Автор: Денис Аветисян
В новой работе представлена методика, использующая возможности больших языковых моделей и символьного исполнения для автоматизированного поиска уязвимостей в коде, используемом для создания нейросетей.
Предложенный подход Centaur сочетает в себе нейросимволическое обучение для выявления ограничений API и повышения эффективности тестирования библиотек глубокого обучения.
Несмотря на широкое распространение библиотек глубокого обучения, таких как PyTorch и TensorFlow, их тестирование остается сложной задачей из-за отсутствия формальных спецификаций API. В работе ‘Testing Deep Learning Libraries via Neurosymbolic Constraint Learning’ предложен Centaur — инновационный нейросимволический подход, использующий большие языковые модели и символьное исполнение для автоматического изучения ограничений на входные данные API. Centaur позволяет генерировать разнообразные и валидные тестовые примеры, значительно повышая эффективность обнаружения ошибок и превосходя существующие методы по показателям покрытия. Каким образом дальнейшее развитие нейросимволических методов может оптимизировать процесс тестирования и обеспечить надежность критически важных систем искусственного интеллекта?
Вызовы надёжного API-тестирования: Эхо будущих сбоев
Современное программное обеспечение в значительной степени опирается на интерфейсы прикладного программирования (API), что делает их тщательное тестирование важнейшим условием обеспечения надежности. API служат своеобразными «строительными блоками», позволяющими различным программным компонентам взаимодействовать друг с другом. От их корректной работы зависит стабильность и функциональность целых систем, от мобильных приложений до сложных корпоративных платформ. Недостаточное тестирование API может привести к серьезным последствиям, включая сбои в работе, потерю данных и уязвимости в безопасности. Поэтому, инвестиции в эффективные стратегии тестирования API являются критически важными для обеспечения качества и долговечности любого программного продукта.
Традиционные методы тестирования всё чаще оказываются неэффективными при работе с современными API. Огромное количество возможных входных данных и сложное взаимодействие между компонентами создают экспоненциально растущее пространство для тестирования. Ручное тестирование попросту не способно охватить все сценарии, а автоматизированные тесты, разработанные по старым принципам, часто не учитывают нюансы поведения API в различных ситуациях. Это приводит к тому, что даже тщательно протестированные API могут содержать скрытые дефекты, проявляющиеся только в реальных условиях эксплуатации, что негативно сказывается на стабильности и надёжности программного обеспечения. Поэтому требуется разработка новых подходов к тестированию, способных эффективно справляться с этой сложностью и обеспечивать высокое качество API.
Centaur: Нейросимволический подход к обучению ограничениям
Система Centaur использует большие языковые модели (LLM) для анализа сигнатур API и генерации предварительных кандидатов на ограничения входных данных. LLM анализируют текстовое описание API, включая имена параметров, типы данных и, при наличии, описания ожидаемых значений. На основе этого анализа, LLM предлагают ограничения, которые, предположительно, определяют допустимое пространство входных данных для API. Этот подход позволяет системе быстро генерировать начальный набор ограничений, который затем уточняется и верифицируется с использованием SMT-решателей.
Предлагаемые LLM ограничения для входных данных API подвергаются уточнению с использованием решателей SMT (Satisfiability Modulo Theories). Этот процесс включает в себя формальную проверку предложенных ограничений на соответствие заданным спецификациям и определение допустимого пространства входных значений. Решатели SMT позволяют определить, существуют ли значения входных параметров, удовлетворяющие одновременно всем ограничениям, и в случае противоречий — выявить и устранить их. Такой подход гарантирует точность и полноту определения допустимых входных данных, что критически важно для обеспечения корректной работы и безопасности программного обеспечения.
Система Centaur демонстрирует высокую эффективность в обучении ограничениям для входных данных API, объединяя интуицию больших языковых моделей (LLM) с формальной верификацией посредством SMT-решателей. В ходе экспериментов, система достигла показателя полноты (recall) в 88.6% при работе с API библиотеки Pytorch и 100% для Tensorflow, сравнивая с эталонными (ground truth) ограничениями. Такой подход позволяет эффективно определять допустимые пространства входных данных, используя сильные стороны как неформального понимания LLM, так и строгой проверки SMT-решателями.

Улучшение генерации тестов с использованием валидных входных данных: Проверка реальности
Генерация валидных входных данных представляет собой ключевую проблему в тестировании API, поскольку неверные или неполные входные данные часто приводят к ложноположительным или ложноотрицательным результатам. Традиционные методы, такие как фаззинг, часто полагаются на случайную генерацию данных, что снижает эффективность обнаружения ошибок. Centaur решает эту проблему, фокусируясь на создании входных данных, которые соответствуют спецификациям API и ожидаемым типам данных. Это позволяет значительно повысить точность тестирования и сократить количество бесполезных тестов, что особенно важно для сложных API, таких как Pytorch и Tensorflow.
