Автор: Денис Аветисян
Новый подход к обучению и компиляции нейронных сетей для ускорителей вычислений, использующих резистивную память, позволяет значительно повысить скорость работы без существенной потери точности.

Предложена система обучения с подкреплением и компилятор для RRAM-ускорителей вычислений в памяти, использующие смешанную точность квантования.
Несмотря на перспективность архитектур вычислений в памяти (CIM) для ускорения задач машинного обучения, ограниченная разрядность входных данных и ячеек памяти препятствует эффективному использованию ресурсов. В работе ‘Mixed-Precision Training and Compilation for RRAM-based Computing-in-Memory Accelerators’ предложен фреймворк и компилятор, использующие смешанную точность для обучения и компиляции, что позволяет оптимизировать производительность CIM-ускорителей на основе RRAM. Предложенная стратегия, основанная на обучении с подкреплением, обеспечивает ускорение до 2.48x при незначительной потере точности (0.086%). Возможно ли дальнейшее расширение области применения смешанной точности для создания еще более энергоэффективных и высокопроизводительных CIM-систем?
Перспективы Вычислительных Систем в Памяти
Современные нейронные сети, особенно глубокие, характеризуются экспоненциальным ростом вычислительной сложности. Основная нагрузка приходится на операции умножения матриц и векторов, необходимые для обработки огромных объемов данных. Традиционная архитектура фон Неймана, где процессор и память физически разделены, испытывает серьезные ограничения. Необходимость постоянного перемещения данных между этими компонентами создает так называемое «узкое место памяти», существенно замедляя процесс вычислений и потребляя значительное количество энергии. С увеличением размеров моделей и объемов обрабатываемой информации, эта проблема становится все более актуальной, ограничивая возможности дальнейшего развития искусственного интеллекта и требуя поиска альтернативных вычислительных парадигм.
В традиционных вычислительных системах, основанных на архитектуре фон Неймана, значительная задержка возникает из-за постоянного перемещения данных между процессором и памятью. Альтернативным подходом является вычислительная память (CIM), которая позволяет выполнять операции умножения матрицы на вектор M \cdot V непосредственно внутри массива памяти. Вместо того, чтобы извлекать веса матрицы и вектор из памяти в процессор, CIM осуществляет вычисления в самой памяти, существенно сокращая перемещение данных и потребление энергии. Это достигается за счет использования свойств самих ячеек памяти для выполнения арифметических операций, что открывает возможности для создания более быстрых и энергоэффективных систем, особенно для ресурсоемких задач, таких как современные нейронные сети.
Для достижения максимальной эффективности вычислений в памяти (CIM) требуется тщательная оптимизация точности модели и схем доступа к памяти. Простое перенесение существующих нейронных сетей на CIM-архитектуру не гарантирует прироста производительности; необходимо адаптировать модели, используя, например, квантование или обрезку весов, чтобы снизить вычислительную сложность и объём данных, обрабатываемых в памяти. Кроме того, порядок доступа к элементам памяти играет критическую роль: оптимальная организация доступа позволяет минимизировать энергопотребление и задержки, раскрывая весь потенциал параллельной обработки, присущий CIM. Исследования показывают, что грамотное сочетание снижения точности и оптимизации доступа к памяти может привести к значительному ускорению вычислений и снижению энергопотребления по сравнению с традиционными архитектурами, особенно в задачах, связанных с глубоким обучением и обработкой больших объёмов данных.
Оптимизация Точности с Учетом Аппаратных Особенностей
Квантование, заключающееся в уменьшении количества бит, используемых для представления весов и активаций нейронной сети, является критически важным фактором для повышения эффективности вычислений в памяти (CIM). Снижение разрядности позволяет уменьшить объем хранимых данных и, следовательно, потребляемую мощность, а также повысить скорость вычислений за счет параллельной обработки данных непосредственно в памяти. В контексте CIM, где операции умножения-аккумулирования выполняются непосредственно над весами и активациями, использование меньшего количества бит существенно снижает требования к пропускной способности и энергопотреблению, что является ключевым для развертывания моделей глубокого обучения на устройствах с ограниченными ресурсами.
Аппаратно-ориентированная автоматическая квантизация (HAQ) использует обучение с подкреплением для определения оптимальных конфигураций квантизации, учитывающих специфические характеристики целевого аппаратного обеспечения. В процессе HAQ, агент обучения с подкреплением исследует различные комбинации битовых ширин для весов и активаций нейронной сети. В качестве функции вознаграждения используется точность модели, а целью является максимизация этой точности при заданных аппаратных ограничениях. Это позволяет адаптировать процесс квантизации к конкретному оборудованию, обеспечивая наилучшую производительность и эффективность использования ресурсов.
