Автор: Денис Аветисян
Новый подход к разработке аппаратного обеспечения для периферийных вычислений позволяет эффективно обучать нейронные сети, используя ограниченные наборы данных.
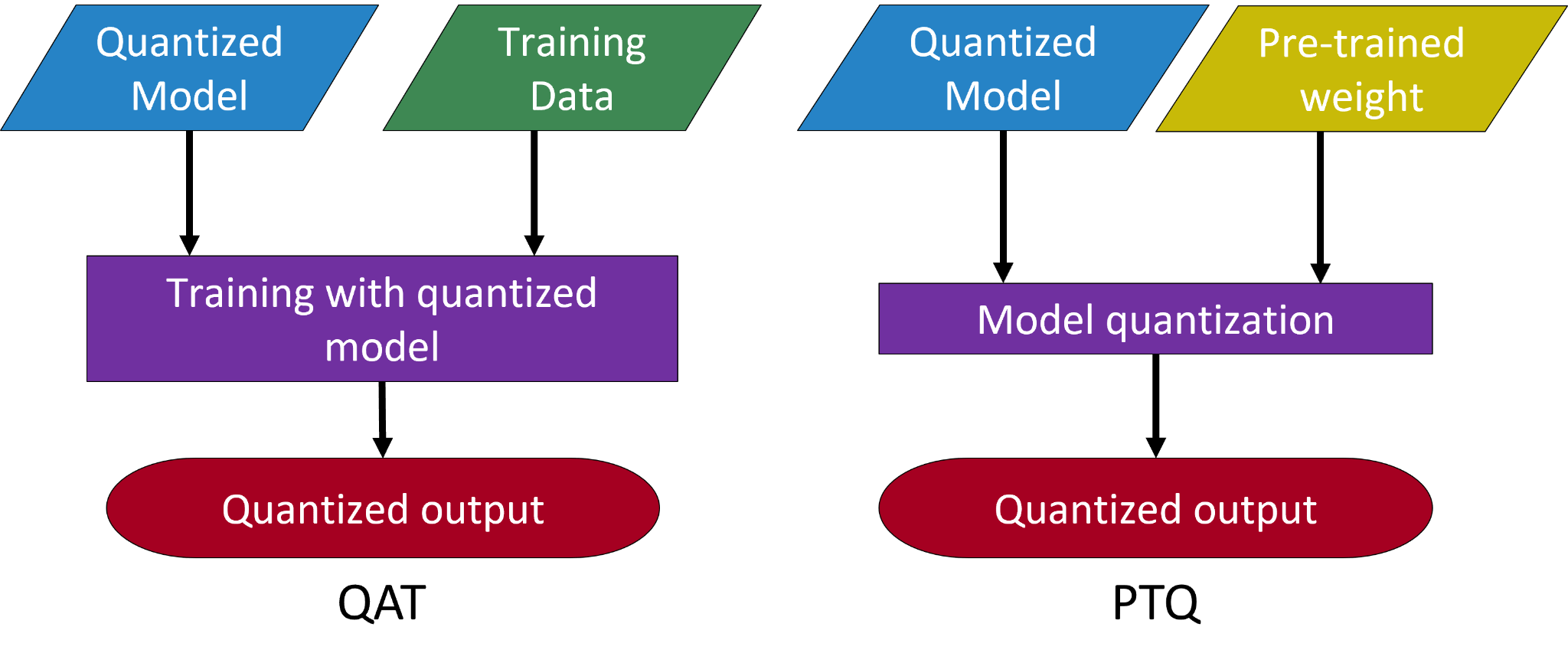
Исследование демонстрирует успешную реализацию фиксированной квантизации (QAT и PTQ) во всей цепочке системы обучения с малым количеством примеров, от предварительного обучения до аппаратной реализации на FPGA и Tensil.