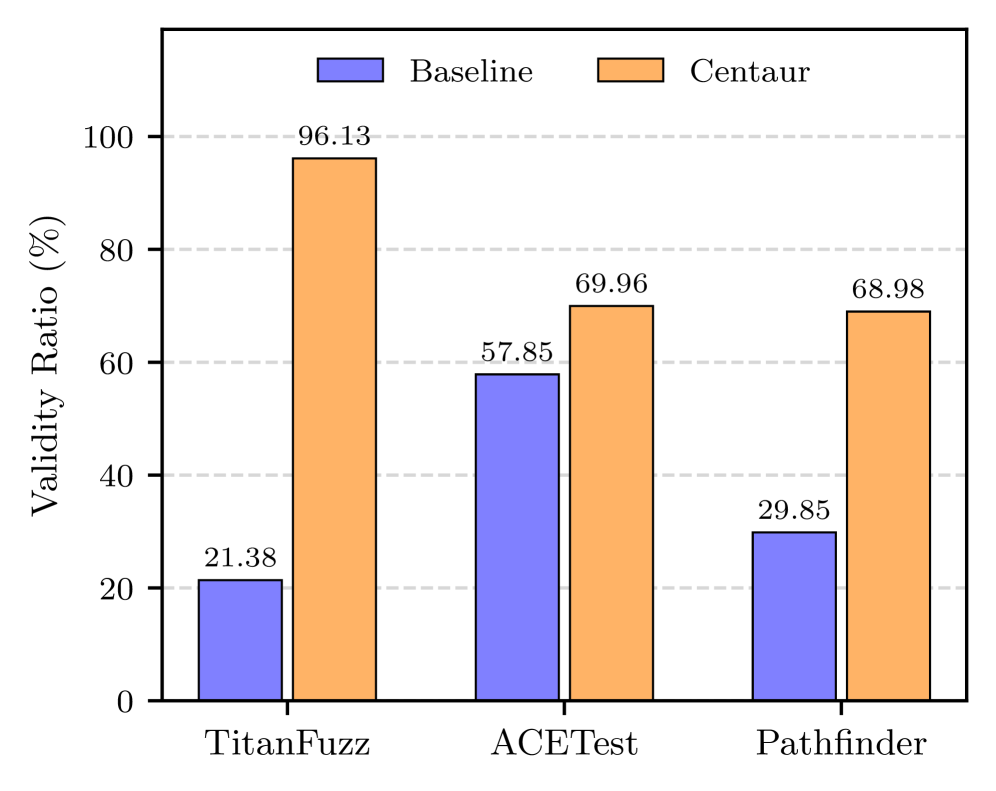
Существующие методы генерации валидных входных данных для API, такие как FreeFuzz, DocTer и TitanFuzz, хоть и способствуют созданию тестовых наборов, зачастую полагаются на эвристические подходы или неполную информацию о спецификациях API. Это приводит к ограниченному покрытию возможных сценариев и потенциальному пропуску краевых случаев. В отличие от формальной верификации, эвристики могут генерировать невалидные или нерелевантные входные данные, требующие дополнительной фильтрации и снижающие эффективность тестирования. Неполная информация о типах данных, ограничениях и взаимосвязях между параметрами также ограничивает возможности этих инструментов по генерации полных и корректных тестовых наборов.
Centaur улучшает генерацию тестовых наборов путём интеллектуального объединения обучения с ограничениями на основе больших языковых моделей (LLM) и формальной верификации. Этот подход позволяет создавать более полные наборы тестов с высокой степенью валидности — 97.87% для Pytorch и Tensorflow. Данный показатель значительно превосходит результаты, достигаемые современными инструментами, что свидетельствует о повышенной эффективности Centaur в обеспечении качества и надёжности тестируемого программного обеспечения.

За пределами API: К всестороннему тестированию моделей — Эхо системы
Система Centaur, демонстрирующая высокую эффективность на уровне тестирования API, органично расширяет свои возможности и на уровень тестирования модели. В основе этого лежит нейросимволический подход, позволяющий системе не только анализировать взаимодействие с интерфейсами, но и углубляться в логику работы самой модели. Это достигается благодаря интеграции нейронных сетей и символьных методов, что позволяет Centaur выявлять более сложные ошибки и уязвимости, не ограничиваясь проверкой корректности входных и выходных данных. В отличие от традиционных методов, фокусирующихся исключительно на API, Centaur способен анализировать внутренние состояния модели и предсказывать её поведение в различных сценариях, обеспечивая более всестороннее и надежное тестирование.