Метод аппаратного-ориентированной автоматической квантизации (HAQ) использует смешанную прецизионную квантизацию (MPQ) для назначения различной разрядности весов и активаций слоям нейронной сети. Разрядность каждого слоя определяется на основе его чувствительности к снижению точности — слои, критичные к потерям информации, получают большую разрядность, а менее чувствительные — меньшую. Такой подход позволяет минимизировать общую потерю точности модели при сохранении преимуществ, связанных с уменьшением вычислительной сложности и энергопотребления, обеспечиваемых квантизацией.
Алгоритм Deep Deterministic Policy Gradient (DDPG) является основой процесса обучения с подкреплением в HAQ, поскольку позволяет эффективно исследовать пространство конфигураций квантования. DDPG — это алгоритм актор-критик, в котором актор определяет политику выбора конфигураций квантизации, а критик оценивает качество этих конфигураций на основе метрик точности и энергоэффективности. Ключевым элементом DDPG является использование детерминированной политики, что позволяет напрямую выбирать действия (конфигурации квантования) без случайного выбора, а также применение буфера воспроизведения опыта для повышения стабильности обучения и снижения корреляции между последовательными образцами. Обновление актора и критика происходит на основе градиентов, вычисленных на основе функции потерь, отражающей как точность модели, так и целевые показатели энергоэффективности, что позволяет оптимизировать конфигурации квантования для конкретного аппаратного обеспечения.

Вычислительные Системы в Памяти с Автоматической Квантизацией: Сближение Теории и Практики
Автоматизированная квантизация с учетом особенностей CIM (CIM-AQ) является развитием подхода HAQ, и направлена на адаптацию процесса квантизации к специфическим характеристикам оборудования CIM. В отличие от стандартных методов квантизации, CIM-AQ учитывает архитектурные особенности схем вычислений в памяти, что позволяет более эффективно отображать веса и активации нейронной сети в аппаратные ресурсы. Данный подход позволяет оптимизировать процесс квантизации для конкретных характеристик используемой памяти, таких как Resistive Random Access Memory (RRAM), что приводит к повышению производительности и снижению энергопотребления по сравнению с универсальными методами квантизации.
Для эффективного отображения данных высокой точности на массивы резистивной оперативной памяти (RRAM), используемые в вычислительных системах в памяти (CIM), применяются методы разделения битов входных данных (Input Bit Slicing, IBS) и весов (Weight Bit Slicing, WBS). IBS позволяет разложить входные данные на несколько битовых срезов, которые обрабатываются параллельно, уменьшая количество необходимых операций умножения-сложения. Аналогично, WBS разделяет веса нейронной сети на битовые срезы, что позволяет более эффективно использовать ограниченные ресурсы RRAM и снизить энергопотребление. Комбинация этих методов позволяет адаптировать данные к архитектуре CIM, оптимизируя производительность и энергоэффективность при сохранении приемлемой точности.
В основе системы лежит использование формата Open Neural Network Exchange (ONNX) для представления моделей глубокого обучения, что обеспечивает совместимость с различными фреймворками и упрощает процесс переноса моделей. Для компиляции и последующего развертывания моделей на целевом оборудовании применяется Tensor Virtual Machine (TVM). TVM позволяет оптимизировать вычислительный граф модели для конкретной аппаратной архитектуры, включая поддержку специализированных инструкций и возможностей, что приводит к повышению производительности и эффективности использования ресурсов. Использование ONNX и TVM позволяет автоматизировать процесс оптимизации и развертывания моделей, снижая требования к ручной настройке и обеспечивая переносимость между различными платформами.
Оптимизация, реализованная в CIM-AQ, демонстрирует увеличение скорости работы до 2.48x по сравнению с 8-битными компиляторами при использовании архитектуры VGG16. При этом максимальная потеря точности составляет всего 0.086%. Полученные результаты подтверждают значительное повышение производительности при сохранении приемлемого уровня точности модели, что делает данный подход перспективным для применения в системах с ограниченными ресурсами и высокими требованиями к скорости обработки.
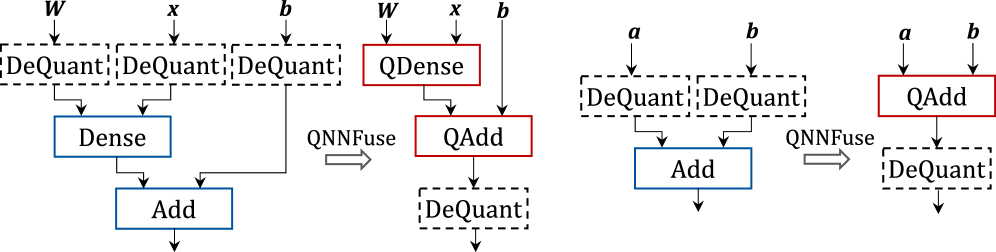
Оценка на Стандартных Моделях
Для подтверждения эффективности разработанного метода квантизации, его применимость была протестирована на общепризнанных моделях глубокого обучения, включая ResNet-18, VGG-16 и ViT-B/32. Выбор этих архитектур обусловлен их широким распространением в задачах компьютерного зрения и служит эталоном для сравнения различных оптимизаций. Использование данных набора ImageNet, стандартного бенчмарка для классификации изображений, позволило получить объективные и воспроизводимые результаты, демонстрирующие способность предложенного подхода к ускорению вычислений без существенной потери точности.
