Автор: Денис Аветисян
Новая платформа объединяет возможности больших языковых моделей и облачных вычислений для автоматизации научных исследований и ускорения открытий в области катализа.
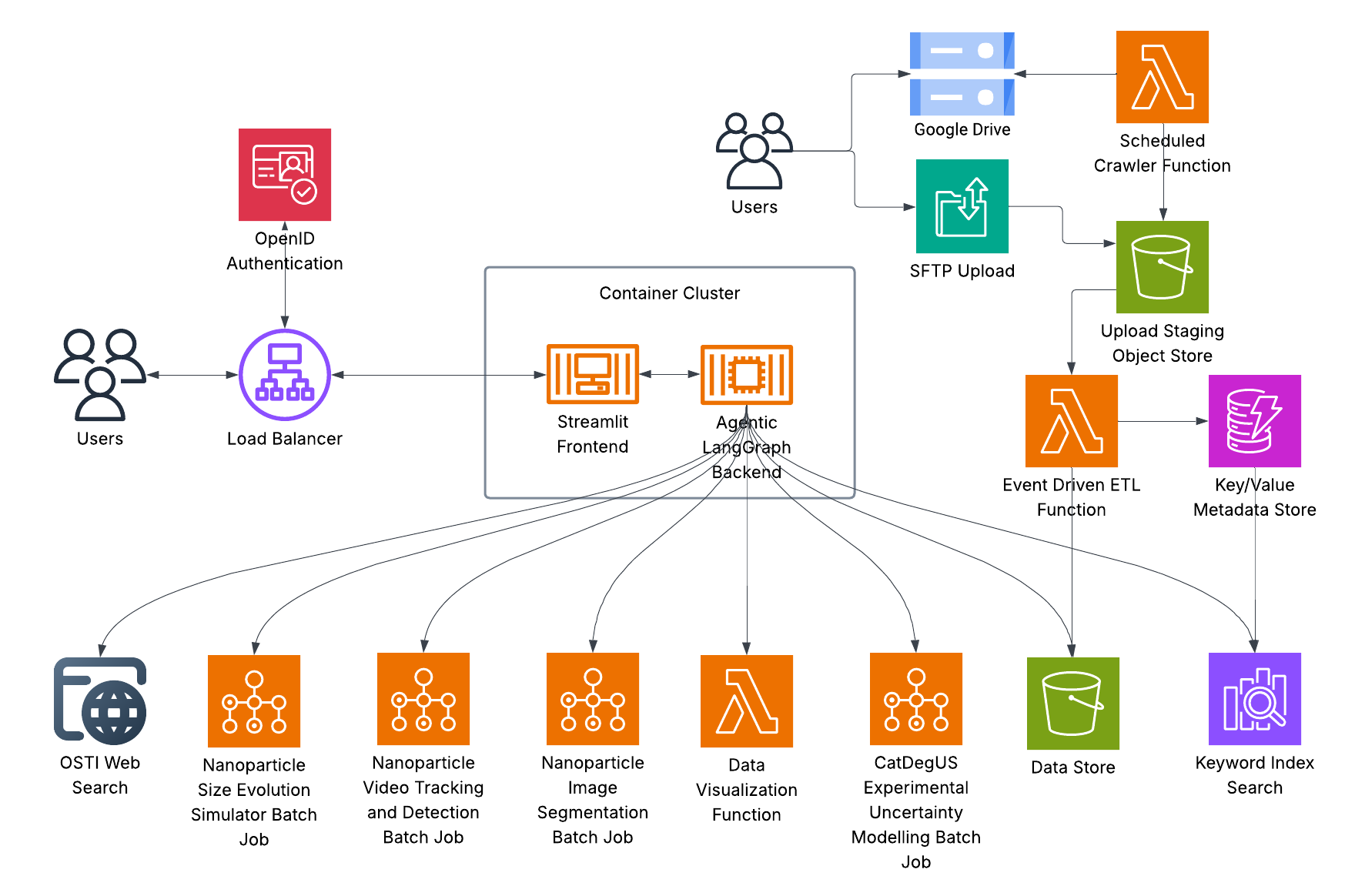
Представлен облачный многоагентный рабочий процесс, использующий большие языковые модели для автоматизации экспериментов и интеграции инструментов в исследованиях катализа.
