Автор: Денис Аветисян
Исследование описывает практический процесс обучения научной языковой модели на основе огромного массива препринтов с платформы arXiv, подчеркивая ключевые аспекты подготовки данных и воспроизводимости результатов.
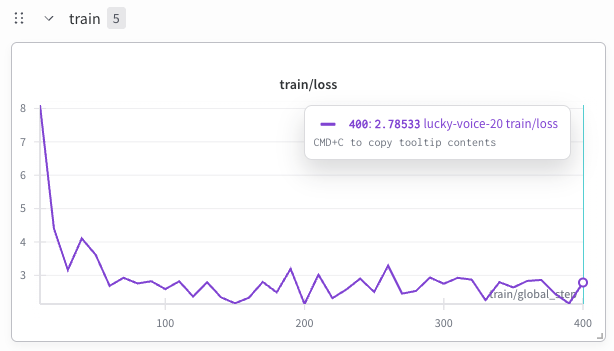
В статье подробно рассматривается обучение 1,36-миллиардной параметрической языковой модели, основанной на данных arXiv, с акцентом на токенизацию, предобработку данных и динамику обучения.
Несмотря на впечатляющие возможности современных больших языковых моделей, практические аспекты обучения специализированных научных моделей из необработанных источников остаются малоизученными. В работе ‘ArXiv-to-Model: A Practical Study of Scientific LM Training’ представлено детальное исследование обучения научной языковой модели с 1.36 млрд параметров на основе данных arXiv по математике, информатике и теоретической физике. Полученные результаты демонстрируют, что решения, принятые на этапах предварительной обработки данных и токенизации, существенно влияют на стабильность обучения и конечный объем полезных токенов, а инфраструктурные ограничения могут конкурировать с вычислительными мощностями. Каким образом эти инженерные аспекты могут быть оптимизированы для создания эффективных и воспроизводимых научных моделей при ограниченных вычислительных ресурсах?
Раскрывая сложность: вызов понимания научных текстов
Существующие языковые модели испытывают значительные трудности при работе со сложным и специализированным языком научной литературы. В отличие от обычного текста, научные статьи изобилуют узкоспециализированной терминологией, сложными синтаксическими конструкциями и часто используют математические формулы, такие как E=mc^2, что требует от модели не только лингвистических, но и предметных знаний. Модели, обученные на общих корпусах текстов, зачастую не способны правильно интерпретировать научный контекст, понимать взаимосвязь между различными понятиями и извлекать значимую информацию из научных публикаций. Это приводит к неточностям в анализе, затрудняет автоматическое реферирование и ограничивает возможности использования искусственного интеллекта в научных исследованиях. Необходимость преодоления этих ограничений стимулирует разработку новых подходов к обработке естественного языка, ориентированных на специфику научной коммуникации.
Успешная обработка архивов, созданных в формате LaTeX, и понимание научного контекста требует принципиально новых подходов к представлению данных и архитектуре моделей. Традиционные методы, ориентированные на естественный язык, часто оказываются неэффективными при работе с \LaTeX-кодом, содержащим сложные математические формулы, символы и специфическую структуру. Необходимо разрабатывать модели, способные не только распознавать отдельные символы и уравнения, но и понимать их взаимосвязь в контексте научной статьи. Это предполагает создание специализированных представлений данных, учитывающих иерархическую структуру \LaTeX-документов и семантику математических выражений, а также разработку новых архитектур, способных эффективно обрабатывать и интерпретировать эти данные. Такой подход позволит значительно улучшить качество автоматической обработки научных текстов, облегчая поиск, анализ и синтез информации для исследователей и специалистов.
Создавая основу: конвейер обработки данных
В основе нашей модели лежит тщательно разработанный конвейер предварительной обработки данных, необходимый для учета специфических характеристик данных arXiv. Данные arXiv, представляющие собой научные публикации в формате LaTeX и текстовых файлов, требуют особого подхода к очистке и структурированию. Конвейер включает в себя этапы извлечения метаданных, удаления нерелевантной информации, нормализации текстовых данных и преобразования LaTeX-формул \sum_{i=1}^{n} x_i в формат, пригодный для машинного обучения. От качества предварительной обработки напрямую зависит эффективность обучения модели и точность полученных результатов, поскольку некорректно обработанные данные могут привести к искажению статистических закономерностей и снижению производительности.
