Автор: Денис Аветисян
Новый метод позволяет создавать практически неограниченный объем обучающих данных для систем искусственного интеллекта, используя информацию из интернета.
![Для создания задач RLVR используется конвейер, преобразующий неструктурированный текст в вопросы с множественным выбором, где ключевой фрагмент рассуждений заменяется [MASK], а затем генерируются правдоподобные, но неверные варианты ответов; для шумных источников данных предварительно извлекается образовательно ценный отрывок, после чего формируется вопрос, а для повышения сложности применяются фильтры, отсеивающие тривиальные примеры.](https://arxiv.org/html/2601.22975v1/figures/G.png)
Представлен GooseReason — подход к синтезу данных для обучения с контролируемыми наградами (RLVR), позволяющий преодолеть насыщение данных и улучшить производительность больших языковых моделей.
Несмотря на успехи обучения с подкреплением с проверяемыми наградами (RLVR) в раскрытии сложного рассуждения в больших языковых моделях, масштабирование этого подхода ограничивается недостатком размеченных данных. В статье ‘Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text’ предложен метод Golden Goose, позволяющий генерировать неограниченное количество задач RLVR из неверифицированных интернет-текстов путем преобразования задач заполнения пропусков в вопросы с множественным выбором. Разработанный датасет GooseReason-0.7M, содержащий более 0.7 миллиона задач из областей математики, программирования и науки, эффективно восстанавливает производительность моделей, достигших насыщения на существующих данных RLVR, и устанавливает новые state-of-the-art результаты. Не откроет ли эта методика путь к автоматическому масштабированию данных RLVR, используя богатые, но ранее недоступные ресурсы интернет-текстов?
Развитие Рассуждений: Обещание Обучения с Подкреплением
Традиционные языковые модели, несмотря на впечатляющие успехи в обработке естественного языка, часто сталкиваются с трудностями при решении задач, требующих сложного, итеративного рассуждения. В отличие от способности эффективно распознавать паттерны в больших объемах данных, эти модели испытывают затруднения в ситуациях, где необходимо последовательно применять логические шаги, проверять гипотезы и адаптироваться к меняющимся условиям. Например, при решении математических задач, требующих нескольких этапов вычислений, или в процессе отладки сложного программного кода, стандартные модели склонны к ошибкам и неспособны к самокоррекции. Это связано с тем, что они обучаются на статичных наборах данных, где правильные ответы предоставляются сразу, в то время как реальные задачи рассуждения часто требуют активного поиска решений и оценки промежуточных результатов.
Метод обучения с подкреплением и проверяемыми наградами (RLVR) представляет собой перспективный подход к развитию способностей моделей к сложному рассуждению, выходящий за рамки простого распознавания закономерностей. В отличие от традиционных методов, полагающихся на статические наборы данных, RLVR позволяет моделям обучаться процессу рассуждения посредством взаимодействия со средой и получения обратной связи. Модель не просто запоминает ответы, а формирует стратегию решения задач, оценивая каждый шаг на основе чётко определённых и проверяемых наград. Это позволяет ей адаптироваться к новым ситуациям и находить оптимальные решения даже в условиях неполной информации, что значительно повышает её способность к решению сложных проблем и логическому мышлению. Такой подход открывает возможности для создания искусственного интеллекта, способного не только обрабатывать данные, но и самостоятельно находить решения, приближаясь к уровню человеческого интеллекта.
В отличие от традиционных моделей, обучающихся на зафиксированных наборах данных, методика обучения с подкреплением и проверяемыми наградами (RLVR) открывает принципиально новую возможность — позволить моделям учиться рассуждать посредством взаимодействия со средой и получения обратной связи. Этот подход имитирует процесс человеческого обучения, где знания приобретаются не пассивным запоминанием, а активным экспериментированием и анализом результатов. Вместо того чтобы просто распознавать закономерности в существующих данных, модель RLVR самостоятельно формирует стратегии решения задач, получая награды за правильные шаги и корректируя поведение при ошибках. Такой итеративный процесс позволяет модели не просто находить ответы, но и понимать как она пришла к этим ответам, что является ключевым шагом на пути к настоящему искусственному интеллекту, способному к сложным рассуждениям и адаптации к новым ситуациям.
GooseReason: Основа для Надежных Рассуждений
Набор данных GooseReason-0.7M представляет собой масштабный ресурс, состоящий из более чем 700 тысяч задач, разработанных для оценки и улучшения способностей к логическому мышлению. Этот набор данных предназначен для тренировки и тестирования моделей искусственного интеллекта, требующих решения комплексных задач, выходящих за рамки простого распознавания образов или статистического анализа. Масштабность GooseReason-0.7M позволяет проводить более эффективное обучение моделей, повышая их устойчивость и обобщающую способность при решении новых, ранее не встречавшихся задач, требующих логических выводов и анализа информации.
