Автор: Денис Аветисян
Исследователи предложили инновационный метод интерполяции, основанный на использовании нейронных сетей и аппроксимации Тейлора для повышения точности на неструктурированных данных.
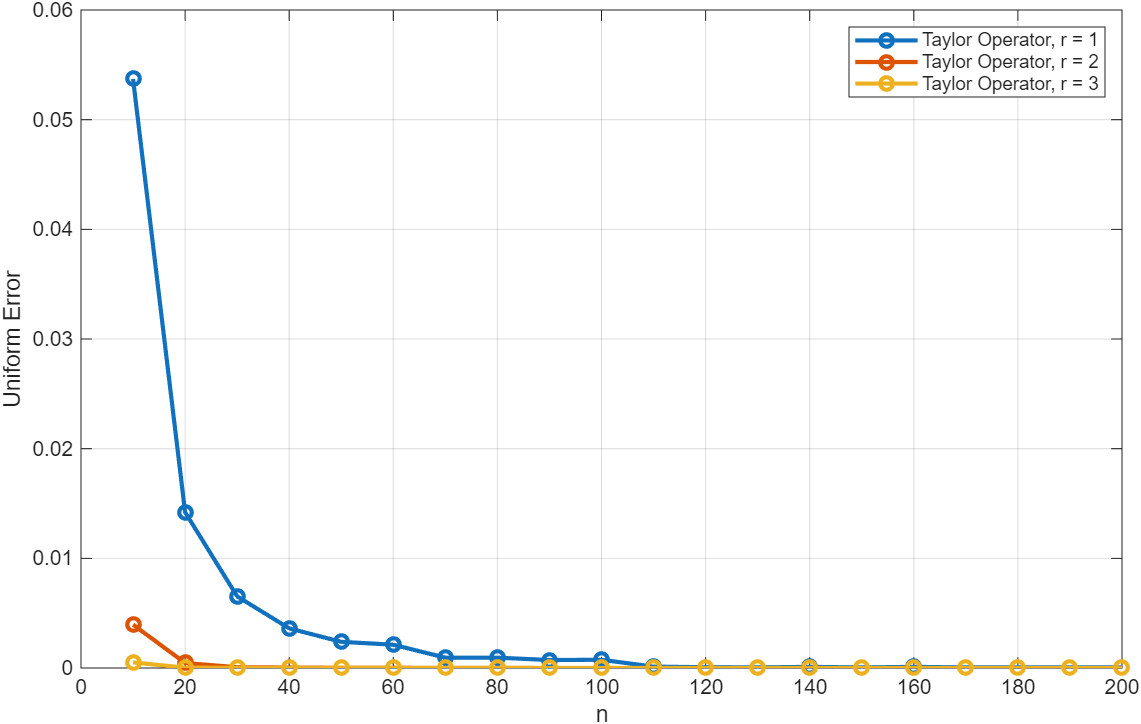
Представлены операторы интерполяции, ускоренные аппроксимацией Тейлора, обеспечивающие более высокую скорость сходимости на нерегулярных сетках.
Несмотря на широкое применение нейронных сетей в задачах интерполяции, достижение высокой точности на нерегулярных сетках остается сложной задачей. В работе ‘Taylor-Accelerated Neural Network Interpolation Operators on Irregular Grids with Higher Order Approximation’ предложен новый класс операторов интерполяции, использующих ускорение на основе рядов Тейлора для повышения порядка сходимости. Показано, что предложенные операторы обладают свойствами равномерной ограниченности, точного интерполирования и воспроизводят полиномы заданной степени, обеспечивая повышенную точность аппроксимации, измеряемую модулями гладкости. Возможно ли дальнейшее развитие данного подхода для адаптации к данным с различной степенью гладкости и сложной геометрией?
