Автор: Денис Аветисян
Исследователи предложили новый тип нейронных сетей, способный более эффективно аппроксимировать функции, заданные наборами данных, открывая новые возможности для машинного обучения.
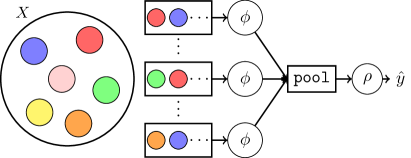
В статье представлена архитектура Quasi-Arithmetic Neural Networks (QUANN), использующая обучаемое среднее Колмогорова для повышения выразительности и обобщающей способности при аппроксимации функций на наборах.
Представление данных в виде множеств является фундаментальной задачей, однако стандартные подходы, такие как DeepSets и PointNet, используют фиксированные операции агрегации, ограничивая выразительность моделей и обобщающую способность. В данной работе, посвященной ‘Improving Set Function Approximation with Quasi-Arithmetic Neural Networks’, предложен новый подход — Quasi-Arithmetic Neural Networks (QUANNs), использующий обучаемое обобщение Колмогорова для повышения точности аппроксимации функций множеств. Теоретический анализ подтверждает универсальность QUANNs для широкого класса декомпозиций, а экспериментальные результаты демонстрируют превосходство над современными аналогами и улучшенную переносимость полученных представлений. Сможет ли предложенный подход открыть новые горизонты в обработке неструктурированных данных и построении более эффективных моделей машинного обучения?
Вызов множеств: Инвариантность к перестановкам как краеугольный камень
Многие задачи из реального мира требуют моделирования функций, работающих с множествами, где порядок элементов не имеет значения. Это представляет собой серьезную проблему для традиционных нейронных сетей, которые, как правило, разработаны для обработки последовательностей, где порядок играет ключевую роль. Например, при анализе корзины покупок или определении состава химического соединения важна не последовательность элементов, а их наличие и количество. Традиционные архитектуры нейронных сетей, ориентированные на последовательную обработку данных, оказываются неэффективными в таких случаях, поскольку незначительные изменения в порядке ввода могут приводить к существенным изменениям в выходных данных, что делает их непригодными для задач, требующих инвариантности к перестановкам.
Достижение инвариантности к перестановкам — то есть, обеспечение согласованности выходных данных независимо от порядка входных элементов — является критически важным требованием для многих задач, связанных с анализом множеств. Однако, реализация данной инвариантности часто сопряжена со значительными вычислительными затратами. Традиционные методы, такие как простое суммирование или усреднение, не способны эффективно улавливать сложные взаимосвязи внутри множеств, что приводит к снижению точности и увеличению времени обработки. Поэтому, разработка эффективных и масштабируемых алгоритмов, гарантирующих инвариантность к перестановкам без существенного увеличения вычислительной сложности, представляет собой важную задачу в области машинного обучения и анализа данных.
Первые попытки обработки множеств с помощью нейронных сетей, такие как простое суммирование или усреднение элементов, зачастую оказывались неэффективными для выявления сложных взаимосвязей внутри этих множеств. Эти методы не учитывают позицию каждого элемента, что приводит к потере информации о структуре множества и, как следствие, к неточным результатам. Например, при анализе набора ингредиентов для рецепта, простое усреднение не позволит выделить ключевые комбинации, определяющие вкус блюда. Более того, при изменении порядка элементов во входном множестве, такие подходы выдают существенно отличающиеся результаты, что делает их непригодными для задач, требующих инвариантности к перестановкам. Таким образом, возникла необходимость в разработке более сложных и эффективных методов, способных учитывать внутреннюю структуру и взаимосвязи элементов в множествах.
Архитектуры, стремящиеся к инвариантности: Строительные блоки
Методы, такие как DeepSets и PointNet, решали проблему пермутационной инвариантности посредством операций пулинга (pooling). В процессе агрегации информации от элементов множества, пулинг неизбежно приводит к потере детализированных данных о каждом отдельном элементе и их взаимном расположении. Например, при максимальном пулинге (max-pooling) выбирается только максимальное значение признака, игнорируя остальные, что может привести к утрате важной информации о структуре входных данных. Это ограничение побудило к разработке альтернативных подходов, направленных на сохранение более полной информации о наборе элементов при обеспечении пермутационной инвариантности.