Ограничения вычислительных ресурсов периферийных устройств часто препятствуют развертыванию моделей машинного обучения, требующих высокой точности. В данной работе, посвященной разработке ‘Design Environment of Quantization-Aware Edge AI Hardware for Few-Shot Learning’, предлагается комплексный подход к реализации аппаратного обеспечения для обучения с небольшим количеством примеров, основанный на фиксированной точке представления данных. Показано, что применение методов обучения с учетом квантования (QAT) и пост-обучающей квантования (PTQ) позволяет достичь сопоставимой с плавающей точкой точности даже при использовании 5-6-битных целых чисел, значительно снижая потребление ресурсов. Каковы перспективы дальнейшей оптимизации подобных систем для еще более эффективного развертывания интеллектуальных приложений на периферийных устройствах?
Ограниченность Данных: Введение в Обучение с Небольшим Количеством Примеров
Традиционные модели машинного обучения, как правило, нуждаются в огромных объемах размеченных данных для достижения высокой точности. Однако, получение и разметка таких данных часто сопряжены со значительными трудностями и затратами. Процесс может быть трудоемким, особенно в специализированных областях, где экспертные знания необходимы для корректной классификации и анализа информации. Кроме того, в некоторых случаях, данные могут быть просто недоступны из-за соображений конфиденциальности или их ограниченного количества. Эта зависимость от больших размеченных наборов данных существенно ограничивает применимость машинного обучения в реальных сценариях, где ресурсы ограничены или данные динамически меняются.