Несмотря на растущую популярность больших языковых моделей (LLM), их применение в сложных научных задачах ограничено отсутствием возможности выполнения вычислений и принятия самостоятельных решений. В работе ‘A Cloud-based Multi-Agentic Workflow for Science’ представлен облачный многоагентный фреймворк, объединяющий LLM и внешние инструменты для автоматизации научных рабочих процессов, в частности, исследований в области катализа. Предложенная система, основанная на взаимодействии специализированных агентов под управлением супервизора, обеспечивает высокую точность маршрутизации задач (90%) и успешное их выполнение (97.5% для синтетических и 91% для реальных задач), при этом демонстрируя сопоставимую или превосходящую точность по сравнению с передовыми моделями. Сможет ли подобный подход стать стандартом для автоматизации научных исследований в различных областях и ускорить процесс открытия новых знаний?
За гранью текста: Необходимость агентского научного поиска
Традиционные научные исследования зачастую сталкиваются с существенными задержками из-за необходимости ручной обработки и систематизации данных, а также разработки гипотез. Этот процесс, требующий значительных временных затрат и усилий исследователей, создает узкие места в процессе открытия новых знаний. В особенности это касается областей, генерирующих огромные объемы информации, таких как геномика или астрономия. Необходимость вручную отбирать релевантные данные, проверять их достоверность и затем формулировать проверяемые гипотезы существенно замедляет темпы научных исследований и ограничивает возможности для масштабных открытий. Подобная ситуация подчеркивает потребность в автоматизированных системах, способных самостоятельно обрабатывать данные, выявлять закономерности и предлагать новые направления для исследований, освобождая ученых от рутинной работы и позволяя им сосредоточиться на творческих аспектах научной деятельности.
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) оперировать информацией, выходящей за рамки простого текста, их возможности в решении сложных задач, требующих глубокого логического вывода и планирования, остаются ограниченными. БЯМ демонстрируют успехи в извлечении знаний и генерации гипотез, однако им не хватает способности к автономному исследованию, проверке и уточнению этих гипотез в динамичной среде. В связи с этим, возникает необходимость в разработке более структурированных, “агентных” подходов, где БЯМ выступают не просто генераторами текста, а компонентами интеллектуальных систем, способных самостоятельно формулировать цели, планировать действия, взаимодействовать с различными инструментами и источниками данных, а также оценивать результаты своих действий для достижения поставленной научной задачи. Такой подход позволит преодолеть ограничения существующих моделей и значительно ускорить процесс научных открытий.
Современные научные исследования всё чаще сталкиваются с необходимостью обработки разнородных данных — от геномных последовательностей и спектральных анализов до изображений, полученных с микроскопов и телескопов. Существующие методы анализа, как правило, разрабатывались для работы с конкретным типом данных или ограниченным набором инструментов, что значительно затрудняет комплексное исследование. Интеграция этих разрозненных источников информации и обеспечение их совместного анализа требует принципиально новых подходов, позволяющих эффективно объединять различные инструменты и алгоритмы. Отсутствие такой интеграции не только замедляет процесс открытия, но и может приводить к упущению важных взаимосвязей и закономерностей, скрытых в многообразии научных данных. Успешное преодоление этой проблемы является ключевым фактором для ускорения научных открытий в различных областях, включая биологию, химию, физику и материаловедение.
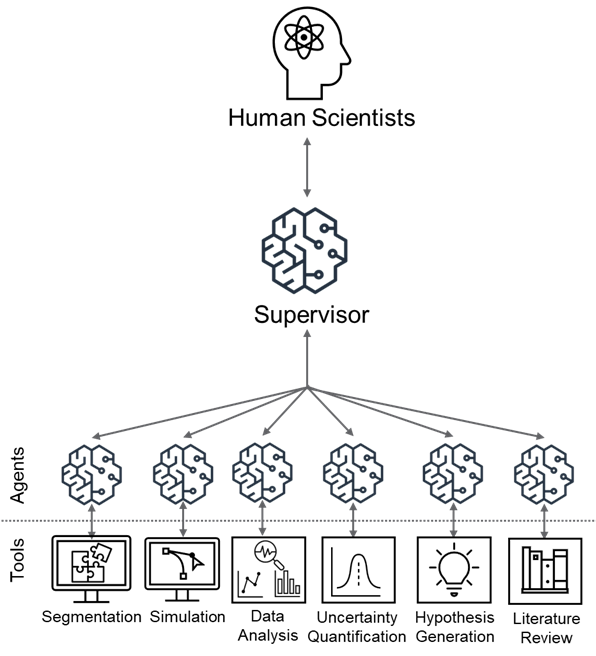
Оркестровка открытия: Мультиагентный фреймворк
Представленный многоагентный фреймворк обеспечивает координацию решения задач посредством делегирования специализированных подзадач отдельным LLM-агентам. Каждый агент выполняет узко определенную функцию, что позволяет повысить эффективность и точность обработки информации. Фреймворк позволяет распределить сложные задачи на более мелкие, управляемые компоненты, каждый из которых обрабатывается специализированным агентом, что значительно снижает когнитивную нагрузку и повышает общую производительность системы. Использование LLM в качестве агентов позволяет системе адаптироваться к различным типам задач и данным, обеспечивая гибкость и масштабируемость.
