Автор: Денис Аветисян
Новое исследование демонстрирует, как с помощью всего нескольких примеров можно научить крупные языковые модели создавать эффективные архитектуры нейронных сетей для задач компьютерного зрения.
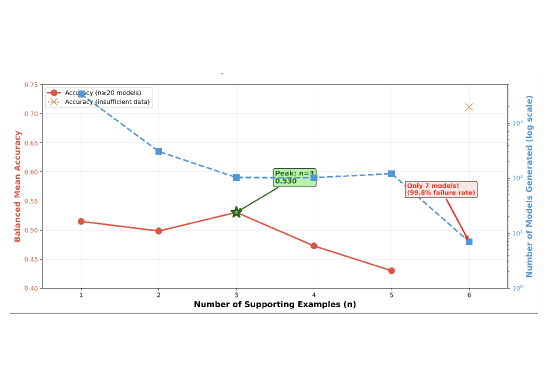
В статье представлен метод оптимизации генерации нейросетей с использованием больших языковых моделей, включающий обучение на небольшом количестве примеров и эффективную нормализацию кода для устранения дубликатов.
Автоматизированный поиск архитектур нейронных сетей остается сложной задачей, требующей баланса между эффективностью и вычислительными затратами. В работе «Enhancing LLM-Based Neural Network Generation: Few-Shot Prompting and Efficient Validation for Automated Architecture Design» представлено исследование возможностей больших языковых моделей (LLM) для генерации архитектур, ориентированное на задачи компьютерного зрения. Показано, что использование трех примеров архитектур в запросах к LLM обеспечивает оптимальный баланс между разнообразием и контекстной фокусировкой, а предложенный метод нормализации пробелов для дедупликации кода значительно ускоряет процесс. Как можно будет использовать эти результаты для создания еще более доступных и эффективных инструментов автоматического проектирования нейронных сетей?
По ту сторону традиционного NAS: обещание больших языковых моделей
Традиционные методы автоматического поиска архитектур нейронных сетей (NAS) характеризуются значительными вычислительными затратами и требуют кропотливой настройки гиперпараметров. Этот процесс часто включает в себя перебор огромного количества возможных конфигураций, что требует колоссальных ресурсов и времени. Каждая итерация поиска, включающая обучение и оценку предложенной архитектуры, может занять часы или даже дни на мощных вычислительных системах. Более того, эффективность NAS сильно зависит от выбора оптимальных гиперпараметров, таких как скорость обучения, размер пакета и стратегии регуляризации, что требует дополнительных экспериментов и анализа. В результате, несмотря на потенциал автоматизации процесса проектирования нейронных сетей, традиционные методы NAS остаются ресурсоемкими и сложными в применении, особенно для задач с ограниченными вычислительными возможностями.
Вместо трудоемкого перебора вариантов, традиционно используемого в поиске оптимальных нейронных сетей, всё большее внимание привлекают большие языковые модели (LLM) как инструмент для непосредственной генерации кода, описывающего архитектуру сети. Этот подход позволяет создавать нейронные сети, опираясь на текстовые описания желаемых характеристик, фактически “описывая” сеть вместо ее построения методом проб и ошибок. LLM, обученные на огромных объемах кода и данных, способны синтезировать архитектуры, соответствующие заданным требованиям, открывая перспективы для автоматизированного и интуитивно понятного проектирования нейронных сетей, что значительно упрощает и ускоряет процесс разработки.
Происходит кардинальный сдвиг в области разработки нейронных сетей: от трудоемких процессов поиска оптимальной архитектуры к более интуитивному подходу, основанному на текстовых запросах. Вместо многократного тестирования и настройки различных конфигураций, исследователи теперь могут описывать желаемые характеристики сети на естественном языке, а большая языковая модель генерирует соответствующую архитектуру. Этот переход позволяет значительно ускорить процесс проектирования и открыть возможности для создания специализированных сетей, адаптированных под конкретные задачи, без необходимости глубоких знаний в области машинного обучения. Такой подход не только упрощает разработку, но и стимулирует творчество, позволяя исследователям экспериментировать с новыми идеями и концепциями, выраженными в простой и понятной форме.