Обучение с малым количеством примеров представляет собой принципиально новый подход в машинном обучении, имитирующий способность человека к быстрому освоению новых концепций на основе ограниченного опыта. В отличие от традиционных моделей, требующих огромных объемов размеченных данных, данная парадигма позволяет алгоритмам эффективно обобщать информацию, используя лишь несколько примеров для каждой категории. Это достигается за счет использования мета-обучения, трансферного обучения и метрического обучения, позволяющих моделям извлекать полезные знания из предыдущих задач и применять их к новым, даже при дефиците данных. Такой подход открывает широкие возможности для применения искусственного интеллекта в областях, где сбор и разметка больших объемов данных затруднены или невозможны, например, в медицине, робототехнике и обработке редких языков.
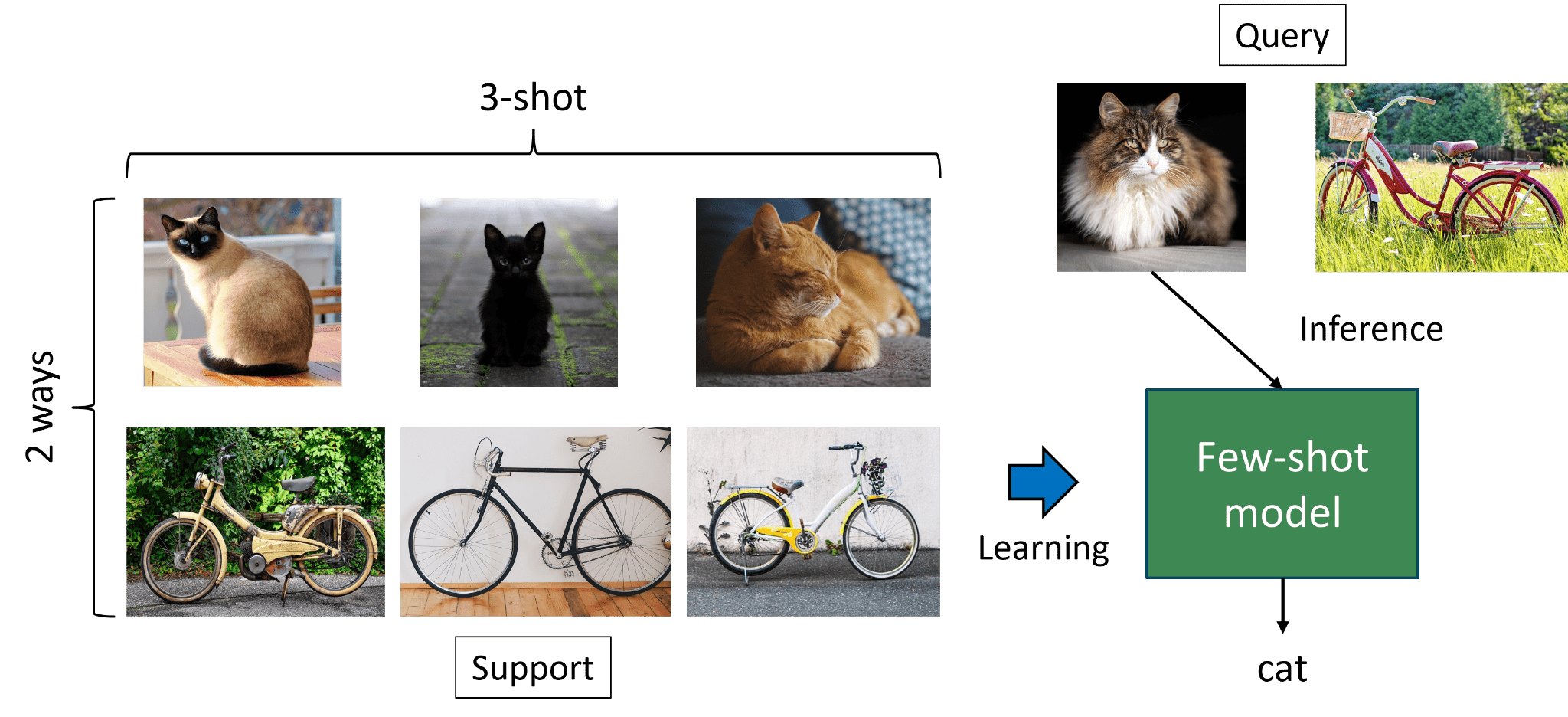
PEFSL: Конвейер для Встраиваемого Обучения с Небольшим Количеством Примеров
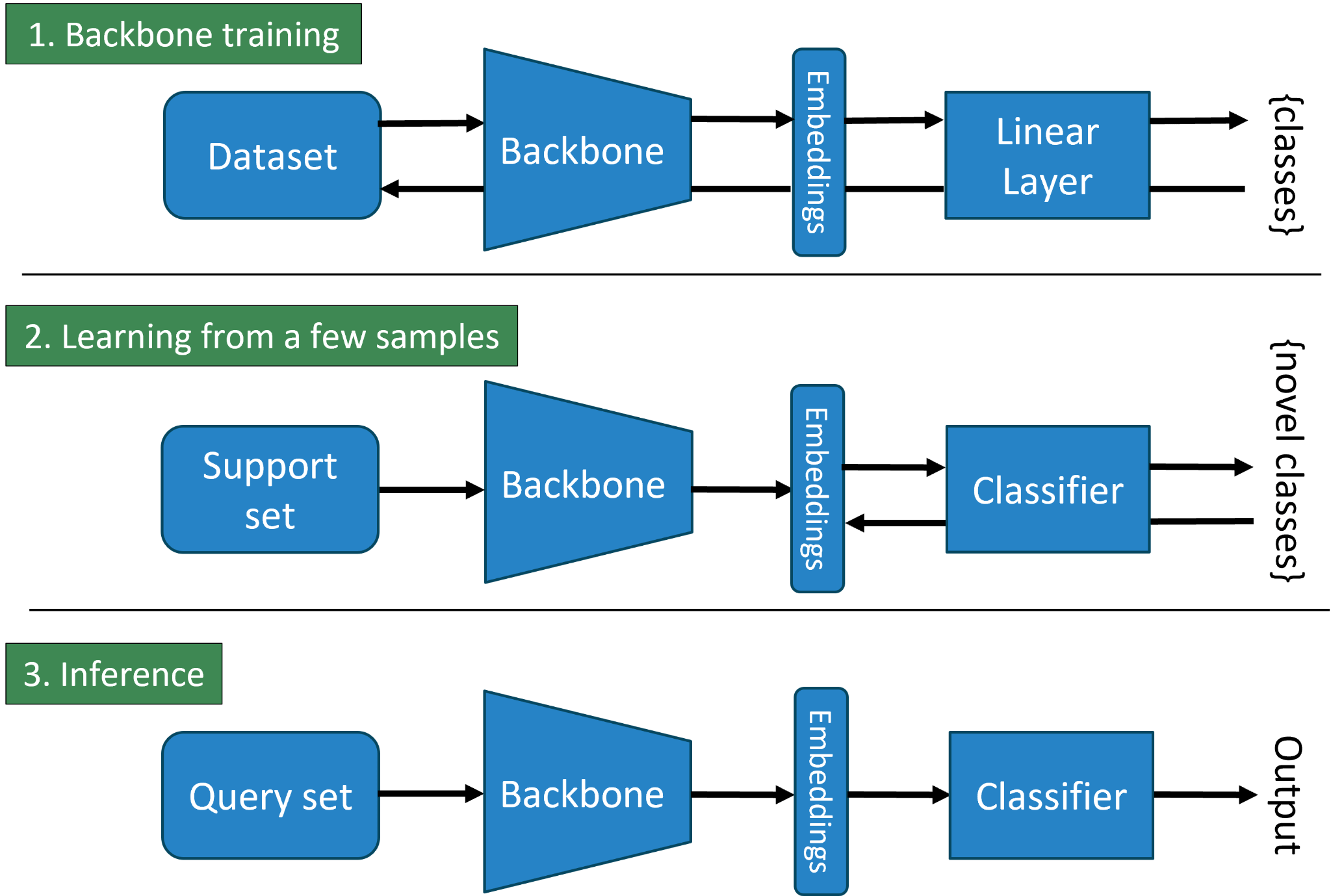
PEFSL представляет собой комплексный конвейер, предназначенный для развертывания моделей обучения с небольшим количеством примеров (few-shot learning) на устройствах с ограниченными ресурсами, таких как встраиваемые системы и периферийные устройства. Конвейер охватывает все этапы — от подготовки данных и обучения модели до оптимизации и развертывания на целевом оборудовании. Он включает инструменты для квантования моделей, компиляции для специализированных аппаратных платформ и профилирования производительности, обеспечивая