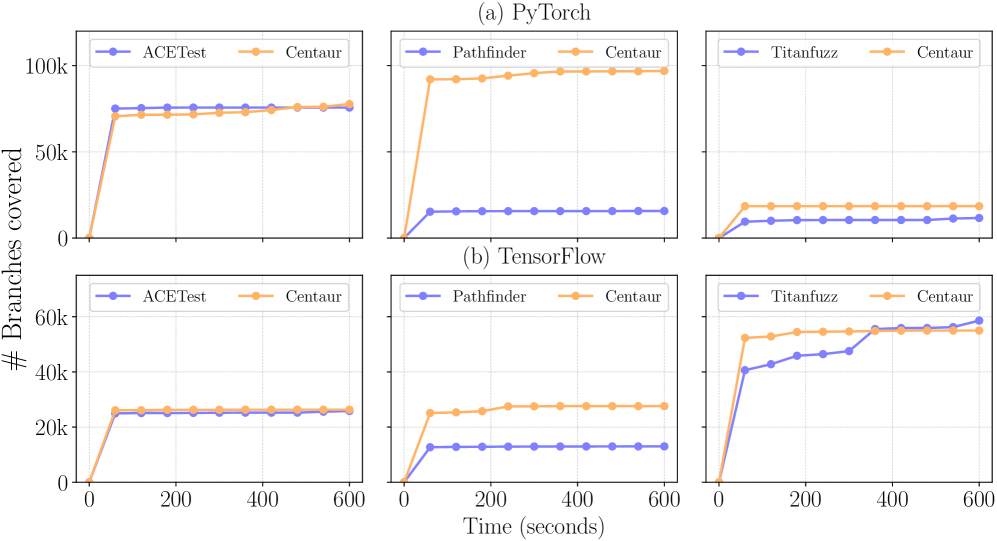
Интеграция Centaur с такими инструментами, как Daikon, Pathfinder и ACETest, позволяет значительно улучшить процесс обучения ограничениям и расширить охват тестирования моделей. Daikon, специализирующийся на обнаружении инвариантов в коде, позволяет Centaur более точно формулировать предположения о корректном поведении программы. Pathfinder, в свою очередь, обеспечивает углубленный символический анализ путей выполнения, выявляя потенциальные ошибки, которые могут быть упущены при поверхностном тестировании. ACETest, фокусируясь на ассертивных проверках, помогает Centaur создавать более надежные и полные тестовые случаи. Сочетание этих подходов позволяет не только выявлять больше ошибок, но и повышать уверенность в надежности и корректности тестируемых моделей, создавая синергетический эффект и существенно расширяя возможности автоматизированного тестирования.
Исследования показали значительное превосходство Centaur над инструментом Pathfinder в области проверки моделей машинного обучения. Статистический анализ с использованием коэффициента Cohen’s d выявил впечатляющий эффект размера — 17.05 для фреймворка Pytorch и 4.76 для Tensorflow, что указывает на существенно более широкое покрытие тестами. В ходе работы Centaur обнаружил в общей сложности 26 ошибок, причем 18 из них были впоследствии подтверждены разработчиками, демонстрируя высокую эффективность подхода в выявлении реальных уязвимостей и повышении надежности систем машинного обучения. Эти результаты подчеркивают потенциал Centaur как мощного инструмента для всестороннего тестирования и обеспечения качества моделей.
Исследование демонстрирует, что подход к тестированию глубоких нейронных сетей требует взгляда, выходящего за рамки традиционных методов. Centaur, предлагаемый в работе, не просто находит ошибки, а предсказывает потенциальные уязвимости, используя нейросимволический подход. Этот процесс напоминает выращивание системы, а не её конструирование по чертежам. Как заметил Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он работает». В данном случае, оптимизация тестирования невозможна без глубокого понимания ограничений API, что и пытается обеспечить Centaur, предвосхищая будущие сбои и уязвимости, а не просто реагируя на уже проявившиеся.
Куда же дальше?
Представленная работа, словно семя, брошенное в почву, демонстрирует возможность выращивания тестов, а не их строительства. Centaur, стремясь уловить границы дозволенного в глубоком обучении через нейросимволический синтез, лишь подтверждает старую истину: каждая зависимость — это обещание, данное прошлому. Иллюзия контроля над сложными системами требует соглашений об уровне обслуживания, и даже самые изощрённые инструменты лишь откладывают неизбежное.
Остаётся открытым вопрос о масштабируемости этого подхода. Большие языковые модели, как известно, склонны к галлюцинациям, а символьное выполнение — к экспоненциальному росту сложности. Вполне вероятно, что будущее лежит не в попытках охватить всё сразу, а в создании саморемонтирующихся систем, способных адаптироваться к неожиданностям. Всё, что построено, когда-нибудь начнёт само себя чинить.
Следующим шагом видится переход от обнаружения ошибок к их предсказанию. Вместо того чтобы реагировать на сбои, необходимо научиться видеть трещины в архитектуре до того, как они приведут к катастрофе. И тогда, возможно, мы поймём, что настоящая цель тестирования — не поиск ошибок, а понимание границ возможного.
Оригинал статьи: https://arxiv.org/pdf/2601.15493.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 16:15