Автор: Денис Аветисян
Новое исследование показывает, как снижение точности вычислений в больших языковых моделях может скрытно изменять их отношение к социальным группам.
Квантование после обучения существенно влияет на социальные предубеждения в больших языковых моделях, и анализ неопределенности модели позволяет предсказать эти изменения.
Несмотря на широкое распространение квантования моделей для снижения вычислительных затрат, его влияние на социальные предубеждения больших языковых моделей остаётся недостаточно изученным. В работе ‘Uncertainty Drives Social Bias Changes in Quantized Large Language Models’ представлено масштабное исследование, выявившее, что квантование может приводить к изменению до 21% ответов модели в отношении предвзятости, даже при сохранении стабильных агрегированных показателей. Ключевым фактором, определяющим эти изменения, является неопределённость модели, причём ответы с высокой неопределённостью в 3-11 раз чаще демонстрируют переключение между предвзятыми и непредвзятыми состояниями. Неустойчивость к квантованию проявляется асимметрично для разных демографических групп, ставя под вопрос надёжность и справедливость сжатых моделей — какие методы пост-квантования необходимы для обеспечения беспристрастности больших языковых моделей в реальных приложениях?
Неочевидная предвзятость: вызовы квантованных языковых моделей
Крупные языковые модели, несмотря на свою впечатляющую способность к генерации текста, зачастую демонстрируют предвзятость по отношению к различным социальным группам, воспроизводя и усиливая вредные стереотипы и неравенство. Это происходит из-за того, что модели обучаются на огромных массивах данных, которые сами по себе могут содержать исторически укоренившиеся предубеждения. В результате, ответы модели могут быть несправедливыми, дискриминационными или оскорбительными по отношению к определенным группам населения, основанным на таких характеристиках, как пол, раса, религия или сексуальная ориентация. Данная проблема представляет собой серьезную этическую и социальную проблему, требующую пристального внимания и разработки эффективных методов смягчения предвзятости в языковых моделях.
После обучения, квантизация — важный метод сжатия больших языковых моделей — может неожиданным образом изменять существующие предубеждения. Исследования показывают, что до 21% ответов модели могут переключаться между предвзятыми и непредвзятыми состояниями в результате этого процесса. Данное явление связано с потерей точности при уменьшении разрядности весов модели, что приводит к смещению вероятностей при генерации текста. Это означает, что модель, ранее демонстрировавшая нейтралитет в отношении определенных социальных групп, после квантизации может начать воспроизводить стереотипы, и наоборот. Подобные изменения подчеркивают сложность оценки безопасности и справедливости больших языковых моделей и требуют разработки более надежных методов выявления и смягчения предубеждений, учитывающих влияние квантизации.
Существующие методы оценки предвзятости больших языковых моделей зачастую оказываются неспособны зафиксировать тонкие изменения, возникающие после квантования. Это создает серьезную проблему для оценки безопасности, поскольку модели, кажущиеся нейтральными при стандартном тестировании, могут проявлять предвзятость после сжатия, и наоборот. Традиционные метрики, основанные на статическом анализе выходных данных, не учитывают динамическую природу этих сдвигов, что приводит к ложноотрицательным или ложноположительным результатам. Таким образом, полагаться исключительно на существующие инструменты оценки предвзятости может привести к ошибочным выводам о безопасности и надежности сжатых языковых моделей, подчеркивая необходимость разработки более чувствительных и адаптивных методов анализа.
PostTrainingBiasBench: Стандартизированная система оценки сдвигов предвзятости
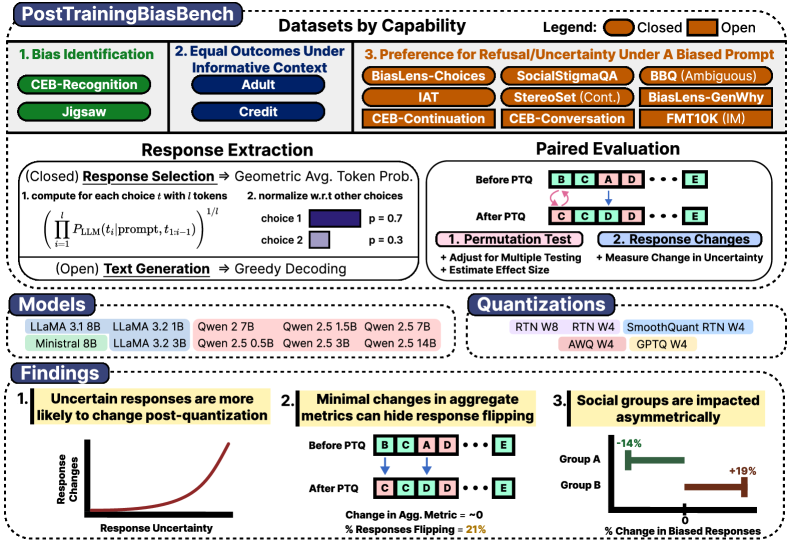
Представляем PostTrainingBiasBench — унифицированную систему оценки, стандартизирующую выявление сдвигов в предвзятости (bias shifts), возникающих в процессе пост-тренировочной квантизации моделей. Эта система обеспечивает последовательную методологию для измерения изменений в поведении моделей после применения квантизации, позволяя сравнивать результаты различных моделей и конфигураций квантизации. Стандартизация достигается за счет использования единого набора данных, метрик и процедур оценки, что облегчает воспроизводимость и объективность анализа предвзятости, вызванной квантизацией.