Архитектура SetTransformer использует механизмы внимания (attention) для моделирования взаимосвязей между элементами множества, что обеспечивает повышенную выразительность по сравнению с подходами, основанными на операциях объединения (pooling). Вместо агрегации информации об элементах множества в единый вектор, SetTransformer позволяет каждому элементу взаимодействовать с другими элементами, вычисляя взвешенные суммы, где веса определяются функцией внимания. Это позволяет модели учитывать контекст каждого элемента внутри множества и более эффективно извлекать информацию о его взаимосвязях с другими элементами, что приводит к улучшению производительности в задачах, требующих понимания структуры и отношений внутри множеств данных.
Несмотря на перспективность подходов, таких как DeepSets, PointNet и SetTransformer, к построению инвариантных к перестановкам архитектур, их вычислительная сложность часто является ограничивающим фактором. Применение механизмов внимания, как в SetTransformer, и сложных операций агрегации требует значительных ресурсов памяти и времени обработки, особенно при увеличении размера входного множества. Это затрудняет масштабирование моделей для задач, требующих обработки больших объемов данных или работы в режиме реального времени, и требует оптимизации архитектуры или использования специализированного аппаратного обеспечения для достижения приемлемой производительности.
Нейрализованное среднее Колмагорова: Новая парадигма агрегации
Среднее Колмагорова представляет собой обобщение стандартных средних, позволяющее вычислять среднее значение функции по заданной мере, а не только по дискретному набору данных. В отличие от арифметического среднего, которое вычисляет \frac{1}{n} \sum_{i=1}^{n} x_i , среднее Колмагорова требует вычисления интеграла \in t f(x) d\mu(x) , где \mu(x) — мера вероятности. Непосредственное вычисление этого интеграла часто оказывается вычислительно сложным или невозможным, особенно в задачах с высокой размерностью или сложными функциями, что ограничивает практическое применение данного метода. Вычислительная сложность связана с необходимостью оценки интеграла в многомерном пространстве, что требует значительных ресурсов и времени.
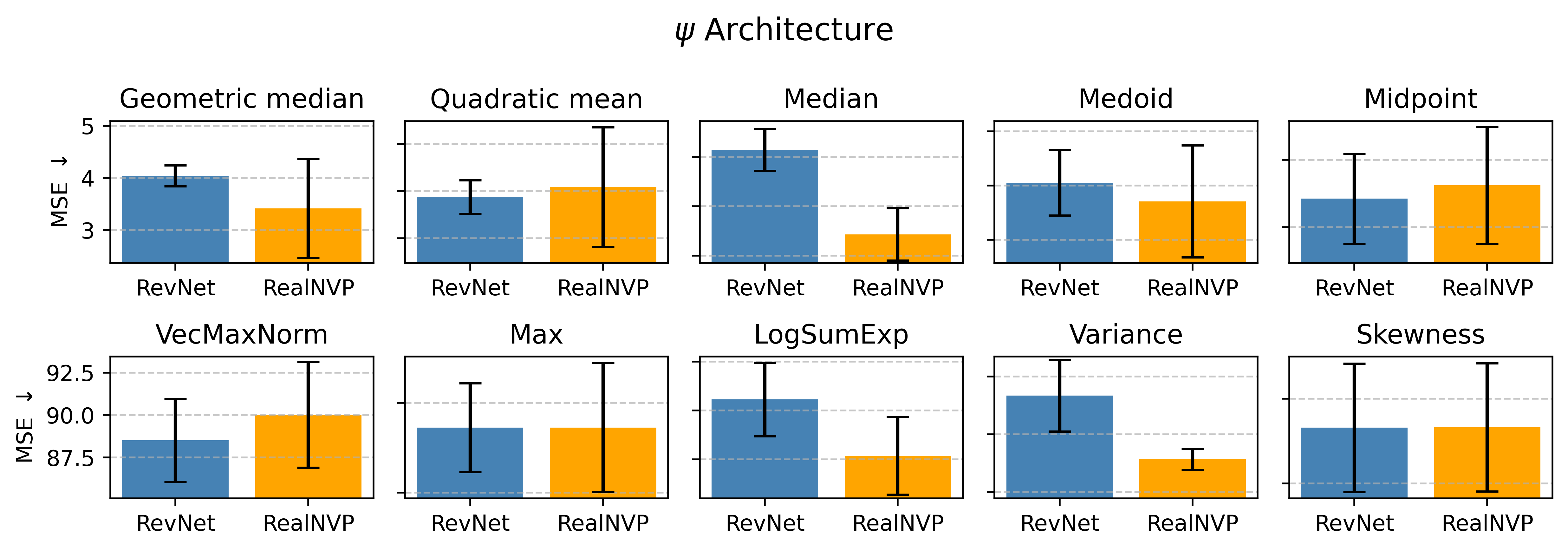
Нейрализованное среднее Колмагорова решает проблему вычислительной сложности прямого вычисления интеграла Колмогорова путем обучения генерирующей функции. В качестве архитектуры для реализации этой функции часто используются RevNet и подобные обратимые нейронные сети, позволяющие эффективно аппроксимировать интеграл Колмогорова. Обучение генерирующей функции позволяет избежать прямого вычисления сложного интеграла, заменяя его операцией прохода по нейронной сети, что значительно снижает вычислительные затраты и делает метод применимым к задачам, где прямое вычисление невозможно.