Преодолевая Ограничения: От Равномерных Сеток к Адаптивности
Традиционные численные методы, широко применяемые в моделировании различных явлений, часто опираются на дискретизацию пространства с помощью равномерных сеток. Однако, при работе со сложными, многомерными данными, этот подход сталкивается с серьезными ограничениями. Равномерные сетки, хотя и просты в реализации, неэффективно используют вычислительные ресурсы, поскольку требуют обработки большого количества точек, даже в областях, где данные меняются незначительно. В высокоразмерных пространствах, количество точек в равномерной сетке растет экспоненциально с увеличением размерности, что делает вычисления практически невозможными. Это особенно критично для задач, связанных с анализом изображений, моделированием турбулентности или решением уравнений в частных производных, где данные обладают сложной структурой и неравномерным распределением. Поэтому, для достижения высокой точности и эффективности при работе с такими данными, требуется переход к более адаптивным и гибким методам дискретизации.
Использование равномерных сеток в численных методах, несмотря на свою кажущуюся простоту, часто приводит к излишним вычислительным затратам и снижению точности, особенно при работе с неоднородно распределенными данными. В областях, где плотность данных существенно варьируется, равномерная сетка вынуждает проводить вычисления в областях, где они практически не нужны, тратя ценные ресурсы. Более того, недостаточное разрешение сетки в областях с высокой плотностью данных может приводить к потере важной информации и, как следствие, к неточным результатам. Таким образом, применение фиксированного шага дискретизации не всегда является оптимальным решением, и требует поиска альтернативных подходов, способных адаптироваться к специфике данных и обеспечить более эффективное и точное моделирование.
Ограничения, присущие традиционным методам численного моделирования, основанным на равномерных сетках, стимулируют поиск альтернативных стратегий дискретизации. Исследования направлены на разработку более гибких подходов, позволяющих эффективно обрабатывать данные сложной структуры и высокой размерности. Вместо жесткой структуры равномерной сетки, предлагаются адаптивные методы, которые концентрируют вычислительные ресурсы в областях с высокой изменчивостью данных, тем самым снижая общую вычислительную нагрузку и повышая точность результатов. Такие стратегии, как разреженные сетки, методы Монте-Карло и адаптивные алгоритмы, позволяют добиться значительного улучшения производительности и эффективности при решении сложных задач, особенно в областях, где данные распределены неравномерно и требуют детального анализа в определенных регионах пространства.
Ускорение Тейлора: Интерполяция Высшего Порядка
Представляется оператор интерполяции на основе нейронных сетей с ускорением Тейлора — новый подход к аппроксимации функций на нерегулярных сетках. В отличие от стандартных методов интерполяции, данный оператор использует локальные полиномы Тейлора для построения аппроксимации. Это позволяет достичь более высокой точности при работе с данными, расположенными неравномерно в пространстве. Основное отличие заключается в способности эффективно использовать информацию о производных функции в каждой точке, что обеспечивает более точное восстановление исходной функции по ограниченному набору данных.
Оператор, использующий ускорение Тейлора, достигает более высокой точности за счет применения локальных полиномов Тейлора. В отличие от интерполяции Лагранжа, которая обычно обеспечивает точность первого порядка, данный подход позволяет аппроксимировать функции с использованием производных, что позволяет получить полином более высокой степени. Это приводит к более точной реконструкции функции в точках, где она не определена, и уменьшает погрешность интерполяции по сравнению с методами, использующими только значения функции в известных точках. Использование локальных полиномов Тейлора эффективно снижает эффект Рунге, часто возникающий при использовании полиномиальной интерполяции высоких степеней на равномерных сетках.
Внедрение информации о производных в предлагаемый метод позволяет достичь скорости сходимости, равной O(n^{-(r+1)}), где ‘n’ — количество используемых выборок, а ‘r’ — степень используемого полинома Тейлора. Это существенно превосходит скорости сходимости, характерные для традиционных методов интерполяции, таких как интерполяция Лагранжа, которые обычно имеют более низкий порядок сходимости. Увеличенная скорость сходимости напрямую ведет к уменьшению необходимого количества выборок для достижения заданной точности аппроксимации, что делает метод более эффективным в задачах, где получение данных сопряжено с высокими затратами или ограничено по ресурсам.