возможность эффективного внедрения алгоритмов машинного обучения в условиях ограниченной вычислительной мощности и энергопотребления. Целью PEFSL является упрощение процесса развертывания и обеспечение высокой производительности моделей few-shot learning на периферийных устройствах.
Фреймворк PEFSL использует аппаратное ускорение на базе FPGA и платформы Tensil для достижения максимальной производительности и минимизации энергопотребления. Tensil позволяет эффективно отображать вычисления нейронных сетей на FPGA, используя специализированные аппаратные блоки для операций матричного умножения и свертки. Такой подход позволяет значительно снизить задержку и энергопотребление по сравнению с традиционными CPU или GPU реализациями, что критически важно для развертывания моделей машинного обучения на периферийных устройствах с ограниченными ресурсами. Использование FPGA обеспечивает гибкость и возможность оптимизации архитектуры для конкретной модели и целевого устройства.
Начальные этапы обработки в PEFSL используют операции с плавающей точкой (floating-point operations) для обеспечения максимальной гибкости и возможности быстрой разработки и прототипирования моделей. Далее, для эффективной аппаратной реализации на FPGA и оптимизации энергопотребления, происходит переход к операциям с фиксированной точкой (fixed-point operations). Этот переход позволяет значительно снизить вычислительную сложность и требования к памяти, необходимые для выполнения операций на ограниченных ресурсах встраиваемых систем, сохраняя при этом приемлемый уровень точности модели.