Конвейер обработки данных включает в себя фильтрацию метаданных для повышения релевантности набора данных и продвинутую токенизацию, необходимую для корректного представления сложной научной нотации. Фильтрация метаданных позволяет исключить из рассмотрения устаревшие или нерелевантные статьи, а также стандартизировать информацию об авторах и категориях. Продвинутая токенизация, в свою очередь, учитывает специфику научных текстов, включая математические формулы, химические соединения и физические величины, обеспечивая их точное представление в виде последовательности токенов, пригодных для обучения модели. Например, E=mc^2 будет разбито на отдельные токены, учитывающие символы и их взаимосвязи, а не просто как набор символов. Это критически важно для задач, требующих понимания научных концепций и взаимосвязей.
Качественная предварительная обработка данных является критически важным фактором, определяющим эффективность обучения модели и достоверность полученных результатов. Высококачественный набор данных, полученный в результате фильтрации метаданных и продвинутой токенизации, обеспечивает более точное представление научных текстов, что позволяет модели извлекать значимую информацию и строить более надежные прогнозы. Отсутствие ошибок и неточностей в данных напрямую влияет на производительность модели, позволяя ей достигать максимального потенциала обучения и обеспечивая получение осмысленных выводов из анализа данных arXiv.
Архитектурные решения и стратегии обучения
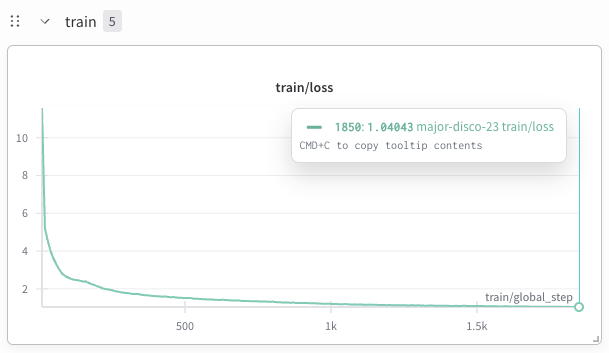
В качестве базовой архитектуры была выбрана LLaMA, что обусловлено ее подтвержденной эффективностью в задачах языкового моделирования. LLaMA, разработанная компанией Meta AI, представляет собой авторегрессионную модель, основанную на архитектуре Transformer. Ее ключевые особенности включают в себя использование предварительного обучения на огромном объеме текстовых данных и масштабируемость, что позволяет достигать высоких результатов в различных задачах обработки естественного языка. Выбор LLaMA позволил нам воспользоваться преимуществами существующих наработок и оптимизаций, сократив время и ресурсы, необходимые для разработки базовой модели.
Для снижения вычислительных затрат при обучении модели на большом объеме данных были применены методы ZeRO оптимизации и использование 16-битной плавающей точки (Bfloat16). ZeRO (Zero Redundancy Optimizer) позволяет разделить параметры модели, градиенты и состояния оптимизатора между несколькими устройствами, значительно сокращая потребление памяти. Использование Bfloat16 вместо стандартной 32-битной плавающей точки (float32) уменьшает требования к памяти вдвое, сохраняя при этом приемлемую точность вычислений, что позволяет увеличить размер обучаемой модели и/или использовать более крупные пакеты данных.
Для повышения производительности и стабильности обучения модели были интегрированы RoPE (Rotary Positional Embeddings) для кодирования позиций и RMSNorm для нормализации слоев. RoPE обеспечивает эффективное представление информации о порядке токенов в последовательности, что критически важно для обработки длинных научных текстов. RMSNorm, являясь вариантом Layer Normalization, стабилизирует динамику обучения, предотвращая взрыв или затухание градиентов, особенно при использовании больших размеров пакетов и сложных архитектур. Комбинация этих методов позволила добиться более бырой сходимости и улучшения обобщающей способности модели.
Для повышения эффективности обучения модели сложным научным концепциям была применена стратегия куррикулярного обучения. Данный подход предполагает постепенное увеличение сложности обучающих данных: модель сначала обучается на простых примерах и задачах, а затем переходит к более сложным и абстрактным понятиям. Это позволяет избежать перегрузки модели на начальных этапах обучения и способствует более эффективному усвоению информации. На начальных этапах обучения использовались данные, содержащие базовые определения и факты, постепенно переходя к сложным научным статьям и экспериментальным данным. Такой подход позволил добиться значительного улучшения показателей модели при решении сложных научных задач.