Для надёжной оценки предложенного метода квантизации, модели ResNet-18, VGG-16 и ViT-B/32 были обучены и протестированы на наборе данных ImageNet — признанном эталоне для задач классификации изображений. ImageNet содержит более 14 миллионов изображений, размеченных по тысяче различных категорий, что обеспечивает строгую и всестороннюю проверку способности моделей к обобщению. Использование этого стандартного набора данных позволяет провести объективное сравнение с другими современными подходами и подтвердить эффективность разработанной квантизационной схемы в реальных условиях, где требуется высокая точность и скорость обработки изображений.
Проведенные тесты показали, что предложенная методика квантизации обеспечивает ускорение работы нейронных сетей как минимум в 2.20 раза на различных архитектурах, включая ResNet-18, VGG-16 и ViT-B/32. При этом, максимальное снижение точности классификации изображений, измеренное на стандартном наборе данных ImageNet, составило лишь 2.140%. Данный результат демонстрирует значительный прирост производительности при незначительной потере в качестве, подтверждая эффективность предложенного подхода для ускорения процесса вывода в задачах глубокого обучения и обеспечивая наивысший показатель S/AL при одновременном соблюдении ограничений по скорости и точности.
Полученные результаты валидации подтверждают ощутимые преимущества предложенного фреймворка CIM-AQ в ускорении процесса инференса глубоких нейронных сетей. В ходе экспериментов, с учетом ограничений по скорости и точности, удалось добиться наивысшего показателя S/AL (Speed/Accuracy), превосходящего аналогичные решения. Это свидетельствует о высокой эффективности CIM-AQ в достижении оптимального баланса между производительностью и сохранением точности, что делает его перспективным инструментом для широкого спектра задач, требующих быстрого и надежного анализа данных.

Исследование, представленное в данной работе, демонстрирует, что системы, подобные RRAM-ускорителям, способны к адаптации и оптимизации даже в условиях ограниченных ресурсов. Этот процесс напоминает эволюцию, где смешанное квантование с точностью, управляемое обучением с подкреплением, выступает в роли механизма отбора наиболее эффективных конфигураций. Ада Лавлейс метко подметила: «То, что может быть выражено в виде алгоритма, может быть сделано машиной». Данное исследование подтверждает эту мысль, показывая, как алгоритмический подход к оптимизации точности позволяет создавать более быстрые и эффективные вычислительные системы, при этом минимизируя потери точности. Оптимизация, основанная на данных и постоянном обучении, является ключом к долговечности и эффективности любой системы.
Что впереди?
Представленная работа демонстрирует, как системы, основанные на памяти RRAM, могут научиться эффективно стареть, адаптируя точность вычислений к имеющимся ресурсам. Однако, стремление к максимальной скорости не должно заслонять более глубокие вопросы. Оптимизация точности — лишь одна грань. Гораздо интереснее наблюдать, как системы учатся справляться с неизбежной энтропией, как они приспосабливаются к деградации компонентов и шуму, присущему физическим устройствам. Ускорение вычислений — это лишь следствие, а не цель.
Следующим шагом видится не столько поиск новых алгоритмов квантования, сколько исследование механизмов самовосстановления и адаптации в подобных системах. Мудрые системы не борются с неизбежным, они учатся дышать вместе с ним. Усилия, направленные на повышение устойчивости к ошибкам и оптимизацию энергопотребления в условиях деградации, представляются более перспективными, чем погоня за абсолютной производительностью. Иногда наблюдение за процессом старения — единственная форма участия.
Подобные системы, как и любые другие, со временем научатся не спешить. Важно понять, что истинная эффективность проявляется не в скорости, а в способности сохранять функциональность и адаптироваться к меняющимся условиям. Дальнейшие исследования должны быть направлены на создание систем, способных достойно стареть, сохраняя свою полезность и ценность на протяжении всего жизненного цикла.
Оригинал статьи: https://arxiv.org/pdf/2601.21737.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Искусственный интеллект на допросе: как объяснить решения в цифровой криминалистике?
2026-01-31 02:10