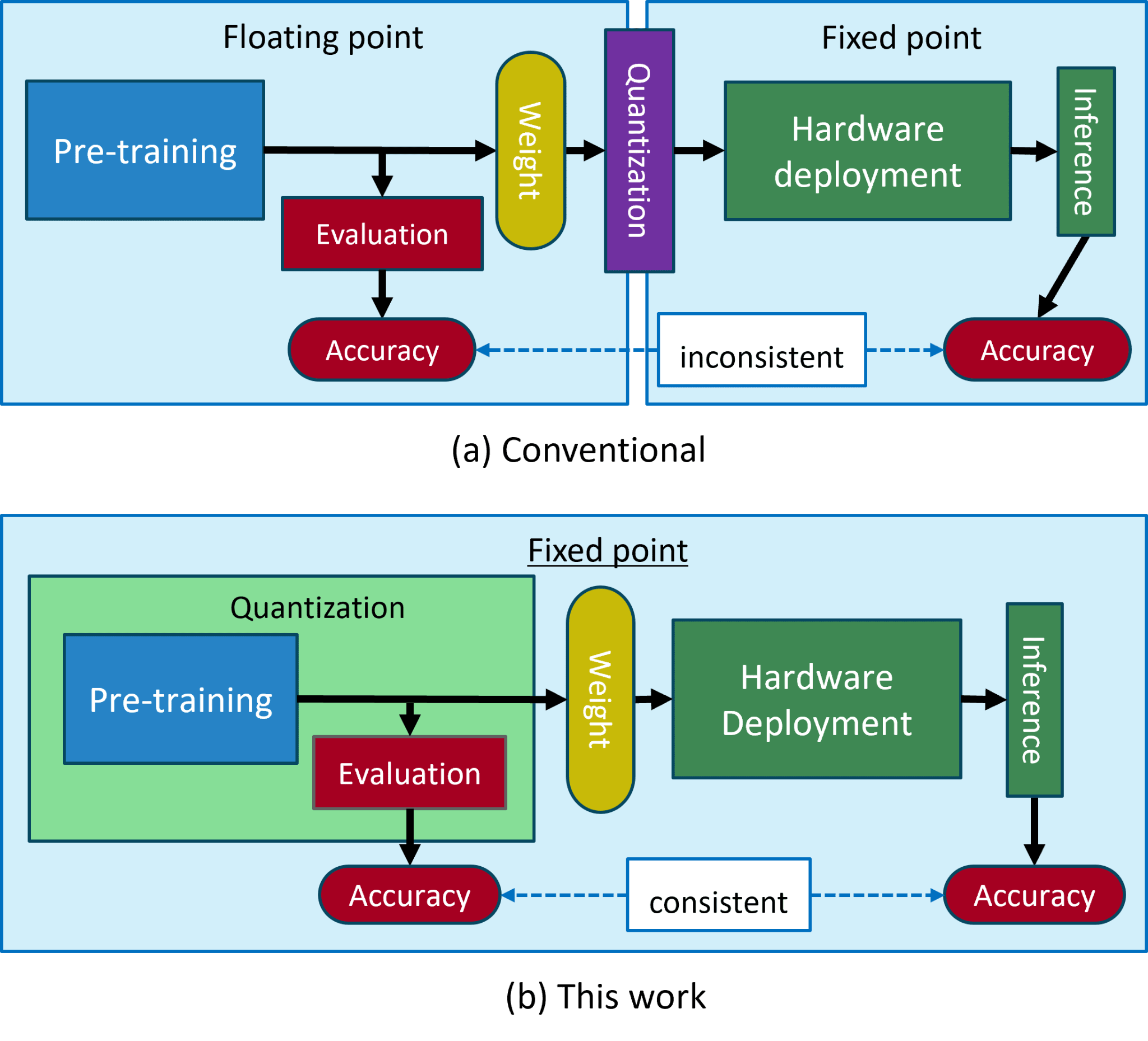
Квантование для Эффективности: Баланс Между Точностью и Производительностью
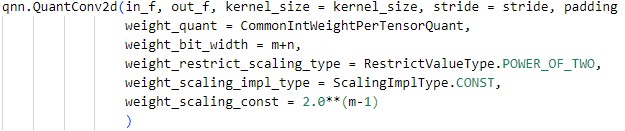
Квантизация, включающая методы вроде обучения с учетом квантизации (Quantization-Aware Training) и пост-обучающая квантизация (Post-Training Quantization), позволяет снизить размер модели и вычислительную сложность за счет представления весов и активаций с использованием меньшей разрядности. Вместо стандартных 32-битных чисел с плавающей точкой (float32), квантизация использует целочисленные представления, такие как int8 или даже меньшие разрядности. Это приводит к уменьшению объема памяти, необходимого для хранения модели, а также к ускорению вычислений, поскольку операции с целочисленными значениями обычно выполняются быстрее, чем операции с числами с плавающей точкой. Снижение точности представления данных является компромиссом, который необходимо учитывать при выборе метода квантизации и разрядности, поскольку это может повлиять на общую точность модели.