Проверка производительности и анализ масштабируемости
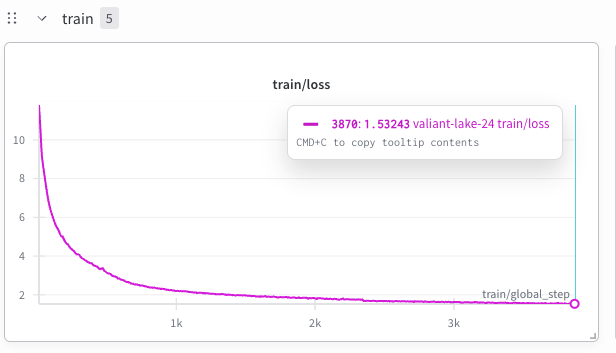
Проведенный анализ динамики обучения позволил оценить влияние размера обучающего набора данных на эффективность модели. Исследователи сравнили производительность модели, обученной на полном объеме данных, с результатами, полученными при использовании существенно меньшего набора. Этот подход позволил выявить закономерности в процессе обучения и определить, как размер данных влияет на скорость сходимости и конечную точность модели. Полученные данные продемонстрировали, что модель способна эффективно обучаться как на больших, так и на ограниченных объемах данных, что открывает возможности для адаптации к различным условиям и ресурсам, доступным в ходе исследований. Анализ выявил, что даже при уменьшении размера данных, модель сохраняет способность к обобщению и решению сложных научных задач.
В процессе обучения модели использовались принципы закона Чинчиллы, что позволило оптимизировать соотношение между количеством параметров модели и объемом обучающих токенов. Данный подход, основанный на эмпирических данных о взаимосвязи между размером модели, размером обучающего набора и достижимой производительностью, позволил эффективно использовать вычислительные ресурсы и добиться высокой эффективности обучения даже при ограниченном объеме данных. Закон Чинчиллы предполагает, что для достижения оптимальной производительности необходимо тщательно балансировать между размером модели и количеством токенов, используемых в процессе обучения, что и было реализовано в данном исследовании. Это позволило создать модель с 1.36 миллиардами параметров, обученную на корпусе из 52.18 миллиардов токенов, демонстрирующую высокую производительность в обработке научных текстов.
Исследование продемонстрировало, что разработанная модель способна эффективно обучаться как на обширных массивах данных, так и при их ограниченном объеме. Эта особенность открывает широкие возможности для применения модели в различных научных областях, где доступ к данным может быть затруднен или неполным. Способность адаптироваться к разным условиям обучения делает модель универсальным инструментом для исследователей, позволяя получать значимые результаты даже при ограниченных вычислительных ресурсах или неполных данных. Такая гибкость особенно ценна в быстро развивающихся областях науки, где новые данные постоянно появляются и требуют быстрой адаптации моделей.
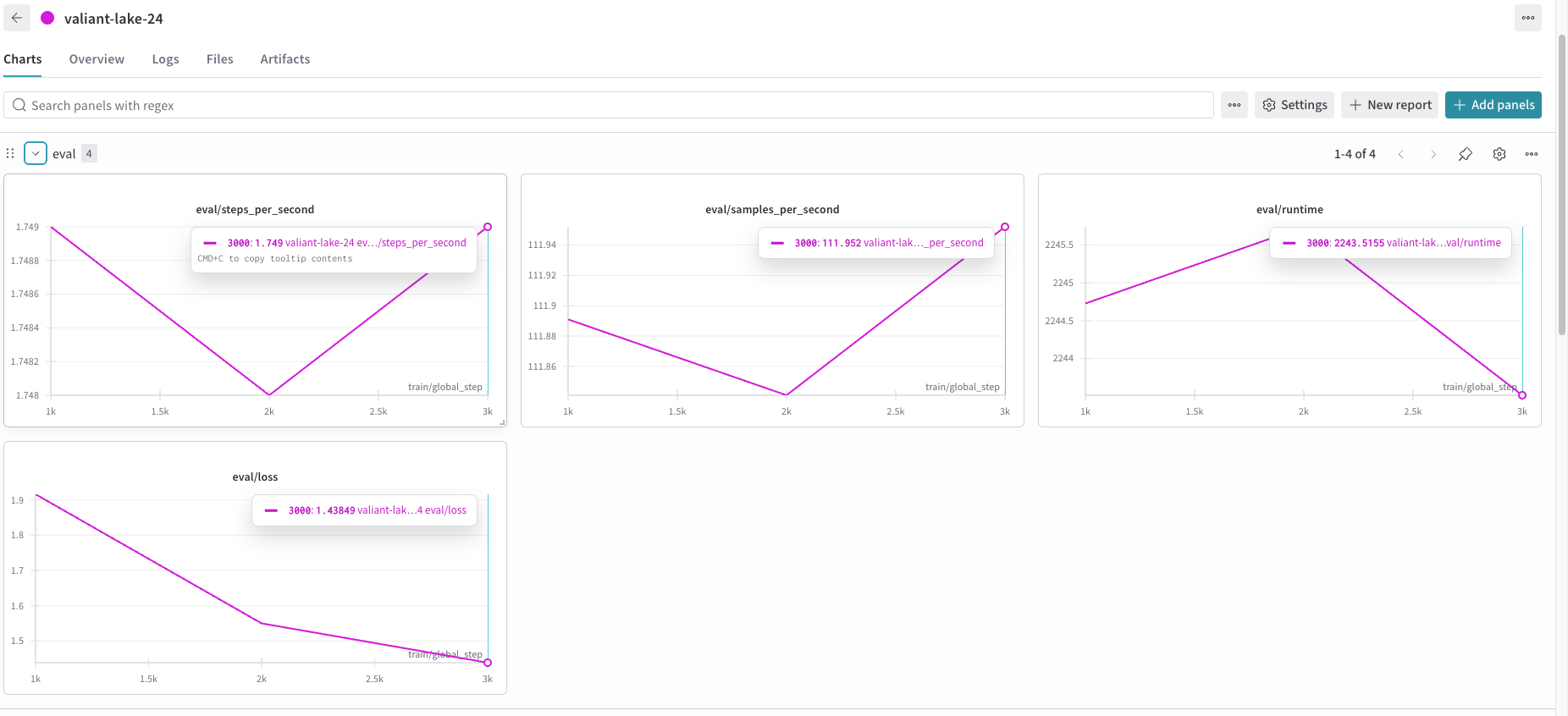
Успешно обученная научная языковая модель, насчитывающая 1,36 миллиарда параметров и прошедшая обучение на корпусе из 52,18 миллиардов токенов, демонстрирует высокую производительность, достигая перплексии приблизительно 4,2 на отложенных научных данных. Данная модель способна обрабатывать контекст длиной до 4096 токенов, хотя в процессе обучения использовалась длина контекста в 768 токенов. Это свидетельствует о потенциале модели к эффективной экстраполяции и обработке более длинных последовательностей, что открывает возможности для анализа и синтеза сложных научных текстов и данных.