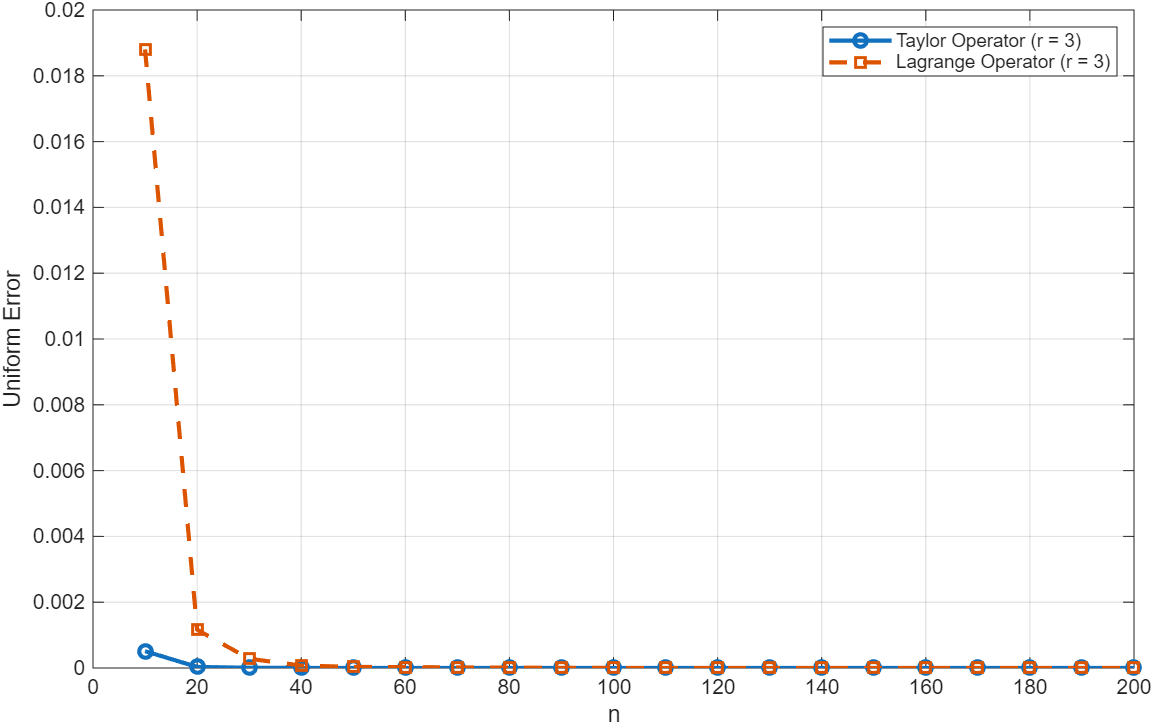
Гладкость и Сходимость: Оценка Эффективности
Точность работы оператора Тейлора-Ускорения напрямую зависит от модуля гладкости интерполируемой функции. Модуль гладкости, обозначаемый как \omega(f, \delta) , количественно оценивает, насколько быстро функция может быть аппроксимирована полиномами заданной степени. Более гладкие функции (с меньшим модулем гладкости) требуют меньше членов разложения Тейлора для достижения заданной точности, что приводит к более быстрой сходимости и снижению вычислительных затрат. В то время как для функций с низкой гладкостью (большим модулем гладкости) требуется больше членов разложения, что может привести к увеличению погрешности и снижению эффективности метода. Таким образом, оценка модуля гладкости является важным этапом при применении оператора Тейлора-Ускорения для обеспечения оптимальной точности и эффективности.
При использовании приближений более высокого порядка, скорость сходимости метода демонстрирует асимптотическое поведение, выражаемое как O(n-(r+1)), где n — количество используемых выборок, а r — степень гладкости функции. Данный показатель свидетельствует о значительно более быстрой сходимости к истинному значению по сравнению со стандартными методами интерполяции, которые обычно имеют линейную или квази-линейную зависимость ошибки от количества выборок. Увеличение порядка приближения позволяет добиться более высокой точности при меньшем количестве выборок, что особенно важно для ресурсоемких вычислений и обработки больших объемов данных. Таким образом, достигается более эффективное уменьшение ошибки и повышение общей производительности метода.
Преимущества использования метода, основанного на ускорении Тейлора, наиболее ярко проявляются при работе с функциями, обладающими высокой степенью гладкости. Как демонстрируют данные, представленные на Рисунках 2-4, высокая гладкость функции позволяет достичь точных приближений, используя существенно меньшее количество выборок. Это связано с тем, что для гладких функций требуется меньше членов разложения Тейлора для достижения заданной точности, что снижает вычислительные затраты и ускоряет процесс интерполяции. В результате, для функций с высокой степенью гладкости достигается значительное снижение ошибки при меньшем объеме исходных данных.