Агент-супервизор выполняет функцию центрального координатора в многоагентной системе, обеспечивая последовательное выполнение рабочего процесса. Он отвечает за распределение задач между отдельными LLM-агентами, отслеживание их выполнения и сбор полученных результатов. Коммуникация между агентами осуществляется через супервизора, который гарантирует согласованность данных и предотвращает конфликты. Функционал супервизора включает в себя анализ промежуточных результатов, принятие решений о дальнейших шагах и динамическую перенастройку рабочего процесса в зависимости от полученной информации, что обеспечивает эффективное и надежное решение поставленной задачи.
Архитектура системы обеспечивает модульность и масштабируемость за счет возможности добавления и удаления отдельных агентов и инструментов без изменения основной функциональности. Это достигается путем использования четко определенных интерфейсов взаимодействия между агентами, позволяющих им обмениваться данными и запросами в стандартизированном формате. Интеграция разнообразных источников данных осуществляется посредством адаптеров, которые преобразуют данные в формат, понятный системе, и обеспечивают доступ к ним для специализированных агентов. Масштабируемость обеспечивается возможностью параллельного выполнения задач несколькими агентами и динамического распределения ресурсов в зависимости от текущей нагрузки и сложности решаемых задач.
Специализированные агенты: От данных к гипотезе
Агент обзора литературы использует API OSTI (Office of Scientific and Technical Information) для эффективного сбора релевантных научных публикаций, формируя тем самым всеобъемлющую базу знаний. API OSTI предоставляет доступ к обширной коллекции исследовательских работ, отчетов и данных, финансируемых Министерством энергетики США. Агент автоматически запрашивает и обрабатывает эти данные, используя заданные критерии поиска, такие как ключевые слова, авторы и даты публикации. Результатом является структурированный набор научных материалов, который служит основой для дальнейшего анализа и генерации гипотез, обеспечивая актуальную и проверенную информацию.
Агент анализа данных осуществляет разведочный анализ данных и выявление ключевых тенденций, используя библиотеку Pydantic для обеспечения строгой проверки данных. Pydantic позволяет определить схемы данных и автоматически валидировать входящие данные, гарантируя их соответствие ожидаемому формату и типу. Это включает проверку типов данных, обязательных полей и диапазонов значений, что существенно повышает надежность и точность результатов анализа. Агент способен обрабатывать структурированные и полуструктурированные данные, выявляя статистические закономерности, корреляции и аномалии, которые могут быть полезны для формирования гипотез.
Агент моделирования, использующий контейнеризацию Docker для обеспечения воспроизводимости результатов, предназначен для моделирования сложных каталитических процессов. Это позволяет исследовать поведение наночастиц в различных условиях, включая изменения температуры, давления и состава среды. Контейнеризация с помощью Docker гарантирует, что моделирование может быть повторено на любой платформе, поддерживающей Docker, с идентичными результатами, что критически важно для верификации и валидации научных исследований. Моделирование охватывает широкий спектр явлений, включая адсорбцию, диффузию и реакции на поверхности наночастиц, предоставляя ценные сведения о механизмах катализа и позволяя прогнозировать эффективность катализаторов.
Агент генерации гипотез осуществляет синтез информации, полученной от других специализированных агентов — агента обзора литературы, агента анализа данных и агента моделирования. Этот процесс включает в себя интеграцию результатов поиска научных публикаций, выявленных трендов в данных и результатов моделирования каталитических процессов. В результате синтеза формируются новые, проверяемые гипотезы, предназначенные для дальнейшей экспериментальной верификации и уточнения понимания исследуемых явлений. Гипотезы, генерируемые агентом, структурированы таким образом, чтобы обеспечить возможность количественной оценки и статистической проверки, что необходимо для подтверждения или опровержения выдвигаемых предположений.
