Автор: Денис Аветисян
Новый фреймворк MechEvalAgent предлагает автоматизированный подход к оценке исследований в области интерпретируемости ИИ, сочетая анализ текстов с проверкой исполняемого кода.
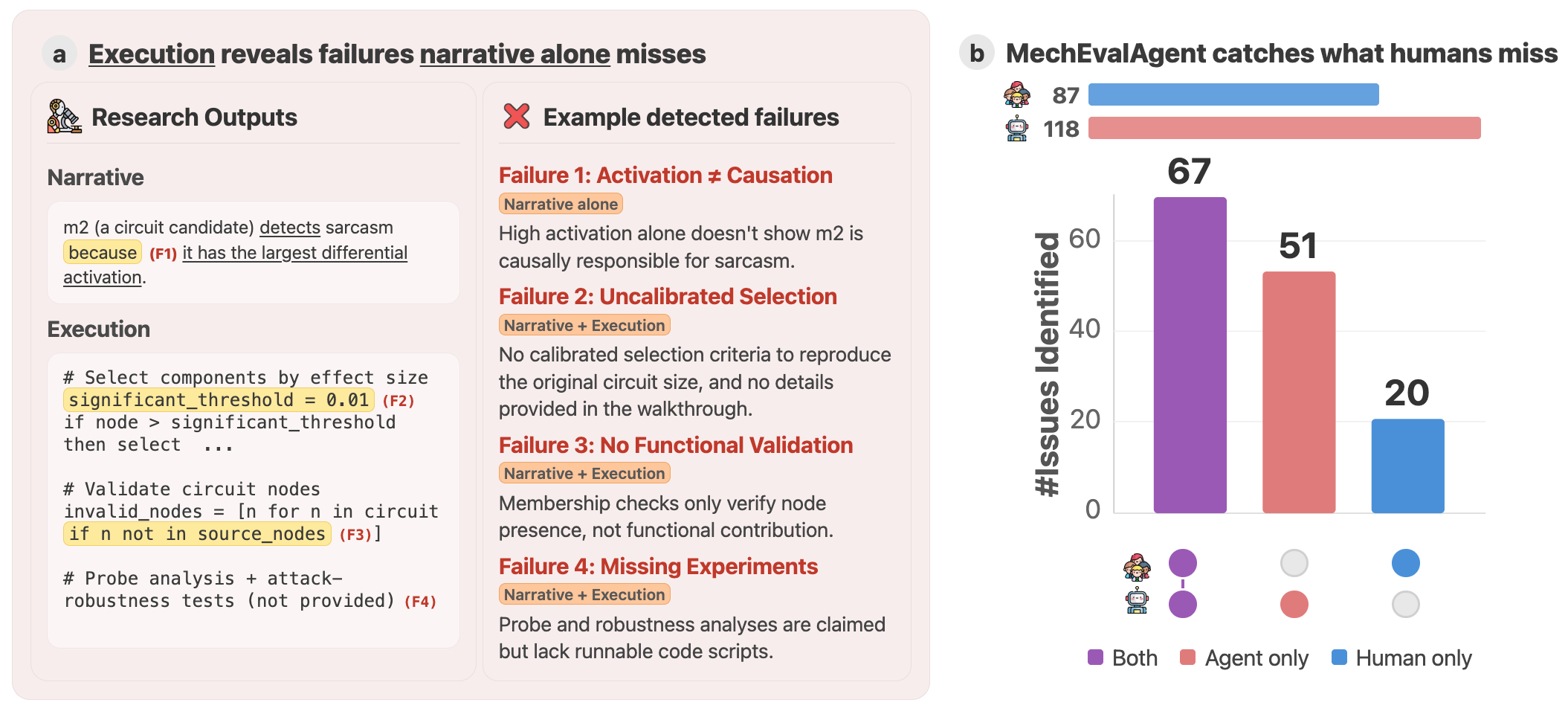
Представлена система автоматизированной оценки исследований в области интерпретируемости ИИ, основанная на сопоставлении нарратива и результатов выполнения кода.