Эффективное конструирование запросов: стратегия обучения с небольшим количеством примеров
Эффективное построение запросов (prompting) является ключевым фактором для получения качественных архитектур нейронных сетей от больших языковых моделей (LLM). Метод обучения с небольшим количеством примеров (Few-Shot Learning) представляет собой мощный инструмент в этом процессе. Он заключается в предоставлении LLM небольшого набора примеров желаемых архитектур вместе с запросом, что позволяет модели понять и воспроизвести соответствующие паттерны проектирования. В отличие от обучения с нуля или тонкой настройки, Few-Shot Learning требует значительно меньше данных и вычислительных ресурсов, что делает его практичным решением для задач генерации архитектур, особенно в компьютерном зрении.
Метод Few-Shot Architecture Prompting заключается в систематическом обогащении запросов примерами хорошо зарекомендовавших себя архитектур, что обеспечивает LLM необходимый контекст для генерации новых решений. Вместо предоставления LLM только описания задачи, данный подход предоставляет несколько полных примеров желаемых архитектур, включая их структуру и, возможно, параметры. Это позволяет модели не просто следовать инструкциям, а изучать и воспроизводить успешные паттерны проектирования, значительно повышая качество генерируемых архитектур, особенно в задачах компьютерного зрения и обработки изображений.
При использовании метода обучения с небольшим количеством примеров (Few-Shot Learning) для генерации архитектур нейронных сетей в задачах компьютерного зрения, оптимальное количество поддерживающих примеров составляет три (n=3). Экспериментальные данные показывают, что применение трех примеров в промпте обеспечивает наивысшую сбалансированную среднюю точность, достигающую 53.1%. Данный результат был получен в ходе тестирования различных конфигураций промптов и подтверждает, что использование именно трех примеров позволяет модели наиболее эффективно усваивать желаемые шаблоны проектирования, обеспечивая при этом сбалансированную производительность в задачах генерации архитектур.
Использование методики Few-Shot обучения в сочетании с Chain-of-thought prompting позволяет языковым моделям (LLM) усваивать желаемые шаблоны проектирования архитектур на ограниченном объеме данных. В результате, наблюдается повышение точности на 11.6% при работе с набором данных CIFAR-100 (p=0.001). Данный подход позволяет LLM не просто генерировать архитектуры, но и демонстрировать улучшенное логическое мышление при их проектировании, что положительно сказывается на результатах.
Оптимизация промптов является критически важной задачей, поскольку необходимо соблюдать баланс между обогащением контекста и риском возникновения переполнения контекстного окна (Context Overflow), что может привести к снижению производительности модели. Переполнение контекста возникает, когда длина промпта превышает максимальную длину, которую может обработать языковая модель, что приводит к отбрасыванию части информации или ухудшению качества генерации. Поэтому, при разработке промптов для обучения с небольшим количеством примеров (Few-Shot Learning), необходимо тщательно оценивать объем предоставляемого контекста, чтобы избежать снижения точности и эффективности модели. Эффективная оптимизация подразумевает выбор наиболее релевантных и информативных примеров, а также использование методов сокращения длины промпта без потери существенной информации.
Устранение уникальности кода: облегченная дедупликация
В процессе генерации архитектур с использованием больших языковых моделей (LLM) возникает проблема уникальности кода, заключающаяся в том, что модели часто генерируют функционально идентичные архитектуры, отличающиеся лишь незначительными различиями в форматировании, такими как пробелы и отступы. Это приводит к избыточности в наборах данных для обучения, увеличивает время обучения и требует дополнительных вычислительных ресурсов. Проблема заключается не в различиях в логике или функциональности кода, а в его поверхностном представлении, что делает обнаружение и устранение дубликатов сложной задачей. Игнорирование этой проблемы может привести к неэффективному использованию ресурсов и замедлить процесс разработки.