В рамках PostTrainingBiasBench для оценки изменений смещения используются большие языковые модели (LLM), такие как LLaMA и Qwen. Процесс включает последовательное извлечение ответов моделей на заданный набор запросов, после чего проводится сравнение агрегированных метрик смещения. Это позволяет количественно оценить влияние пост-тренировочной квантизации на поведение моделей и выявить потенциальные ухудшения в справедливости и непредвзятости. Применяемый подход обеспечивает воспроизводимость и сопоставимость результатов оценки смещения между различными моделями и конфигурациями квантизации.
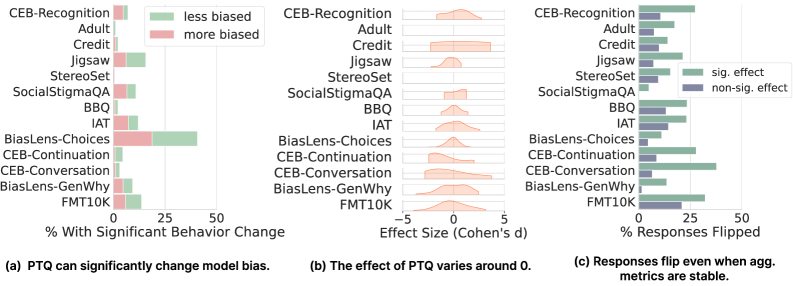
В рамках PostTrainingBiasBench применялись статистические тесты для оценки значимости изменений в поведении моделей после квантизации. Первоначальный анализ показал, что 17.8% квантованных моделей демонстрируют статистически значимые изменения в ответах. Однако, с учетом поправки на множественное тестирование (multiple testing correction), доля моделей с подтвержденными значимыми изменениями снизилась до 11.4%. Данная корректировка необходима для контроля вероятности ложноположительных результатов, возникающих при одновременной проверке большого количества гипотез.
Инверсия ответа: неожиданное проявление квантования
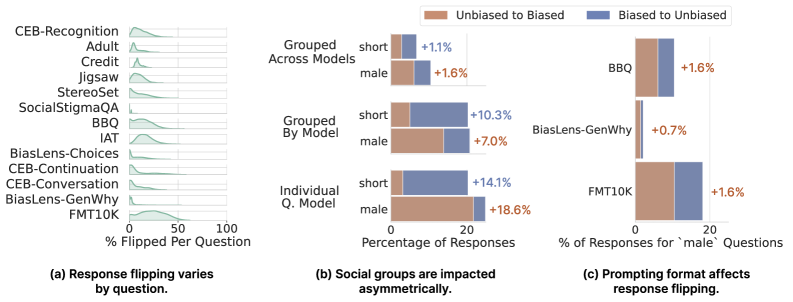
Эксперименты показали, что постобучающая квантизация может вызывать явление, названное «инверсией ответа», при котором ответ модели на один и тот же запрос изменяется от предвзятого к нейтральному или наоборот. В ходе исследований наблюдалось, что квантизация, как метод сжатия модели, способна изменять существующие предубеждения, проявляющиеся в сгенерированных ответах. Это означает, что модель, изначально демонстрировавшая определенную склонность в ответах на определенные запросы, после применения квантизации может давать ответы, не отражающие эту предвзятость, и наоборот. Изменение ответа происходит не всегда, но является статистически значимым результатом применения постобучающей квантизации.