Воспроизводимость научных исследований, особенно в быстро развивающихся областях, часто страдает от недостаточной проверки не только выводов, но и фактической реализации. В работе «The Story is Not the Science: Execution-Grounded Evaluation of Mechanistic Interpretability Research» предложен новый подход к оценке научных работ, основанный на проверке кода и данных, а не только на анализе текстового описания. Авторы демонстрируют, что автоматизированная система MechEvalAgent способна с высокой точностью выявлять методологические ошибки и дополнять оценку, проводимую экспертами-людьми. Может ли подобный подход, сочетающий нарративный анализ с проверкой исполняемого кода, стать стандартом в оценке научной строгости и надежности?
Пределы Оценки по «Повествованию»
Традиционная система экспертной оценки, основанная на анализе лишь текстового описания исследования — так называемая «оценка по повествованию» — сталкивается с растущими трудностями при проверке функционирования всё более сложных работ, особенно в таких областях, как интерпретируемость механизмов искусственного интеллекта. В то время как ранее эксперты могли оценить валидность исследования, опираясь на логику и полноту описания, современные исследования часто включают сложные алгоритмы и большие объемы кода, где несоответствие между описанием и фактической реализацией может остаться незамеченным. Это представляет особую проблему, поскольку даже небольшая ошибка в реализации может привести к неверным результатам и неверным выводам, что подрывает доверие к научным публикациям и замедляет прогресс в данной области. Таким образом, подход, полагающийся исключительно на текстовое описание, становится недостаточным для обеспечения надёжности и воспроизводимости современных научных исследований.
Традиционный подход к рецензированию, основанный исключительно на анализе описания исследования, оказывается уязвим перед скрытыми ошибками и неподтвержденными утверждениями. Отсутствие прямой проверки реализации алгоритмов и методов представляет серьезную проблему, поскольку несоответствие между заявленными принципами и фактическим исполнением может привести к неверным результатам. Даже незначительные погрешности в коде или методологии, не выявленные в процессе рецензирования, способны существенно повлиять на достоверность выводов, особенно в сложных областях, где детали реализации играют критическую роль. Таким образом, полагаться исключительно на текстовое описание становится недостаточным для обеспечения надежности и воспроизводимости научных исследований.
Особую сложность в проверке достоверности исследований представляет ситуация, когда в работе используется программный код. Несоответствие между описанием алгоритма и его фактической реализацией может привести к неверным результатам, даже если теоретическая основа исследования выглядит безупречной. Традиционный метод рецензирования, основанный лишь на анализе текста, не позволяет выявить подобные ошибки, поскольку не проверяет работоспособность кода напрямую. В результате, даже тщательно сформулированные выводы могут оказаться ошибочными из-за скрытых дефектов в программной реализации, что подчеркивает необходимость новых подходов к оценке научных работ, включающих автоматизированную проверку и тестирование кода.
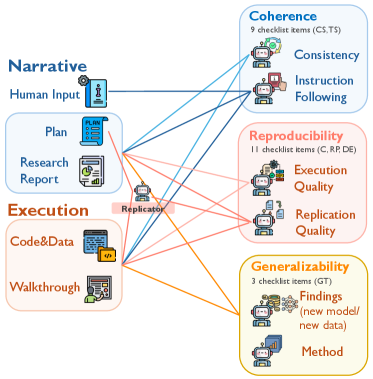
Оценка, Основанная на Выполнении: Новый Стандарт
Основой надежной оценки является метод «Оценка, основанная на выполнении» (Execution-Grounded Evaluation), который дополняет традиционный нарративный обзор путем непосредственной проверки работоспособности реализаций исследований через выполнение кода (Code Execution). Данный подход предполагает запуск предоставленного исследовательского кода в контролируемой среде для верификации заявленных результатов и функциональности. В отличие от анализа только опубликованных данных и описаний, «Оценка, основанная на выполнении» позволяет независимо подтвердить корректность реализации и воспроизводимость полученных результатов, что повышает доверие к научным исследованиям и способствует более объективной оценке их вклада.