Гарантия липшицевой непрерывности (Lipschitz continuity) является ключевым свойством, обеспечивающим стабильность и устойчивость процесса обучения при использовании Neuralized Kolmogorov Mean. Липшицева непрерывность означает, что небольшие изменения во входных данных приводят к ограниченным изменениям в выходных данных, что предотвращает резкие скачки и обеспечивает предсказуемость модели. Математически, это выражается как |f(x) - f(y)| \le L ||x - y|| , где L — константа Липшица, а ||x - y|| — метрика расстояния между входными векторами. Поддержание липшицевой непрерывности критично для предотвращения переобучения и обеспечения обобщающей способности модели на новых данных, особенно в задачах, требующих высокой точности и надежности.

QUANN: Квази-арифметические нейронные сети для обучения функциям множеств
В основе QUANN лежит концепция нейрализованного среднего Колмогорова, выступающего в роли фундаментального строительного блока для эффективного обучения функциям, оперирующим с множествами. Этот подход позволяет сети обрабатывать входные данные, представленные в виде неупорядоченных наборов, без необходимости предварительной сортировки или упорядочивания. Нейрализованное среднее Колмогорова, по сути, представляет собой дифференцируемую аппроксимацию классического среднего Колмогорова, что позволяет использовать стандартные методы градиентного спуска для оптимизации параметров сети. Благодаря этой ключевой особенности QUANN способна эффективно улавливать сложные взаимосвязи внутри входных множеств и, как следствие, демонстрирует высокую производительность при решении задач, связанных с анализом и обработкой данных, представленных в виде наборов элементов. \mathbb{E}_x[f(x)] — пример представления среднего значения, которое, будучи нейрализованным, становится ключевым компонентом архитектуры QUANN.
В основе QUANN лежит способность обрабатывать множества данных, используя различные методы декомпозиции — суммирование, усреднение и выбор максимума. Такой подход позволяет сети эффективно выявлять и моделировать разнообразные взаимосвязи внутри входных множеств. Вместо того, чтобы рассматривать множество как неупорядоченный набор элементов, QUANN применяет эти операции для агрегации информации, позволяя ей адаптироваться к различным структурам данных. Например, суммирование может быть полезно для анализа совокупных эффектов, в то время как усреднение позволяет выявить общие тенденции, а выбор максимума — выделить наиболее значимые элементы. Гибкость в применении этих методов декомпозиции делает QUANN особенно эффективной при работе с данными, где важны не отдельные значения, а их совокупное влияние и взаимосвязи.