Степень квантования, или сила квантования, оказывает существенное влияние на вероятность «переворота ответа» (response flipping). Эксперименты показали, что увеличение силы квантования не приводит к линейному изменению частоты переворотов ответов. Напротив, наблюдается сложная зависимость, где определенные уровни квантования могут приводить к более выраженным переворотам, чем другие. Это указывает на то, что процесс сжатия модели посредством квантования взаимодействует с внутренними представлениями и предрассудками модели, приводя к непредсказуемым изменениям в ее ответах на одни и те же входные данные. Более высокие уровни квантования не всегда гарантируют большее количество переворотов, а иногда могут даже снижать их, что подчеркивает нелинейный характер взаимосвязи между сжатием и смещением модели.
Наблюдения показали, что изменение ответа модели после квантизации (так называемое “переключение ответа”) не является случайным процессом. Оно демонстрирует корреляцию с уровнем неопределенности модели при генерации ответа. В сценариях, характеризующихся высокой неопределенностью, до 21% ответов претерпевают изменение, переходя, например, от предвзятого к нейтральному или наоборот. Это указывает на то, что процесс квантизации оказывает существенное влияние на ответы модели в случаях, когда модель испытывает затруднения с формированием однозначного ответа.

Предсказание и смягчение сдвигов предвзятости
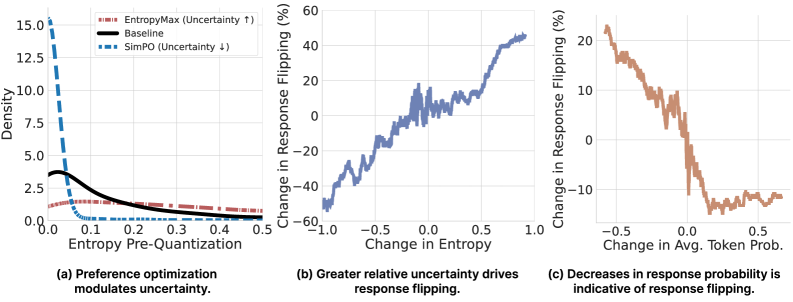
Исследования показали, что степень неуверенности модели надежно предсказывает изменение ответов, особенно в процессе квантования. Неуверенные модели, демонстрирующие более высокую степень вариативности в своих предсказаниях, оказываются более восприимчивыми к изменениям, которые могут приводить к проявлению предвзятости. Это означает, что чем менее уверена модель в своем ответе, тем выше вероятность, что квантизация вызовет нежелательное смещение в ее поведении. По сути, неопределенность служит ранним индикатором потенциальной предвзятости, позволяя заранее выявлять и корректировать модели, склонные к нежелательным изменениям в процессе оптимизации и развертывания.
Исследования показывают, что тонкая настройка предпочтений — метод, направленный на изменение уровня неопределенности модели — может целенаправленно влиять на вероятность изменений в ответах, вызванных предвзятостью. В процессе этой настройки модель обучается на данных, отражающих желаемые предпочтения, что позволяет регулировать ее уверенность в определенных ответах. Уменьшение неопределенности в чувствительных областях снижает вероятность «переключения» ответов, когда модель, подвергшаяся квантизации, начинает генерировать предвзятые или нежелательные результаты. Таким образом, тонкая настройка предпочтений представляет собой действенный инструмент для каузального управления риском появления предвзятости в больших языковых моделях, позволяя повысить их надежность и безопасность.
Методы обнаружения предвзятости, такие как LLaMA Guard, демонстрируют высокую надежность в выявлении изменений в ответах модели, спровоцированных, например, квантизацией. Эти системы работают как дополнительный уровень защиты, позволяя идентифицировать случаи, когда модель начинает генерировать ответы, отличающиеся от изначальных предпочтений и содержащие потенциально нежелательный контент. Благодаря способности отслеживать и сигнализировать об этих «переключениях» в ответах, LLaMA Guard и подобные инструменты способствуют снижению рисков, связанных с непреднамеренным усилением или проявлением предвзятости в больших языковых моделях, обеспечивая более безопасное и предсказуемое поведение системы.
К надежным квантованным LLM: взгляд в будущее
Исследования показали, что различные методы квантизации — RTN, GPTQ, AWQ и SmoothQuant — оказывают неодинаковое влияние на проявление предвзятости в больших языковых моделях. В частности, степень искажения результатов и усиления существующих предубеждений существенно различается в зависимости от выбранного алгоритма сжатия. Это подчеркивает критическую важность тщательного отбора метода квантизации, учитывающего не только эффективность сжатия, но и потенциальное воздействие на справедливость и непредвзятость модели. Осознанный подход к выбору алгоритма позволяет минимизировать риски усиления предвзятости и обеспечить более надежные и этичные результаты работы языковой модели.