Метод Execution-Grounded Evaluation предоставляет объективную оценку воспроизводимости научных результатов, подтверждая возможность получения идентичных результатов при независимом повторении эксперимента. Воспроизводимость определяется как способность других исследователей, используя предоставленный код и данные, добиться сопоставимых результатов, что является критически важным для подтверждения достоверности и надежности научного исследования. Этот процесс включает в себя автоматизированное выполнение кода исследователя в контролируемой среде, что позволяет исключить субъективные факторы и обеспечить последовательность в оценке. Подтверждение воспроизводимости существенно повышает доверие к опубликованным исследованиям и способствует более эффективному накоплению знаний в научной сфере.
Традиционная оценка научных работ основывается на анализе представленных утверждений и результатов, что может быть подвержено субъективным интерпретациям и неточностям. Проверка работоспособности представленного кода позволяет перейти от оценки заявленных результатов к подтверждению фактической работоспособности предложенного решения. Этот подход позволяет объективно установить, соответствует ли реализованный код заявленным алгоритмам и действительно ли он достигает заявленных результатов, что существенно повышает доверие к научным исследованиям и позволяет верифицировать не только что утверждается, но и что фактически работает.

Автоматизированная Оценка с MechEvalAgent
Разработка инструментов автоматизированной оценки, таких как MechEvalAgent, предоставляет масштабируемое решение для рецензирования, основанного на выполнении кода. Традиционные методы оценки часто ограничены количеством рецензентов и сложностью проверки воспроизводимости результатов. Автоматизированные инструменты позволяют проводить более широкий анализ, охватывая большее количество исследований и проверяя корректность реализации на основе фактического выполнения кода. Это особенно важно для проектов, связанных с машинным обучением и программированием, где даже небольшие ошибки в реализации могут привести к значительным отклонениям в результатах. Масштабируемость, обеспечиваемая такими инструментами, позволяет эффективно оценивать большое количество работ, что невозможно при ручном рецензировании.
Механизм MechEvalAgent использует агентов на основе больших языковых моделей (LLM) для проведения комплексной оценки исследований. Он сочетает в себе анализ текстового описания работы (narrative checks) с автоматическим выполнением и верификацией представленного кода. Такой подход позволяет оценивать исследования по нескольким параметрам, включая корректность реализации, соответствие заявленным целям и достоверность полученных результатов. Автоматизированное выполнение кода позволяет выявлять ошибки и неточности, которые могут быть пропущены при ручной проверке, обеспечивая более объективную и всестороннюю оценку.
В отличие от традиционных методов оценки, MechEvalAgent проводит анализ не только воспроизводимости исследований, но и их внутренней согласованности (Coherence) — соответствия между заявленными целями, реализацией и полученными результатами, а также обобщающей способности (Generalizability). Подтверждено, что оценки MechEvalAgent согласуются с экспертными оценками в более чем 80% случаев по всем категориям задач, что демонстрирует высокую надежность и объективность автоматизированной системы оценки.
В ходе тестирования, система MechEvalAgent выявила 51 дополнительную проблему в исследуемых проектах, которые не были замечены экспертами-людьми. Это свидетельствует о способности системы обнаруживать тонкие дефекты и несоответствия, которые могут ускользнуть от внимания при ручной проверке. Выявленные проблемы варьируются от незначительных ошибок в коде до логических нестыковок в представленных результатах, что подтверждает эффективность MechEvalAgent как инструмента для углубленного анализа и повышения надежности научных исследований.

