Автор: Денис Аветисян
Новое исследование показывает, что случайная маскировка градиентов в процессе обучения может значительно повысить эффективность адаптивных оптимизаторов, особенно при работе с большими языковыми моделями.
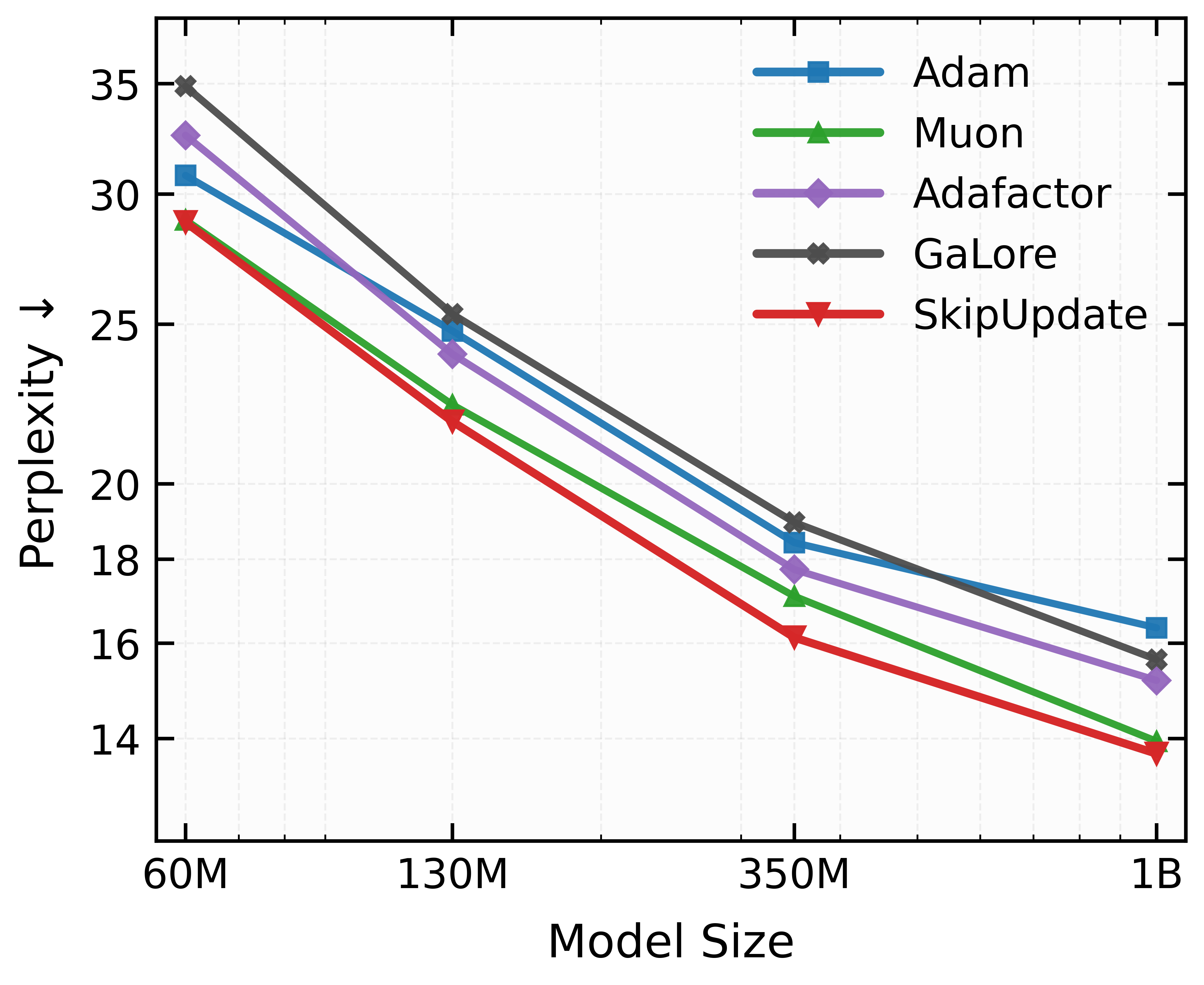
Маскировка градиентов обеспечивает геометрическую регуляризацию и выравнивание импульса, что приводит к улучшению обобщающей способности и скорости сходимости.