Набор данных GooseReason-Cyber представляет собой специализированную подвыборку из GooseReason-0.7M, ориентированную на задачи в области кибербезопасности. Он включает сценарии, требующие не просто логического вывода, но и адаптивного решения проблем в условиях, приближенных к реальным угрозам. В отличие от общих задач на рассуждение, GooseReason-Cyber акцентирует внимание на нюансах, характерных для анализа сетевой активности, выявления уязвимостей и реагирования на инциденты, что делает его ценным инструментом для обучения и оценки моделей, предназначенных для автоматизации задач в сфере информационной безопасности.
Специально разработанный набор данных GooseReason-Cyber позволяет создавать модели, эффективно решающие задачи в области кибербезопасности. Тестирование этих моделей на стандартных бенчмарках кибербезопасности показало абсолютное увеличение производительности на 4.44% по сравнению с существующими решениями. Данный прирост указывает на то, что модели, обученные на GooseReason-Cyber, демонстрируют улучшенную способность к адаптации и решению сложных, специализированных задач в сфере информационной безопасности.
ProRL: Масштабирование Рассуждений с Эффективным Обучением
ProRL использует модифицированный алгоритм GRPO (Generalized Replay Policy Optimization) для обеспечения масштабируемости обучения с подкреплением. В отличие от стандартного GRPO, модификация ProRL направлена на снижение вычислительных затрат, связанных с обработкой больших объемов данных и сложных моделей. Это достигается за счет оптимизации процесса сбора и использования данных опыта, а также за счет более эффективной реализации алгоритма оптимизации политики. Ключевым нововведением является снижение требований к памяти и вычислительной мощности, что позволяет обучать модели с миллиардами параметров на доступном оборудовании и значительно увеличивать скорость обучения по сравнению с традиционными подходами к обучению с подкреплением.
Модель ProRL-1.5B-v2, представляющая собой языковую модель с 1.5 миллиардами параметров, обученная с использованием алгоритма ProRL, демонстрирует практическую реализуемость данного подхода к масштабированию обучения с подкреплением. Успешное обучение модели такого размера подтверждает возможность применения ProRL для создания крупных языковых моделей, способных к решению сложных задач. Данная модель служит основой для дальнейших исследований и оптимизации алгоритма ProRL, а также для оценки его эффективности на различных типах данных и задачах.
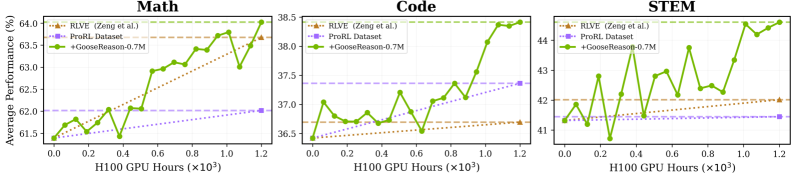
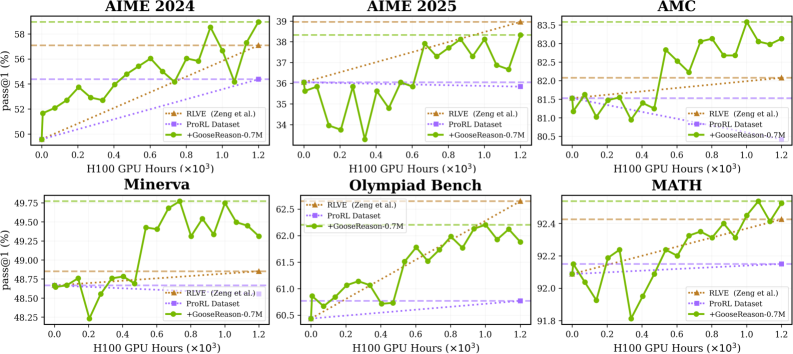
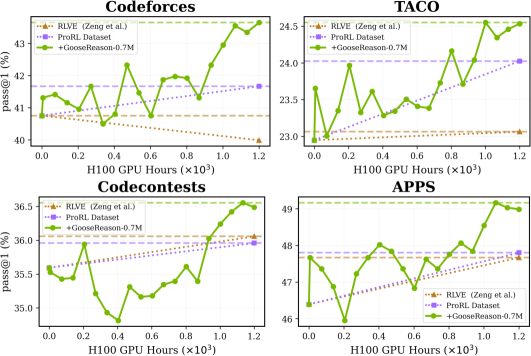
Эксперименты показали, что модели, обученные с использованием ProRL, демонстрируют эффект насыщения данных, когда дальнейшее увеличение объема обучающего набора приводит к уменьшению прироста производительности. Это подчеркивает критическую важность масштаба и разнообразия датасета для эффективного обучения. Дополнительное расширение обучающей выборки более чем на 450,000 синтезированных примеров позволило значительно улучшить результаты, что подтверждает перспективность использования синтетических данных для преодоления ограничений, связанных с доступностью и разнообразием реальных данных.