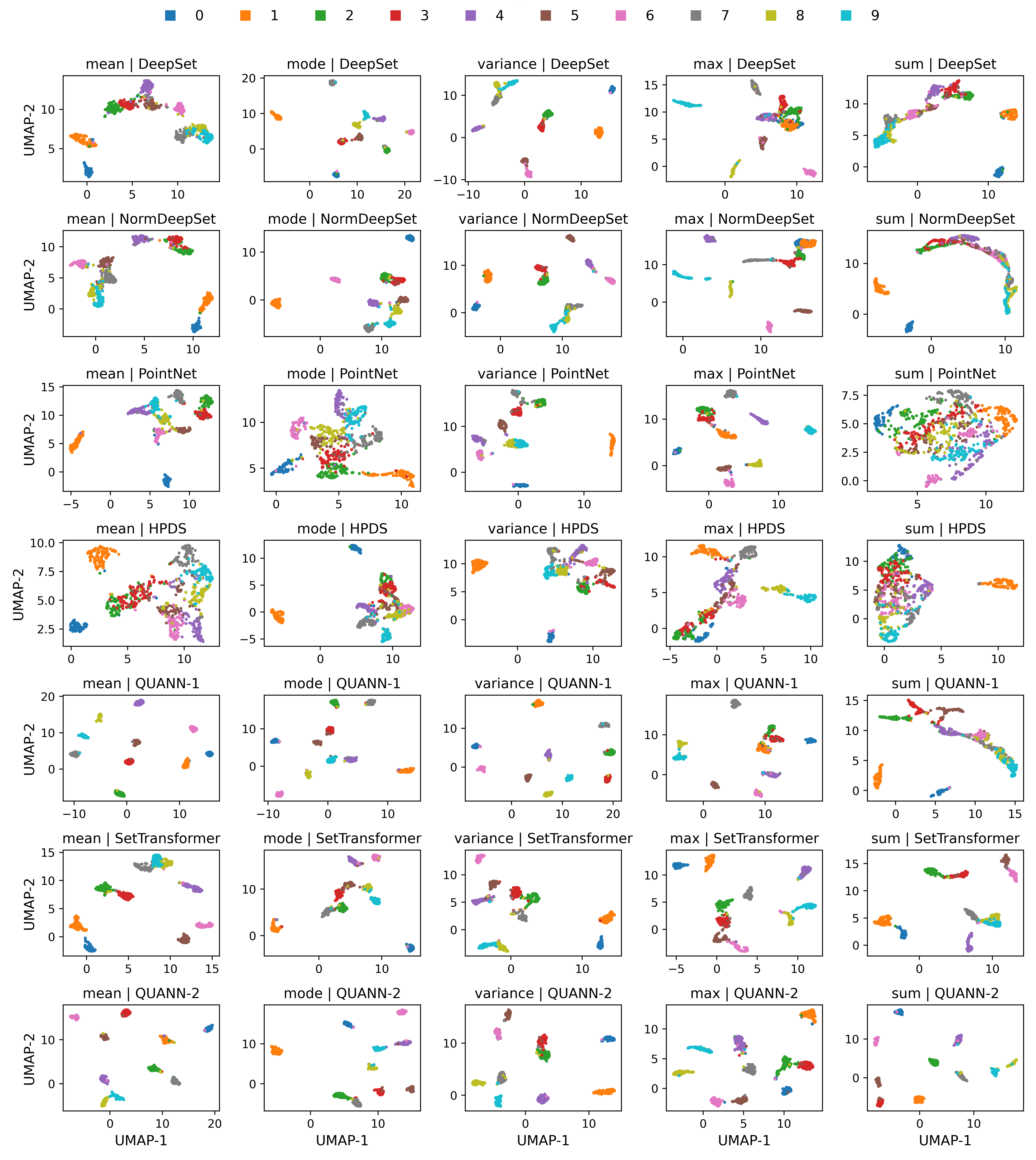
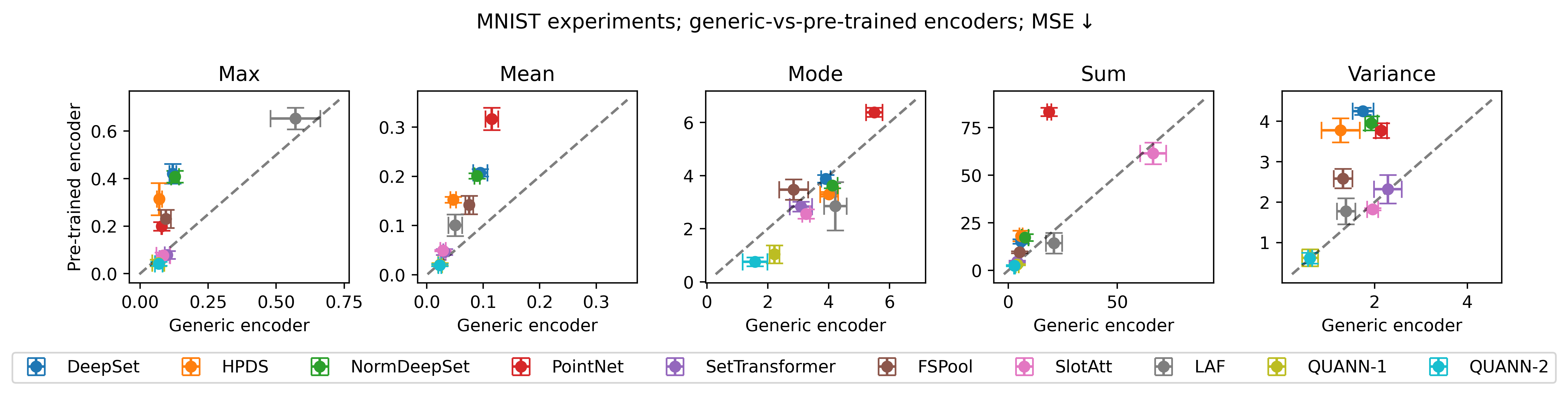
Результаты обширных сравнительных тестов однозначно демонстрируют превосходство QUANN над существующими моделями в задачах обучения функциям множеств. В ходе парных сравнений, QUANN показал значимый выигрыш, что подтверждено статистически значимыми результатами биномиального теста (p < 0.01 для значительного числа случаев). Такой результат свидетельствует о том, что разработанная архитектура обеспечивает более точное и эффективное моделирование сложных зависимостей в данных, представленных в виде множеств, и открывает новые возможности для применения в различных областях, где требуется анализ и обработка неструктурированных данных.