Несмотря на преобладание сложных адаптивных оптимизаторов в обучении больших языковых моделей, их эффективность не всегда очевидна. В работе ‘On Surprising Effectiveness of Masking Updates in Adaptive Optimizers’ показано, что случайное маскирование обновлений параметров может неожиданно повысить производительность, превосходя современные алгоритмы оптимизации. Анализ выявил, что маскирование индуцирует геометрическую регуляризацию, зависящую от кривизны, и сглаживает траекторию оптимизации, а предложенный метод Magma, использующий выравнивание по импульсу, обеспечивает стабильные улучшения с минимальными вычислительными затратами. Можно ли разработать новые методы оптимизации, основанные на принципах разреженных обновлений и геометрической регуляризации, для дальнейшего повышения эффективности обучения LLM?
Неизбежность Масштаба: Пределы Стандартной Оптимизации
Обучение масштабных языковых моделей, таких как Llama, представляет собой колоссальную задачу, требующую огромных вычислительных мощностей и подверженную значительной нестабильности. Для эффективной работы таких моделей требуется обработка терабайтов данных и использование тысяч графических процессоров, что делает процесс обучения чрезвычайно дорогостоящим и энергоемким. Нестабильность проявляется в виде колебаний градиентов, приводящих к расхождению обучения или застреванию в локальных минимумах функции потерь. По мере увеличения размера модели и объема данных эти проблемы усугубляются, требуя разработки новых методов обучения, способных преодолеть ограничения стандартных алгоритмов оптимизации и обеспечить стабильное и эффективное обучение даже при экстремальных масштабах. Сложность заключается не только в вычислительных затратах, но и в поддержании численной стабильности в процессе вычислений, что требует тщательной настройки гиперпараметров и применения специальных техник регуляризации.
Традиционные алгоритмы оптимизации, такие как плотные адаптивные оптимизаторы и RMSProp, испытывают значительные трудности при работе с чрезвычайно сложным ландшафтом функции потерь, характерным для крупных языковых моделей. Этот ландшафт, изобилующий локальными минимумами, седловыми точками и плоскими областями, создает препятствия для эффективного поиска глобального оптимума. В отличие от более простых моделей, где градиентный спуск может относительно легко найти оптимальные параметры, в случае с большими языковыми моделями, градиенты могут быть шумными, нестабильными и указывать в неправильном направлении. Это приводит к замедлению сходимости, необходимости использования более высоких скоростей обучения, что, в свою очередь, повышает риск расхождения, и, в конечном итоге, к ухудшению способности модели к обобщению на новых данных. Сложность ландшафта требует разработки более устойчивых и эффективных методов оптимизации, способных преодолевать эти трудности и обеспечивать стабильное и быстрое обучение.
Замедленная сходимость при обучении больших языковых моделей, таких как Llama, является серьезной проблемой, приводящей к увеличению времени и затрат на разработку. Это проявляется не только в длительном процессе настройки параметров, но и в снижении способности модели к обобщению — то есть, к эффективной работе с новыми, ранее не встречавшимися данными. Неспособность алгоритмов оптимизации эффективно исследовать сложный ландшафт функции потерь L приводит к тому, что модель застревает в локальных минимумах или на плато, не достигая оптимальной производительности. В связи с этим, разработка и внедрение более эффективных стратегий обучения, способных преодолевать эти ограничения и обеспечивать быструю сходимость и хорошую обобщающую способность, представляется критически важной задачей в области машинного обучения.
Редкие Обновления: Стабилизация Обучения через Маскирование
Алгоритм SkipUpdate, являющийся модификацией RMSProp, использует стратегию разреженных обновлений (Sparse Updates) путем случайного маскирования блоков параметров на каждой итерации обучения. Это означает, что не все параметры модели обновляются на каждом шаге оптимизации; вместо этого, определенные блоки параметров временно исключаются из процесса обновления. Маскирование выполняется случайным образом, обеспечивая, что на каждой итерации обновляется различный подмножество параметров. Такая схема позволяет снизить дисперсию и повысить стабильность обучения, предотвращая застревание оптимизатора в острых минимумах функции потерь. Выбор блоков для маскирования осуществляется случайным образом, что позволяет охватить все параметры модели в течение нескольких итераций обучения.