Исследование, представленное в данной работе, демонстрирует, что создание эффективной научной языковой модели требует не только алгоритмической проработки, но и глубокого понимания принципов обработки данных. Авторы подчеркивают важность токенизации и предобработки данных, что позволяет извлечь максимум информации из корпуса текстов arXiv. Этот подход перекликается с мыслью Андрея Николаевича Колмогорова: «Вероятность того, что в конечном случае мы не сможем предсказать, равна единице». Подобно тому, как математик стремится к точности предсказаний, исследователи стремятся к оптимизации данных, осознавая, что полная предсказуемость в сложных системах недостижима, но минимизация неопределенности — вполне реальная задача. В данном исследовании, акцент на воспроизводимости обучения также важен, как и понимание принципов работы самой модели.
Куда дальше?
Представленная работа, по сути, лишь вскрытие первого слоя. Создание рабочей языковой модели для научной литературы — это не столько инженерная задача, сколько попытка реверс-инжиниринга самой структуры знания. Успешное обучение модели на 1.36 миллиардах параметров — это, конечно, приятный артефакт, но истинный вопрос заключается в том, насколько адекватно эта модель отражает не просто статистику текстов, а логику научного поиска. Очевидно, что текущие стратегии токенизации и предобработки данных — это лишь приближение, компромисс между вычислительной эффективностью и семантической точностью.
Следующим шагом видится отказ от упрощенных представлений о “научном тексте” как о последовательности токенов. Необходимо исследовать способы интеграции метаданных, структуры статей, цитирований — всего того, что делает научную литературу уникальной. Более того, возникает вопрос о возможности создания моделей, способных не просто генерировать текст, но и формулировать гипотезы, выявлять противоречия, предлагать направления для дальнейших исследований. Это уже не просто машинный перевод, а эмуляция процесса научного открытия.
И, конечно, не стоит забывать о воспроизводимости. В мире, где публикация — это гонка за первенством, а не стремление к истине, создание действительно воспроизводимых моделей — это акт саботажа, попытка вернуть науку к её корням. В конечном итоге, ценность этой работы не в самой модели, а в вопросах, которые она ставит перед сообществом.
Оригинал статьи: https://arxiv.org/pdf/2602.17288.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Временная запутанность: от хаоса к порядку
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Квантовое программирование: Карта развивающегося мира
- Предел возможностей: где большие языковые модели теряют разум?
- ЭКГ-анализ будущего: От данных к цифровым биомаркерам
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Сердце музыки: открытые модели для создания композиций
- Квантовые кольца: новые горизонты спиновых токов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
2026-02-21 01:21