Архитектура QUANN демонстрирует впечатляющую масштабируемость благодаря гарантированным границам аппроксимации. Для функций, которые могут быть представлены через операцию максимума (Max-Decomposable Functions), ошибка аппроксимации ограничена величиной ≤ La<i>log(n) + ε , где La — константа, зависящая от функции, n — размер входного набора данных, а ε — допустимая погрешность. В случае функций, основанных на суммировании (Sum-Decomposable Functions), ошибка аппроксимации выражается как ≤ La</i>(n<i>B1 - w</i>B0) + ε , где B1 и B0 — параметры, определяющие сложность функции. Ключевым является то, что зависимость от размера набора данных n в этих выражениях логарифмическая или линейная, что обеспечивает эффективную обработку больших объемов информации и предотвращает экспоненциальный рост вычислительных затрат по мере увеличения масштаба данных.
Архитектура QUANN обеспечивает надежность и устойчивость благодаря гарантированной инвариантности к перестановкам входных данных. Это означает, что порядок элементов в наборе не влияет на результат вычислений, что критически важно для множества практических задач. Такая особенность позволяет QUANN эффективно работать с неструктурированными данными и избежать проблем, связанных с чувствительностью к порядку, которые часто возникают в традиционных нейронных сетях. Инвариантность к перестановкам делает QUANN особенно полезным в приложениях, где важна обобщающая способность и устойчивость к изменениям в представлении данных, например, в задачах анализа изображений, обработки естественного языка и прогнозирования, где порядок элементов может быть произвольным или нерелевантным.
Работа демонстрирует стремление к упрощению сложных вычислений, что находит отклик в словах Винтона Серфа: «Сложность — это тщеславие. Ясность — милосердие». Предложенные Quasi-Arithmetic Neural Networks (QUANNs) стремятся к более эффективному представлению функций над множествами, используя обучаемое среднее Колмогорова. Авторы подчеркивают важность инвариантности к перестановкам, что является ключевым аспектом для обработки неупорядоченных данных. Подход позволяет добиться лучшей обобщающей способности и переносимости моделей, избегая излишней сложности в архитектуре сети. Каждая сложность требует алиби, и данная работа предоставляет убедительное обоснование для предложенного упрощения.
Что дальше?
Представленные сети, использующие квази-арифметическое среднее, предлагают лишь частичное решение проблемы аппроксимации функций, определённых на множествах. Улучшение выразительности — это, конечно, прогресс, но истинная сложность кроется не в количестве параметров, а в их архитектурной честности. Очевидно, что текущая реализация требует дальнейшей оптимизации в части вычислительной эффективности; «улучшение» не имеет ценности, если оно сопровождается экспоненциальным ростом затрат.
Следующим шагом представляется не поиск новых агрегационных функций, а критический анализ существующих. Необходимо выяснить, какие свойства функций действительно важны для обобщения, а какие — лишь статистический шум. Попытки построить универсальную сеть, способную аппроксимировать любую функцию на множестве, представляются тщеславными; целесообразнее сосредоточиться на классах функций, имеющих практическую значимость.
В конечном итоге, задача сводится не к созданию более сложных моделей, а к более глубокому пониманию природы функций, определённых на множествах. Иногда, самые элегантные решения оказываются самыми простыми. Возможно, молчание, то есть отказ от излишней сложности, содержит больше информации, чем любое количество параметризованных уравнений.
Оригинал статьи: https://arxiv.org/pdf/2602.04941.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Генерация изображений: Новый взгляд на скорость и детализацию
- Визуальный разум: Как видеомодели научились понимать текст и создавать изображения
- Искусственный разум: Нет доказательств самосознания в современных языковых моделях
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Квантовые состояния под давлением: сжатие данных для новых алгоритмов
2026-02-08 06:58