Метод блочной маскировки (Block-wise Masking) в SkipUpdate вносит контролируемый шум в процесс оптимизации путем случайного исключения определенных блоков параметров из обновления на каждой итерации. Этот подход направлен на предотвращение застревания оптимизатора в острых минимумах функции потерь. Острые минимумы характеризуются высокой чувствительностью к небольшим изменениям параметров, что может привести к нестабильности обучения и плохой обобщающей способности. Введение шума позволяет оптимизатору исследовать более широкую область пространства параметров и находить более плоские минимумы, которые, как правило, обеспечивают лучшую производительность и устойчивость.
Стратегия SkipUpdate снижает дисперсию процесса обучения за счет выборочного обновления параметров. Вместо обновления всех весов модели на каждой итерации, SkipUpdate случайным образом маскирует блоки параметров, что приводит к обновлению только подмножества весов. Это уменьшает влияние отдельных примеров на процесс оптимизации и стабилизирует сходимость, особенно в задачах с зашумленными данными или сложными функциями потерь. Уменьшение дисперсии позволяет использовать более высокие скорости обучения без риска расходимости и способствует более плавному и надежному обучению модели.
Зависимая от Кривизны Регуляризация: Формирование Ландшафта Потерь
Метод SkipUpdate реализует регуляризацию, зависящую от кривизны, путем эффективного снижения веса обновлений, совпадающих с направлениями высокой кривизны в пространстве потерь. Это достигается за счет модификации шага оптимизации, что приводит к ослаблению изменений параметров в областях, где поверхность потерь резко меняется. Фактически, SkipUpdate вносит вклад в функцию потерь дополнительный член, пропорциональный кривизне, \nabla^2 Loss , что приводит к более мягким обновлениям параметров в областях высокой кривизны и, как следствие, к снижению вероятности переобучения.
Регуляризация, достигаемая за счет повышения плоскостности (Flatness) пространства потерь, является ключевым фактором улучшения обобщающей способности модели. Плоскостность, в данном контексте, характеризует ширину и неглубокость минимумов функции потерь. Модели, находящиеся в широких, плоских минимумах, демонстрируют повышенную устойчивость к незначительным изменениям входных данных и параметрам модели, что приводит к более стабильным и надежным предсказаниям на новых, ранее не встречавшихся данных. В отличие от узких, острых минимумов, которые могут быть чувствительны к шуму и приводить к переобучению, плоские минимумы способствуют формированию более обобщенных представлений, что положительно сказывается на производительности модели в реальных условиях.
Алгоритм SkipUpdate способствует поиску широких минимумов в ландшафте функции потерь, что является эффективным методом предотвращения переобучения модели. Переобучение возникает, когда модель слишком хорошо адаптируется к обучающим данным, теряя способность к обобщению на новые, ранее не встречавшиеся данные. Широкие минимумы характеризуются более устойчивыми параметрами, менее чувствительными к незначительным изменениям во входных данных, что обеспечивает лучшую обобщающую способность и, следовательно, более высокую точность на тестовых данных. Использование широких минимумов позволяет модели избегать застревания в узких, острых минимумах, которые, хоть и обеспечивают низкую ошибку на обучающей выборке, часто приводят к плохой производительности на реальных данных.