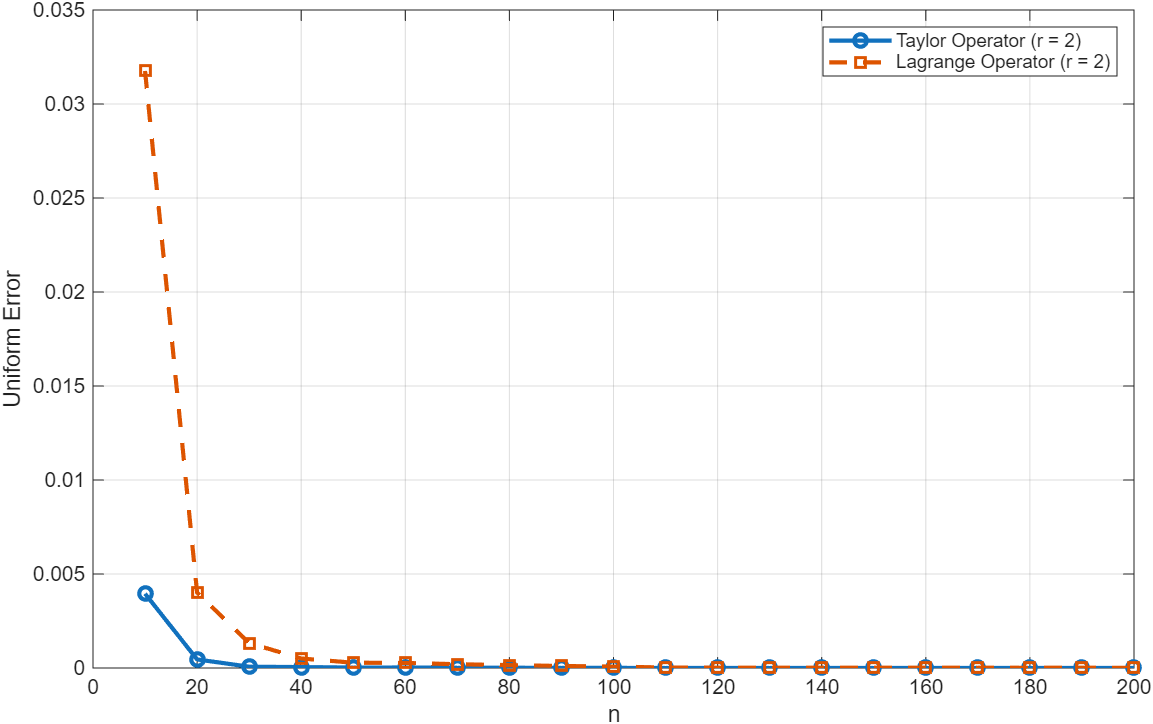
Проектирование Гибких Операторов: Активация и Выборка
В нашей системе для реализации нелинейности используются сигмоидальные функции активации. В отличие от линейных моделей, которые ограничены в представлении сложных зависимостей, сигмоидальные функции, такие как \sigma(x) = \frac{1}{1 + e^{-x}} , позволяют моделировать нелинейные отношения между входными данными и выходными значениями. Это критически важно для задач, где данные не могут быть адекватно представлены линейными функциями, обеспечивая возможность приближения к произвольным функциям и, как следствие, повышение точности и выразительности модели. Использование сигмоидальных функций позволяет создавать более сложные и адаптивные модели, способные эффективно обрабатывать широкий спектр входных данных.
Для генерации узлов дискретизации используется квазиравномерное нерегулярное разбиение. Данный подход сочетает в себе случайность распределения узлов, необходимую для предотвращения артефактов интерполяции, и определенную степень равномерности, обеспечивающую стабильность процесса. В отличие от полностью случайного или равномерного распределения, квазиравномерное разбиение стремится к минимизации кластеризации узлов и обеспечению равномерного покрытия пространства, что способствует повышению точности и эффективности интерполяции, особенно в задачах с высокой размерностью. Параметры разбиения настраиваются для достижения оптимального баланса между нерегулярностью и равномерностью, исходя из специфики решаемой задачи.
