирует существенный прогресс в области мультимодального рассуждения, успешно справляясь с широким спектром научных задач. В ходе тестирования на различных бенчмарках, модель достигла среднего балла в 61.83%, что свидетельствует о ее способности эффективно интегрировать и анализировать информацию, представленную в различных форматах — от текста и изображений до графиков и диаграмм. Такая способность к комплексному анализу данных позволяет модели выявлять закономерности и делать обоснованные выводы, что особенно ценно в областях, требующих обработки большого объема разнородной информации, таких как биология, химия и материаловедение. Полученные результаты подтверждают потенциал Innovator-VL-8B в качестве мощного инструмента для поддержки и ускорения научных исследований.
Конструкция Innovator-VL-8B отличается повышенной эффективностью использования токенов, что позволяет достигать высоких результатов при значительно меньших вычислительных затратах. В отличие от многих современных моделей, требующих огромного количества ресурсов для обработки информации, данная разработка оптимизирована для экономичного использования данных. Это достигается благодаря специальным алгоритмам обработки и сжатия информации, позволяющим модели более эффективно извлекать суть из входных данных и генерировать релевантные ответы. Такая эффективность открывает возможности для использования Innovator-VL-8B на устройствах с ограниченными ресурсами и для решения задач, требующих высокой скорости обработки больших объемов данных, что делает ее ценным инструментом для широкого спектра научных исследований и практических приложений.
Сочетание выдающихся способностей к логическому мышлению и высокой эффективности делает Innovator-VL-8B ценным инструментом для ускорения научных открытий. Модель способна решать сложные задачи, требующие анализа данных из различных источников, при этом используя относительно небольшое количество вычислительных ресурсов. Это особенно важно в областях, где обработка больших объемов информации является ключевым фактором, таких как геномика, материаловедение и астрофизика. Благодаря оптимизации использования токенов, Innovator-VL-8B позволяет исследователям получать значимые результаты быстрее и экономичнее, открывая новые возможности для инноваций и продвижения научного знания. Такая комбинация характеристик делает модель перспективной платформой для автоматизации научных процессов и поддержки принятия решений в различных областях исследований.

Представленная работа демонстрирует элегантность подхода к созданию научных мультимодальных больших языковых моделей. Innovator-VL, в отличие от многих современных систем, делает акцент на прозрачности обучения и эффективности использования данных. Это особенно важно, поскольку позволяет исследователям не только получать впечатляющие результаты в научной области, но и понимать, как именно модель приходит к своим выводам. Как однажды заметил Ян Лекун: «Машинное обучение — это не волшебство, а инженерия». Данный подход к разработке, сфокусированный на научном обосновании и ясности, подтверждает эту мысль, представляя собой гармоничное сочетание формы и функции в области искусственного интеллекта. Модель демонстрирует прогресс в понимании химических структур и выполнении научных рассуждений, что является значительным шагом вперед.
Куда же дальше?
Представленная работа, демонстрируя элегантность в достижении результатов при ограниченном объеме данных, всё же оставляет открытым вопрос о самой природе “понимания” в контексте больших языковых моделей. Достигнуты впечатляющие результаты в распознавании химических структур, но способность к истинному научному открытию, к генерации гипотез, выходящих за рамки проанализированных данных, остаётся областью для дальнейших исследований. Слишком часто “интеллект” машин проявляется как умение искусно компилировать существующие знания, а не создавать новые.
Очевидной задачей является расширение мультимодальности. Визуальная информация — лишь один аспект научного познания. Необходимо интегрировать данные, полученные из различных сенсоров, экспериментальных установок, а также учитывать контекст, в котором эти данные были получены. Крайне важна прозрачность обучения, но недостаточно просто заявить о ней — необходимо разработать инструменты, позволяющие отследить процесс принятия решений моделью и выявить потенциальные предвзятости.
В конечном счёте, истинный прогресс заключается не в создании всё более сложных моделей, а в разработке принципиально новых подходов к машинному обучению, которые позволят машинам не просто “имитировать” интеллект, а действительно понимать окружающий мир. И тогда, возможно, мы увидим не просто автоматизацию научных исследований, а рождение новых научных парадигм.
Оригинал статьи: https://arxiv.org/pdf/2601.19325.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
2026-01-28 16:59