За Пределами Верификации: Влияние на Качество Исследований
Внедрение оценок, основанных на непосредственном исполнении кода, особенно с использованием инструментов вроде MechEvalAgent, способствует формированию культуры ответственности и строгости в научных исследованиях. Такой подход позволяет перейти от простой верификации результатов к их активной проверке в процессе выполнения, выявляя скрытые ошибки и несоответствия. Инструменты автоматизированной оценки не только повышают надежность научных выводов, но и стимулируют исследователей к более тщательному проектированию экспериментов и более корректной интерпретации данных. В результате, формируется более прозрачная и воспроизводимая научная практика, что критически важно для продвижения вперед в сложных областях, требующих высокой степени достоверности результатов.
Внедрение автоматизированной проверки статистической значимости и воспроизводимости результатов исследований позволяет существенно снизить влияние ошибочных или неподтвержденных утверждений. Исследования показали, что инструмент MechEvalAgent способен выявлять проблемы со статистической значимостью в 80% случаев, используя метрику CS5. Это свидетельствует о высокой эффективности автоматизированного подхода к оценке надежности научных выводов и позволяет отсеивать работы, в которых обнаружены недостатки в методологии или анализе данных. Такая практика способствует повышению доверия к научным результатам и ускоряет прогресс в различных областях, где важна достоверность полученных знаний.
Переход к более надежной и достоверной основе исследований, обеспечиваемый инструментами вроде MechEvalAgent, открывает новые перспективы в таких областях, как механическая интерпретируемость. Высокий уровень согласованности — 89.4% — между оценками, полученными с помощью MechEvalAgent на основе мажоритарного голосования, и экспертными человеческими оценками, подтверждает высокую валидность данного подхода. Это позволяет не только повысить качество проводимых исследований, но и ускорить темпы прогресса, поскольку результаты, прошедшие строгую верификацию, обладают большей степенью доверия и могут служить более прочной базой для дальнейших разработок и открытий.

Работа над MechEvalAgent, судя по всему, подтверждает старую истину: история — это лишь набор оправданий для неудачных деплоев. Авторы пытаются приручить хаос, автоматизируя проверку «механической интерпретируемости», и это, конечно, благородное начинание. Но, как говорил Винтон Серф: «Интернет — это просто большая машина для доставки спама». Аналогично, и все эти сложные модели, которые мы пытаемся понять, рано или поздно найдут способ сломаться самым непредсказуемым образом. Автоматизированная оценка, предложенная в статье, может выявить ошибки, но она не гарантирует, что код не упадет в самый неподходящий момент. В конце концов, тесты — это лишь форма надежды, а не уверенности, и прод всегда найдёт способ превзойти самые смелые ожидания.
Что дальше?
Представленный фреймворк, как и любая попытка автоматизировать оценку, неизбежно столкнётся с проблемой «непредсказуемой поломки». Всё, что обещает самовосстановление, попросту ещё не сломалось достаточно раз, чтобы продемонстрировать истинные масштабы необходимой поддержки. Автоматизированная проверка кода, безусловно, выявит ошибки в реализации, но она не сможет обнаружить элегантную, но ошибочную логику, которая выглядит убедительно на бумаге. Документация, как известно, — это форма коллективного самообмана, а значит, полагаться на неё в оценке механической интерпретируемости — всё равно, что строить замок на песке.
Будущие исследования, вероятно, будут сосредоточены на расширении набора «агентов», способных выполнять оценку, но ключевой вопрос остаётся: как определить, что агент сам не подвержен предвзятости или ошибкам? Если баг воспроизводится, это не признак стабильной системы, а скорее указание на то, что мы нашли достаточно сложный случай, чтобы он проявился. Реальная проверка придёт с увеличением сложности систем и, соответственно, с ростом числа краевых случаев, которые система должна обработать.
В конечном итоге, ценность подобных фреймворков заключается не в создании идеальной системы оценки, а в том, чтобы заставить исследователей задавать более сложные вопросы и признавать неизбежность ошибок. И, возможно, в том, чтобы просто отвлечь их от написания бесконечных обзоров литературы.
Оригинал статьи: https://arxiv.org/pdf/2602.18458.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-24 23:43