Фреймворк Brevitas предоставляет инструменты для упрощенной реализации методов квантизации, включая как Quantization-Aware Training (QAT), так и Post-Training Quantization (PTQ). Он позволяет разработчикам оптимизировать модели машинного обучения для снижения вычислительных затрат и размера, одновременно стремясь к сохранению высокой точности. Brevitas автоматизирует многие аспекты процесса квантизации, такие как калибровка и настройка параметров, что позволяет ускорить развертывание моделей на целевых аппаратных платформах и эффективно использовать ресурсы, особенно в средах с ограниченными вычислительными возможностями.
Результаты исследований показывают, что обучение с учётом квантизации (Quantization-Aware Training, QAT) позволяет поддерживать точность, сопоставимую с использованием чисел с плавающей точкой, даже при представлении весов и активаций 5-битными целыми и дробными числами. В то же время, постобработочная квантизация (Post-Training Quantization, PTQ) с 3-битной точностью приводит к снижению точности почти на 40%. Данные различия обусловлены тем, что QAT адаптирует модель к пониженной точности в процессе обучения, в то время как PTQ применяет квантизацию к уже обученной модели, что может приводить к значительным потерям информации.
Проверка и Производительность на Стандартных Датасетах
Для оценки эффективности разработанного конвейера PEFSL использовались стандартные бенчмарк-датасеты miniImageNet и CIFAR-FS, широко применяемые в задачах обучения с небольшим количеством примеров (few-shot learning). miniImageNet представляет собой набор изображений, состоящий из 100 классов с 600 изображениями в каждом классе, в то время как CIFAR-FS — это подмножество датасета CIFAR-100, содержащее 100 классов с 600 изображениями. Использование этих общепринятых наборов данных позволяет проводить объективное сравнение PEFSL с другими современными моделями в области обучения с небольшим количеством примеров и подтвердить его эффективность.
В рамках PEFSL используется подход, основанный на обучении базовой модели — сети ResNet12 — для извлечения признаков из входных данных. Обученная базовая модель служит для формирования векторных представлений изображений. Для классификации полученных признаков применяется алгоритм ближайшего среднего класса (Nearest Class Mean), который вычисляет средний вектор признаков для каждого класса и относит входное изображение к классу с наиболее близким средним вектором. Данный подход позволяет эффективно использовать извлеченные признаки для классификации в задачах обучения с небольшим количеством примеров.
При использовании квантизации с обучением после квантизации (QAT) и 5-битной квантизацией, PEFSL демонстрирует точность около 55% на датасете miniImageNet при 1-shot обучении и 75% на CIFAR-FS при аналогичных условиях. При 5-shot обучении точность возрастает до приблизительно 65% на miniImageNet и 85% на CIFAR-FS. Важно отметить, что полученные результаты сопоставимы с точностью, достигаемой при использовании вычислений с плавающей точкой, что подтверждает эффективность предложенного подхода к квантизации для сохранения производительности модели.
К Универсальному Встраиваемому Интеллекту
Система PEFSL открывает новые горизонты для интеллектуальных устройств, работающих непосредственно на месте — от робототехники и систем здравоохранения до автономных транспортных средств. Благодаря возможности обучения на небольшом количестве примеров, PEFSL позволяет этим устройствам адаптироваться к новым задачам и условиям без необходимости обширных наборов данных или постоянного подключения к облачным серверам. Это особенно важно в ситуациях, где доступ к сети ограничен или требуется немедленная реакция, например, при диагностике заболеваний в удаленных районах или управлении роботом в условиях меняющейся обстановки. Подобный подход не только расширяет функциональность периферийных устройств, но и способствует повышению их надежности и безопасности, поскольку обработка данных происходит локально, минимизируя риски, связанные с передачей конфиденциальной информации.