Комбинирование компактно поддерживаемых сигмоидальных функций активации с четко определенной нерегулярной сеткой позволяет достичь устойчивой и эффективной интерполяции. Компактная поддержка сигмоиды ограничивает область влияния каждого узла, снижая вычислительную сложность и обеспечивая локальность вычислений. Использование нерегулярной сетки узлов повышает устойчивость к алиасингу и обеспечивает более гибкое представление данных по сравнению с регулярными сетками. В результате, предложенный подход демонстрирует высокую производительность при интерполяции данных различной размерности и сложности, а также обеспечивает эффективное использование вычислительных ресурсов. f(x) = \frac{1}{1 + e^{-x}} является примером используемой сигмоидной функции.
К Адаптивному Аппроксимированию Функций
Разработанный новый оператор интерполяции представляет собой мощный инструмент для аппроксимации функций в различных областях, включая научные вычисления и машинное обучение. В отличие от традиционных методов, этот оператор обеспечивает более гибкое и эффективное представление функций, позволяя достигать высокой точности при меньшем объеме вычислений. Его применение охватывает широкий спектр задач — от моделирования сложных физических процессов и анализа больших объемов данных до построения и обучения алгоритмов машинного обучения. f(x) \approx \sum_{i=1}^{n} w_i \phi_i(x) — подобное представление позволяет эффективно оценивать значения функций в любой точке, используя лишь ограниченное число известных значений. В перспективе, данный оператор может стать ключевым элементом в разработке более эффективных и точных алгоритмов для решения сложных научных и инженерных задач.
Переход от использования равномерных сеток к адаптивным методам дискретизации открывает значительные возможности для повышения эффективности и точности в различных областях. Традиционные подходы, основанные на равномерном распределении точек, зачастую требуют избыточного количества вычислений для достижения приемлемой точности, особенно при аппроксимации функций с высокой степенью изменчивости или сложной структурой. Адаптивные методы, напротив, позволяют концентрировать вычислительные ресурсы в тех областях, где функция изменяется наиболее быстро, что приводит к снижению погрешности при меньшем количестве вычислений. Это особенно важно в задачах научного моделирования, где требуется высокая точность при работе с большими объемами данных, а также в машинном обучении, где эффективное представление функций является ключевым фактором для построения точных и надежных моделей. Возможность гибко адаптировать сетку к особенностям функции позволяет значительно ускорить вычисления и уменьшить требуемые ресурсы, делая сложные задачи более доступными и решаемыми.
Дальнейшие исследования направлены на разработку адаптивных стратегий выборки, учитывающих специфические характеристики аппроксимируемой функции. Вместо использования фиксированных или равномерных сеток, предлагается динамически определять точки выборки, исходя из локальной сложности и изменчивости функции. Такой подход позволит существенно повысить точность и эффективность аппроксимации, особенно в случаях, когда функция имеет резкие градиенты или сложные особенности. Планируется использование алгоритмов машинного обучения для автоматического определения оптимальной стратегии выборки, что обеспечит не только повышение производительности, но и устойчивость к шумам и погрешностям исходных данных. В результате, предложенный метод сможет эффективно применяться в широком спектре задач, от численного моделирования физических процессов до построения сложных моделей в области машинного обучения.