Валидация и развертывание: Бенчмаркинг и доступность
Эффективность разработанного фреймворка наглядно демонстрируется его применением к области катализа — сложной научной дисциплине, требующей всестороннего анализа. Катализ, как процесс, включает в себя множество взаимосвязанных факторов, таких как структура катализатора, механизм реакции и влияние окружающей среды. Фреймворк позволяет комплексно исследовать эти аспекты, объединяя данные из различных источников и используя продвинутые алгоритмы для прогнозирования и оптимизации каталитических процессов. Способность фреймворка успешно справляться с задачами в такой сложной области подтверждает его универсальность и потенциал для решения широкого спектра научных проблем, требующих глубокого анализа и синтеза информации.
Оценка эффективности предложенной системы проводилась на базе ChembBench — авторитетного набора задач в области химии, требующего комплексного анализа. Результаты демонстрируют высокую производительность: система успешно выполняет 90.49% поставленных задач, а точность ответов составляет 61%. Данный показатель сопоставим с результатами, достигаемыми передовыми современными моделями в данной области, что подтверждает состоятельность разработанного подхода и его потенциал для решения сложных задач в химической науке. Высокая результативность на ChembBench свидетельствует о надежности и практической ценности предложенной системы для исследователей, работающих в области химии и смежных дисциплин.
Для обеспечения широкой доступности и удобства использования, разработанная платформа оснащена интуитивно понятным пользовательским интерфейсом, реализованным с помощью библиотек Streamlit и FastAPI. Это позволяет исследователям легко взаимодействовать с системой, загружать данные, запускать анализ и визуализировать полученные результаты без необходимости глубоких знаний в области программирования или машинного обучения. Интерфейс обеспечивает гибкость в настройке параметров и позволяет проводить детальное исследование различных аспектов каталитических процессов, значительно упрощая процесс научного открытия и способствуя более эффективному использованию возможностей разработанной системы.
Для повышения масштабируемости и надежности многоагентной системы использовался LangGraph, обеспечивающий иерархическую координацию. Данный подход позволяет эффективно организовывать взаимодействие между агентами, разделяя сложные задачи на более мелкие, управляемые подзадачи. Иерархическая структура не только упрощает процесс решения, но и повышает устойчивость системы к ошибкам, поскольку отказ одного агента не приводит к полному сбою. LangGraph предоставляет инструменты для определения иерархии, управления потоком данных между агентами и мониторинга их работы, что особенно важно при работе с крупномасштабными и сложными научными задачами, такими как анализ каталитических процессов. В результате, система демонстрирует повышенную эффективность и надежность при решении сложных задач, сохраняя при этом гибкость и адаптивность к различным условиям.
Будущее научных агентов
Архитектура данной системы построена по модульному принципу, что обеспечивает гибкость и масштабируемость. Благодаря этому, новые агенты и инструменты могут быть легко интегрированы без необходимости внесения значительных изменений в существующую структуру. Такая конструкция позволяет оперативно адаптироваться к меняющимся потребностям научных исследований и быстро внедрять инновационные методы анализа данных. Модульность не только упрощает процесс расширения функциональности системы, но и способствует повышению её надёжности, поскольку отдельные компоненты могут быть обновлены или заменены без влияния на работу остальных. Данный подход открывает широкие возможности для создания динамичной и самообучающейся платформы, способной решать широкий спектр научных задач.
В дальнейшем планируется усовершенствование способности агентов к логическому мышлению и включение в их арсенал более сложных методов анализа данных. Разработчики стремятся к тому, чтобы агенты не просто находили информацию, но и могли устанавливать причинно-следственные связи, делать обоснованные выводы и предлагать гипотезы. Это потребует интеграции передовых алгоритмов машинного обучения, включая нейронные сети и методы глубокого обучения, а также расширение контекстного понимания и способности к абстракции. Особое внимание будет уделено способности агентов к самообучению и адаптации к новым данным, что позволит им непрерывно совершенствовать свои навыки и повышать эффективность работы в различных научных областях.