Эффективность разработанной системы позволяет значительно снизить потребность в огромных объемах данных для обучения и мощной облачной инфраструктуре. Это достигается за счет оптимизации алгоритмов и использования более компактных моделей, что приводит к снижению вычислительных затрат и энергопотребления. Уменьшение зависимости от централизованных облачных серверов не только снижает финансовую нагрузку, но и повышает уровень конфиденциальности данных, поскольку обработка информации происходит непосредственно на устройстве, минимизируя риски, связанные с передачей и хранением данных третьими сторонами. Такой подход открывает новые возможности для развертывания интеллектуальных систем в условиях ограниченных ресурсов и строгих требований к защите персональной информации.
Перспективные исследования направлены на углубленное изучение методов квантования, позволяющих существенно снизить вычислительную нагрузку и энергопотребление при работе алгоритмов искусственного интеллекта непосредственно на периферийных устройствах. Параллельно ведется разработка и оптимизация специализированных аппаратных архитектур, адаптированных для эффективной реализации этих квантованных моделей. Успешное внедрение этих технологий позволит значительно расширить возможности граничных вычислений, открывая путь к созданию более автономных, энергоэффективных и конфиденциальных систем искусственного интеллекта, способных функционировать в самых разнообразных условиях и областях применения — от робототехники и здравоохранения до беспилотного транспорта и умных городов.
Представленная работа демонстрирует стремление к математической чистоте в реализации систем машинного обучения. Авторы последовательно применяют методы фиксированной точечной квантизации — QAT и PTQ — на всех этапах конвейера обучения с небольшим количеством примеров. Такой подход, направленный на обеспечение согласованности точности от предварительного обучения до аппаратной реализации на периферийных устройствах, соответствует принципам формальной верификации. Как однажды заметил Давид Гильберт: «В каждой математической науке есть две мотивации: решение конкретных проблем и поиск общих принципов». В данном случае, стремление к общей точности и доказуемости алгоритмов является ключевым аспектом исследования, а не просто достижение работоспособности на тестовых данных.
Куда Дальше?
Представленная работа демонстрирует возможность сквозного применения фиксированной квантизации в системах обучения с малым количеством примеров. Однако, кажущаяся элегантность этой реализации не должна заслонять фундаментальную проблему: любая дискретизация неизбежно вносит ошибку. Достигнутая консистентность точности от предварительного обучения до аппаратной реализации на FPGA — это не абсолютная истина, а лишь временное затишье перед лицом неизбежной погрешности. Будущие исследования должны быть направлены не на маскировку этой погрешности, а на её формальное описание и, возможно, даже использование в качестве дополнительного источника энтропии.
Особое внимание следует уделить исследованию границ применимости представленных техник. Насколько устойчива эта архитектура к изменениям в данных или задачах? Какова цена, которую приходится платить за снижение вычислительной сложности? Пределы точности, достижимые при экстремальной квантизации, требуют строгого математического обоснования. Любое эмпирическое «работает» без доказательства — это лишь иллюзия контроля.
Перспективы кажутся очевидными: переход от простого снижения разрядности к разработке адаптивных схем квантизации, способных динамически подстраиваться под структуру данных и специфику задачи. Поиск алгоритмов, которые не просто «работают на тестах», а гарантированно обеспечивают заданный уровень точности при любой конфигурации, — вот истинный вызов для исследователей в области Edge AI.
Оригинал статьи: https://arxiv.org/pdf/2602.12295.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Физика под контролем: Как «научить» модели понимать мир
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
- Самообучающиеся агенты: извлечение навыков из открытого кода
2026-02-17 01:38