Нормализация пробелов и последующее хеширование, например, с использованием MD5, представляет собой эффективный и легковесный метод для выявления и устранения дубликатов архитектур кода. Этот подход предполагает приведение исходного кода к единому формату путем удаления или стандартизации пробельных символов, что позволяет игнорировать поверхностные различия в форматировании. Полученный нормализованный код затем преобразуется в хеш-значение, которое используется для быстрой идентификации идентичных архитектур. В отличие от сравнения на основе токенов, этот метод устойчив к вариациям форматирования, и он обходится дешевле в вычислительном плане по сравнению с анализом абстрактного синтаксического дерева (AST).
В отличие от сопоставления кода на основе токенов, которое чувствительно к вариациям форматирования (например, к пробелам и переносам строк), и трудоемкого сравнения на основе абстрактного синтаксического дерева (AST), предлагаемый метод нормализации пробелов и хеширования обеспечивает более надежное определение дубликатов архитектур. Подход на основе токенов может ошибочно идентифицировать функционально идентичный код как различный из-за незначительных изменений в форматировании, в то время как построение и анализ AST требует значительно больших вычислительных ресурсов. Нормализация пробелов позволяет игнорировать эти поверхностные различия, а хеширование (например, с использованием MD5) обеспечивает быструю и эффективную проверку на дубликаты без необходимости дорогостоящего синтаксического анализа.
Проект NNGPT продемонстрировал эффективность данного подхода, выполнив тонкую настройку модели DeepSeek Coder на наборе данных LEMUR и интегрировав технику дедупликации. Время вычисления хеша для каждого образца кода составило менее 1 миллисекунды, что подтверждает возможность применения данного метода в задачах, требующих обработки больших объемов данных в реальном времени. Использование хешей позволило идентифицировать и исключить дубликаты архитектур, оптимизируя процесс обучения и снижая вычислительные затраты.
Применение метода удаления дубликатов архитектур кода в проекте NNGPT позволило достичь значительной экономии вычислительных ресурсов. Оценка экономии составляет от 200 до 300 GPU-часов, что обусловлено предотвращением повторного обучения на идентичных архитектурах. Устранение дубликатов, выявленных посредством нормализации пробелов и хеширования, позволяет эффективно использовать доступные GPU ресурсы и ускорить процесс обучения модели, особенно при работе с большими наборами данных, такими как LEMUR Dataset.
Валидация и производительность: новая эра для NAS
Проект NNGPT демонстрирует перспективную альтернативу традиционным методам автоматизированного проектирования нейронных сетей (NAS) благодаря интеграции больших языковых моделей (LLM) с эффективными техниками дедупликации. Этот подход позволяет значительно снизить вычислительные затраты, поскольку LLM способны генерировать архитектуры нейронных сетей, избегая повторения уже исследованных вариантов. Вместо дорогостоящего перебора различных конфигураций, LLM, обученные на существующих данных о нейронных сетях, способны предлагать новые, потенциально более эффективные решения, что открывает возможности для более широкого исследования пространства поиска и создания инновационных архитектур, способных превзойти результаты, достигнутые традиционными методами NAS.
Тщательная оценка сгенерированных архитектур нейронных сетей требует применения строгих статистических методов. В рамках исследований особое внимание уделяется использованию Dataset-Balanced Statistics, позволяющих избежать предвзятости, возникающей при оценке на несбалансированных наборах данных. Для подтверждения значимости полученных результатов применяется независимый t-критерий, обеспечивающий статистическую достоверность сравнения производительности новых архитектур с существующими. Игнорирование этих методов может привести к ошибочным выводам о реальной эффективности предложенных решений, поэтому валидация с использованием надежных статистических инструментов является неотъемлемой частью процесса разработки и оптимизации нейронных сетей.
Исследования показали, что количество примеров, предоставляемых большой языковой модели (LLM) для генерации архитектур нейронных сетей, критически влияет на результат. Несмотря на то, что использование трех примеров обеспечило наивысшую сбалансированную среднюю точность, увеличение этого числа до шести привело к катастрофическому росту частоты неудачных генераций, достигшей 99.8%. Это подчеркивает важность тщательной оптимизации запросов (prompt engineering) и выбора оптимального количества обучающих примеров для достижения надежных и эффективных результатов в автоматизированном проектировании нейронных сетей. Недостаточная оптимизация может привести к полному провалу процесса генерации, даже при использовании мощных LLM.