Влияние на NanoMoE: Подтверждение и Более Широкие Последствия
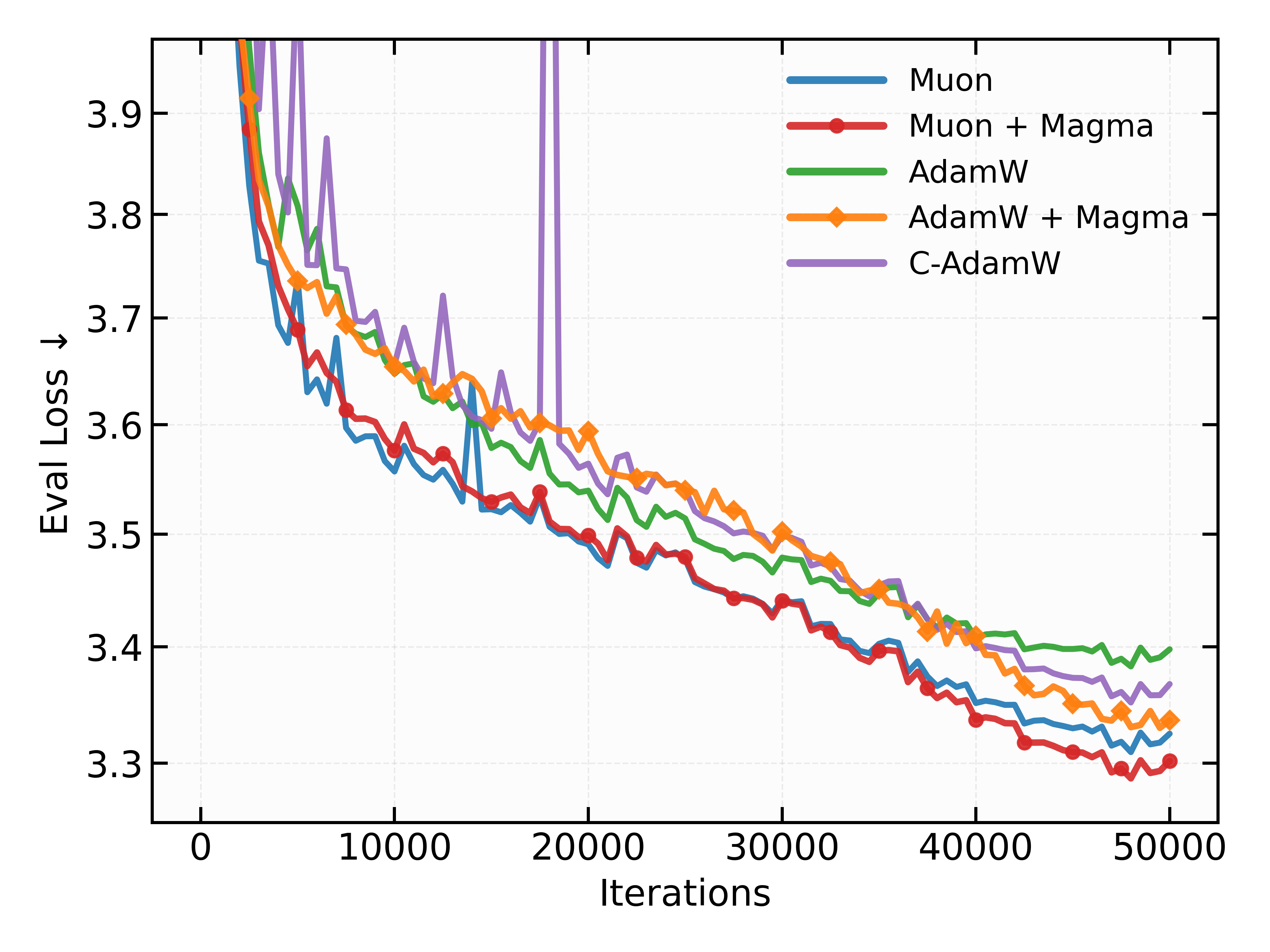
Исследование демонстрирует эффективность метода SkipUpdate при обучении NanMoE — модели на основе Nano Mixture of Experts. Данный подход позволяет значительно улучшить стабильность процесса обучения и ускорить сходимость модели. Эксперименты показали, что применение SkipUpdate обеспечивает достижение более высоких результатов по сравнению со стандартным алгоритмом RMSProp. В частности, при использовании NanMoE на модели Llama, состоящей из 130 миллионов параметров, удалось достичь показателя валидационной перплексии в 21.58, что на приблизительно 0.99 лучше, чем при использовании базового RMSProp. Это свидетельствует о потенциале SkipUpdate для эффективного обучения крупных моделей, что открывает новые возможности для достижения передовых результатов в различных задачах обработки естественного языка.
В ходе экспериментов с моделью NanoMoE продемонстрирована заметная улучшенная стабильность обучения и ускоренная сходимость по сравнению со стандартным алгоритмом RMSProp. Использование предложенного подхода позволило достичь показателя валидационной перплексии в 21.58 на 130-миллионной модели Llama, что превосходит результат базового RMSProp примерно на 0.99. Этот прирост указывает на повышенную эффективность оптимизации и способность модели быстрее адаптироваться к данным, что является важным шагом к созданию более мощных и эффективных языковых моделей.