Широкое Влияние: Улучшение Рассуждений в Различных Моделях
Исследования показали, что методика RLVR (Reasoning with Language Verification and Refinement) существенно повышает способность к логическому мышлению у передовых языковых моделей. В ходе экспериментов, модели DeepSeek-R1, OpenAI-o3 и Gemini-3 продемонстрировали заметное улучшение в решении задач, требующих последовательного анализа и вывода. Это свидетельствует о том, что RLVR не просто оптимизирует существующие возможности моделей, но и развивает их способность к более сложным формам рассуждений, открывая перспективы для применения в различных областях, где требуется интеллектуальный анализ данных и принятие обоснованных решений.
Исследования демонстрируют, что улучшение способности к рассуждениям, достигнутое благодаря новым методам обучения, не ограничивается конкретными задачами. Повышение производительности было подтверждено на широком спектре бенчмарков, включая MATH, предназначенный для оценки математических способностей, IFEval, тестирующий логическое мышление, и AIME, сложный экзамен по математике для школьников. Успешное применение подхода на столь разнообразных наборах данных указывает на его общую применимость и способность улучшать навыки рассуждений моделей в различных областях знаний, что делает его ценным инструментом для развития искусственного интеллекта.
Модель Qwen-4B-Instruct, прошедшая обучение с использованием GooseReason, демонстрирует значительное повышение эффективности даже в условиях ограниченных вычислительных ресурсов. Данный подход не только обеспечивает абсолютное улучшение общей производительности на 2.27%, но и успешно компенсирует ухудшение результатов на 0.79%, зафиксированное в ходе предыдущего обучения. Особенно заметно превосходство Qwen-4B-Instruct над моделью Llama-Primus-Instruct: она опережает её на 3.00% в задачах, связанных с кибербезопасностью, и демонстрирует впечатляющий прирост в 3.48% в областях, относящихся к науке, технологиям, инженерии и математике (STEM). Это свидетельствует о том, что GooseReason эффективно оптимизирует даже компактные модели, повышая их способность к решению сложных задач.
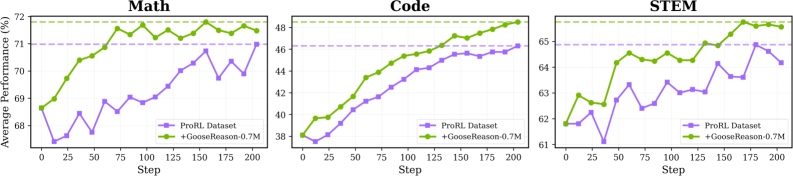
Исследование демонстрирует, что даже при кажущейся насыщенности данных, возможности для улучшения моделей машинного обучения остаются. Авторы предлагают подход GooseReason, позволяющий синтезировать обучающие данные из неструктурированного интернет-текста, тем самым обходя проблему нехватки верифицируемых данных для обучения с подкреплением. Этот процесс, по сути, продлевает жизненный цикл системы, позволяя ей эволюционировать даже в условиях стагнации. Как метко заметил Брайан Керниган: «Простота — это высшая степень совершенства». Применение GooseReason, стремясь к лаконичности и эффективности синтеза данных, подтверждает эту мысль, предлагая элегантное решение для поддержания устойчивости и развития моделей.
Что дальше?
Представленная работа, словно гусь, несущий золотые яйца, демонстрирует возможность извлекать ценность из, казалось бы, неисчерпаемого, но при этом ненадежного источника — неструктурированного текста из интернета. Однако, следует помнить: любое яйцо рано или поздно разбивается. Вопрос не в том, как бесконечно наращивать объемы синтетических данных, а в том, как обеспечить их качество и устойчивость к неизбежному энтропийному распаду. Подобно тому, как система стареет, данные неизбежно устаревают, и необходимо искать механизмы самокоррекции и адаптации.
Очевидным направлением дальнейших исследований представляется разработка методов верификации не только вознаграждений, но и самих задач, синтезируемых GooseReason. Простое увеличение масштаба недостаточно; требуется глубинное понимание того, какие типы задач действительно способствуют развитию обобщающей способности больших языковых моделей, а какие лишь создают иллюзию прогресса. Важно помнить, что время — не метрика, а среда, в которой ошибки и исправления становятся неотъемлемой частью эволюции системы.
Инциденты, возникающие в процессе обучения, следует рассматривать не как сбои, а как шаги системы по пути к зрелости. В конечном итоге, задача состоит не в том, чтобы создать идеальный набор данных, а в том, чтобы создать систему, способную учиться на своих ошибках и адаптироваться к изменяющимся условиям. И тогда, возможно, этот золотой гусь продолжит нести яйца, даже когда все остальные источники иссякнут.
Оригинал статьи: https://arxiv.org/pdf/2601.22975.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Кванты в Финансах: Не Шутка!
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Квантовый оптимизатор: Новый подход к сложным задачам
- Молекулярный конструктор: Искусственный интеллект на службе создания лекарств
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Генерирующие модели: новый подход с использованием тензорных сетей
- Когда точность не равна пониманию: ограничения обучения с подкреплением в математических задачах
2026-02-03 00:41