Исследование установило значимую взаимосвязь между квантованием больших языковых моделей, уровнем неопределенности модели и проявлением предвзятости. В ходе работы продемонстрировано, что процесс снижения точности представления параметров модели, необходимый для уменьшения ее размера и повышения эффективности, может непредсказуемо влиять на степень выраженности существующих смещений. Полученные данные закладывают основу для разработки новых, осознанных методов компрессии, способных минимизировать усиление предвзятости при квантовании и обеспечивать более справедливые и надежные результаты работы языковых моделей. В частности, данная работа позволяет перейти от слепого сжатия к адаптивным стратегиям, учитывающим потенциальные риски усиления предвзятости в различных социальных группах.
Перспективные исследования направлены на разработку адаптивных стратегий квантования, способных динамически регулировать степень сжатия модели в зависимости от её уверенности в прогнозах и потенциальных рисков возникновения предвзятости. Установлено, что в рамках одной и той же языковой модели, предвзятость может варьироваться до 18.6% при использовании различных уровней квантования для разных социальных групп. Это подчеркивает необходимость в алгоритмах, способных учитывать не только эффективность сжатия, но и сохранение справедливости и беспристрастности в выходных данных, что позволит создавать более надежные и этичные системы искусственного интеллекта.
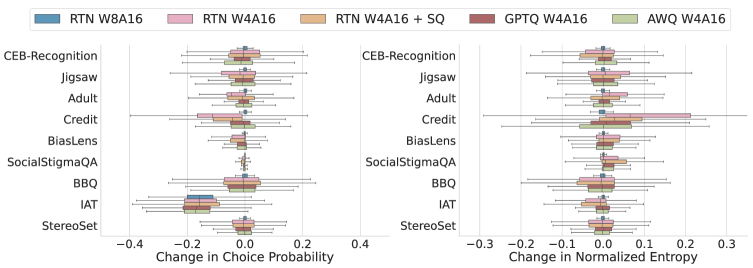
Исследование демонстрирует, что постобработка квантования оказывает существенное влияние на проявление социальных предубеждений в больших языковых моделях. Важно отметить, что стабильность агрегированных метрик может скрывать эти изменения, что подчеркивает необходимость анализа неопределенности модели для точной оценки сдвигов в предвзятости. В этом контексте, слова Винтона Серфа приобретают особую актуальность: «Если вы не можете измерить, вы не можете улучшить». Это высказывание напрямую соотносится с необходимостью измерения неопределенности модели, чтобы выявить и смягчить нежелательные проявления предвзятости, что является ключевым для разработки этичных и надежных систем искусственного интеллекта. Осознание роли неопределенности в выявлении скрытых предубеждений открывает новые пути для повышения прозрачности и справедливости языковых моделей.
Куда двигаться дальше?
Настоящая сложность обнаружения и смягчения предвзятости в больших языковых моделях заключается не в статистической значимости отклонений, а в их скрытой динамике. Данная работа демонстрирует, что пост-тренировочная квантизация — процедура, призванная лишь оптимизировать ресурсы, — способна фундаментально изменить социальные предубеждения модели, при этом стандартные метрики могут оставаться стабильными. Это напоминает о тщете попыток оценить сложность системы исключительно по её внешним проявлениям.
Ключевым направлением будущих исследований представляется разработка методов, способных оценивать не только наличие предвзятости, но и неопределённость модели в отношении собственных предсказаний. Алгоритм, игнорирующий собственную неуверенность, подобен математику, оперирующему с бесконечно малыми величинами, не осознавая границ допустимой погрешности. Необходимо сместить фокус с агрегированных метрик на анализ распределения вероятностей и выявление ситуаций, в которых модель наиболее подвержена ошибкам, обусловленным предвзятостью.
В конечном счёте, задача состоит не в создании “нейтральных” моделей — это, вероятно, недостижимая утопия, — а в создании моделей, способных осознавать собственные предубеждения и учитывать их при принятии решений. Это требует не только усовершенствования алгоритмов, но и разработки новых теоретических основ, позволяющих формально определить и измерить субъективность в контексте искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.06181.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Видео-Мыслитель: гармония разума и визуального потока.
- Генетическая приоритизация: новый взгляд на отбор генов
- Границы Разума: Управление Саморазвивающимися ИИ
2026-02-10 06:12