Исследования показали, что точность маршрутизации агентов в разработанной системе достигает 90% для всех агентов, что свидетельствует о высокой эффективности алгоритмов распределения задач. Несмотря на общую высокую точность, агент, отвечающий за моделирование — “Simulation agent” — демонстрирует результат в 75%. Этот показатель указывает на сложность задач, связанных с моделированием, и необходимость дальнейшей оптимизации алгоритмов для повышения его эффективности. В целом, достигнутая точность маршрутизации позволяет надеяться на автоматизацию значительной части научных процессов и ускорение темпов научных открытий.
Поддержание функционирования данной системы агентов оценивается в 1500 долларов США в месяц. Значительная часть этой суммы, приблизительно 50%, приходится на затраты, связанные с созданием и поддержкой ключевого индекса. Этот индекс обеспечивает быстрый и эффективный поиск релевантной научной информации, что критически важно для работы агентов. Оптимизация и масштабирование ключевого индекса является приоритетной задачей, поскольку это напрямую влияет на общую стоимость владения системой и ее способность обрабатывать растущие объемы данных. Экономическая эффективность предложенного подхода, несмотря на первоначальные затраты на индекс, представляется перспективной в долгосрочной перспективе, учитывая потенциал автоматизации научных исследований и ускорения темпов открытий.
Предложенный агентский подход обладает значительным потенциалом для радикального преобразования научных рабочих процессов в различных дисциплинах, способствуя ускорению темпов открытия и инноваций. Вместо традиционного последовательного выполнения задач, система позволяет распределять отдельные этапы исследования между специализированными агентами, действующими параллельно и автономно. Такая архитектура не только повышает эффективность, но и открывает возможности для автоматизации рутинных операций, высвобождая ресурсы для более творческих и сложных задач. Благодаря способности к адаптации и интеграции новых инструментов, данная система может стать ключевым фактором в решении сложных научных проблем, требующих междисциплинарного подхода и обработки больших объемов данных, что, в конечном итоге, приведет к более быстрым и значимым научным прорывам.
Наблюдатель отмечает, что предложенная облачная платформа для автоматизации научных исследований, использующая мультиагентные системы и большие языковые модели, не является чем-то принципиально новым. Конечно, инструменты эволюционируют, и интеграция LLM-агентов выглядит элегантно, но суть остаётся прежней: стремление автоматизировать рутинные задачи и ускорить научные открытия. Как заметил Роберт Тарьян: «Совершенные алгоритмы — это прекрасно, но в конечном итоге важна лишь работающая система». И, вероятнее всего, эта «работающая система» потребует постоянной доработки и компромиссов, ведь автоматизация научных процессов — это всегда баланс между идеальной моделью и суровой реальностью экспериментов. В конце концов, даже самая изящная архитектура неизбежно обрастёт техдолгом.
Что дальше?
Представленная работа, как и большинство «революций» в автоматизации науки, лишь перекладывает сложность с одной ступени на другую. Автоматизация рабочих процессов с использованием LLM-агентов, безусловно, упрощает некоторые рутинные задачи в области катализа, но в конечном итоге неизбежно порождает новые вопросы. Например, верификация «творческих» предложений, сгенерированных агентами, потребует от исследователей ещё больше времени и усилий, чем просто выполнение экспериментов по заранее известным схемам. Каждая автоматизированная цепочка, рано или поздно, столкнётся с краевым случаем, который потребует вмешательства человека. И тогда станет ясно, что «автоматизация» — это просто способ сделать отладку сложнее.
Увлечение многоагентными системами, несомненно, интересно, но стоит помнить, что согласование действий множества LLM-агентов — это задача, граничащая с неразрешимостью. Каждый агент, стремясь к оптимизации своей части процесса, может случайно сорвать общую задачу. Идея интеграции разнородных инструментов через LLM — это, конечно, прогресс, но не стоит забывать, что каждый новый инструмент — это ещё одна точка отказа и дополнительная сложность в поддержке. Если код выглядит идеально — значит, его ещё никто не развернул в продакшене.
Вместо того чтобы гнаться за «автоматизацией ради автоматизации», возможно, стоит сосредоточиться на создании более простых и понятных инструментов, которые действительно помогают исследователям решать конкретные задачи. Каждая «революционная» технология завтра станет техдолгом. Продакшен всегда найдёт способ сломать элегантную теорию. И в конечном итоге, успех этой области будет определяться не количеством автоматизированных экспериментов, а качеством полученных результатов.
Оригинал статьи: https://arxiv.org/pdf/2601.12607.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Квантовая обработка данных: новый подход к повышению точности моделей
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые прорывы: Хорошее, плохое и смешное
2026-01-22 06:01