В ходе экспериментов с моделью Nano Mixture of Experts (NanoMoE) было установлено, что применение алгоритма Magma как к слоям внимания, так и к многослойным персептронам (MLP), позволяет достичь показателя валидационной перплексии в 21.65. Данный результат демонстрирует значительное превосходство над базовым алгоритмом RMSProp. Это указывает на то, что Magma эффективно оптимизирует процесс обучения, позволяя модели более точно предсказывать последовательности текста и, следовательно, улучшая её общую производительность в задачах обработки естественного языка. Достижение более низкой перплексии свидетельствует о повышенной способности модели к обобщению и адаптации к новым данным.
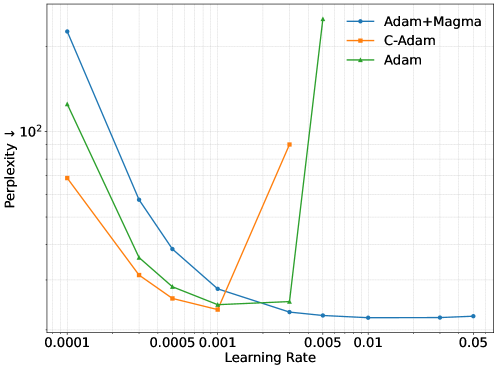
Предложенный подход открывает новые перспективы для масштабирования моделей MoE (Mixture of Experts), позволяя достигать передовых результатов в различных задачах обработки естественного языка. Ключевым преимуществом является сохранение стабильной работы модели в широком диапазоне скоростей обучения, что существенно упрощает процесс настройки и позволяет избежать проблем, связанных с расхождением обучения. Это особенно важно при работе с крупномасштабными моделями, где даже небольшие колебания в скорости обучения могут привести к значительным ухудшениям производительности. Стабильность, достигнутая в ходе исследований, позволяет исследователям и разработчикам более уверенно экспериментировать с архитектурой и гиперпараметрами, открывая путь к созданию еще более мощных и эффективных языковых моделей.
Исследование показывает, что случайное маскирование градиентов во время обучения больших языковых моделей приводит к неожиданным улучшениям. Этот подход, по сути, является формой геометрической регуляризации и выравнивания импульса, что позволяет оптимизаторам более эффективно ориентироваться в сложном ландшафте потерь. Как заметил Андрей Колмогоров: «Математика — это искусство невозможного». Действительно, в данном случае, кажущаяся нелогичной идея случайного вмешательства демонстрирует свою эффективность, подтверждая, что хаос не является сбоем, а лишь языком природы. Стабильность, в контексте обучения глубоких сетей, оказывается иллюзией, хорошо кэшированной в удачных конфигурациях, но маскирование градиентов раскрывает новые пути к более надёжной оптимизации.
Что же дальше?
Представленная работа, подобно любому вмешательству в сложный механизм, скорее обнажила вопросы, чем дала ответы. Случайное маскирование градиентов, привносящее кажущийся хаос в процесс обучения, неожиданно демонстрирует признаки порядка. Но порядок этот — не статичный, а динамичный, подобно росту кристаллов в перенасыщенном растворе. Истинная проблема заключается не в оптимизации самого алгоритма, а в понимании, как эта кажущаяся случайность формирует ландшафт потерь, как она выравнивает импульс и смягчает острые углы кривизны. Каждый рефакторинг начинается как молитва и заканчивается покаянием.
Очевидно, что маскирование — лишь один из способов внести геометрическую регуляризацию. Следующим шагом представляется поиск более тонких, адаптивных методов, способных учитывать локальную кривизну и структуру градиентов. Важно понимать, что системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. Адаптивные оптимизаторы, стремящиеся к идеальной траектории, часто упускают из виду фундаментальную истину: стабильность рождается не в контроле, а в способности системы к самоорганизации.
Истина, вероятно, заключается в том, что “успешность” оптимизатора — это лишь иллюзия, временное состояние равновесия. Система, подобно живому организму, постоянно взрослеет, мутирует и приспосабливается. Когда спрашивают, почему система нестабильна, ответ прост: она просто взрослеет. Попытки зафиксировать её в определенном состоянии обречены на провал. Следует научиться не строить, а взращивать.
Оригинал статьи: https://arxiv.org/pdf/2602.15322.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и квантовая физика: кто кого?
- Языковые модели и границы возможного: что делает язык человеческим?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Взрыв скорости: Оптимизация внимания для современных GPU
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Роботы учатся действовать, наблюдая за миром
- Сознание машин: новая модель двойных законов
2026-02-18 11:05