Предложенный подход к автоматическому проектированию нейронных сетей не только существенно снижает вычислительные затраты, но и открывает принципиально новые возможности для исследования архитектурного пространства. Традиционные методы, ограниченные ресурсами и временем, зачастую вынуждают исследователей фокусироваться на узком подмножестве возможных конфигураций. В отличие от них, интеграция больших языковых моделей (LLM) позволяет быстро генерировать и оценивать огромное количество разнообразных архитектур, выходя за рамки привычных шаблонов. Это, в свою очередь, создает условия для обнаружения инновационных и высокоэффективных решений, которые могли бы остаться незамеченными при использовании стандартных методов проектирования. Возможность исследовать более широкий спектр вариантов позволяет находить оптимальные конфигурации для конкретных задач, адаптируя архитектуру к специфическим требованиям и ограничениям, что ведет к повышению производительности и снижению энергопотребления.
Предлагаемый подход открывает перспективы для автоматизации и значительного ускорения процесса разработки нейронных сетей. Исследования демонстрируют, что большие языковые модели (LLM) способны не только генерировать архитектуры нейронных сетей, но и оптимизировать их, предлагая альтернативу традиционным, трудоемким методам. В будущем LLM могут стать ключевым инструментом для инженеров и исследователей, позволяя им исследовать более широкий спектр проектных решений и создавать более эффективные и инновационные архитектуры с меньшими вычислительными затратами. Это может привести к революции в области машинного обучения, где дизайн нейронных сетей станет более доступным и быстрым, а инновации будут появляться с беспрецедентной скоростью.
Исследование показывает, что даже самые передовые модели, вроде больших языковых, не избавлены от необходимости в простых примерах. Авторы предлагают использовать всего три архитектуры в качестве подсказки, и это, как ни странно, работает. Напоминает старый анекдот про ученика, которому показали, как правильно забивать гвозди, а он просто взял молоток и начал стучать. Похоже, даже нейросети нужно немного «пощупать» реальность, прежде чем генерировать что-то новое. Как метко заметил Джеффри Хинтон: «Я думаю, что мы все еще очень далеки от создания машин, которые могут думать, как люди». И, вероятно, ещё долго будем подсовывать им примеры, надеясь, что они хоть что-то поймут. Особенно учитывая, что предложенная нормализация пробелов — это, по сути, попытка навести порядок в хаосе, который порождает сам код.
Что дальше?
Представленная работа, безусловно, демонстрирует, что даже несколько примеров архитектур могут направить большую языковую модель в нужное русло. Однако, оптимизм относительно автоматического проектирования нейронных сетей, как правило, быстро упирается в суровую реальность. Всё это, конечно, интересно, пока не возникнет необходимость масштабировать предложенный подход на задачи, требующие не десятков, а сотен или тысяч параметров. Тогда и проявятся истинные пределы контекстного окна, а элегантные решения по нормализации пробелов покажутся лишь косметической мерой.
Вероятно, более продуктивным направлением исследований станет не столько поиск идеального промпта, сколько разработка методов верификации сгенерированных архитектур. Ведь, как показывает практика, «scalable» часто означает лишь «не тестировалось под нагрузкой». Локальная оптимизация посредством LoRA — это, конечно, хорошо, но настоящая проблема — это глобальная согласованность и устойчивость всей системы.
В конечном счете, не исключено, что иногда лучше монолитный, тщательно отлаженный энsemble, чем сотня микросервисов, каждый из которых лжёт о своей производительности. И пусть это звучит старомодно, но, возможно, в погоне за автоматизацией мы упускаем из виду простую истину: иногда ручная работа всё ещё даёт лучшие результаты.
Оригинал статьи: https://arxiv.org/pdf/2512.24120.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-02 16:14