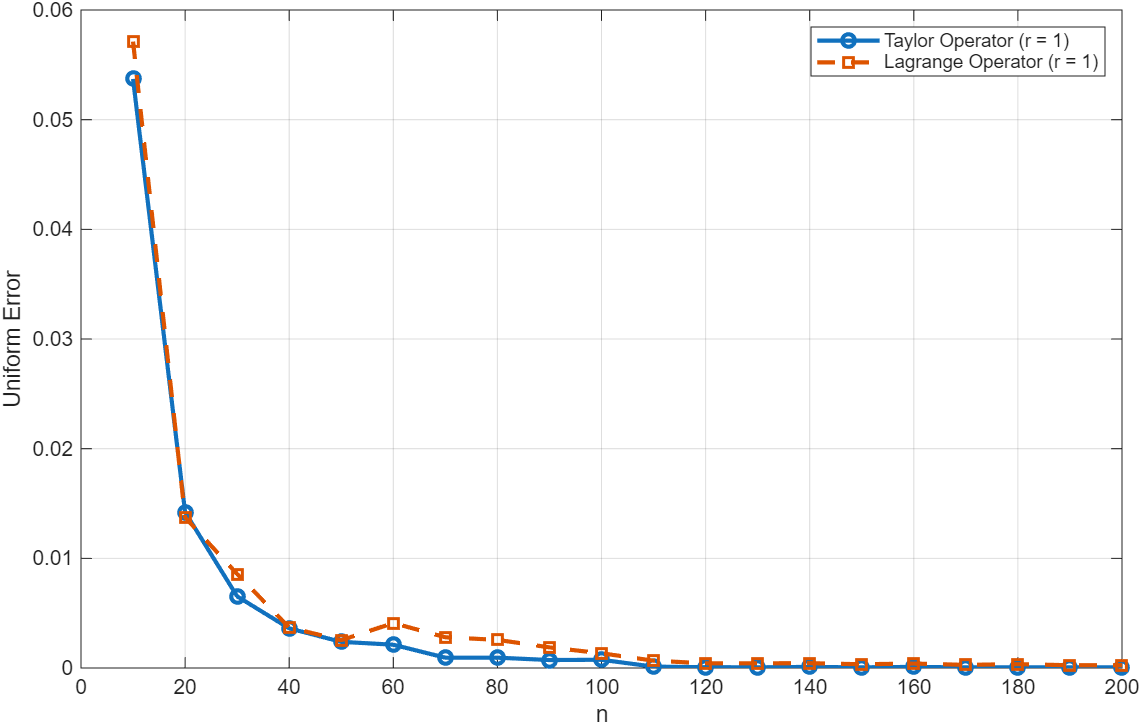
Исследование, представленное в данной работе, стремится к упрощению сложных вычислений посредством применения нейронных сетей к задачам интерполяции на нерегулярных сетках. Авторы, используя приближения Тейлора, демонстрируют возможность достижения более высоких скоростей сходимости. В стремлении к элегантности и точности, они следуют принципу, который, как заметил Альберт Эйнштейн: «Самое простое есть самое сложное, а самое сложное — самое простое». Идея заключается в том, что истинное понимание проявляется не в усложнении модели, а в её очищении от избыточности, что особенно актуально при работе с данными на нерегулярных сетках, где чрезмерная сложность может заслонить суть.
Что дальше?
Представленная работа, стремясь к элегантности аппроксимации посредством нейронных операторов на нерегулярных сетках, неизбежно обнажает новые грани сложности. Достижение более высоких порядков сходимости, безусловно, достойно внимания, однако, истинный вопрос заключается не в скорости, а в целесообразности. Погоня за точностью часто затмевает понимание природы данных, их внутренней гладкости. Оценка влияния модулей гладкости, хотя и заявлена, требует более глубокого анализа, освобожденного от излишней математической суеты.
Будущие исследования, вероятно, столкнутся с необходимостью преодоления ограничений, связанных с вычислительной стоимостью. Стремление к высокой точности не должно приводить к непрактичным алгоритмам. Гораздо более плодотворным представляется поиск компромисса между точностью и эффективностью, отказ от иллюзии абсолютной точности в пользу разумной достаточности. Важно помнить, что математика — это не инструмент для создания иллюзий, а способ постижения реальности.
Следует также обратить внимание на адаптацию этих методов к данным различной природы. Универсальность — это мираж. Эффективность интерполяции, скорее всего, будет зависеть от специфических свойств данных, их структуры и характеристик. Поиск специализированных решений, освобожденных от претензий на общую применимость, может оказаться более перспективным путем.
Оригинал статьи: https://arxiv.org/pdf/2602.05589.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
- Стиль сквозь века: математика искусства
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Искусственный разум: Нет доказательств самосознания в современных языковых моделях
- Искусственный интеллект на службе карьеры: STEM-образование нового поколения
- Ожившие Миры: Новая Эра Видеогенерации
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
2026-02-08 01:56